
はじめに
音声認識技術は、私たちの生活やビジネスにおいて欠かせないものとなりつつあります。議事録の自動作成、コールセンターの応対分析、多言語翻訳など、その活用範囲は広がる一方です。
本記事では、Google Cloudが提供する強力な音声認識サービスCloud Speech-to-Textに焦点を当て、2025年12月現在、その最新かつ高性能な基盤モデルChirp3を用いて、実際の日本語の音声データでどの程度の認識精度が得られるのかを検証します。
Cloud Speech-to-Text とは?
Cloud Speech-to-Textは、Googleの最先端の音声認識技術を活用した、高精度で使いやすい音声テキスト変換サービスです。
- 高度な音声AI:数百万時間の音声データと数十億の文章でトレーニングされたGoogle Cloudの音声向け基盤モデルChirp(チャープ)を利用可能
- 多言語対応:85以上の言語と言語変種※に対応しており、グローバルなユーザーベースに対応
- 多様な機能:ストリーミング音声認識、モデル適応(特定の単語の認識精度を向上させる)、話者ダイアライゼーション(誰が話したかを識別)、冒とく的な語句のフィルタリングなど、豊富な機能を提供
※ 同じ言語内における、地域(方言)、社会階層、年齢、性別などによって生じる言葉のバリエーションのこと。「英語」における「アメリカ英語(en-US)」や「イギリス英語(en-GB)」、「インド英語(en-IN)」など。
Chirp3とは?
Chirp3※は、Googleによって開発された最新の多言語自動音声認識(ASR)専用生成モデルです。以前の Chirp モデルよりもASR精度と速度が大幅に向上され、また、話者ダイアライゼーションと多言語音声の自動言語検出が可能になりました。
2025年10月13日にSpeech-to-TextでChirp3が一般提供され、利用できるようになりました。
※ここで言及しているChirp3は「Chirp 3: Transcription」のこと。同じChirp3の名を冠するモデルとして「Chirp 3: HD voices」も存在するが、これはテキストから音声を生成する別のモデル。
検証環境・手順
今回の検証では、手軽に試せるCloud Speech-to-Text コンソールを使用します。
1. 検証環境
- インターフェース:Cloud Speech-to-Text コンソール
- 使用モデル:Chirp3
- 音声データ:特撮映画「透明人間現わる」
- 1949年公開
- 透明人間による凶行と悲哀を描く、特撮の神様・円谷英二の戦後復帰作
- 著作権の保護期間が終了しているパブリックドメイン作品を使用
- 音声ファイル形式:FLAC ※
- 言語設定:日本語 (ja-JP)
※「Free Lossless Audio Codec」の略称で、音質を劣化させずに(可逆圧縮で)音声データを圧縮できる音声ファイル形式。Speech-to-Textへ渡す音声ファイルはFLACもしくはLINEAR16形式が推奨されている。参考)音声データを Speech-to-Text API へ渡す際の推奨事項
2. 検証手順
Audacity(オーディオ編集ソフト)を用いて、検証に使用する音声クリップを用意します。
音声データをアップロードするためのCloud Storage バケットを作成します。
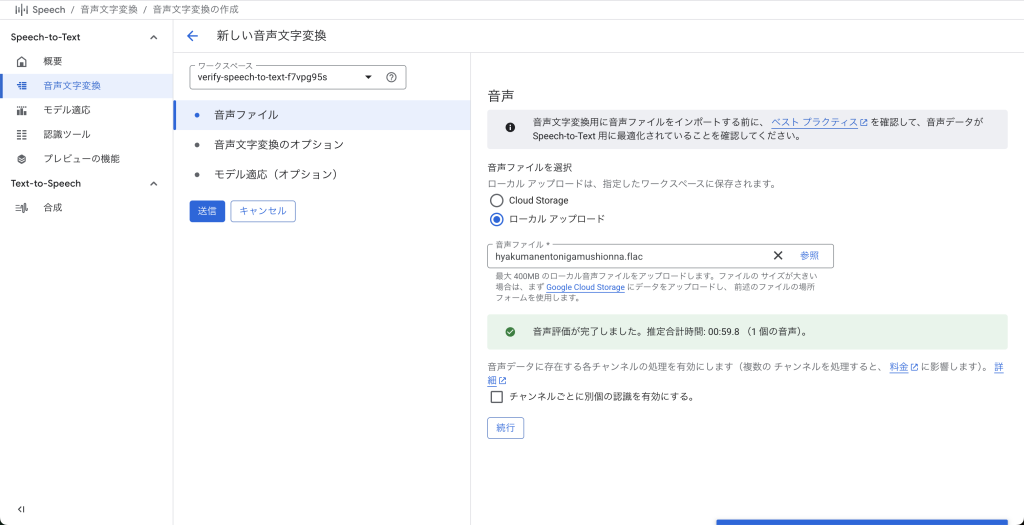
Cloud Speech-to-Text コンソールにアクセスし、音声ファイルをアップロードします。
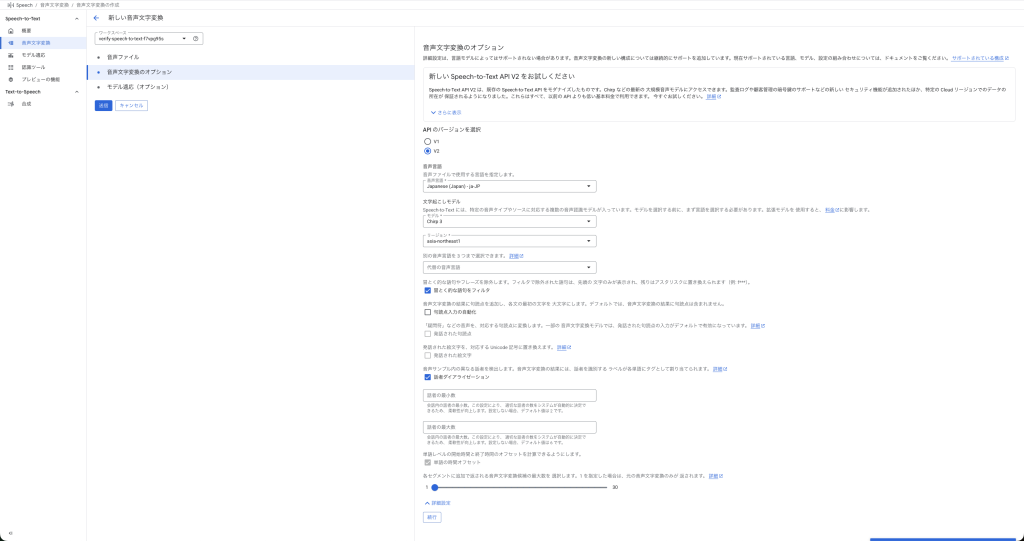
言語、モデル、話者ダイアライゼーションなどの設定を行います。
書き起こしを実行し、コンソール上で表示された文字起こしのテキストと、元の音声内容を比較して精度を評価します。
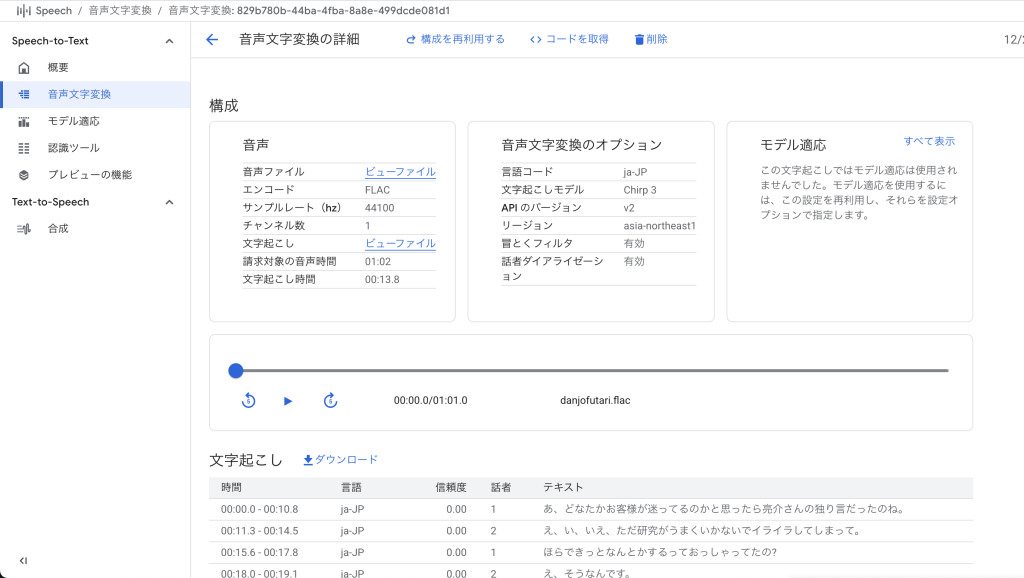
検証結果
検証1:男女の会話
「透明人間に気づかず、中里博士の娘・真知子が博士の弟子・瀬木に愛を語るシーン(55:15~56:15)」を対象にします。
| 項目 | 内容 |
|---|---|
| 会話の特徴 | 男女、女性が上機嫌で男性が不安げに喋る |
| ノイズ | わずかな環境音 |
| 話者の数 | 2人 |
検証結果
- 00:27.6 – 00:30.0で「透明液」を「そのうち」と誤って文字起こししていたが、それ以外はほぼ文字起こしできていた
- 漢字、カタカナ、ひらがな、疑問符の区別が基本できていた
- 話者の区別に問題なし
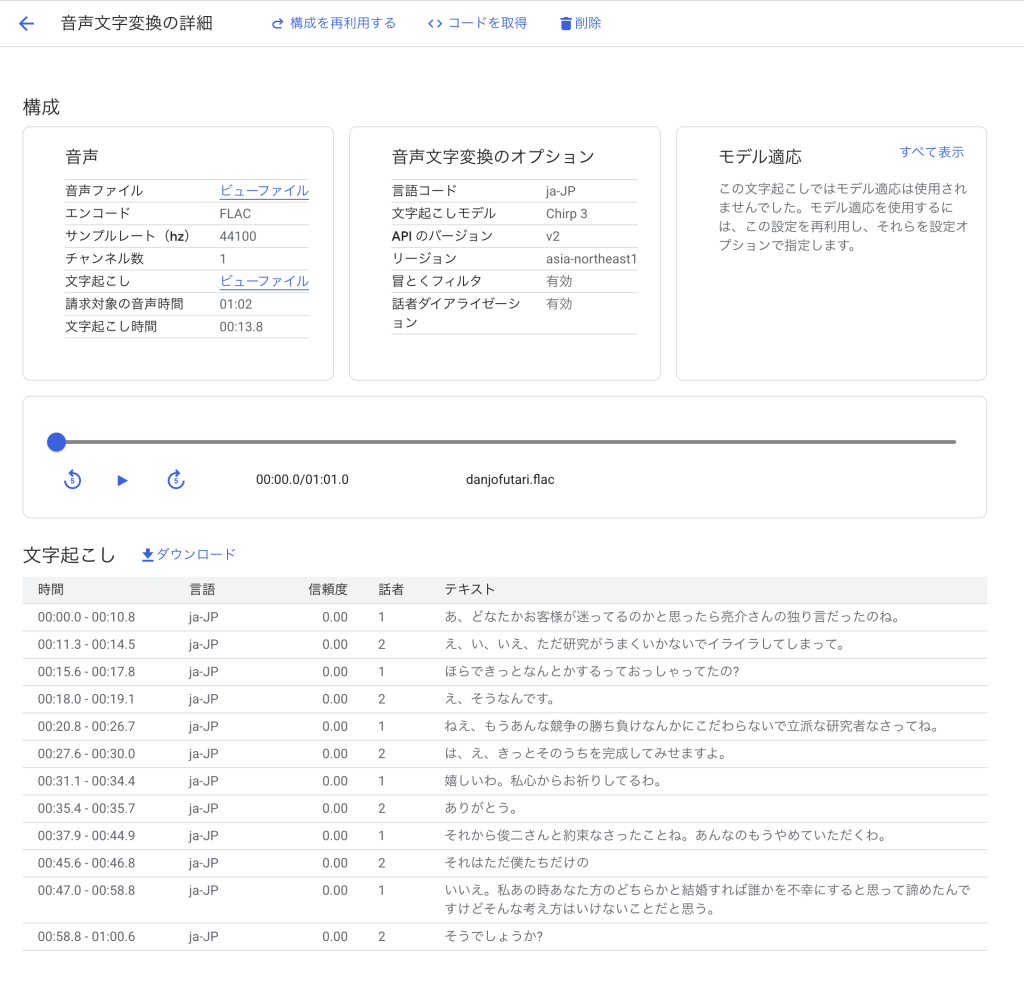
検証2:男性同士の会話
「中里博士がカワベ社長に透明薬の開発に成功したことを打ち明けるシーン(04:50~05:40)」を対象にします。
| 項目 | 内容 |
|---|---|
| 会話の特徴 | 男性同士、静かなトーン、2人の声が似ている |
| ノイズ | わずかな環境音 |
| 話者の数 | 2人 |
検証結果
- 00:05.8 – 00:12.2で「説」を「先生」と誤って文字起こししていたが、それ以外は完璧に文字起こしできていた
- 漢字、ひらがな、疑問符の区別が基本できていた
- 00:39.4 – 00:48.3で話者の区別に失敗していた
検証3:女性同士の会話
「真知子が博士の弟子2人にプロポーズされたと嬉しそうに母と話すシーン(04:05~04:35)」を対象にします。
| 項目 | 内容 |
|---|---|
| 会話の特徴 | 女性同士、和気藹々とした会話 |
| ノイズ | わずかな環境音 |
| 話者の数 | 2人 |
検証結果
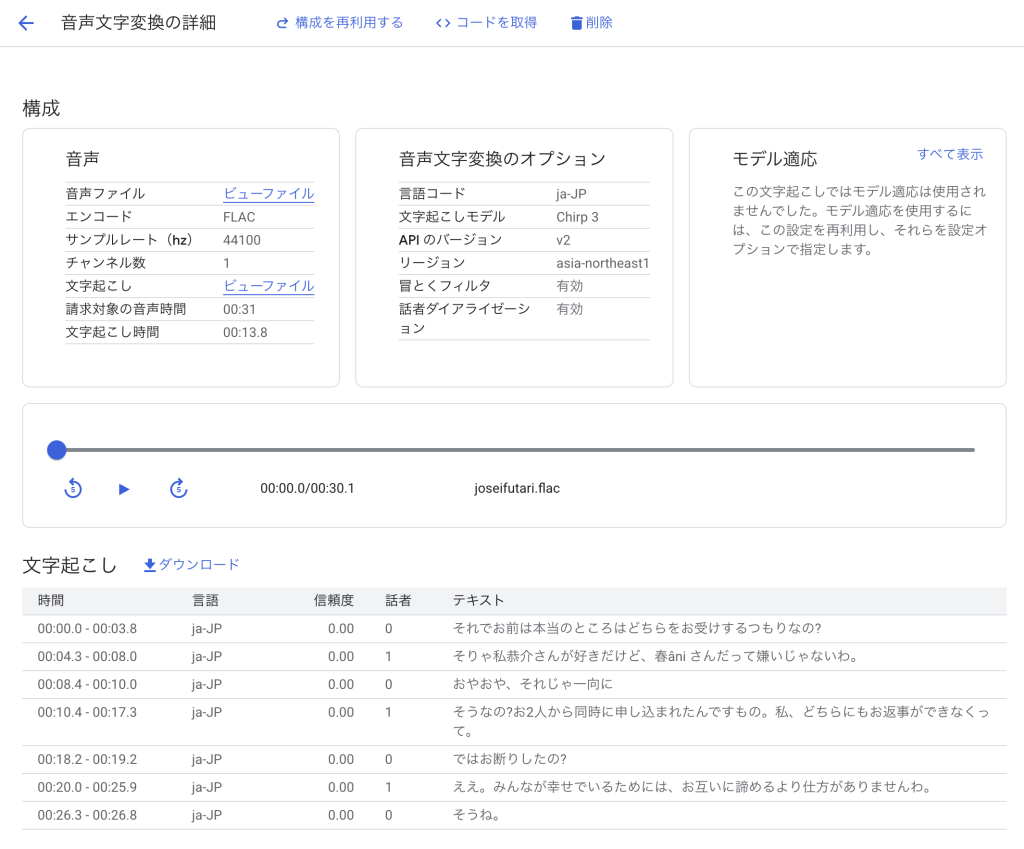
- 00:04.3 – 00:08.0で「俊二」を「春âni」と誤って文字起こししていたが、それ以外は完璧に文字起こしできていた
- 漢字、ひらがな、疑問符の区別が基本できていた
- 話者の区別に問題なし
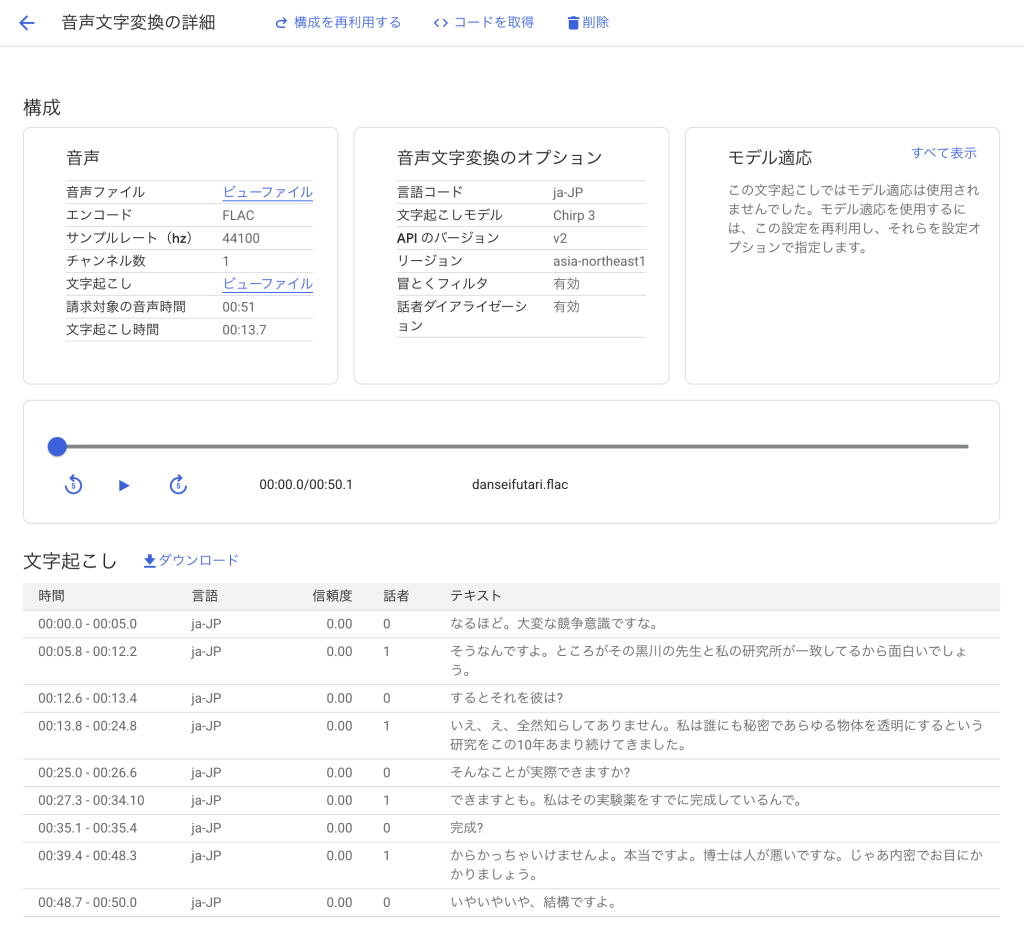
検証4:男女混合の会話
「真知子と瀬木とカワベ社長が黒川(透明人間)について話すシーン(38:45~40:15)」を対象にします。
| 項目 | 内容 |
|---|---|
| 会話の特徴 | 男2人・女1人の会話 |
| ノイズ | わずかな環境音 |
| 話者の数 | 3人 |
検証結果
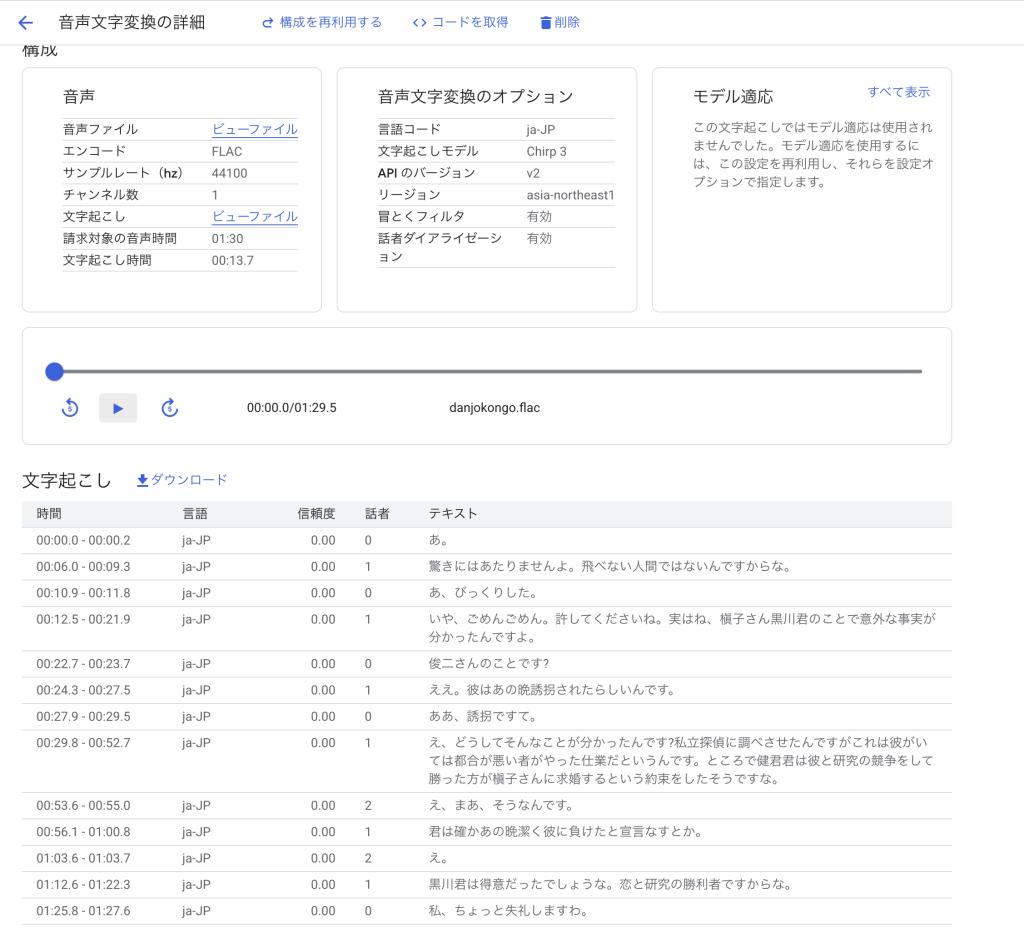
- 00:06.0 – 00:09.3で「透明人間」を「飛べない人間」と誤って文字起こししていたが、それ以外は基本文字起こしできていた
- 漢字、ひらがな、疑問符の区別が基本できていた
- 00:29.8 – 00:52.7で話者の区別に失敗していた
検証5:男女の会話 + ノイズ
検証1の会話にノイズを被せて検証します。
| 項目 | 内容 |
|---|---|
| 会話の特徴 | 男女、女性が上機嫌で男性が不安げに喋る |
| ノイズ | テレビの砂嵐音 |
| 話者の数 | 2人 |
検証結果
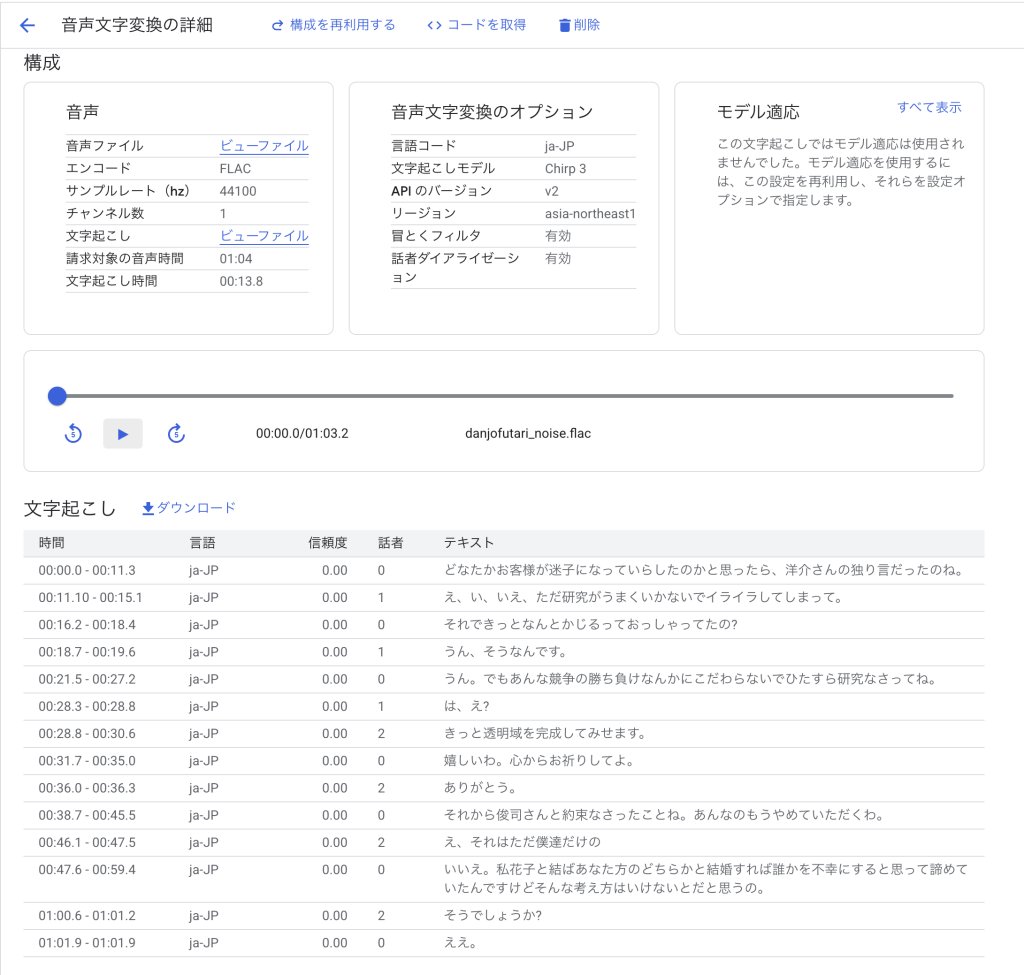
- 検証1の時と比べ、誤って文字起こしされる部分が多かったが、概ね文字起こしできていた
- 漢字、カタカナ、ひらがな、疑問符の区別が基本できていた
- 話者は2人だが、3人で認識されていた
検証6:暴力的・差別的な表現
ビジネスシーンや公開コンテンツで音声認識を活用する場合、不適切な発言がそのままテキスト化されることで、企業のブランド毀損や放送事故に繋がるリスクがあります。Cloud Speech-to-Textには、これらを自動で検出し、該当箇所の先頭文字以外をマスクして出力する(例: f***)「冒とくフィルタリング」が備わっています。ここでは、日本語で冒とくフィルタリングがどこまで機能するのかを検証します。
なお、対象の音声データに冒とく的な表現がなかったため、本検証のみ自分の声を録音して検証します。
| 項目 | 内容 |
|---|---|
| 特徴 | 暴力的・差別的な表現の読み上げ |
| ノイズ | なし |
| 話者の数 | 1人 |
検証結果
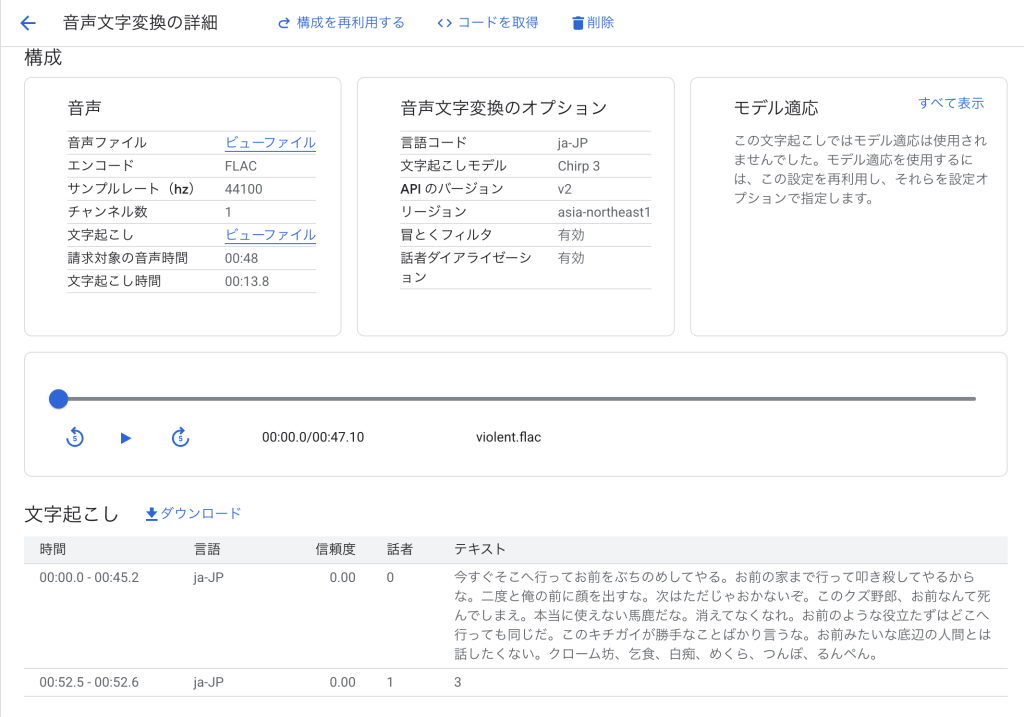
- 差別表現の一部が誤って文字起こしされていたが、伏せ字ではないので、冒とくフィルタリングによるものではない
- 漢字、ひらがな、カタカナの区別が基本できていた
- 今回選出した暴力的・差別的な表現は冒とく的な表現に該当せず、フィルタリングされなかった
まとめ
最新モデル Chirp3 を用いたSpeech-to-Textの検証の結果、文字起こしの精度がかなり高いことが分かりました。特にノイズが被っても一定文字起こしの精度を維持していた点から、ノイズ耐性も高いことが分かります。
一方で、話者の区別が曖昧になるという課題も見受けられました。特に、声のトーンが似ている話者が発言するシーンでは、一人ひとりを正確に識別し続けることはまだ難しいようです。
しかし、単語自体の誤認識はごく一部に留まっており、文脈の理解度は非常に優れています。ユースケース、妥協点、他ツールとの組み合わせを熟慮することで、既存プロダクトの改善や新規サービスの創出において、非常に強力なエンジンとなることは間違いありません。