
本記事は、Kubernetes(以下、k8s)に関する基礎的な知識を有していることを前提としています。
また、KEDAの特徴の一つであるゼロスケーリングについては詳しく触れませんのでご了承ください。
はじめに
期限付きインターン生の伊藤です。
本記事では、KEDA を使用したオートスケーリングについて、「スパイクという障害パターンへの対策」という観点から比較・検証を行い、スパイクに対してどの程度有効な手段であるかを確認します。
また、検証の過程でHPAとKEDAの拡張メトリクスについても触れるので参考にしていただければ幸いです。
さっそく、KEDAの解説…と進みたいところですが、KEDAを理解するうえで欠かせないHPAについて簡単に整理しておきます。
HPAとは
HPA (Horizontal Pod Autoscaler) とはk8sの標準機能として提供されているオートスケーリング機能です。オートという名称の通り、管理者による手動操作を必要としない点が特徴的です。
HPA は、Pod の負荷が高まった際に、Pod数を増やす(スケールアウトする)ことでアプリケーション全体に負荷を分散させます。これにより、安定性の向上、レスポンスの改善、障害耐性の強化などが期待できます。また、負荷が低下すれば、不要になったPodを自動的に削除(スケールイン)する機能も備えています。
公式ページ:https://kubernetes.io/docs/concepts/workloads/autoscaling/horizontal-pod-autoscale/
HPAの拡張ツールについて
HPAは標準機能として、CPU使用率とメモリ使用率のみをメトリクスとして扱うことができます。しかし、それだけでは柔軟なスケーリング設計が難しいケースも多く、こうした課題を背景にHPAの拡張ツールが登場しました。拡張ツールを利用することで、リクエスト数や未処理のタスク数、キャッシュヒット率、時間帯など、メトリクスとして扱える指標の幅が広がります。
HPAの拡張ツールには、Prometheus Adapter、Datadog Cluster Agent、各種クラウドが提供するAdapterそして今回注目しているKEDAなどがあります。それぞれk8sが公式で提供しているものではなく、各々のプラットフォームが提供しているツールとなっています。
メトリクス:システムの状態や負荷を数値で表す指標のことです。例えば、CPU がどの程度使用されているか、どれくらいのリクエストが発生しているかといった情報がメトリクスとして扱われ、オートスケーリングの判断材料となります。
さて、HPA の拡張ツールの一つとして KEDA を紹介しましたが、ここでは他の拡張ツールとの違いを説明していきます。
KEDAとは

HPA の拡張ツールの多くは、いわゆる アダプター(Adapter)と呼ばれる仕組みです。
アダプターは、k8s標準では扱えないメトリクスを取得し、それを Kubernetes の metrics API に変換することで、HPA が参照できる形にする役割を担います。この場合、スケーリングの判断や制御の主体はあくまで HPA です。
一方で KEDA は、このアダプター型の拡張とは少し異なります。
KEDA はメトリクスやイベントをもとに HPA を内部的に生成・更新する仕組みを持っており、HPA を「使う側」に回ります。そのため、KEDA を利用する場合は、KEDA がスケーリング全体を制御し、HPA はその一部として動作するという関係になります。
両者の違いをまとめると、どちらが主役かという点にあります。
アダプターを利用する場合は HPA が API クライアントとして振る舞いますが、KEDA を利用する場合は KEDA が HPA を扱う立場となります。
KEDAの開発元や運営に関しては記事最後の補足部分で話します。
KEDA公式ページ:https://keda.sh/
〇アダプターを使用したHPA図式
┌────────┐
│ 外部サービス │
│ Prometheus │
│ CloudWatch │
│ Stackdriver │
└──┬─────┘
│
▼
┌───────────┐
│ Adapter │
│ (Custom / External │
│ Metrics API) │
└──┬────────┘
│ 変換:metrics.k8s.io, external.metrics.k8s.io
│
▼
┌──────────┐
│ HPA │
│ (判定・制御) │
└──┬───────┘
▼
┌─────────┐
│ Deployment / Pod │
└─────────┘
〇KEDA図式
┌───────┐
│ イベント / │
│ メトリクス │
│ (Queue, │
│ RPS, Cron) │
└──┬────┘
│
▼
┌─────────┐
│ KEDA Operator │
│ (判定・制御) │
│ HPA(自動生成) │
└──┬──────┘
▼
┌─────────┐
│ Deployment / Pod │
└─────────┘
KEDAのトリガーについて
KEDA では、標準のトリガーとして さまざまなメトリクスを最初から扱えるようになっています。
KEDA 公式のトリガー一覧を確認すると、2025年12月23日時点で 74 種類のトリガーが built-in として提供されていることが分かります。
KEDAトリガー一覧ページ:https://keda.sh/docs/2.18/scalers/
ここまで比較対象とするツール達の説明をしました。ここからは今回の検証内容に触れていきます。
検証概要
頻出単語:RPS=Requests per second(リクエスト毎秒)
本検証ではHPA, HPA(拡張), KEDA, KEDA(cron)それぞれのスパイク対応能力を比較しました。
負荷対象となるアプリケーションおよびトラフィックシナリオを自作し、k6をKubernetesのJobとして実行することでクラスタ内部からの負荷として扱いました。また、本検証では実際に発生した障害時の環境やトラフィックを用意し、実運用でどう扱えるかという部分にも着目しています。
作成ファイルはこちらから
https://github.com/haitooo/keda_spikeTest
<検証環境>
今回はGCP/GKE上で検証を行いました。ローカル環境で検証を行わなかった理由としては私のマシンスペックが不足していたことや、より実案件環境に近づけるためです。
マシンスペック
マシンタイプ:e2-highcpu-8(vCPU:8, メモリ:約8GB)
ディスクサイズ:50GB
コンテナリソース
resources:
requests:
cpu: "300m"
memory: "128Mi"
limits:
cpu: "300m"
memory: "128Mi"HPA共通設定
spec:
minReplicas: 15
maxReplicas: 100
behavior:
scaleUp:
stabilizationWindowSeconds: 0
selectPolicy: Max
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleDown:
stabilizationWindowSeconds: 30
selectPolicy: Max
policies:
- type: Percent
value: 100
periodSeconds: 30<バージョン>
KEDA :2.18.2
k6 Operator:1.1.0
k6 本体 :0.49.0
GKE:
Client Version: v1.33.5-dispatcher
Kustomize Version: v5.6.0
Server Version: v1.33.5-gke.1308000
<負荷対象の作成>
想定:実際に稼働しているサービスのAPIサーバー部分を切り取ったものを負荷対象とする
1リクエストあたりどの程度負荷をかけるかを検証しながら調整するために可変式にしました。クエリパラメータでCPUの占有時間と一時的に使用するメモリ量を指定できるように実装しました。
最終的に1リクエストで1ms占有、その間1mbを確保という値設定にしました。また、今回使用するメトリクスのRPSを集計するための機構もアプリに組み込んでいます。
// workHandler: 1リクエスト=1カウントして、CPU/メモリ負荷を任意で発生
func workHandler(w http.ResponseWriter, r *http.Request) {
atomic.AddUint64(&totalRequests, 1)
// 任意パラメータ
// ?cpuMs=30 => 30ms CPU負荷
// ?memMB=10 => 10MB 1回確保して触る
cpuMs := parseInt(r.URL.Query().Get("cpuMs"), 0)
memMB := parseInt(r.URL.Query().Get("memMB"), 0)
if cpuMs > 0 {
doCPULoad(time.Duration(cpuMs) * time.Millisecond)
}
if memMB > 0 {
allocateMemoryOnce(memMB)
}
w.Header().Set("Content-Type", "application/json")
_ = json.NewEncoder(w).Encode(map[string]any{
"ok": true,
"count": atomic.LoadUint64(&totalRequests),
})
}トリガーの選定では、HPA/KEDAでどのメトリクスがスパイクに有効かを検討しました。
候補としては、キューに滞留している未処理タスク数や、キャッシュヒット率などが挙げられました。
本検証ではAPI サーバー部分のみを切り取ったものを負荷対象としており、キューイング機構を持たないサービスであることを前提としています。そのため、HPA/KEDAが扱うメトリクスとしてRPSを採用し、KEDA固有のトリガーとしてcronを用いる方針としました。
<トラフィックシナリオ>
- 負荷ツールとして、k6とheyが選択肢になりましたが、シナリオに柔軟性を持たせるためにk6を選択しました。k6はクラスタ内のJobから実行します。
- タイムアウト時間を10秒に設定しており、この時間を超えるとk6はそのリクエストをエラーとしてカウントします。
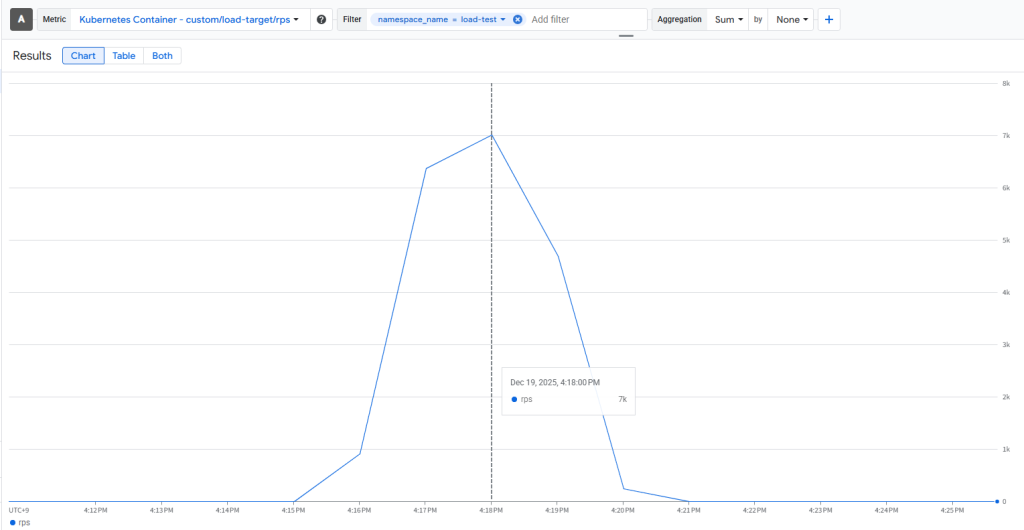
- 実案件に沿って、実際に障害が発生した際のトラフィックを再現したk6シナリオを用意しました。下記のコードはk6が使用するスクリプトの内容となっており、時系列データから、スクリプト通りのリクエストが発生していることが確認できます。
〇スクリプト内容
// 単位:RPS
startRate: 800
stages: [
{ target: 1500, duration: '30s' }, // スパイク前兆(800RPS→1500RPS)
{ target: 7000, duration: '15s' }, // メインスパイク
{ target: 7000, duration: '2m' }, // スパイク継続
{ target: 800, duration: '1m' }, // クールダウン
{ target: 0, duration: '10s' },
〇時系列データ
<比較対象>
- 従来メトリクス と 拡張メトリクスの比較
- HPA と KEDAの比較 (アダプターを介す事がスケーリングに影響するかどうか)
- cronスケジュールによる影響
という3つの観点から比較できるように4種類のスケーリング方法を用意しました。
①HPA(CPU/メモリベース)
- 標準/従来のスケーリング方法
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 60
②HPA(拡張メトリクス)
トリガー:1Podあたりの目標RPSを定めスケーリング
- アプリに送られてきたリクエストをカウントしてGCP Monitoringに提供する機能を実装しました。
- 今回は1Podあたり70RPSを目標値に設定しました。
- type: Pods
pods:
metric:
name: custom.googleapis.com|load-target|rps
target:
# 1 Pod あたりの目標 RPS
type: AverageValue
averageValue: "70"
③KEDA(HPA拡張と同じものをメトリクスで取る)
- ②と同じメトリクスでスケール
triggers:
- type: gcp-stackdriver
name: gcp-rps
authenticationRef:
name: load-target-keda-gcp
metricType: AverageValue
metadata:
projectId: haruki-ito
filter: >
metric.type="custom.googleapis.com/load-target/rps"
targetValue: "70"
activationTargetValue: "1"
valueIfNull: "0"
alignmentPeriodSeconds: "60" #60秒間のデータを1つの区間として扱う
alignmentReducer: sum
alignmentAligner: mean
④KEDA(前述のメトリクスに加えてcronを追加する)
- ③に加えてCronスケーリングを追加
- ある程度スパイクが発生する時間帯を予測できる前提で設定しました。
複数トリガーのスケーリング挙動に関しては補足をご覧ください。
triggers:
# GCP Monitoring (Stackdriver) custom metric: RPS
- type: gcp-stackdriver
name: gcp-rps
authenticationRef:
name: load-target-keda-gcp-with-cron
metricType: AverageValue
metadata:
projectId: haruki-ito
filter: >
metric.type="custom.googleapis.com/load-target/rps"
targetValue: "70"
activationTargetValue: "1"
valueIfNull: "0"
alignmentPeriodSeconds: "60"
alignmentReducer: sum
alignmentAligner: mean
- type: cron
name: cron-business-hours
metadata:
timezone: Asia/Tokyo
start: "0 9 * * 5"
end: "0 19 * * 5"
desiredReplicas: "50" #対象の時間帯は最小Pod数を50にしておく
結果予想
- ある程度スパイクが予想できるという前提のため、cronを使用したスケーリングが一番有効だと考えています。唯一Podの立ち上げというボトルネックに有効な手段とみているためです。
- 拡張メトリクスは、CPU使用率が上がりきる前にスケーリングできるのがどのくらい良い影響を与えるのという点に着目して検証したいと思います。CPUベースとそこまで大きな差は生まれないと予想しています。
検証
検証中の監視
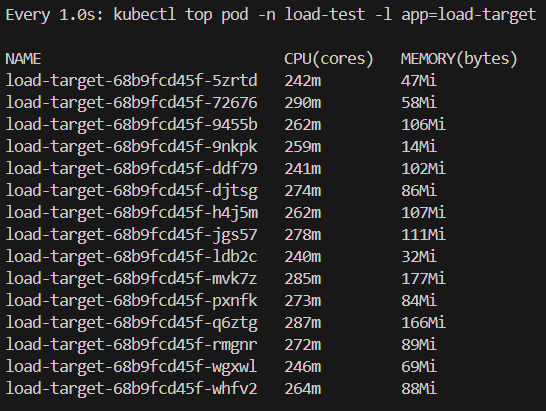
スケーリング中に各Podへ適切に負荷が分散されているかについては、以下のコマンドを使用しました。特定のPodに集中して負荷がかかっている様子などは見られず、全体として均等に処理が分散されていることが確認できました。
Kubernetes Service やロードバランシングの仕組みについて十分に理解できていない部分もあるため、今後の学習課題となりそうです。
watch -n 1 'kubectl top pod -n load-test -l app=load-target'-n : Namespace -l : ラベルセレクタ
以下のコマンドを負荷試験中に使用することで、リアルタイムで要求Pod数を確認できました。
kubectl describe hpa load-target-hpa -n load-testload-target-hpa → HPA の名前
load-test → Namespace
他、以下のコマンドでログを追いました。
kubectl get pods -n load-test -w
kubectl logs -n load-test deploy/load-target -fdeploy/load-target : ログ取得対象。Deployment のload-targetを指定しているという意味になる。
検証結果
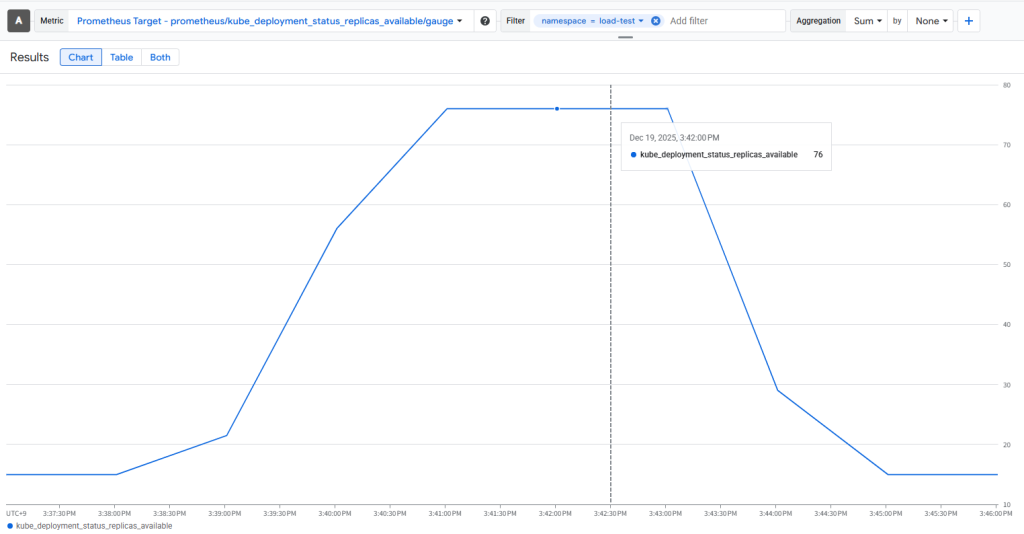
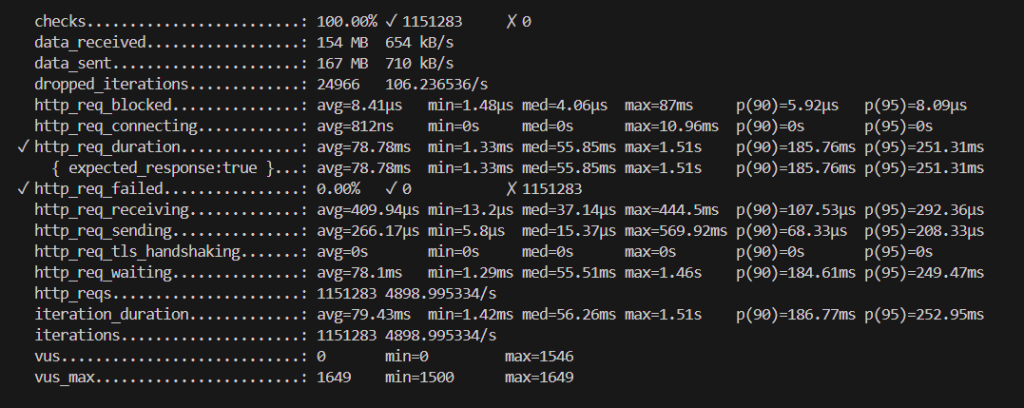
画像上:k6結果
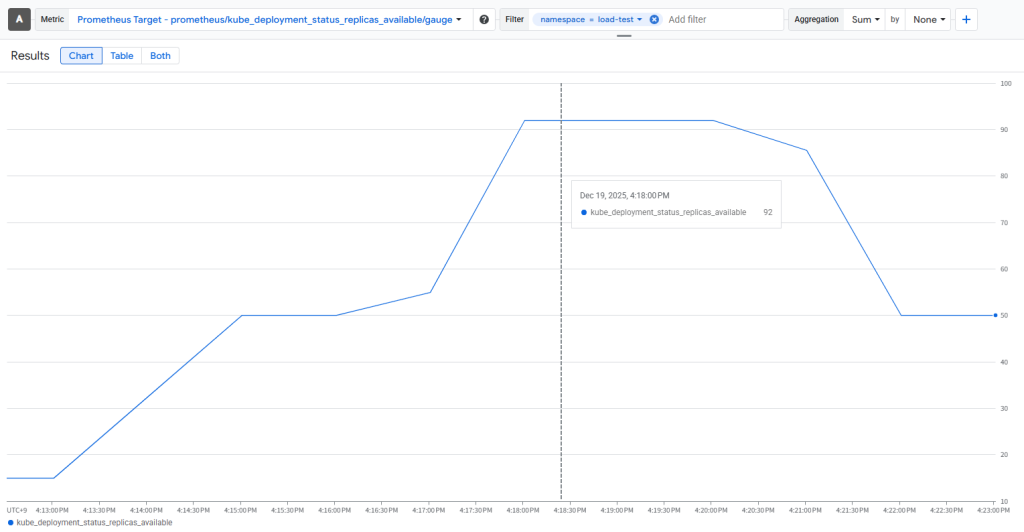
画像下:Monitoringで集計した負荷試験中のPod数推移
①HPA(CPU/メモリベース)
②HPA(拡張メトリクス)
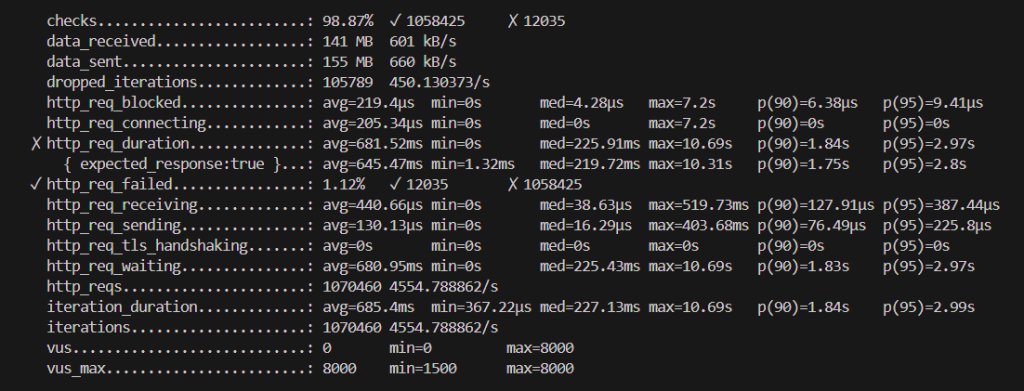
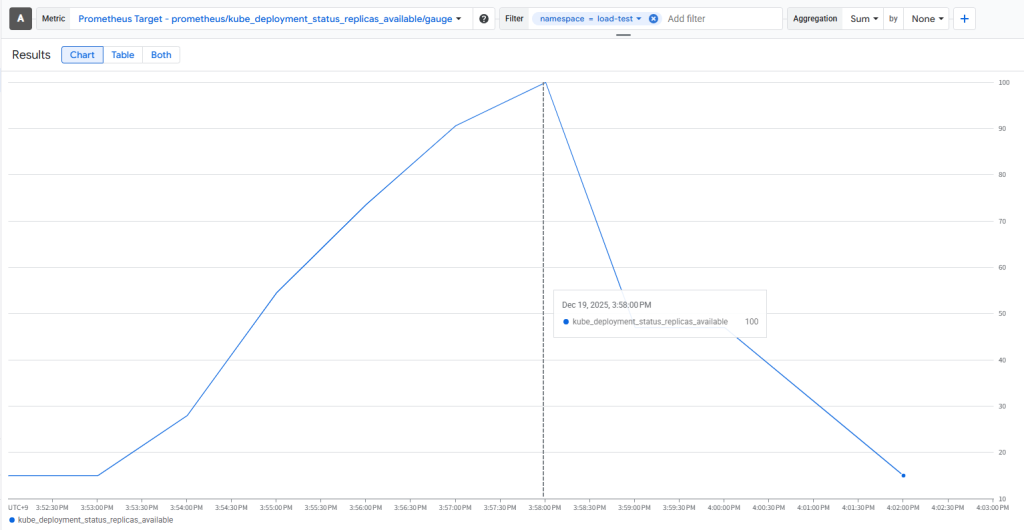
③KEDA(HPA拡張と同じものをメトリクスで取る)
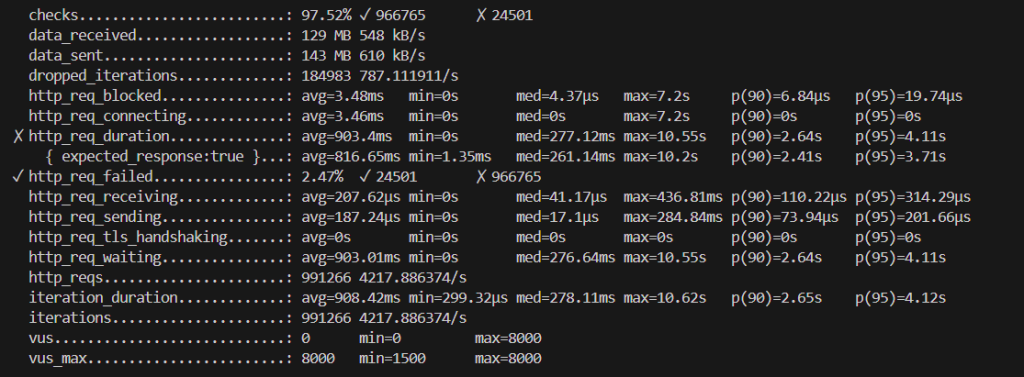
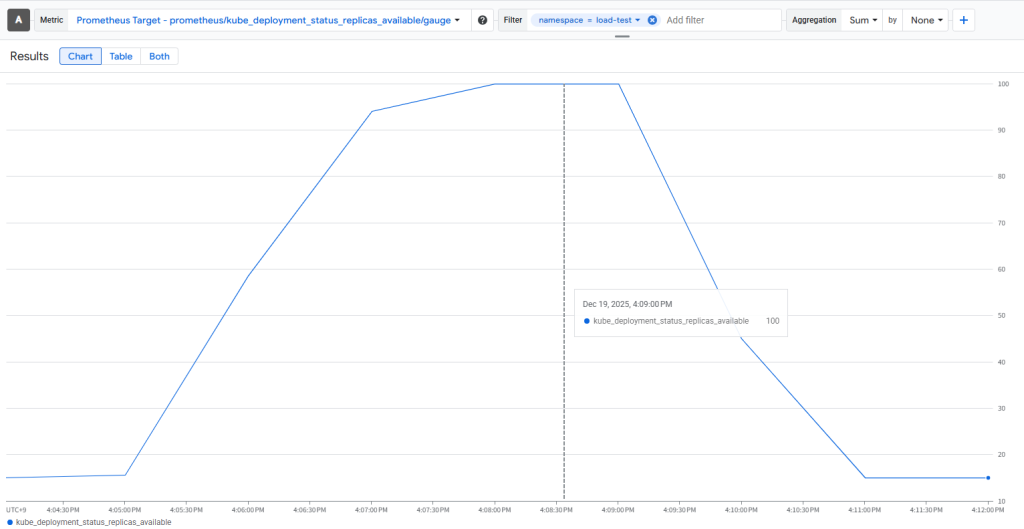
④KEDA(前述のメトリクスに加えてcronを追加する)
結果まとめ
- CPU/メモリスケーリングとHPA/KEDA(拡張)スケーリングの比較
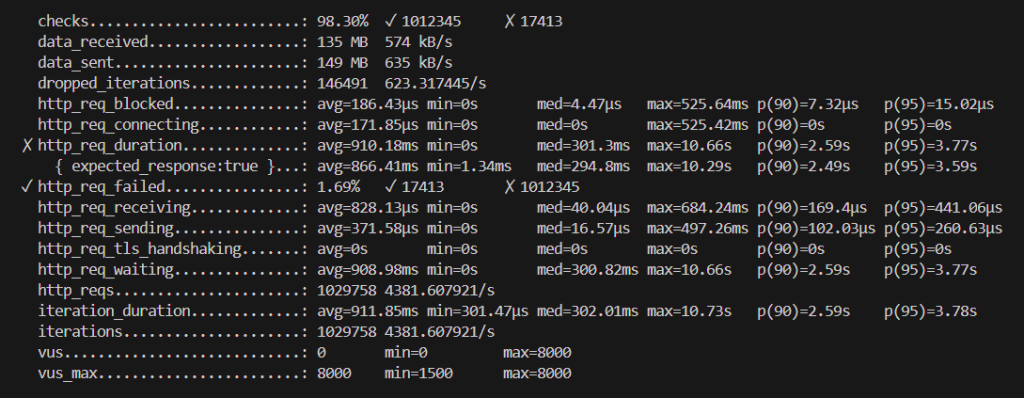
“http_req_duration”という項目を見ると、リクエスト送信からレスポンス受信完了までの合計時間一般的にいうAPIレイテンシの結果を確認できます。従来のスケーリングより拡張メトリクスを使用したほうがレイテンシが若干改善しています。- HPA/KEDA(拡張)が判断材料をわずかに早く取得していることが改善の理由だと考えています。実数値をみて分かる通り、体感ではほとんど感じることのない程のわずかな差です。
- やはりPodの立ち上げというボトルネックが残っているため、HPA/KEDA(拡張)のスケーリングだけでは十分なスパイク対策になるとは言えないと思います。
- HPA(拡張)とKEDA(拡張)の比較について
HPA→Adapterを介す か KEDA→直接取りに行くというメトリクス収集フローの点で違いがありますが、実際のスケーリングに及ぼす影響は少なく、この二つの間にスケーリング性能の差はほとんどないと考えています。- 実装段階の話になりますが、KEDAは複数のカスタムメトリクスを併用できる点やトリガーとして既に用意があるものはすぐに使用できる点など、設定が柔軟で簡単なため、実装・導入においてはKEDAに軍配が上がると思います。
- cronに関して
予想していた通り、”スパイク対策として唯一有効的である”という結果を取得できました。他のスケーリングと比較して、レイテンシ、エラー率共に改善していることが確認できます。- 最初からスパイクを予測して多めにPodを建てているため、ボトルネックであるPodの起動を解消できている点が強みだと感じています。
- スパイク予測が外れコスト面で大きく損をする可能性を考慮すると、導入する際は費用対効果をしっかりと見積もる必要がありそうです。
以上の結果から、KEDAは従来のHPAスケーリングと比較して、より柔軟かつ豊富な選択肢でスケーリングが可能であると言えます。しかし、KEDAの設計によっては十分なスパイク対策とは言えないため、しっかりとサービスにあった設定を施す必要がありそうです。
KEDAは運用の段階だけではなく、実装の難易度や複雑さも考慮したうえでHPAより優位性があると考えています。
KEDAを導入する際は、期待される効果とコストのバランスを踏まえた上で、十分な工数見積もりを行い、計画的にプロジェクトを進めることが重要だと思います。
反省と今後の課題
スケーリング中のレイテンシ結果も時系列データとして取得するとより分析しやすくなっていたと思います。
補足
複数メトリクスを同時に使用したときの挙動
HPA、KEDAは両者とも複数メトリクスを同時に扱いスケーリングすることがあります。その際は、その中で一番要求Pod数が多かったものを最終結果として扱います。
k6をJobで動かすために使用したコマンド
テストが終了したら、Jobを削除しないと、もう一度applyできない点は注意です。
kubectl delete job -n k6 k6-run --ignore-not-found
kubectl apply -f k6-spike.yaml
kubectl logs -n k6 job/k6-run -f
https://github.com/haitooo/keda_spikeTest/tree/main/k6
KEDAの開発元・運営について
KEDAは当初MicrosoftとRed Hatの共同で開発が始まりました。現在はCloud Native Computing Foundation(CNCF)のインキュベーティングプロジェクトとして管理されています。
また、KEDAはオープンソースプロジェクトです。
今回は触れませんでしたが、KEDAの特徴的な機能としてゼロスケーリングという、Podを0の状態で稼働させておくことができる機能があります。運用コストを見つめ直すためにKEDAの導入を検討する際は調べてみる価値があると思います。
kedifyについて
kedifyはKEDAのエンタープライズ版として提供されているサービスとなっています。UIが付いて作業効率が向上したり、buil-inとして扱えるトリガーも増えているというお話です。
https://kedify.io/?utm_source=keda_oss_site
VPAについて
HPAとは異なる縦方向のスケーリング方法です。HPAはHorizontal(水平)という名前の通り横にコピーを作成するようにスケーリングしていましたが、VPAはVertical(縦方向)でPod1つに割り当てるCPUやメモリ量を調整するスケーリングです。
他の障害パターンについて
よくある障害パターンとして、スパイクの他にフラッピングやストッピング、サチュレーションなど様々なパターンがあると思います。緩やかな波に対してはKEDAは強そう、有効そうだと予想しています。