
はじめに
今回、3-shakeで期限つきインターンをさせていただきました坂内理人(@rihib)と申します。インターン期間中はKubernetes Network Driverと呼ばれるKubernetesのネットワーク周りの新たな機能についての調査を行いました。これまではKubernetesのスケジューラ周りを触ることが多かったのですが、今回新たにネットワーク周りの話を調べることになり、とても勉強になりました。特にKNDはスケジューラ周りでも良く目にしたDRAに関連した機能であったため、DRAによってこれからのKubernetesの姿が大きく変わっていく兆しを感じることができました。
概要
Kubernetesは当初、ステートレスなマイクロサービスアプリケーションを念頭に設計されており、HTTPやgRPCなどの標準的な通信プロトコルを使うWebアプリケーションには非常に適していました。しかし、近年の生成AIや通信事業者の5G/6Gネットワーク機能の仮想化(NFV)などの台頭により、これまでとは異なるワークロードへの対応が求められるようになりました。特にAI/MLの分散学習ジョブのようなHPCワークロードは、ハードウェアの物理的な性能を最大限に引き出すため、トポロジー認識やRDMA通信などの低遅延・高帯域幅の通信が不可欠となっています。
従来のKubernetesでは、Deviceプラグインを使ってRDMAデバイスなどの特殊なハードウェアリソースを管理し、CNIプラグインを使用してネットワーク接続を提供する構成が一般的でした。しかし、AI/MLの分散学習ジョブのような新たなワークロードに対応するにあたって、下記のような課題が存在します。
- トポロジーを考慮できない:従来のスケジューラとDeviceプラグインは、リソースを単なる個 数(整数)として管理します。GPUとNICの物理的な位置関係(NUMAノードやPCIeルートコンプレックスの近接性)を考慮できないため、ワークロードの配置が最適化されず、パフォーマンスが予測不能になる問題を引き起こします。
- 運用コストの増大:高性能ネットワークを実現するために、Multus CNI、SR-IOV Device Plugin、IPAM Pluginなど複数のコンポーネントを組み合わせる必要があり、これらがバラバラに存在することで、設定の整合性を保つのが難しく、障害発生時の切り分けも複雑になります。
- APIサーバーの負荷増大と遅延: Podの起動時にIPアドレス割り当てやネットワーク設定を 行う際、CNIプラグインがAPIサーバーと同期的に通信を行う必要があり、これがPod起動のレイテンシを増大させ、大規模クラスタにおけるスケーラビリティのボトルネックとなっています。
これらの課題を解決するために、Google、Red Hat、NVIDIAなどのエンジニアを中心としたコミュニティによって提唱されたのが、Kubernetes Network Driver (KND) モデルです。KNDは、Kubernetesの新しい拡張APIであるDynamic Resource Allocation (DRA) と Node Resource Interface (NRI) を活用し、NICを設定対象ではなく Kubernetes のリソースとして扱うことで、宣言的かつトポロジーを意識した管理を実現します。
KNDとは?
KNDは単一のソフトウェアではなく、Kubernetesの新しいAPIであるDRAとNRIを組み合わせた設計パターン(モデル)です。
Dynamic Resource Allocation (DRA)
DRAは、従来のDeviceプラグインを置き換えるリソース管理APIです。Deviceプラグインがリソースをnvidia.com/gpu: 1のような単純なカウンターとして扱っていたのに対し、DRAはリソースの属性を定義できます。
- ResourceSlice: ドライバはノード上のデバイスを ResourceSlice オブジェクトとして公開します。ResourceSliceには、ベンダーID、モデル名、PCIバスアドレス、NUMAノードID、サポートするプロトコル(RoCEv2、InfiniBandなど)といった詳細情報が含まれます。
- DeviceClass: ドライバが見つけたデバイスの中から要求するデバイスを、CEL式を用いて条件(ベンダー名やドライバ名など)を指定して定義します。
- ResourceClaim: DeviceClassを用いて要求したいデバイスを指定します。PodはResourceClaimを使用することでデバイスを要求できます。
Kubernetesスケジューラは、ResourceClaim の条件(CEL式)と ResourceSlice の情報を照らし合わせてPodを配置すべき最適なノードを決定します。これにより「NUMAノード1に接続されており、かつリンク速度が200Gbps以上のMellanox NIC」といった複雑な条件指定が可能になります。
Node Resource Interface (NRI)
NRIは、コンテナランタイム(containerd、CRI-O)に対する共通のプラグインインターフェースであり、KNDの実装において物理的なデバイス注入を担当します。
NRIプラグイン(KNDドライバ)は、コンテナのライフサイクルの特定のポイントに介入します。
- CNIがネットワーク設定を行うタイミングとは独立して、KNDはコンテナ作成プロセス(RunPodSandbox および CreateContainer)にフックし、必要なデバイスファイルのマウントや、NICのネームスペース移動を実行します。
- NRIを使用することで、KNDは既存のCNIプラグイン(CalicoやCiliumなど)と競合することなく共存できます。プライマリネットワーク(eth0)はCNIが管理し、ハイパフォーマンス用のセカンダリネットワーク(net1等)はKNDが管理するという役割分担が明確になります。
KNDが想定するハードウェア
RDMA
KNDが主なターゲットとするRDMA (Remote Direct Memory Access) は、CPUを介さずにメモリ間で直接データを転送する技術です。これにより、高スループット、低レイテンシ、低CPU負荷を実現します。
- OSバイパス: アプリケーションはカーネルのTCP/IPスタックを通さず、ユーザー空間から直 接NICハードウェアと通信します。
- ゼロコピー: データはアプリケーションバッファからNICへ直接転送され、余計なメモリコピーが発生しません。
KNDは、このRDMAデバイスファイル(/dev/infiniband/uverbsXなど)を適切にコンテナ内に注入し、かつトポロジー的に最適なNICを選択する役割を担います。これにより、NCCL(NVIDIA Collective Communication Library)などの通信ライブラリがハードウェア性能を最大限に引き出せるようになります。
NUMA アーキテクチャ
現代の高性能サーバーは、複数のCPUソケット(プロセッサ)を搭載し、それぞれのCPUがローカルメモリとPCIeレーンを持っています。これをNUMA(Non-Uniform Memory Access)ノードと呼びます。
- ローカルアクセス: CPUが自身の管理下にあるメモリやPCIeデバイス(GPU、NIC)にアクセスする場合、レイテンシは最小となり帯域幅は最大となります。
- リモートアクセス(クロスNUMA): CPUが別のNUMAノードに接続されたメモリやデバイスに アクセスする場合、CPU間のインターコネクト(Intel UPIやAMD Infinity Fabric)を経由する必要があり、レイテンシが増大し、帯域幅が制限されます。
AI/MLの分散学習においては、GPUメモリからNICへのデータ転送(RDMA通信)が頻繁に発生します。もし、使用するGPUとNICが異なるNUMAノードに接続されている場合、データ転送はインターコネクトを通過する必要があり、これがボトルネックとなります。従来のKubernetesスケジューラは、CPUやメモリの量は計算しても、配置までは考慮できなかったため、偶然に依存した性能のばらつきが発生していました。
従来モデル vs KNDモデル
従来モデル
DeviceプラグインとCNIプラグインを用いた従来モデルの処理の流れは下記のようになります。
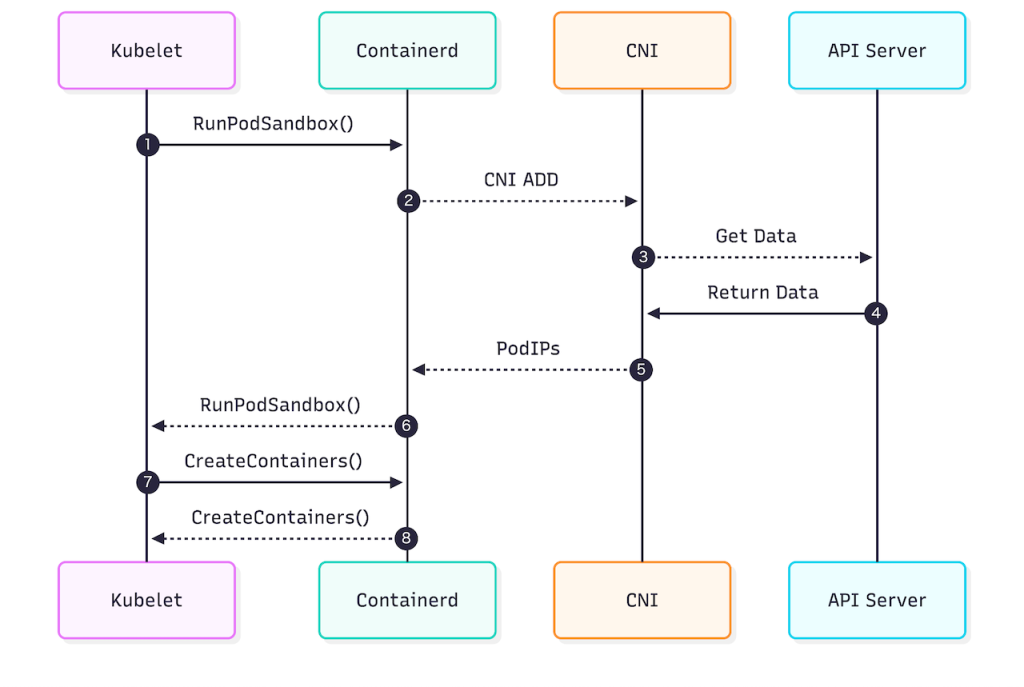
- RunPodSandbox() [Kubelet -> Containerd]: KubeletがPodのサンドボックス作成を指示し ます。
- CNI ADD [Containerd -> CNI]: ランタイム(Containerd)はCNIプラグインを呼び出します。
- PodIPs [CNI -> Containerd]: CNIプラグインはIPアドレスの割り当て、ネットワーク設定、 ルーティングのプログラミングを行います。
- この処理は同期的であり、CNIプラグインの処理が完了するまでPodの起動プロセス全体がブロックされます。特にMultusを用いて複数のインターフェースを設定する場合や、IPAMが外部システムと通信する場合、ここが大きなレイテンシ要因となります。
- RunPodSandbox() return: 設定完了後、Kubeletに制御が戻ります。
- CreateContainers() [Kubelet -> Containerd]: アプリケーションコンテナの作成が開始され ます。
このような従来モデルには下記のような問題があります。
- CNIプラグインは実行時に必要な情報をAPIサーバーなどから収集する必要があり、パ フォーマンスやスケーラビリティの問題が発生します。
- 物理デバイスの配置を考慮してPodをスケジュールすることができません。ネットワーク設定 は事後処理として行われるため、不適切なノードにスケジュールされた後にネットワーク設定が行われることになります。
KNDモデル
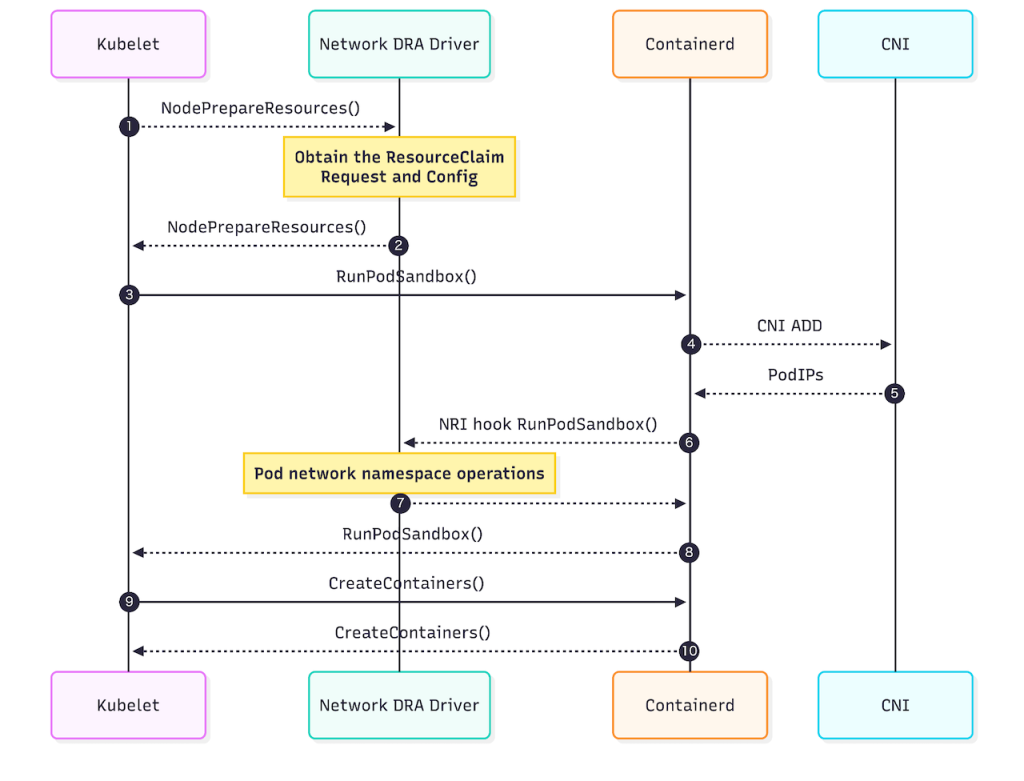
- NodePrepareResources():
- Podがスケジュールされた後、Kubeletは実際のコンテナ起動プロセスに入る前に、 KNDドライバ(DraNetなど)に対してリソースの準備を指示します。
- Kubeletは、スケジューラが決定した ResourceClaim の情報(どのデバイスを使うべきか)をドライバに渡します。ドライバはAPIサーバーに問い合わせる必要がなく、渡された情報だけで準備作業(VFの初期化など)を開始できます。これによりAPIサーバーの負荷とレイテンシが削減されます。
- RunPodSandbox() [Kubelet -> Containerd]: リソース準備完了後、サンドボックス作成が指示されます。
- CNI ADD [Containerd -> CNI]: 従来のCNIによるプライマリネットワーク(eth0)の設定が行われます。
- NRI hook RunPodSandbox():
- サンドボックス(ネットワークネームスペース)が作成された直後、ContainerdはNRIを 通じてKNDドライバを呼び出します。
- Pod network namespace operations: ドライバは、ステップ1で準備しておいた物理インターフェース(またはVF)を、ホストのネームスペースからPodのネームスペースへ移動(ip link set netns)させます。
- RunPodSandbox() return: 制御が戻ります。
- CreateContainers() [Kubelet -> Containerd]: コンテナの作成を指示します。
KNDモデルは従来モデルと比べて下記のメリットがあります。
- 重い初期化処理(VF作成など)を NodePrepareResources で事前に行えるため、Pod起動のクリティカルパスにおける遅延を最小化できます。
- CNIとKNDの役割が明確に分離され、それぞれのライフサイクルを独立して管理できます。
DraNet
KNDモデルの参照実装として、GoogleによってDraNetが開発されました(google/dranet)。現在はKubernetesコミュニティに譲渡されています(kubernetes-sigs/dranet)。
処理の流れ
DraNetは、まず各ノードのDraNetデーモンがNICとそのトポロジ属性(PCIルート、NUMAノード)を発見し、ResourceSlices APIオブジェクトとして公開します。ユーザーがRDMA NICを要求するResourceClaimを作成すると、KubernetesスケジューラはDraNetが提供する属性を利用して最適なノードを見つけます。その後、kubeletがNodePrepareResourcesフックを呼び出し、DraNetがデバイスを準備して、RunPodSandboxでNICをPodの名前空間に移動させます。
これにより、従来はSR-IOV Network Device PluginのようなDeviceプラグインや、RDMA CNIのようなCNIプラグイン、MultusのようなCNIメタプラグインの3つのコンポーネントが必要だった設定が、独立した2つのドライバー(GPU DRAドライバーとDraNetドライバー)によるシンプルな構成で実現できるようになり、運用コストを軽減できるようになります。
実験
DraNetでは「The Kubernetes Network Driver Model: A Composable Architecture for High-Performance Networking」という論文が公開されており、論文では実際にDraNetを使用してTopology aware schedulingを行った際のパフォーマンスを評価する実験を行っています。
この実験では、Google Cloud上でベンチマークが実施され、GPUとRDMA NICが同じPCIルートにあるように意図的に配置されたトポロジを考慮した構成と、Device Pluginを使用してGPUがランダムに割り当てられるトポロジを考慮していない構成の比較を行っています。
結果、トポロジを考慮した構成は、トポロジを考慮していない構成と比較して、平均スループットが非常に高いだけでなく、分散(性能の不安定性)も非常に低いことが証明されました。特に、8GBのメッセージサイズでのNCCL all gatherテストでは、トポロジを考慮した構成がトポロジを考慮していない構成よりもバス帯域幅が最大59.6%向上しました。このことから、従来モデルにおけるトポロジ認識の欠如が、分散ワークロードの大きなパフォーマンス上のボトルネックであることがわかります。
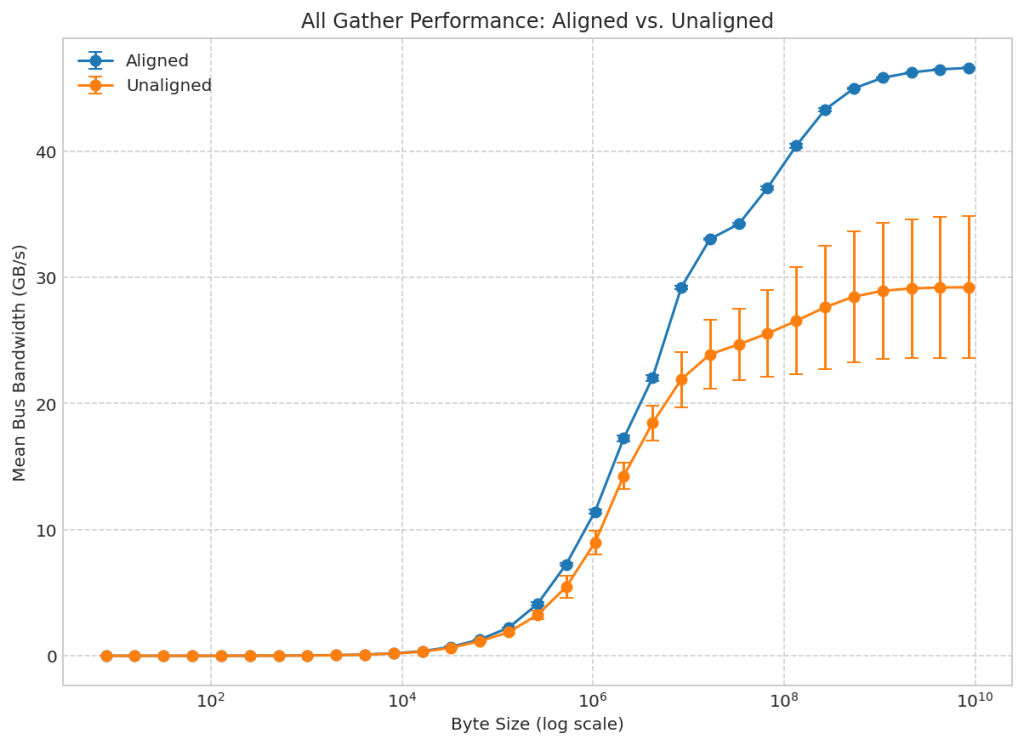
論文では、今後はDraNetを拡張して、NICが特定のNUMAノード上にあるだけでなく、Podのワークロードスレッドをその同じノードのCPUコアにピン留めするCPUのピンニングをサポートし、完全にトポロジを考慮した高性能データパスを提供する予定であると述べています。
DraNetを動かしてみる
Kindを使ってローカルでDraNetを動かすことができます。
1. kindクラスタを作成
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
image: kindest/node:v1.34.0
- role: worker
image: kindest/node:v1.34.0
- role: worker
image: kindest/node:v1.34.0
% kind create cluster --config kind.yaml2. install.yamlでDraNetドライバをDaemonSetとして作成
% kubectl apply -f https://raw.githubusercontent.com/google/dranet/refs/heads/main/install.yaml3.下記のコマンドを使用して、DraNetドライバによって公開されたNICとその属性のリストを 表示(DraNetドライバの作成に時間がかかるので何も表示されない場合はしばらく待っ てから再度実行してみてください)。
% kubectl get resourceslices -o yaml
apiVersion: v1
items:
- apiVersion: resource.k8s.io/v1
kind: ResourceSlice
metadata:
creationTimestamp: "2025-12-11T06:23:05Z"
generateName: kind-control-plane-dra.net-
generation: 2
name: kind-control-plane-dra.net-hwg94
ownerReferences:
- apiVersion: v1
controller: true
kind: Node
name: kind-control-plane
uid: dc8f9f06-9671-424d-a41a-5be1ed11a83d
resourceVersion: "799"
uid: 9504c73b-2e43-4200-b922-7c0ef5f2b64a
spec:
devices:
- attributes:
dra.net/alias:
string: ""
dra.net/ebpf:
bool: false
dra.net/encapsulation:
string: ether
dra.net/ifName:
string: dra0
dra.net/mac:
string: 32:bd:75:60:2d:dc
dra.net/mtu:
int: 1500
dra.net/rdma:
bool: false
dra.net/sriov:
bool: false
dra.net/state:
string: unknown
dra.net/type:
string: dummy
dra.net/virtual:
bool: true
name: dra0
4.ホスト上で仮想NIC(`dra0`)を作るための特権DaemonSetである`dummy-nic`を作成
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: dra-kind-dummy-nic
namespace: kube-system
spec:
selector:
matchLabels:
app: dra-kind-dummy-nic
template:
metadata:
labels:
app: dra-kind-dummy-nic
spec:
hostNetwork: true
serviceAccountName: dranet
tolerations:
- operator: Exists
effect: NoSchedule
containers:
- name: dummy-nic
image: docker.io/library/busybox:stable
securityContext:
privileged: true
command:
- /bin/sh
- -c
- |
set -o errexit
set -o nounset
set -o pipefail
if ! ip link show dra0 >/dev/null 2>&1; then
ip link add dra0 type dummy
fi
ip link set dra0 up
tail -f /dev/null% kubectl apply -f dummy-nic.yaml5.要求デバイスの条件式を書いたDeviceClassを作成
apiVersion: resource.k8s.io/v1
kind: DeviceClass
metadata:
name: dranet-cloud
spec:
selectors:
- cel:
expression: device.driver == "dra.net"% kubectl apply -f deviceclass.yaml6.DeviceClassに合致するデバイスを要求するResourceClaimとPodを作成
apiVersion: resource.k8s.io/v1
kind: ResourceClaim
metadata:
name: cloud-network-dra-net-1
spec:
devices:
requests:
- name: req-cloud-net-1
exactly:
deviceClassName: dranet-cloud
---
apiVersion: v1
kind: Pod
metadata:
name: pod-dra-net1
labels:
app: pod-dra-net1
spec:
containers:
- name: ctr1
image: registry.k8s.io/e2e-test-images/agnhost:2.39
resourceClaims:
- name: net-1
resourceClaimName: cloud-network-dra-net-1% kubectl apply -f resourceclaim.yaml7.Podが要求するデバイスを持つノード( kind-worker)上にスケジュールされる
% kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
NOMINATED NODE READINESS GATES
pod-dra-net1 1/1 Running 0 6s 10.244.1.2 kind-worker <none> <none>
% kind delete cluster8.下記のように確認すると、ResourceClaimが要求した条件を満たすデバイスとして kind-worker から dra0 が割り当てられており、実際に nodeSelector も kind-worker を選択していることがわかります。
% kubectl get resourceclaim cloud-network-dra-net-1 -o jsonpath='{.status.a llocation.devices.results[*].device}'
dra0
% kubectl get resourceclaim cloud-network-dra-net-1 -o jsonpath='{.status.a llocation.devices.results[*].pool}'
kind-worker
% kubectl get resourceclaim cloud-network-dra-net-1 -o jsonpath='{.status.a llocation.nodeSelector}'
{"nodeSelectorTerms":[{"matchFields":[{"key":"metadata.name","operator":"In","value s":["kind-worker"]}]}]}
% kubectl get pod pod-dra-net1 -o jsonpath='{.spec.nodeName}'
kind-workerまとめ
KubernetesがHPCなどの新たなワークロードに対応する上で、KNDは今後重要な役割を担うことが期待されます。まだ開発段階の機能であり、すぐに本番環境へ導入するのは難しいかもしれませんが、今後の動向を注視していく必要があるでしょう。最後までお読みいただき、ありがとうございました。