
はじめに
OpenTelemetry Collector の導入が広がるにつれ、メモリ使用量の高騰という問題が顕在化しやすくなっています。Receiver・Processor・Exporter を組み合わせてパイプラインを定義できますが、パラメータ調整が甘いとメモリ使用量が高騰してしまいます。問題が顕在化するのは負荷が本番レベルに達したときで、そのときにはすでにデータが欠損していることが多いです。
特に監査ログを扱っている場合、重要な情報が欠損する可能性があり無視できません。
対処を難しくしているのは、同じ「メモリ高騰」でも原因構造が一様ではない点です。原因が違えば対処も変わります。原因を特定せずにコンテナのメモリを増やしても根本解決にならないことが多いです。
本記事では Tail Sampling Processor を題材にOTel Collector の内部テレメトリと pprof を使い、メモリ高騰の原因を特定し、パラメータ変更で改善するまでの過程を追います。
検証環境は OpenTelemetry Collector Contrib v0.140.1(2025 年 11 月版)で、コンテナメモリ制限 512MB の環境で実施しました。バージョンによりデフォルト値やメトリクス名が異なる場合があります。
デバッグの基本方法
今回のデバッグでは内部メトリクス(Grafana で可視化)と pprof(heap profile) を中心に使いました。前者で何が起きているかを把握し、後者でなぜ起きているかを具体的にどの関数でメモリが高騰しているのかを掘り下げます。
主要な内部メトリクス
| メトリクス | 何がわかるか |
|---|---|
| otelcol_process_runtime_heap_alloc_bytes | 現在の Heap 使用量。 |
| otelcol_receiver_refused_{spans,metric_points,log_records}_total | Collector がメモリ超過を理由に受信を拒否した回数。継続して発生している場合、クライアントの再送実装次第でデータロスになりうる。 |
| otelcol_exporter_send_failed_{spans,metric_points,log_records}_total | バックエンドへの送信失敗数。リトライがあるためデータロスを直接意味するわけではないが、継続して高い場合はネットワークやバックエンドの問題を示す。 |
| otelcol_exporter_queue_size | Exporter の送信キュー長。otelcol_exporter_queue_capacity と合わせて見ると、キュー逼迫の有無を判断できる |
公式ドキュメントの Monitoring セクション内 Receive failures で、otelcol_exporter_queue_size と otelcol_exporter_queue_capacity は同セクションの Queue length / capacity で挙げられているメトリクスです。
otelcol_process_runtime_heap_alloc_bytes はメモリデバッグの観点から本記事が加えています。加えて、Processor / Connector 固有のメトリクス(otelcol_processor_<name>_*)を Prometheus API で列挙すると、パイプライン内部のどこでデータが滞留しているかを特定できます。
メトリクス名や取得方法の詳細は公式ドキュメント(Internal Telemetry)を参照してください。バージョン間で名前やデフォルト値が変わる可能性があるため、差異がある場合は公式の記述を優先してください。
pprof
メトリクスで「Heap が増えている」ことがわかっても、「どの関数がメモリを確保しているか」まではわかりません。pprof は Go 標準のプロファイリング機能で、heap profile を取得すると、関数ごとのメモリ使用量の内訳を確認できます。
OTel Collector では pprof extension を有効にすると、HTTP endpoint 経由で heap profile を取得できます。
extensions:
pprof:
endpoint: 0.0.0.0:1777
service:
extensions: [pprof]pprof の出力には、主に flat と cum という 2 つの指標があります。
- flat: その関数自身が直接確保したメモリ量
- cum(cumulative): その関数と、そこから呼び出される関数を含めた累積のメモリ使用量
メモリ高騰の原因を追うときは flat だけでなく cum を確認することが重要です。flat が小さくても cum が大きい関数は、呼び出し先を含めた経路全体でメモリを保持しています。
memory_limiter
memory_limiter は Collector のメモリ使用量を監視し、閾値を超えると新規データの受信を拒否する processor です。公式の Recommended Processors の 1 番目に挙げられており、パイプラインの先頭に配置します。
本記事の検証環境では以下の設定を使用しています。
memory_limiter:
check_interval: 1s
limit_percentage: 80
spike_limit_percentage: 20受信拒否が始まる実効閾値(soft_limit)はコンテナメモリ × (limit_percentage - spike_limit_percentage) で計算されます。本環境では512 MB × (80% - 20%) = 307 MB です。Heap がこの値に達すると、Receiver が新規スパンの受信を拒否し始めます。
環境準備
負荷生成
telemetrygen(OpenTelemetry 公式)を使って負荷を生成しています。telemetrygen は OpenTelemetry Collector のデモや動作確認でも使われているテスト用ツールで、gRPC/OTLP プロトコルで Collector にトレースを送信します。
本記事の検証では使用していませんが、参考までに OpenTelemetry 公式のデモ環境である OpenTelemetry Demo には Python/Locust ベースの load-generator サービス も用意されています。これは継続的なリクエストを与えるための負荷生成コンポーネントです。本記事では、より単純に OTLP でトレースを送れる telemetrygen を使用しています。
検証環境
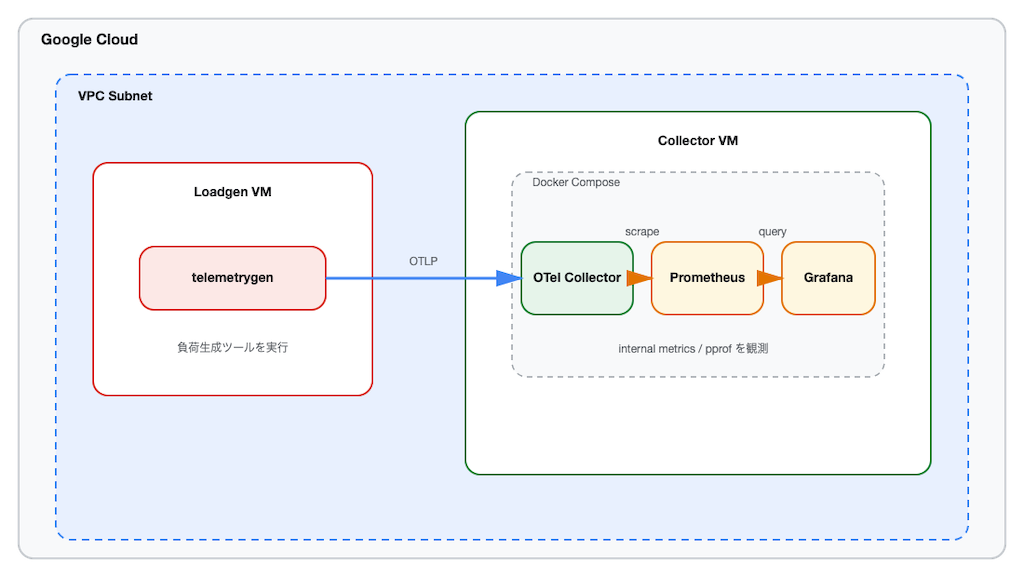
本記事のデータは Google Cloud 上で取得しました。Loadgen VM と Collector VM の 2 インスタンス構成で、負荷生成と Collector を分離しています。本文では、取得済みのメトリクス、pprof、クライアントログをもとに、どのように原因を切り分けたかというデバッグの流れに絞って説明します。同じ環境で再現したい場合は GitHub リポジトリ を参照してください。
キャプチャデータは docs/blog/scenario-reports/tail-sampling/captures/ の non-opt/(修正前)と opt/(修正後)に分かれており、手元で同じ分析を再現できます。
キャプチャデータの構成と読み方
各キャプチャには以下のデータが含まれています。
| パス | 内容 | 用途 |
|---|---|---|
| pprof/ | heap profile(5秒間隔) | go tool pprof で関数ごとのメモリ内訳を分析 |
| metrics/ | Prometheus メトリクスの時系列データ | 数値での傾向確認。_SUMMARY.md にメトリクス一覧あり |
| images/ | Grafana スクリーンショット | 本文中の画像の原本 |
| docker-stats.log | docker stats の定点記録 | Collector を含む各コンテナの CPU / メモリ使用量を横断的に確認 |
| scenario.log | シナリオ実行ログ | 適用した設定、負荷投入、終了時の生成量、待機処理などの実行経過を確認 |
より詳細な分析手順は キャプチャデータの読み方ガイド を参照してください。
各シナリオは複数回実施して傾向を確認した上で、代表的な1回の結果を掲載しています。
実践検証: Tail Sampling
Tail Sampling は、トレースの全スパンが揃ってからサンプリング判定を行う processor です。判定までの待機時間 decision_wait の間、受信したトレースをメモリに保持します。
つまり、decision_wait が長いほど、その間に流入するトレースがすべてメモリに積み上がります。流量が多い環境では、この保持量だけでコンテナのメモリ制限に達しえます。
再現条件
tail_sampling processor を以下の設定で動作させました(設定ファイル)。パイプラインにはbatchも含まれており、pprof でどちらがメモリ消費の主因かを切り分けます。
tail_sampling:
decision_wait: 30s
num_traces: 100000
policies:
- name: always-sample
type: always_sample # 検証用に全トレースをサンプリング
batch:
send_batch_size: 2048
timeout: 1s
service:
pipelines:
traces:
receivers: [otlp]
processors: [memory_limiter, tail_sampling, batch]
exporters: [debug]負荷条件: telemetrygen で 2,500 traces/sec(各トレース 1 root + 10 child = 27,500 spans/sec 相当)を 10 分間投入しました。
telemetrygen traces --otlp-endpoint $(ENDPOINT) --otlp-insecure \\
--rate 2500 --duration 600s --workers 10 --child-spans 10問題の発見(Grafana 観測)
Heap の推移
まずotelcol_process_runtime_heap_alloc_bytes を確認します。
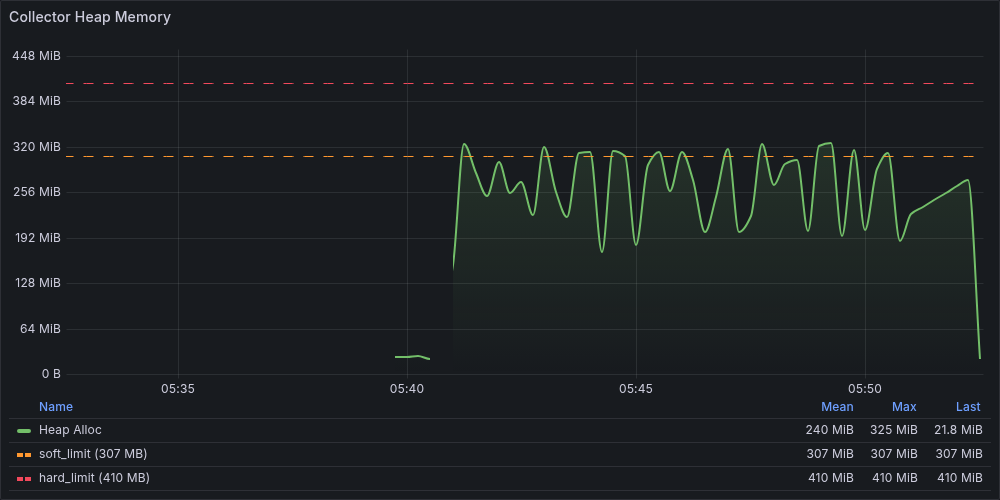
Heap は負荷開始後に soft_limit(307 MB)付近まで上昇しスパイクを繰り返すパターンが続いています。GC によって一時的にメモリは解放されますが、再び上昇し全体として高い水準が維持されています。
Accepted rate の低下
Heap の高止まりだけでは、データに影響が出ているかまでは判断できません。次にrate(otelcol_receiver_accepted_spans_total) を確認します。
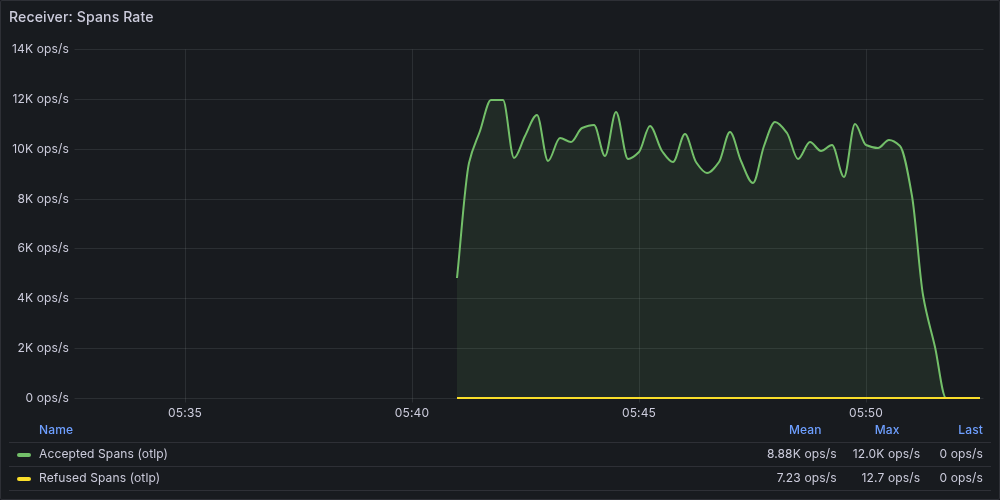
投入量に対して受信レートが低い水準で推移しており、投入したスパンの多くが受信されていないことがわかります。同じグラフに表示されている Refused Spans は 0 ではありませんが微量で、この数値だけでは損失の規模を説明できません。はじめは Refused の少なさから問題は軽微だと考えましたが、実際の受信レートと釣り合いませんでした。
補足: グラフの単位について
このグラフの縦軸はspans/secですが、telemetrygen --rate 2500はtraces/sec指定です。1 トレースあたり 11 spans(1 root + 10 child)なので、理論上の投入量は 27,500 spans/sec になります。また、telemetrygen の実測生成量は理論値の約 6 割(約95万 / 150万 traces)に留まりました。受信レートはこの実送信量に対しても低い水準です。
ここまでの Grafana 観測で「Heap が soft_limit を超えている」「スループットが低下している」「memory_limiter が発火している」ことがわかりました。次は pprof で、何がメモリを消費しているかを特定します。
pprof で原因を特定
Heap がピーク付近のタイミングで取得した heap profile を確認します。
go tool pprof -inuse_space docs/blog/scenario-reports/tail-sampling/captures/non-opt/pprof/heap_144114.pprof
(pprof) top
Showing nodes accounting for 227.18MB, 89.54% of 253.71MB total
Dropped 92 nodes (cum <= 1.27MB)
Showing top 10 nodes out of 84
...表に整理しました(パッケージパスは短縮表記)。
| flat | flat% | cum | cum% | 関数 |
|---|---|---|---|---|
| 117.53 MB | 41.83% | 117.53 MB | 41.83% | pdata/internal.NewSpan |
| 37 MB | 13.17% | 52.50 MB | 18.69% | pdata/internal.CopyKeyValueSlice |
| 16.50 MB | 5.87% | 29 MB | 10.32% | pdata/internal.(*KeyValue).UnmarshalProto |
| 15.50 MB | 5.52% | 15.50 MB | 5.52% | pdata/internal.CopyAnyValue |
| 14.50 MB | 5.16% | 14.50 MB | 5.16% | pdata/internal.NewResourceSpans |
| 13 MB | 4.63% | 13 MB | 4.63% | pdata/internal.NewScopeSpans |
| 12.50 MB | 4.45% | 12.50 MB | 4.45% | pdata/internal.(*AnyValue).UnmarshalProto |
| 6 MB | 2.14% | 35 MB | 12.46% | pdata/internal.(*Span).UnmarshalProto |
| 5.50 MB | 1.96% | 119.02 MB | 42.36% | pdata/ptrace.SpanSlice.AppendEmpty |
| 5 MB | 1.78% | 214.53 MB | 76.35% | tailsampling.processTraces |
大半は pdata/internal パッケージ(Collector の内部データ表現)の関数です。ここからわかるのは「どこでメモリが確保されたか」であり、パイプライン内のどの processor がそれを保持しているかまでは判断できません。batch が原因なのか tail_sampling が原因なのか、flat だけでは切り分けられない状態です。
そこで top -cum に切り替えます。上位には gRPC フレームワーク層の関数も並びますが、ここでは tail_sampling に関係する行だけを抜粋します。
(pprof) top -cum
Showing nodes accounting for 5MB, 1.78% of 280.98MB total
Dropped 128 nodes (cum <= 1.40MB)
Showing top 10 nodes out of 84
...| flat | flat% | cum | cum% | 関数 |
|---|---|---|---|---|
| 0 | 0% | 214.53 MB | 76.35% | tailsampling.(*tailSamplingSpanProcessor).ConsumeTraces |
| 5 MB | 1.78% | 214.53 MB | 76.35% | tailsampling.(*tailSamplingSpanProcessor).processTraces |
processTracesの flat はわずか 5 MB ですが、cum は 214.53 MB(全体の 76%)に達しています。先ほど flat で上位に並んでいたNewSpan やCopyKeyValueSlice は、このprocessTraces の呼び出し経路上で確保されたメモリでした。つまり、pdata のメモリを保持し続けている起点は tail_sampling です。
コールグラフで視覚的に確認します。
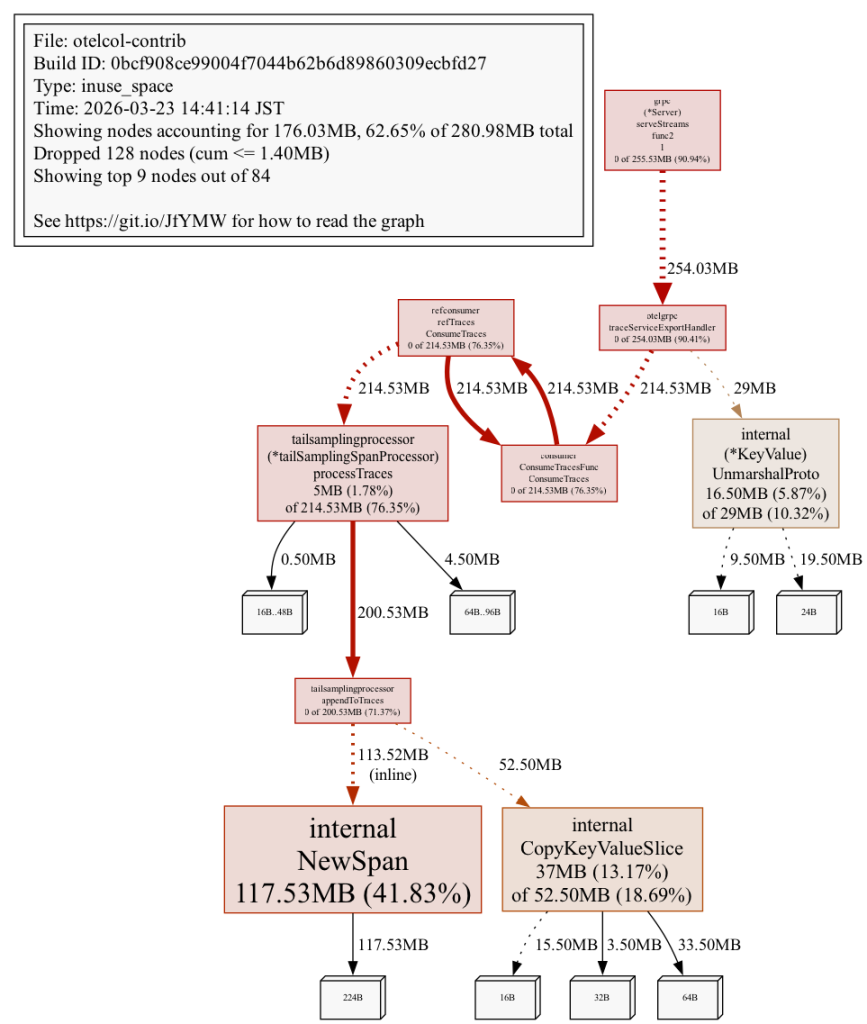
processTraces から NewSpan への太い矢印が、保持の連鎖を示しています。パイプラインには batch も含まれていますが、メモリ消費の大部分は tail_sampling の内部バッファです。
processTraces は Tail Sampling Processor がスパンを受け取ってからサンプリング判定を下すまでの間、データをメモリに保持する処理です。decision_wait=30s の間に到着するすべてのトレースがこのバッファに蓄積されるため、投入レートが高いほどメモリ消費は急激に増加します。
pprof により、メモリを保持している起点が tail_sampling であることは特定できました。ただし、ここでわかるのは原因であって、どれだけのデータが失われたかではありません。Grafana 上の Refused は微量だったため、Collector の内部メトリクスだけでは実害の大きさを判断しきれません。そこで次に、クライアント側のログと生成量を確認し、影響範囲を把握します。
クライアントログの確認
クライアント(telemetrygen)のログを確認すると、以下のエラーが記録されていました。
traces export: exporter export timeout: rpc error: code = Unavailable
desc = data refused due to high memory usagedata refused due to high memory usage は memory_limiter が生成するメッセージです。Collector がメモリ超過を理由に受信を拒否していることがクライアント側からも確認できます。
telemetrygen のログに記録された生成数と、Collector のotelcol_receiver_accepted_spans_total を突合します。
| 指標 | 値 |
|---|---|
| telemetrygen 生成トレース数 | 約95万 traces |
| 生成スパン数 | 約1,049万 spans |
| Receiver Accepted | 約611万 spans |
| 到達率 | 約58% |
注記:
これらの値は telemetrygen のログと Collector のメトリクスから算出した概算値です。集計タイミングのずれや丸めの影響があるため、厳密な一致ではなく傾向を見るための値として扱ってください。
全体の約 42%(~約438 万 spans)が Collector に到達していません。Refused が数件なら欠損も数件だろうと思いましたが、実際には欠損の大部分は Refused ではなくクライアント側の gRPC timeout という形で起きていました。
Refused と実際の損失が大きく乖離する背景として、memory_limiter が拒否した瞬間は Refused カウンタに記録される一方、Collector 側のメモリ圧力に伴うクライアント側の timeout やスループット低下は Collector のメトリクスには現れません。Collector のメトリクスだけを見ていると、損失の規模を見誤る可能性があります。
修正と確認
pprof で tail_sampling の内部バッファがメモリを保持していることが確認できました。保持期間を決めているのはdecision_waitです。30s のままでは投入レートに対して保持期間が長すぎるため、decision_wait を 30s から 5s に短縮して再テストします(フル設定ファイル)。それ以外のパラメータはすべて同一です。
tail_sampling:
decision_wait: 5s # 30s → 5s
num_traces: 100000
policies:
- name: always-sample
type: always_sampledecision_wait の値は、non-opt の pprof 結果から逆算して決めました。メモリ保持量はdecision_wait に比例するため、30s という設定はsoft_limit 付近の設定だったと判断できます。今回はこの processor のデフォルト値 10s よりもさらに短い 5s を選び、soft_limit を明確に下回るように設定しました。
設定値の根拠となった概算
# non-opt の pprof テーブルより
total heap ≈ 280 MB
processTraces ≈ 214 MB (tail_sampling による保持メモリの主因とみなす)
# tail_sampling 以外の ベース を差し引きする
base = total heap - processTraces
= 280 - 214
= 66 MB
# 1 秒あたりの蓄積速度の目安
蓄積速度 = processTraces ÷ decision_wait
= 214 ÷ 30
≈ 7.1 MB/s
# soft_limit(307 MB)内に収まる decision_wait の目安
decision_wait ≈ (soft_limit - base) ÷ 蓄積速度
= (307 - 66) ÷ 7.1
= 241 ÷ 7.1
≈ 33s同じ近似で見積もると、10s では total heap は約 138 MB、5s では約 102 MB となります。どちらも soft_limit は下回りますが、今回は改善をより確実に確認するため 5s を採用しました。
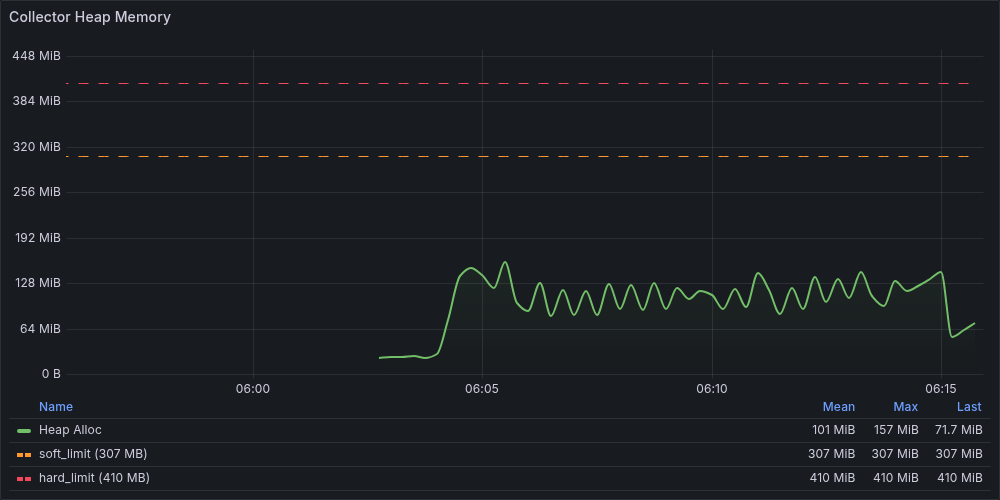
Heap は soft_limit を大きく下回る水準で安定しており、memory_limiter は一度も発火していません。
Receiver Spans Rate も確認します。
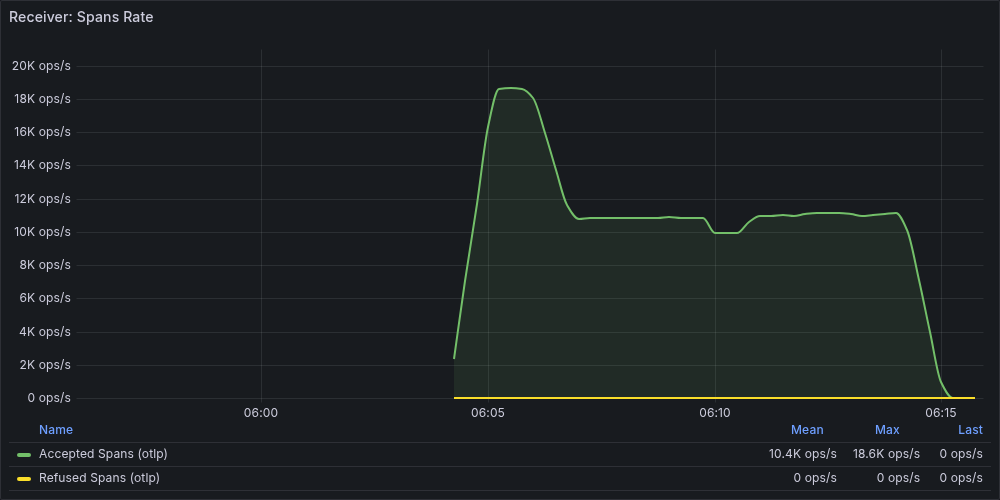
non-opt で見られた受信レートの低下が解消され安定しています。
non-opt と同様にクライアント側を確認すると、gRPC エラーは 0 件でした。生成数と Accepted の結果を non-opt と対比します。
| 指標 | non-opt (30s) | Opt (5s) |
|---|---|---|
| 生成スパン数 | 約1,049万 | 約733万 |
| Receiver Accepted | 約611万 | 約732万 |
| 到達率 | 約58% | ほぼ100% |
| クライアント gRPC エラー | あり | なし |
注記:
non-opt と opt では telemetrygen の生成スパン数自体に差がありました。これは telemetrygen の実効生成レートが一致していなかったためで、今回の比較では絶対生成数そのものではなく、生成数に対する Collector 到達率と gRPC エラーの有無を主に評価しています。
non-opt で 42% あった欠損が、decision_wait の短縮により解消されています。Collector のメモリ問題を修正したことで、クライアント側の損失も同時になくなりました。
ただし 5s はこの検証環境で有効だった値であり、すべての環境に適用できるわけではありません。decision_wait を短縮すると到着が遅いスパンを取りこぼす可能性があります。例えば複数サービスを経由するリクエストでは各サービス間のネットワーク遅延や API の処理待ちが積み重なり、スパンの到着に数秒以上かかることがあります。5s 以内に全スパンが揃わないケースも起こりえるため、自身の環境でのスパン遅延を把握した上で値を設定することが重要です。
pprof でも改善を確認します(docs/blog/scenario-reports/tail-sampling/captures/opt/pprof/heap_150600.pprof)。tail_sampling に関係する行のみ抜粋します。
(pprof) top -cum
Showing nodes accounting for 14MB, 13.74% of 101.90MB total
Dropped 40 nodes (cum <= 0.51MB)
Showing top 10 nodes out of 112
...| flat | flat% | cum | cum% | 関数 |
|---|---|---|---|---|
| 0 | 0% | 72.01 MB | 70.67% | tailsampling.(*tailSamplingSpanProcessor).ConsumeTraces |
| 14 MB | 13.74% | 72.01 MB | 70.67% | tailsampling.(*tailSamplingSpanProcessor).processTraces |
non-opt と対比します。
| 指標 | non-opt (30s) | Opt (5s) |
|---|---|---|
| processTraces cum | 約1,049万 | 72.01 MB (71%) |
| total heap | 280.98 MB | 101.90 MB |
cum の割合は依然として高いですが、絶対量は 180 MB から 58 MB と 3 分の 1 以下に減少しています。total も 280 MB から 101 MB に縮小しました。バッファの保持期間が短くなったことで、同時にメモリ上に存在するトレース数が減った結果です。
まとめ
最終的な修正は decision_wait: 30s を 5s に変えるだけでした。ただ、そこに辿り着くまでに Grafana、pprof、クライアントログという 3段階の確認が必要でした。
Grafana の Heap パネルで異常に気づくことはできます。しかし Collector 内部のどの processor がメモリを圧迫しているかは Grafana だけではわかりません。pprof の top -cum で初めて processTraces が保持の起点だと特定できました。また、今回は telemetrygen を使っていたため、Collector の外側の状況はクライアントログを手がかりに確認しました。 Collector のメトリクス上は Refused が微量であるにもかかわらず、クライアント側では約 4 割のデータが消失していました。
この結果から、メモリ高騰時の影響を把握するには、Collector 内部のメトリクスや pprof だけでなく、送信側や下流側のような Collector 外の観測点も併せて確認する必要があることがわかりました。
実運用では複数の観測点をダッシュボードやアラートとして整備しながら継続的に更新し、pprof や Collector 外も参照できる状態にしておくことで、メモリ高騰時の対応が進めやすくなると思います。
なお、本記事の検証は tail_sampling + batch + debug exporter という最小構成で実施しています。本番環境では複数の processor や外部バックエンドへの exporter が加わるため、メモリ消費のパターンはより複雑になります。ここで示した診断フローはメモリ高騰をデバッグする際の出発点になると思いますが、環境に応じて異なる点に注意してください。