
1. はじめに
「先月の売上を部門別に見せてほしい」「ECサイト経由の注文数の推移を出して」— データチームにはこうした分析依頼が日々寄せられます。依頼のたびにSQLを書いて結果を返す、という対応を繰り返しているチームも多いのではないでしょうか。
今回紹介するCortex Analystを利用することで自然言語の質問をSQLクエリに自動変換し、Snowflake上で実行して結果を返してくれる仕組みです。つまり、ビジネスユーザーが自分でデータに問い合わせられるようになります。
データエンジニアの立場で見ると、これは「分析依頼のセルフサービス化」を意味します。セットアップさえ整えれば、定型的な分析依頼への対応負荷を大幅に減らせる可能性があります。本記事では、Cortex Analystの仕組みと構築手順を紹介し、実際に自然言語で質問してどの程度使えるのかを検証します。
2. Cortex Analystとは
概要
Cortex Analystは、自然言語の質問をSQLクエリに変換し、Snowflake上の構造化データから回答を返すフルマネージドサービスです。Meta Llama やMistral Largeなどの最先端LLMを搭載しており、REST APIを通じてあらゆるアプリケーションに統合できます。
Snowflake Cortex AIスタックの中では「最先端の検索」レイヤーに位置し、構造化データの検索を担当します。非構造化データの検索を担うCortex Searchと対になる存在です。
仕組み — 質問からSQLができるまで
Cortex Analystが質問を受けてから回答を返すまでの流れは、大きく4つのステップで構成されています。
ステップ1:リクエスト ユーザーの質問とセマンティックモデル(後述)をCortex AnalystのREST APIへ送信します。
ステップ2:質問の理解と補強 分類エージェントが質問に回答可能かどうかを判断します。回答可能な場合は、質問を追加のエージェントで補強します。回答不可の場合は、類似する質問を提示してくれます。
ステップ3:SQL生成とエラー修正 複数のSQL生成エージェントが並列で動作し、それぞれがSQLクエリを生成します。エラー修正エージェントがSQLをチェック・修正した後、統合エージェントが最適なSQLクエリを選定します。
ステップ4:レスポンス 生成されたSQLクエリと質問の解釈がAPIの応答として返されます。クエリを実行すれば最終結果が得られます。
内部で複数のエージェントが協調して動いている点が特徴的です。1つのLLMがSQLを生成するだけではなく、分類・補強・生成・修正・統合という多段階のプロセスを経ることで、精度を高めています。
利用方法
Cortex Analystを使うには主に2つの方法があります。REST APIを介して自社アプリケーションやStreamlitアプリに統合する方法と、Snowflake IntelligenceのUIから直接自然言語で質問する方法です。いずれの場合も、次章で説明するセマンティックモデルの準備が前提となります。
3. 精度の鍵 — セマンティックモデル
セマンティックモデルとは
Cortex Analystの精度を左右する最も重要な要素が、セマンティックモデルです。
セマンティックモデルとは、テーブルやカラムの意味、ビジネス固有の用語、メトリクスの計算方法などを定義したメタデータです。たとえば「売上」という言葉が、実際にはどのテーブルのどのカラムの、どういう計算式で求められるのか。「店舗エリア」はstore_regionカラムのことなのか。こうした対応関係をセマンティックモデルで定義しておくことで、Cortex Analystは自然言語の質問を正確なSQLに変換できるようになります。
逆に言えば、セマンティックモデルが不十分だと、どれだけ高性能なLLMを使っても正確なSQLは生成されません。
セマンティックビュー — データベース内にネイティブ保持
従来、セマンティックモデルはステージ上に保存されたYAMLファイルとして管理されていました。現在はセマンティックビューというスキーマレベルのオブジェクトとして、データベース内にネイティブに保持できるようになっています。
セマンティックビューには以下の要素を定義します。
テーブル概念(Logical Table Concepts):分析対象のテーブルとその説明。たとえば「Store Sales:実店舗の売上トランザクション」のように、テーブルが何を表すかを記述します。
メトリクス:ビジネス上の指標と計算式の定義。たとえば total_net_revenue = SUM(store_sales_net_revenue) + SUM(web_sales_net_revenue) のように、カラムの合計や計算ロジックを定義します。
ディメンション:分析の切り口となる軸。store_region(店舗エリア)、store_district(店舗地区)などです。
シノニム(同義語):同じ意味の異なる表現を結びつける定義。「売上」「revenue」「売上高」を同一視させるために使います。日本語環境ではこの定義が特に重要です。
リレーションシップ:テーブル間の結合条件。customer_to_store_sales のような結合関係を定義します。
セマンティックオートパイロット
セマンティックモデルの構築は本来手間のかかる作業ですが、Cortex Analystにはセマンティックオートパイロットという自動生成機能があります。既存のSnowflakeダッシュボード、クエリ履歴、Tableauデータソース、PDFドキュメントなどのコンテキストを読み込み、セマンティックモデルを自動で推論・生成してくれます。
Snowsight上で Cortex Analyst → Create Semantic Model と進み、既存のコンテキストを指定するだけで利用できます。数ヶ月かかる手動モデリング作業を数分に短縮できる可能性があり、導入のハードルを大きく下げる機能です。
本記事では手動によるセマンティックビューにて構築しています。
4. 実際に構築してCortex Analyst使ってみた
事前準備
検証用に、店舗マスタ(5店舗)、商品マスタ(5商品)、売上トランザクション(20件、2025年1〜3月)の3テーブルを用意し、セマンティックビューを作成しました。
-- ============================================
-- 1. スキーマ作成
-- ============================================
CREATE SCHEMA IF NOT EXISTS DEMO_DB.CORTEX_ANALYST_DEMO;
USE SCHEMA DEMO_DB.CORTEX_ANALYST_DEMO;
-- ============================================
-- 2. サンプルデータ作成(売上分析用)
-- ============================================
-- 店舗マスタ
CREATE OR REPLACE TABLE stores (
store_id INT,
store_name STRING,
store_region STRING,
store_type STRING
);
INSERT INTO stores VALUES
(1, '渋谷店', '関東', '直営'),
(2, '梅田店', '関西', '直営'),
(3, '名古屋店', '中部', 'FC'),
(4, '福岡店', '九州', 'FC'),
(5, '札幌店', '北海道', '直営');
-- 商品マスタ
CREATE OR REPLACE TABLE products (
product_id INT,
product_name STRING,
category STRING,
unit_price NUMBER(10,0)
);
INSERT INTO products VALUES
(101, 'ノートPC', '電化製品', 120000),
(102, 'ワイヤレスイヤホン', '電化製品', 15000),
(103, 'オーガニック野菜セット', '食品', 3000),
(104, 'プレミアムコーヒー豆', '食品', 2500),
(105, 'ランニングシューズ', 'スポーツ', 18000);
-- 売上トランザクション
CREATE OR REPLACE TABLE sales (
sale_id INT,
sale_date DATE,
store_id INT,
product_id INT,
quantity INT,
sales_amount NUMBER(12,0),
channel STRING
);
INSERT INTO sales VALUES
-- 2025年1月
(1, '2025-01-05', 1, 101, 2, 240000, 'store'),
(2, '2025-01-08', 1, 103, 10, 30000, 'store'),
(3, '2025-01-10', 2, 102, 5, 75000, 'store'),
(4, '2025-01-12', 2, 104, 20, 50000, 'online'),
(5, '2025-01-15', 3, 105, 3, 54000, 'store'),
(6, '2025-01-20', 4, 101, 1, 120000, 'online'),
(7, '2025-01-25', 5, 103, 15, 45000, 'store'),
(8, '2025-01-28', 1, 105, 4, 72000, 'online'),
-- 2025年2月
(9, '2025-02-03', 1, 101, 3, 360000, 'store'),
(10, '2025-02-05', 2, 103, 8, 24000, 'store'),
(11, '2025-02-10', 3, 102, 6, 90000, 'online'),
(12, '2025-02-14', 4, 104, 25, 62500, 'store'),
(13, '2025-02-18', 5, 105, 2, 36000, 'store'),
(14, '2025-02-22', 1, 102, 10, 150000, 'online'),
(15, '2025-02-28', 2, 101, 2, 240000, 'store'),
-- 2025年3月
(16, '2025-03-02', 3, 103, 12, 36000, 'store'),
(17, '2025-03-05', 4, 105, 5, 90000, 'online'),
(18, '2025-03-10', 5, 101, 1, 120000, 'store'),
(19, '2025-03-15', 1, 104, 30, 75000, 'store'),
(20, '2025-03-20', 2, 102, 8, 120000, 'online');
-- ============================================
-- 3. セマンティックビューの作成
-- ============================================
CREATE OR REPLACE SEMANTIC VIEW DEMO_DB.CORTEX_ANALYST_DEMO.sales_analysis_sv
TABLES (
sales_tbl AS DEMO_DB.CORTEX_ANALYST_DEMO.SALES
PRIMARY KEY (SALE_ID)
COMMENT = '売上トランザクションテーブル。各販売取引の詳細を保持',
stores_tbl AS DEMO_DB.CORTEX_ANALYST_DEMO.STORES
PRIMARY KEY (STORE_ID)
COMMENT = '店舗マスタ。店舗の基本情報を保持',
products_tbl AS DEMO_DB.CORTEX_ANALYST_DEMO.PRODUCTS
PRIMARY KEY (PRODUCT_ID)
COMMENT = '商品マスタ。商品の基本情報と価格を保持'
)
RELATIONSHIPS (
sales_to_stores AS sales_tbl (STORE_ID) REFERENCES stores_tbl,
sales_to_products AS sales_tbl (PRODUCT_ID) REFERENCES products_tbl
)
DIMENSIONS (
sales_tbl.sale_date AS SALE_DATE
COMMENT = '販売日',
sales_tbl.channel AS CHANNEL
WITH SYNONYMS ('チャネル', '販路')
COMMENT = '販売チャネル。storeは実店舗、onlineはEC',
stores_tbl.store_name AS STORE_NAME
WITH SYNONYMS ('店舗', '店名')
COMMENT = '店舗名',
stores_tbl.store_region AS STORE_REGION
WITH SYNONYMS ('エリア', '地方', 'region')
COMMENT = '地域',
stores_tbl.store_type AS STORE_TYPE
WITH SYNONYMS ('種別', '業態')
COMMENT = '店舗種別。直営またはFC(フランチャイズ)',
products_tbl.product_name AS PRODUCT_NAME
WITH SYNONYMS ('商品', '製品')
COMMENT = '商品名',
products_tbl.category AS CATEGORY
WITH SYNONYMS ('カテゴリ', '分類')
COMMENT = '商品カテゴリ',
products_tbl.unit_price AS UNIT_PRICE
WITH SYNONYMS ('定価', '価格')
COMMENT = '単価(税込)'
)
METRICS (
sales_tbl.total_sales AS SUM(SALES_AMOUNT)
WITH SYNONYMS ('総売上', '合計売上', 'total revenue')
COMMENT = '売上合計金額',
sales_tbl.total_quantity AS SUM(QUANTITY)
WITH SYNONYMS ('合計数量', '総数')
COMMENT = '総販売数量',
sales_tbl.avg_sales_per_transaction AS AVG(SALES_AMOUNT)
WITH SYNONYMS ('客単価', '平均売上')
COMMENT = '1取引あたりの平均売上金額'
)
COMMENT = '店舗売上分析用のセマンティックビュー';
-- ============================================
-- 4. 動作確認
-- ============================================
-- テーブルの確認
SELECT * FROM stores;
SELECT * FROM products;
SELECT * FROM sales ORDER BY sale_date;
-- セマンティックビューの確認
DESCRIBE SEMANTIC VIEW sales_analysis_sv;セマンティックビューのポイントは、各ディメンションとメトリクスにCOMMENT(説明)とSYNONYMS(同義語)を定義している点です。たとえばSTORE_REGIONには「エリア」「地方」「region」を同義語として登録しており、「地域別の売上」でも「エリア別の売上」でも正しく解釈されます。
作成後、SnowsightのCortexアナリスト画面(AIとML > Cortexアナリスト)でセマンティックビューを指定し、右側のプレイグラウンドから自然言語で質問を投げて検証しました。
質問と結果
難易度を段階的に上げて4つの質問を試しました。代表的な結果を紹介します。
Q1: 「売上合計はいくらですか?」(簡単:単一テーブル集計)
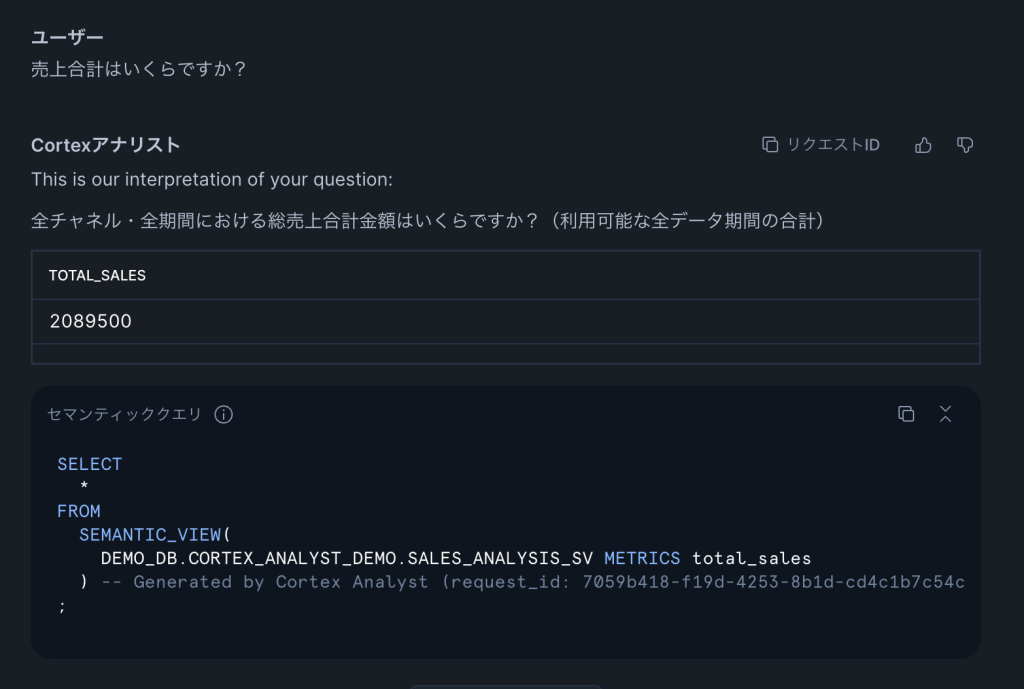
セマンティックビューで定義したtotal_salesメトリクスがそのまま使われ、正しい結果が返りました。
Q2: 「2月の売上を教えてください」(曖昧な質問)
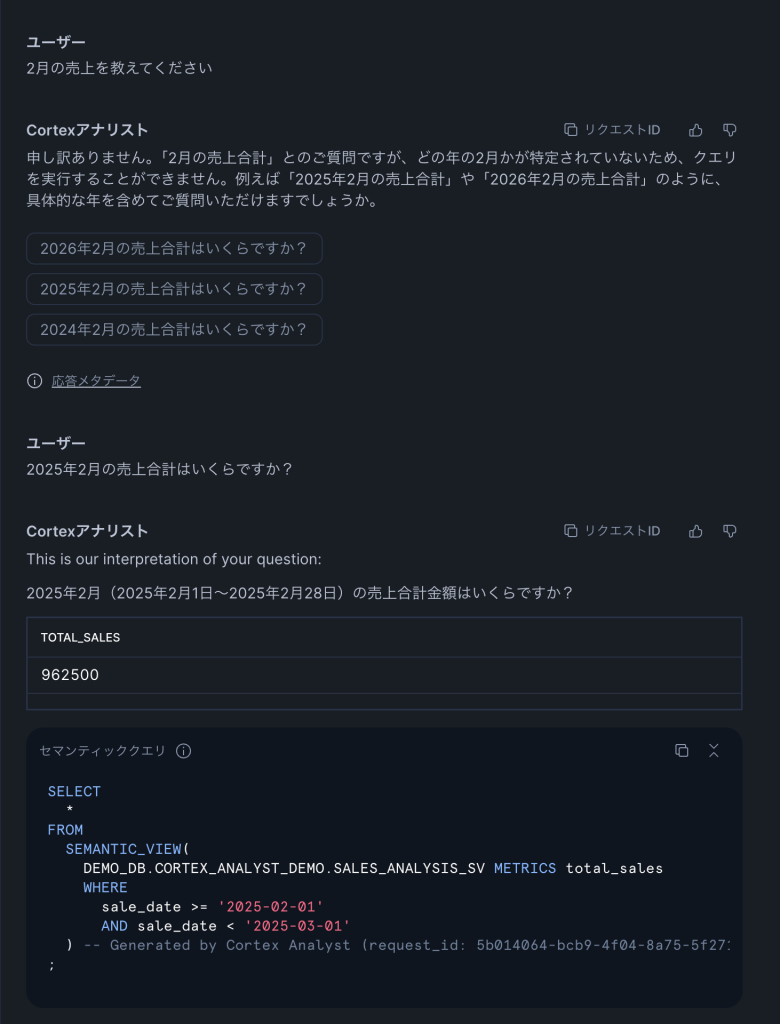
ここで面白い挙動が見られました。Cortex Analystは直接回答せず、「どの年の2月か特定されていないため、クエリを実行することができません」と返し、以下の候補を提示しました。
「2025年2月の売上合計はいくらですか?」を選択すると、WHERE句で日付範囲を正しく絞ったSQLが生成され、962,500円という正確な結果が返りました。曖昧な質問に対して推測で回答するのではなく、確認を求めてくれる安全設計です。
Q3: 「地域別の売上を見せてください」(中程度:テーブル結合)
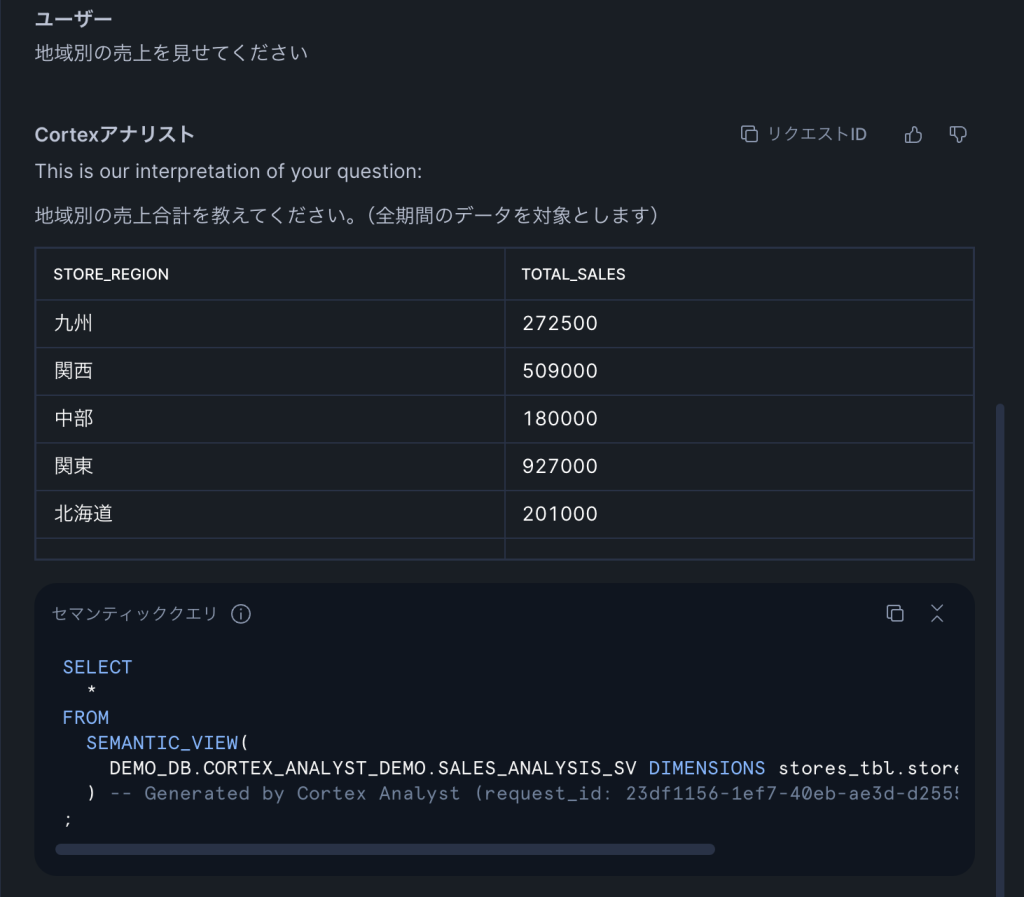
「地域別」という日本語から、storesテーブルのSTORE_REGIONディメンションを自動で選択し、salesテーブルとの結合も自動で行っています。セマンティックビューにリレーションシップを定義しておいたことで、テーブル結合の指定なしに正しいJOINが生成されました。
Q4: 「オンライン経由の月別売上推移を教えてください」(複雑:結合+集約+条件)
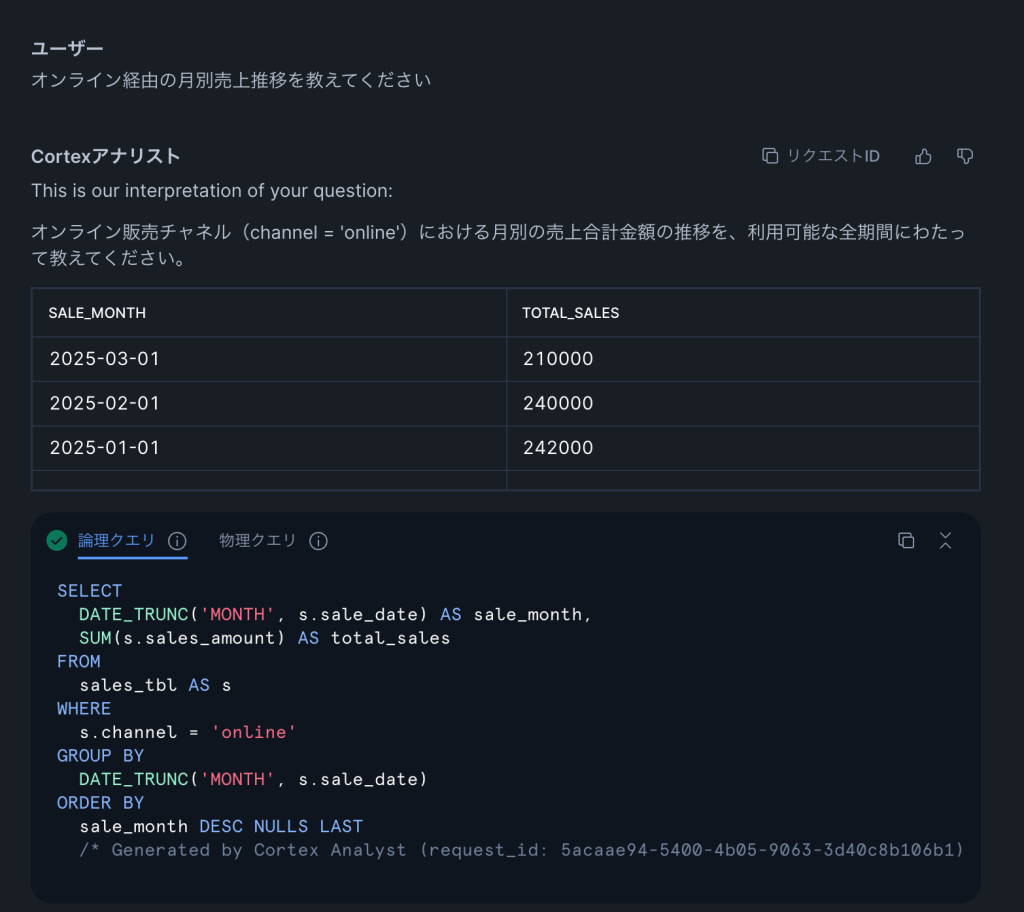
ユーザからの曖昧な質問はCortex Analystの解釈が表示されます「オンライン販売チャネル(channel = ‘online’)における月別の売上合計金額の推移を、利用可能な全期間にわたって表示してください。」
「オンライン経由」をchannel = ‘online’に変換し、「月別推移」をDATE_TRUNC + GROUP BYで表現しています。自然言語の1文から、WHERE、GROUP BY、ORDER BYを正しく組み合わせたSQLを生成できている点は注目に値します。
5. 試してわかったこと
セマンティックモデルの設計が精度に直結する
今回の検証では、すべての質問に対して正確な回答(または回答できない旨の応答)が得られました。これはセマンティックビューにCOMMENT、SYNONYMS、メトリクス、リレーションシップを丁寧に定義したことが大きいです。
特にSYNONYMS(同義語)の効果は顕著でした。「地域別」という質問がSTORE_REGIONに正しくマッピングされたのは、シノニムに「エリア」「地方」を登録しておいたからです。逆に言えば、シノニムの定義が不足していると「その質問は理解できません」という結果になる可能性があります。セマンティックモデルの設計にどれだけ手間をかけるかが、Cortex Analystの精度をほぼ決定すると感じました。
曖昧さへの対応が賢い
「2月の売上を教えて」に対して「どの年の2月か?」と確認を求め、「来月の売上を予測して」に対して「SQLでは対応できない」と明確に回答する。この「わからないことをわからないと言える」設計は、ビジネスユーザーに安心して使ってもらうために重要です。誤った結果を自信満々に返されるよりも、確認を求めてくれる方が実務では信頼できます。
データエンジニアの役割が変わる
Cortex Analystを導入すると、データエンジニアの仕事は「SQLを書いて渡す」から「セマンティックモデルを整備・運用する」にシフトします。定型的な「○○別の売上を教えて」のような依頼はビジネスユーザーがセルフサービスで解決でき、データエンジニアはモデルの精度向上や新しい分析軸の追加に注力できるようになります。
ただし、セマンティックモデルの初期構築には相応の労力が必要です。テーブルの意味、メトリクスの定義、同義語の洗い出しなど、データに対する深い理解が求められます。セマンティックオートパイロット機能を活用すれば既存のダッシュボードやクエリ履歴から自動生成できますが、生成されたモデルのレビューと調整は人の手が必要です。
6. まとめ
Cortex Analystは、自然言語の質問をSQLに変換することで、ビジネスユーザーが直接データと対話できる環境を実現します。今回の検証では、簡単な集計から複数テーブルの結合を含む複雑な分析まで、正確なSQLを生成してくれることを確認しました。曖昧な質問や回答不可の質問に対する応答も適切で、実務で使える品質だと感じます。
導入を検討する場合は、まず小さなスコープ(1〜2テーブル)でセマンティックビューを作成し、よく受ける分析依頼の質問を試してみるところから始めるのがおすすめです。精度はセマンティックモデルの設計に大きく依存するため、シノニムやメトリクスの定義を丁寧に行うことが成功の鍵です。