
はじめに
2021年スリーシェイクに入社してから案件で BigQuery を触ったのをきっかけに、Google BigQuery: The Definitive Guideを読んだので本の内容を一部紹介します。
10章までありますが、個人的に勉強になった内容を抜粋して紹介します。

Chapter 2: Query Essentials
SQL を書いているとサブクエリを使いたいケースが出てきます。今回は BigQuery が一般公開しているデータセットを使用した、サンプルを紹介します。
Subqueries with WITH (p30)
野球のゲームの開始時間、ホームチーム名、アウェイチーム名、球場名を、SELECT 句の中にサブクエリを使って出力しています。
SELECT
startTime,
homeTeamName,
awayTeamName,
(
SELECT
DISTINCT venueName
FROM
`bigquery-public-data.baseball.games_wide` AS Game
WHERE
Schedules.gameId = Game.gameId ) AS venueName
FROM
`bigquery-public-data.baseball.schedules` AS Schedules
+---------------------+--------------+--------------+------------------------------+
| startTime | homeTeamName | awayTeamName | venueName |
+---------------------+--------------+--------------+------------------------------+
| 2016-06-26 17:10:00 | Marlins | Cubs | Marlins Park |
| 2016-06-25 20:10:00 | Marlins | Cubs | Marlins Park |
| 2016-06-11 20:10:00 | Braves | Cubs | Turner Field |
| 2016-06-12 17:35:00 | Braves | Cubs | Turner Field |
| 2016-06-08 17:05:00 | Phillies | Cubs | Citizens Bank Park |次は、野球の結果を表示するために FROM 句にサブクエリを使って出力しています。
SELECT
startTime,
homeTeamName,
awayTeamName,
Game.homeFinalRuns,
Game.awayFinalRuns
FROM
`bigquery-public-data.baseball.schedules` AS Schedules,
(
SELECT
DISTINCT gameId,
homeFinalRuns,
awayFinalRuns
FROM
`bigquery-public-data.baseball.games_wide` ) AS Game
WHERE
Schedules.gameId = Game.gameId
+---------------------+--------------+--------------+---------------+---------------+
| startTime | homeTeamName | awayTeamName | homeFinalRuns | awayFinalRuns |
+---------------------+--------------+--------------+---------------+---------------+
| 2016-06-26 17:10:00 | Marlins | Cubs | 6 | 1 |
| 2016-06-25 20:10:00 | Marlins | Cubs | 9 | 6 |
| 2016-06-11 20:10:00 | Braves | Cubs | 2 | 8 |
| 2016-06-12 17:35:00 | Braves | Cubs | 2 | 13 |以上のようにサブクエリを使うことで、テーブルを組み合わせてデータを表現することができました。
しかし、サブクエリの記述量が多かったり、ネストするクエリの数が増えると読みづらくなることが想像できます。
そんな読みづらさを解消するためには、 WITH を使用します。
先ほどの SELECT 句に書いたクエリと FROM 句に書いたクエリをそれぞれ、WITH 句を使用して書き直してみます。
WITH
Game AS (
SELECT
DISTINCT gameId,
venueName
FROM
`bigquery-public-data.baseball.games_wide` )
SELECT
startTime,
homeTeamName,
awayTeamName,
Game.venueName
FROM
`bigquery-public-data.baseball.schedules` AS Schedules,
Game
WHERE
Schedules.gameId = Game.gameIdWITH
Game AS (
SELECT
DISTINCT gameId,
venueName
FROM
`bigquery-public-data.baseball.games_wide` )
SELECT
startTime,
homeTeamName,
awayTeamName,
Game.venueName
FROM
`bigquery-public-data.baseball.schedules` AS Schedules,
Game
WHERE
Game.gameId = Schedules.gameIdWITH 句を使うことで、クエリを上から下へ読めるようになります。
サブクエリを使った場合よりも可読性が高まったのではないでしょうか?
WITH 句は、主に可読性を高めるために役立ちます。
参照: WITH句
💡 Tips: クエリを書くとき、サブクエリではなく、WITH 句の使用を検討する
📝 Memo: 共通テーブル式 Common Table Expression (CTE)
結果に対して一時的な名前を付与すること。CTE はサブクエリ、ビュー、ユーザー定義関数の代わりであると考えられています。
参照: Common table expression – wiki
各 CTE は、サブクエリの結果をテーブル名にバインドします。
参照: WITH 句
Chapter 5: Developing with BigQuery
Parameterized queries (p157)
続いては5章に書いてあったパラメータ化されたクエリです。
各言語には文字列に変数を展開する機能がありますが、使わない方が良いです。理由は SQL インジェクションを未然に防ぐことに繋がるからです。以下は Typescript を使った例です。
ダメな例
const userId = "aaa"
const query = `
SELECT *
FROM table
WHERE user.id = ${userId}
`
console.log(query)良い例
変数を入れたいなら、 @ から始まる名前付きパラメータを使用してください。
const userId = "aaa"
const query = `
SELECT *
FROM table
WHERE user.id = @userId
`
console.log(query)パラメータはリクエストを投げるときに、クエリと一緒に渡します。
{
query,
useLegacySql: false,
queryParameters: [
{
name: "userId",
parameterType: { type: "STRING" },
parameterValue: { value: userId },
}
]
}Chapter 7: Optimizing Performance and Cost (p229)
BigQuery の料金は、以下のように分類されています。
- 分析料金
1.オンデマンド料金
2.定額料金 - ストレージ料金
BigQuery のオンデマンド分析では、クエリでスキャンされたデータ量に対して料金が発生する仕組みになっています。一般的に、スキャンするデータ量を減らすことができれば、クエリ速度の向上も期待できます。
Controlling Cost (p230)
書いたクエリの費用を計算する方法は以下の手順で知ることができます。
Estimating per-query cost
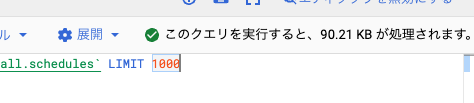
1.クエリによって処理されるデータ量を調べる
BigQuery の Web コンソールには、クエリ実行によって読み取られるデータ量が表示されます。bqコマンドだと --dry-run オプションがあります。
2.料金計算ツールを使って BigQuery の料金を計算する。
関連:
💡 Tips:
bq queryコマンドのオプションには、 --maximim_bytes_billed というオプションがあり、これを使うと処理したデータが指定した量以上になった場合、エラーを返して実行を止めることができます。 (料金は発生しません)
コンソールにも設定があります。
展開 > クエリ設定 > 詳細オプション > 課金される最大バイト数 を設定します。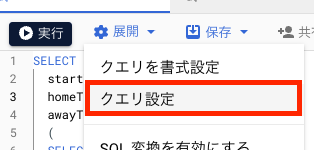
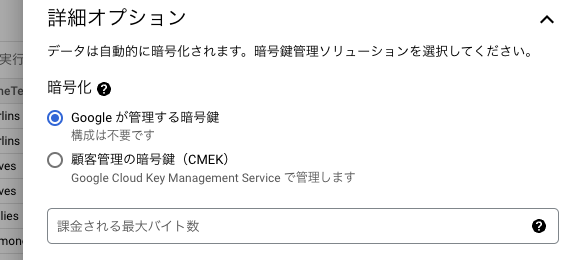
関連:課金されるバイト数を制限してクエリ費用を抑える
Cloud Console から、1 日に処理可能なデータ量の上限をプロジェクトまたはユーザ単位で設定することができます。
関連:カスタムコスト管理を作成する
Finding the most expensive queries
先ほど紹介したものは、実行前のクエリに対してコストを計算する方法でしたが、今度はクエリを実行した後の話です。
クエリごとに処理したデータ量は、INFORMATION_SCHEMA を使うことで確認することができ、 total_bytes_processed を調べるとどのクエリがどのくらいデータをスキャンしているのかを調べることができます。
SELECT
job_id,
user_email,
query,
total_bytes_processed
FROM
`region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
EXTRACT(YEAR
FROM
creation_time) = 2022
ORDER BY
total_bytes_processed DESC
LIMIT
5⚠️ 現在実行中のジョブと、過去 180 日間に完了したジョブの履歴が表示されます。
INFORMATION_SCHEMA を使用したジョブ メタデータの取得
Caching the Results of Previous Queries (p250)
一時テーブルはクエリ中間結果を保存できます。
特徴:
- 24時間で消える
- 料金はかからない
キャッシュの例外
- ランダムなデータが入るクエリはキャッシュされない (RANDなど)
- クエリは文字列の一致を確認しているので、スペースが入ったりするとキャッシュヒットしなくなる
- WITH 句は可読性を上げるが、結果をキャッシュしないのでコストやスピードに影響を与えない
など。
その他の例外はこちらを参照してください。
主に Google Cloud コンソールを使用している場合に気をつけたいことは、空白文字でさえクエリに入ってしまうとキャッシュが効かなくなるので注意しましょう。
本当にキャッシュヒットしないか確認してみる
本当にキャッシュヒットしないのか確認してみましょう。
まずは以下の画像のようにクエリを書きます。その後クエリを2回実行すると2回目の結果はキャッシュされたデータを返してきます。
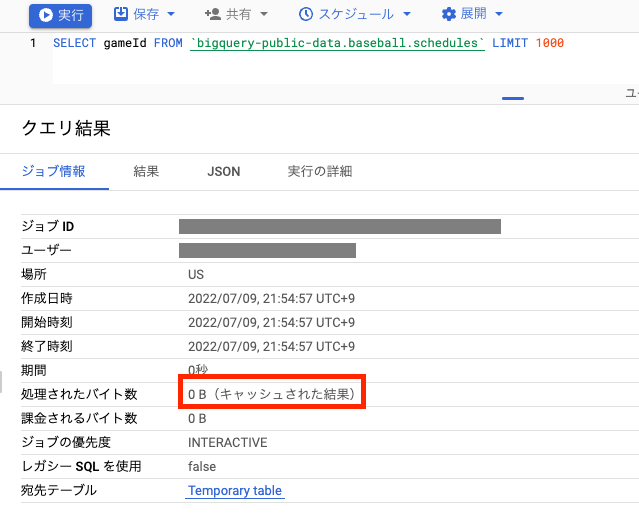
その後、先ほど書いたクエリにスペースを入れて実行してみると、キャッシュが効かなくなっていることが確認できます。
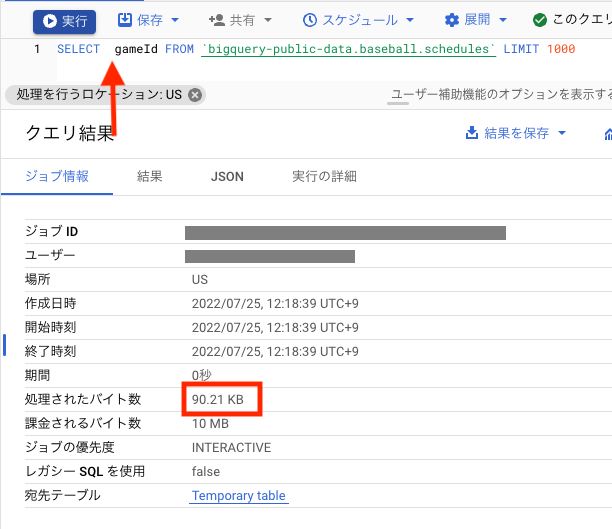
💡 Tips: もしクエリの結果を別のクエリの入力として使用するならば、その結果を一時テーブルではなく新規に作成したテーブルに入れるか、マテリアライズビューを使用しましょう。
📝 Memo: マテリアライズド ビュー
マテリアライズド ビューは事前に計算されたビューで、パフォーマンスと効率を向上させるためにクエリの結果を定期的にキャッシュに保存します。
よく使うクエリを何度も繰り返し使用するような特性を持つワークロードのパフォーマンスを大幅に向上させることができます。
マテリアライズド(実体化)ビューの概要
📝 Memo: PostgreSQL にもマテリアライズドビューの機能はあります。
ビューから参照されているテーブルを直接参照するよりも高速ですが、データが常に最新であるとは限りません。
SQL を使った統計情報を更新するジョブを毎晩スケジュールしておくことができます。
38.3. マテリアライズドビュー
関連
感想
- BigQuery には一般の公開データもあり、毎月 1TB は無料なのでクエリを勉強するのには良い教材だと感じました。
- 本書は2019年に発売されたので、2020年以降の BigQuery に関するアップデートは書いていません。そのため本書を読んで終わりではなくリリースノートや BigQuery 関連のブログも読みながら情報を取捨選択する必要があると思いました。
- BigQuery でクエリを実行してデータを取得したいだけの場合、この本を最初に読まなくても良いと思っています。理由としては、クエリなど多くの情報が BigQuery のガイド & リファレンスにほとんど書いてあり、日本語の情報で十分と感じました。
BigQuery 関連ブログ
- BigQuery のパフォーマンスを各種ダッシュボードでトラブルシューティング
- 機密データを保護する BigQuery の新機能を発表
- BigQuery の行レベルのセキュリティにより、データへのアクセスのよりきめ細かい制御が可能に
- BigQuery 管理者リファレンス ガイド: クエリ処理
- BigQuery 管理者リファレンス ガイド: リソース階層
- BigQuery 管理者リファレンス ガイド: クエリの最適化
- BigQuery 管理者リファレンス ガイド: ストレージの仕組み
- BigQuery 管理者リファレンス ガイド: データ ガバナンス
最後に
現在スリーシェイクでは、DBREのメンバーを募集しています!!