
はじめに
PagerDutyはインシデントの管理、オンコール通知のサービスとして、とても優秀なサービスです。直近も、様々な新機能が出ていますが、旧機能から新機能への移行も同時に行われています。
弊社では、PagerDutyの案件を通し、社内勉強会を実施してきました。今回は、その資料をまとめ、最近のPagerDutyの機能のユースケースと概要について記事にさせてもらいました。
今回紹介させていただく機能としては以下の通りです。
- インシデント管理機能
- Event Orchestration
- Internal Status Page
- Postmortems
- 分析機能
- Analytics
- Oncall-Readiness Report
- 自動化機能
- Incident Workflows
- Custom Incident Action
- Generic webhooks(v3)
こちらの対象読者層としては、PagerDutyの以下の基本的な機能について知っている方を対象としております。
- アカウント、インシデント、Service、EventRulesという概念について理解している
- インシデントのエスカレーションについて理解している
Event Orchestration
概要
インシデントを特定のServiceにルーティングができます。これは、外部のシステムと連携を動かす際に役に立ちます。
EventRulesの後継であり、EventRulesで実現できたこと+追加の機能があります。
そして、EventRulesは2024年にEOLになるため、今から作成する場合は、EventOrchestrationを使用することが推奨されています。
既存のEventRulesのmigrationについても記載がありますのですでに利用されている場合は一読しておくことをおすすめします。
https://support.pagerduty.com/docs/migrate-to-event-orchestration
EventOrchestrationを使う詳しい経緯についてはこちらを参照ください。
https://support.pagerduty.com/docs/event-orchestration#whats-the-difference-between-event-rules-and-event-orchestrations
ユースケース
- Integrationしたアプリケーションからのインシデントを、すでに用意している複数のServiceに振り分けたい
- システム側で、とりあえずインシデントを送り、どのServiceに振り分けるか、Oncall対応してもらうかのロジックは、PagerDuty側で管理したい
詳細
EventRulesのときと同じにはなりますが、「インシデントのルーティング」ができます。
ルーティングとは、Event Orchestrationから入ってきたインシデントを、どのServiceへ振り分けるかということです。
例えば、Datadogと連携したEvent Orchestrationがあるとします。その際に、以下のようにServiceがあったとします。
| Service名 | 内容 |
|---|---|
| FrontEndApplication | フロントエンドアプリケーションのインシデント |
| AuthApplication | 認証認可アプリケーションに対するインシデント |
| NotificationApplication | ユーザへの通知を行うアプリケーションに対するインシデント |
この際、Event Orchestrationはインシデントの中身を精査して、Serviceにルーティングできます。Ruleは例えば、以下のように記述します。
event.summary matches part 'frontEnd’event.summary matches part 'AuthApplication’event.summary matches part 'NotificationApplication’
Datadogとの連携をした際に、インシデントが送られてきた場合はDatadogのlog本文がevent.summaryになります。そのため、この場合、Datadogのlog本文に、 frontEnd という文字があれば、FrontEndApplicationに対してインシデントが登録されます。そして、 AuthApplication や、 NotificationApplication には到達しません。
flowchart LR
Datadog --> A{本文中にfrontEndという文字がある}
A -- ok --> FrontEndApplication
A -- no --> B{本文中にAuthApplicationという文字がある}
B -- ok --> AuthApplication
B -- no --> C{本文中にNotificationApplicationという文字がある}
C -- ok --> NotificationApplication
C -- no --> E(not routing)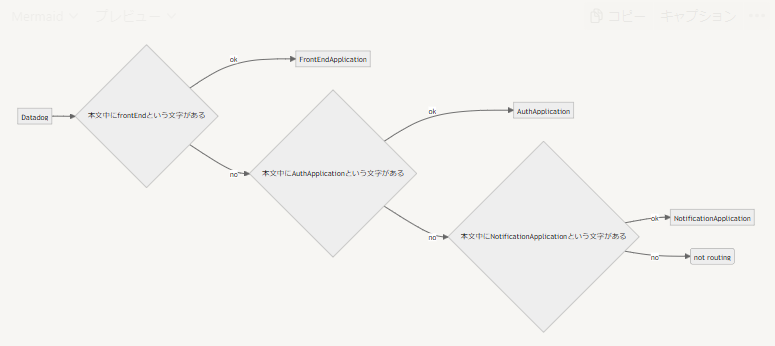
似たような名前の機能として Service Orchestration がありますが、こちらはServiceにインシデントが届いたときに一定の処理を実施できるものになり、別物になります。
Internal Status Page
概要
Business Serviceに対して、各Serviceで問題のあるインシデントが発生しているかどうかをダッシュボードとしてまとめて確認ができます。そのため、ダッシュボードを通して、マネージャや経営などのステークホルダーとインシデント対応チームとのコミュニケーションを改善できます。
マイクロサービス化された一つのアプリケーションに対してServiceを作成している場合、Business Serviceが、複数存在することもあると思います。
その場合のために、Business Service自体をまとめてダッシュボードを作成し、システム全体がどうなっているのかを確認することができます。
制限
Internal Status Pageは「Business」および「Digital Operations」プランで利用可能です。
ユースケース
- ステークホルダーに対してどのServiceが今現在何かしらの対応をしているか?などを通知したい
- マイクロサービス化されたアプリケーションごとではなく、システム全体として、なにか問題があるのかを確認したい
詳細
問題のあるインシデントの判定は、Business Serviceの設定で変更できます。(こちらの変更は、 すべての Business Serviceに対して影響があるので注意する必要があります)
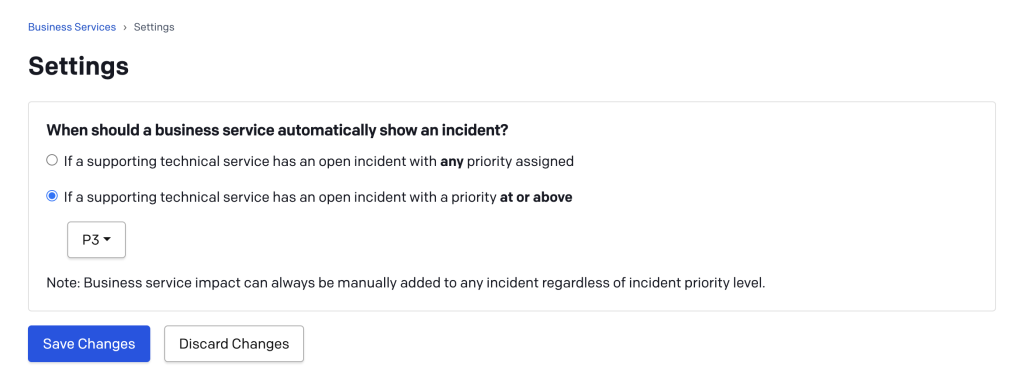
それぞれ以下のような設定になります
- 優先度が割り当てられたオープンなインシデントがある
- 優先度が
[SELECTED-PRIORITY]以上のオープンインシデントがある
Status Pageには、External Status Page機能もあります。
こちらは、上記制限におけるプランと、インシデントレスポンスまたはカスタマーサービスのプランを組み合わせる必要があるアドオンです。
こちらは、社外の人に向けたServiceのステータスページです。注意点として、Internal Status Pageとは違いデフォルトで、優先順位が P1またはP2のインシデントは、[影響を与える]インシデントとみなされます。
Postmortems
概要
インシデントに対するポストモーテムのフォーマットを決めることができ、記述揺れを減らす、また、社内展開に役立てることができます。また、機能としてSlackの会話ログを残すことができるので、障害対応時の会話をまとめることができます。
ユースケース
インシデントに対する、「良い」ポストモーテムの記述に対するフォーマットを決めて、ドキュメントとして残す
詳細
フォーム形式のフォーマットを決めて、そのフォーマットに沿ってインシデントに対するポストモーテムを記載することができます。
ポストモーテムをどう書けばよいか、また、良いポストモーテムについてはこちらを参照ください。
組織によってはSlackでインシデント対応をまとめて行っていることもあると思います。
ポストモーテムには時系列で何が起きたのかを記載していきますが、この機能では、Slackのチャネルを参照して、インシデント時のtimelineとして追加できます。もちろん、手動でも追加ができます。
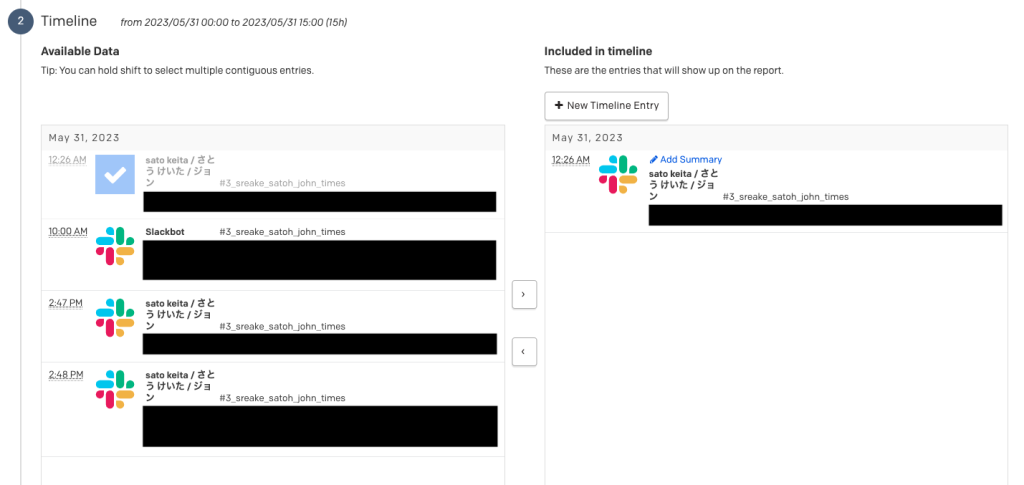
記載したポストモーテムは、後に追加編集もできます。そして、もし社内で別に残す必要がある場合はPDFファイルとしてダウンロードして保存しておく事もできます。
しかし、現状溜まっていったポストモーテムをフィルターして抽出する機能がないため注意が必要です。
Incident Workflows
概要
インシデントが発生した時に自動的に一連のアクションをトリガーする機能です。具体的には、特定のServiceや重要度レベル、タグ、時間帯などに基づいてトリガーを設定し、自動通知やEscalation Policyのトリガー、Slack通知などのアクションを定義することができます。インシデント管理を自動化することで、人的ミスを減らし、インシデントの解決を効率的に行うことができます。
ユースケース
- インシデント発生時に手動で行っていた以下の作業を自動化できる
- 特定のユーザを
responder、stakeholderとして登録する - Zoomの会議を設定する
- Slackへ通知を行う
- 特定のユーザを
詳細
インシデント ワークフローは、トリガーとアクションという2つの主要なコンポーネントで構成されています。トリガーとアクションの適切なセットをカスタマイズすることで、特定のユースケースに合わせてワークフローを調整できます。
- https://support.pagerduty.com/docs/incident-workflows#incident-workflow-components
- https://developer.pagerduty.com/api-reference/d54514b5b003f-list-incident-workflows
1.トリガー
Incident Workflowsは、インシデントが発生した際にトリガーされます。トリガーは、特定のService、特定の重要度レベル、特定のタグ、特定の時間帯などに基づいて定義することができます。
Conditional Triggerといった項目があり、以下の選択をすることができます。
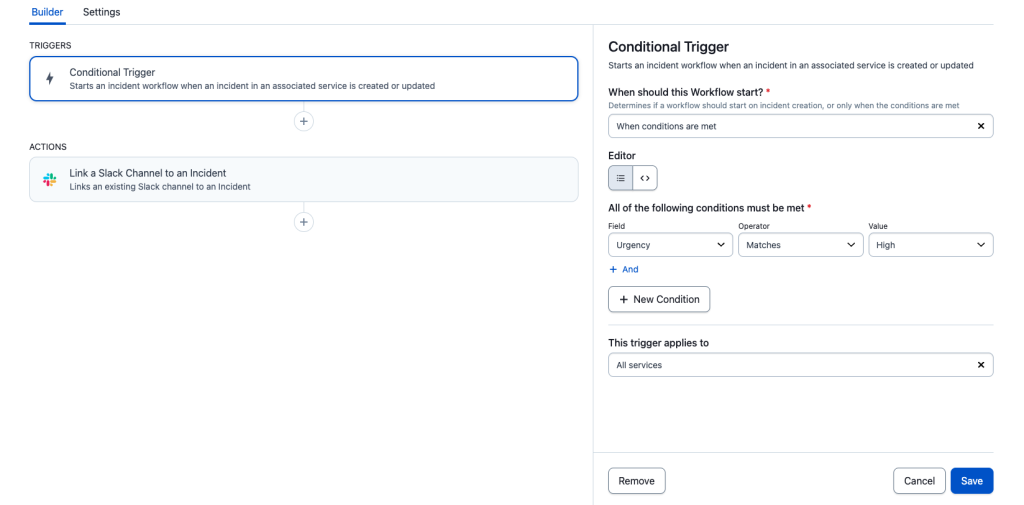
ワークフローを起動するための条件
1.インシデントが作成されたときはいつでも
2.特定の条件下
| Field | Operator | Value |
|---|---|---|
| Status | Matches / Do not Matches | Acknowledged |
| Status | Matches / Do not Matches | Resolved |
| Status | Matches / Do not Matches | Triggered |
| Urgency | Matches / Do not Matches | High |
| Urgency | Matches / Do not Matches | Low |
上記の条件はAnd/ Orで組み合わせることが可能です。
また、PCL(PagerDuty Condition Language)を利用することもできます。
全Serviceに適用するか特定のServiceに適用するかを指定できます。
2.アクション
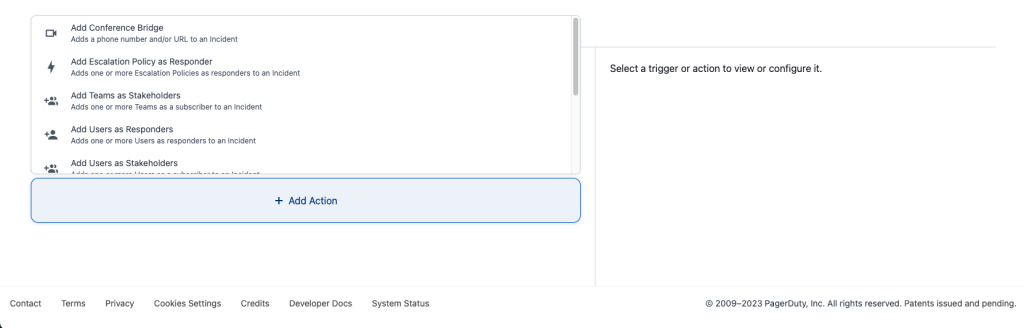
- Incident Workflowsは、インシデントが発生した際に自動的に実行される一連のアクションを定義することができます。
- アクションとして以下の選択肢が存在します。
- 会議を作成する(URL指定)
- エスカレーションポリシーをレスポンダーとして追加
- チームをステークホルダーとして追加
- ユーザーをレスポンダーとして追加
- インシデントのSlackチャンネルを作成(SlackのIntegrationが必要)
- インシデントのメッセージをSlackチャンネルに送信(SlackのIntegrationが必要)

- Zoom Meetingを作成(ZoomのIntegrationが必要)
- ステータス更新の送信
- アクションで送信するメッセージを選択可能
また、Incident Workflowsには以下のような編集制限をつけることができます。
- 管理者のみ編集ができる
- 特定のチームのみ編集ができる
しかし、自動化できるゆえの注意点もあります。
例えば、誤ったルールの設定によって、誤ったアクションがトリガーされたり、必要なアクションが実行されなかったりすることがあります。そのため、Incident Workflowsを使用する際には、慎重に設定を行い、テストを実施することが重要です。
また、Incident Workflowsを使用する際には、トリガーとアクションの関係性を理解することが必要です。トリガーが発生したら、どのようなアクションが実行されるのかを明確に定義し、必要に応じてルールを調整することが必要です。
Analytics
概要
アカウントの中のユーザ、インシデントの状況をレポートにして閲覧・ダウンロードができます。
レポートの内容としては以下のような値が見れ、アカウント全体で、または、それぞれServiceごとに絞って、日毎、週毎などで日付でも確認ができます。
- インシデントの傾向
- AcknowledgeとResolveまでに要した時間
- 誰が上げたかなどのレポート
また、こちらのデータをサマリーしてSlackに通知することもできます。
ユースケース
- インシデントに対する以下のような集計を自動化するため、日々のインシデントの対応状況をレポーティングして、上位管理者に連絡する
- インシデントにかかった工数、インシデントにおけるビジネスインパクト
- インシデントの対応にかかっている時間の推移などを見ることができるため、振り返り時に先週との差分で見ることができる
- Serviceに対する権限を見直して、アラート疲れを予防することができる
詳細
Analyticsにはインシデントレポート、Insight、Recommendationがあります。
- インシデントレポート
- ベーシックアカウントで利用できる
- インシデントの傾向、AcknowledgeとResolveまでに要した時間、誰が上げたかなど、インシデントに関わる情報を確認できる
- 上記を全体で、または、それぞれServiceごとにも確認できます。
- 上記を全体で、または、それぞれServiceごとにも確認できます。
- Insight
- インシデントレポートとは、別の視点でインシデントに対する情報を確認できる
- 緊急度、優先度、インシデント作成日、承認までの合計時間(TTA)、Responder数、従事までの合計時間(TTE)、対応工数、対応までの合計時間(TTR)、エスカレーション数など
- Serviceを複数選択し、積み重ねとして、どのぐらい対応までに時間がかかっていたかなど
- Teamの状態、パフォーマンス、誰がどのぐらいレスポンダーとして対応したか、その中断時間など
- 1時間〇〇ドルというのを入力して、上記までの障害対応時間からどれぐらいビジネスインパクトがあった
- インシデントレポートとは、別の視点でインシデントに対する情報を確認できる
- Recommendation
- Serviceに対して検査して、通知されるアラートが多すぎないかなどを判定する
- その際に権限周りをどのように修正したほうがいいかを提案してくれる
他にも、インテリジェント・ダッシュボードや、監査証跡のレポート機能もあり、インシデントに関わるレポートに付いて様々なデータを閲覧し活用することができるようになっています。
Oncall-Readiness Report
概要
チームに対して、電話を必須とするという制限を指定することができます。
また、そのルールを守っていない人を洗い出すことができ、その人に対して通知を送ることができます。
ユースケース
特定のチームは、電話対応、SMSを必須とするというルールを徹底したい。
詳細
設定できるルールとしては以下の種類があります。この中でNever miss a page が推奨になります。
- Never miss a page
- 設定必須種類: 電子メール、SMS、電話、プッシュ
- 最初の通知を見逃した場合に備えて、再度通知する
- Try Every Notion Method
- 設定必須種類: 電子メール、SMS、電話、プッシュ
- More than Email
- 設定必須種類: SMS、電話、プッシュ
- Must Include phone
- 設定必須種類: 電話
- 最初の通知を見逃した場合に備えて、再度通知する
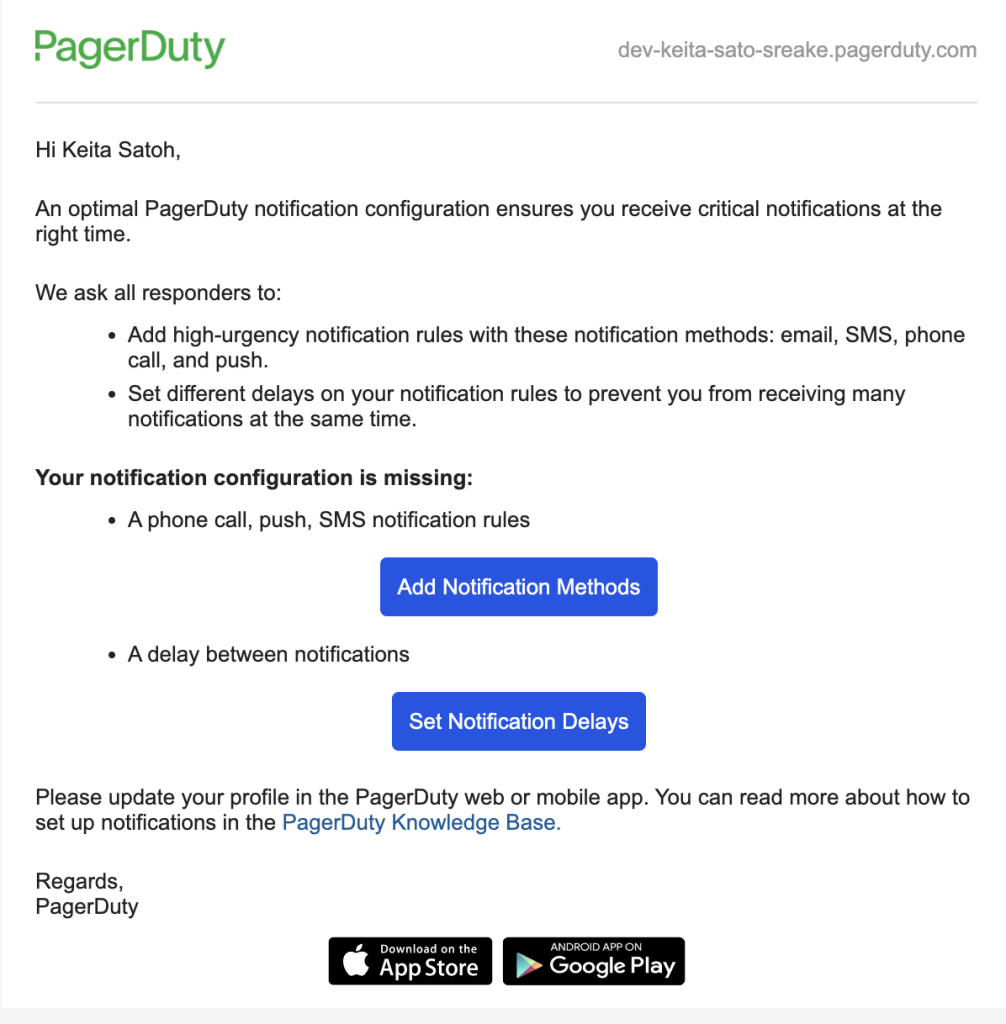
そして、上記の設定をしていない人に対して、メール通知を送ることができ、受け取った方はボタンのリンクから設定を変更できます。文章としては以下のようになります。
Custom Incident Action
概要
発生しているインシデントに対して、対象のアプリケーションへ「手動で」通知を送り、自作した処理を実行することができます。
現状のインテグレーションでは補えないパターンを自作したい場合に有用な手法と考えられます。
ユースケース
すでに以下のようなアクションを用意しており、インシデントによっては手動で実行したい。
- サーバの再起動
- 診断に追加
- 前のコミットのリバート
- ステータスページの更新
詳細
Serviceに紐付けることで発生したインシデントに対して、特定の処理を自動化できます。
注意点としては以下の通りです。
- インシデントを参照できる人のみ実行できる
- observerも割り当てられていればできる
- 1Serviceに対して最大3つのアクションができる
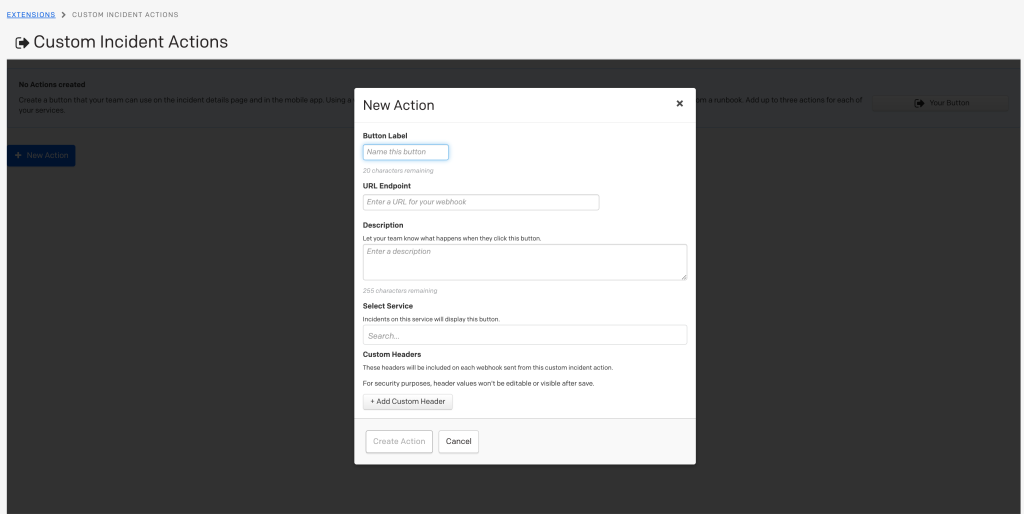
作成は、Extensionsの一覧ページから「Custom Incident Actionの作成」を行います。
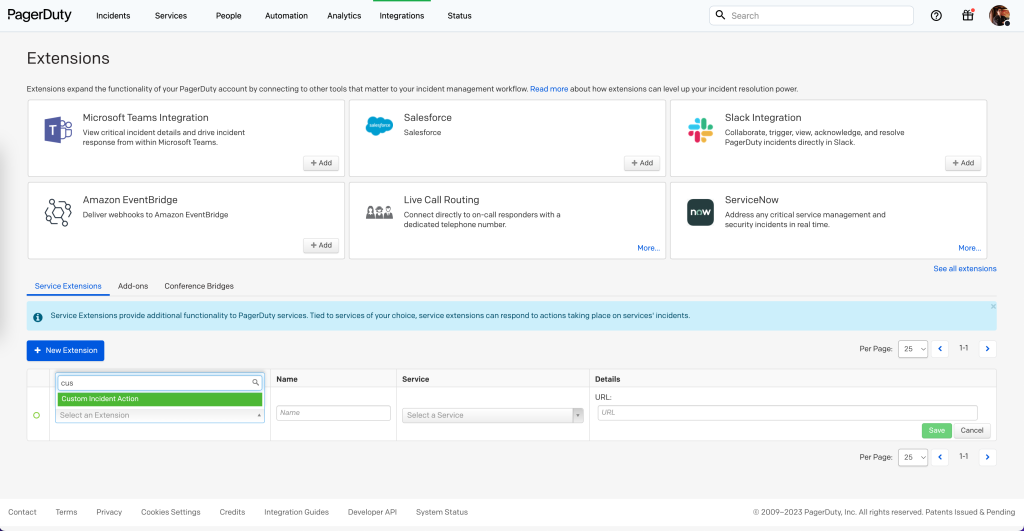
作成しようとするとカスタムインシデントアクションのページに遷移します。
ここではWebhook URL、ヘッダを入れることができます。
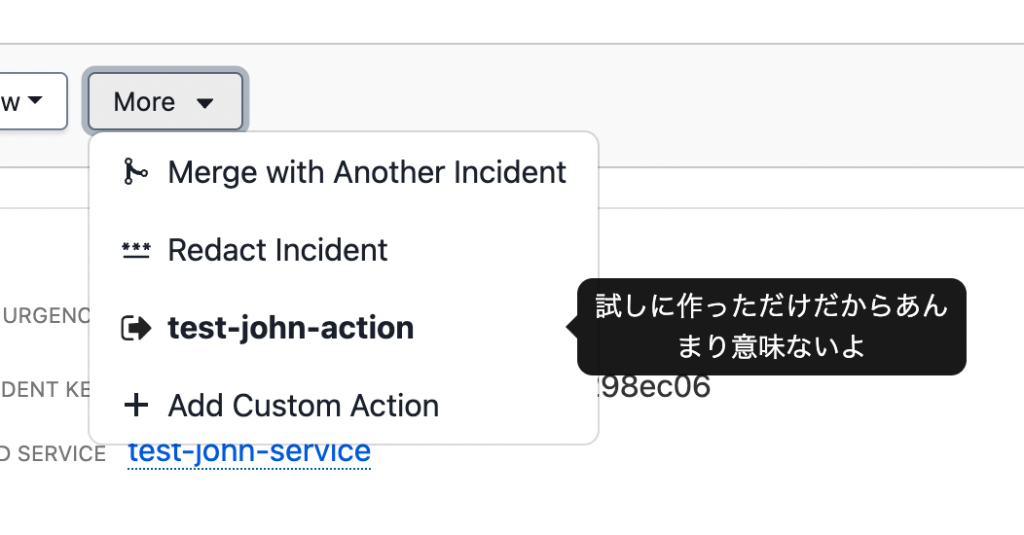
作成した後に以下のようにインシデントのページでアクションを実行することができます。
対象のURLにはPOSTで https://developer.pagerduty.com/docs/ZG9jOjQ1MTg4ODQ0-overview#webhook-payload のペイロードが送られます。
こちらは手動で実行するものになっております。もし自動で実行したい場合は次のIncidents workflow、または、Webhookの機能を利用してください。
Generic webhooks(v3)
概要
発生しているインシデントに対して、対象のアプリケーションへ「自動で」通知を送り、自作した処理を実行することができます。
現状のインテグレーションでは補えないパターンを自作したい場合に有用な手法と考えられます。
Incident Workflowsとの違いは、通知先に処理を任せる、トリガーは通知種類でのみフィルタできる、の2点です。
ユースケース
既存のIntegrationの機能では足りず、かつ、自動で処理をしてほしい。
詳細
インシデントの作成、変更などを感知して、対象のURLへ通知を送ることができ、先程のカスタムインシデントアクションを自動で処理するものと考えても良いと思います。
ただ、Webhookの場合は、以下のスコープでインシデントの通知の処理を分けることができます。
- 全てのServiceで起きたインシデントが対象
- あるTeamの見ているServiceに起きたインシデントが対象
- 特定のServiceに起きたインシデントが対象
またイベントには以下の種別があります。
| イベント | 説明 |
|---|---|
| incident.acknowledged | インシデントが承認(Acknowledge)された |
| incident.annotated | Noteが追加された |
| incident.delegated | 別のエスカレーションポリシーに再割り当てされた |
| incident.escalated | エスカレーションされた |
| incident.priority_updated | インシデントの優先度が更新された |
| incident.reassigned | Reassignされた |
| incident.reopened | 再度開かれた |
| incident.resolved | Resolveされた |
| incident.responder.added | レスポンダーが追加された |
| incident.responder.replied | レスポンダーが追加リクエストを受け入れた |
| incident.status_update_published | ステータスが更新された |
| incident.triggered | インシデントがトリガーされた |
| incident.unacknowledged | unacknowledgedされた |
| service.updated | Serviceが更新された |
| service.created | Serviceが作成された |
| service.deleted | Serviceが削除された |
送られるWebhookのペイロードに関しては、https://developer.pagerduty.com/docs/ZG9jOjQ1MTg4ODQ0-overview を参照ください。
注意点としては、正常にWebhookが送れなかった場合にDisableになってしまう点です。アプリケーション側が、処理できないパターンが有るなどの場合、また、必ず実行しなければ行けないというような場合は、利用が難しいかもしれません。
おわりに
いかがでしたでしょうか?
以前よりも、PagerDutyだけでインシデント管理が完結できるように進化してきていると感じております。
今回紹介させていただいた機能としては、Analyticsの機能が、チームの計測やサービスの計測に役立てることができるため、特に便利なのかと感じております。
