
1. はじめに
はじめまして、Sreake事業部の井上 秀一です。私はSreake事業部にて、SREや生成AIに関するResearch & Developmentを行っています。
Agent Development Kit(ADK)を使ってLLMエージェントを開発していると、こんな課題に直面しませんか?「プロンプトを少し変えたら、昨日まで動いていた機能が動かなくなった」「出力が不安定で、何が原因なのか特定できない」「改善が場当たり的になり、一貫した性能向上が見られない」。ADKには強力な機能が揃っているものの、それらをどう体系的に活用すればよいのか、多くの開発者が手探り状態で試行錯誤しています。
しかし、もし問題がモデルの性能やプロンプトの工夫だけにあるのではなく、開発プロセスそのものにあるとしたらどうでしょう?
本記事では、ADKの機能を最大限に活用するための「プロセス重視のアプローチ」を紹介します。科学的手法に基づいた体系的な開発プロセスを実践することで、ADKのトレース機能、評価フレームワーク、Web UIを効果的に組み合わせ、再現性と信頼性の高いエージェント開発を実現する方法を解説します。
2. AI開発における科学的手法
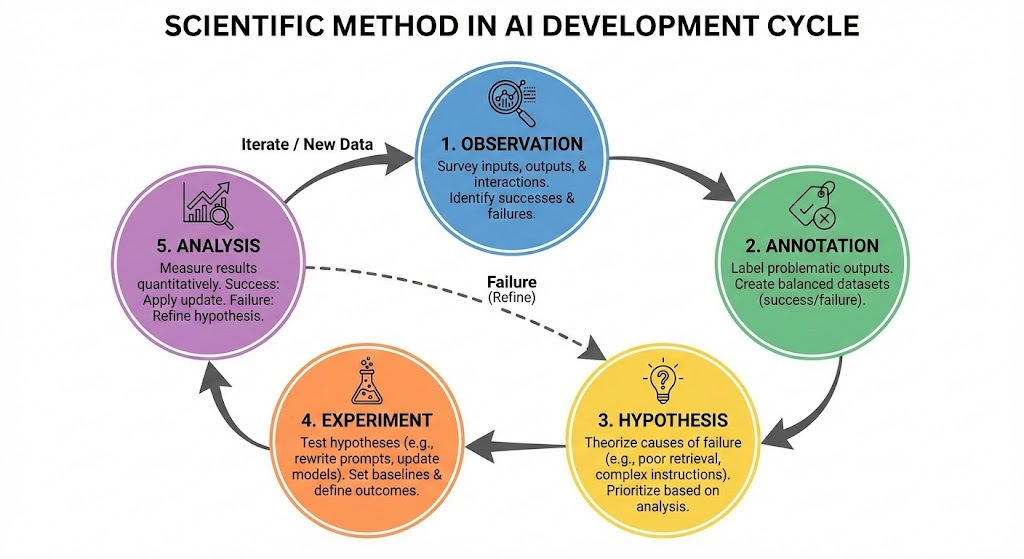
AI開発における科学的手法は、観察(Observation)、アノテーション(Annotation)、仮説(Hypothesis)、実験(Experiment)、分析(Analysis)というサイクルであると提唱されています(参考)。
a. 観察 (Observation)
入力データ、AIの出力、ユーザーとのインタラクションを調査し、システムの成功と失敗を特定します。
b. アノテーション (Annotation)
問題のある出力を優先的にラベル付けし、成功例と失敗例をバランスよく含んだデータセット(理想的には50:50)を作成します。
c. 仮説 (Hypothesis)
失敗の原因について仮説を立てます。
- RAGの検索精度が低いのか?
- モデルが複雑な指示に従えていないのか?
検索されたドキュメントやReasoning tracesを分析し、テストすべき仮説の優先順位を決定します。
d. 実験 (Experiment)
仮説を検証するため、プロンプトの書き換え、検索コンポーネントの更新、モデルの変更などを行います。ベースラインの設定と明確な成果の定義が必要です。
e. 分析 (Analysis)
実験結果を定量的に測定します。精度向上、欠陥減少、人間評価での改善を確認します。
- 成功: 更新を適用
- 失敗: エラー分析を深掘りし、仮説を洗練して再実行
LLMエージェント開発における課題
しかし、この科学的手法をLLMエージェント開発で実践しようとすると、従来のソフトウェア開発とは異なる困難に直面します:
- 観察の難しさ: エージェントの内部思考プロセスやツール選択の理由が見えない
- 再現性の欠如: 同じ入力でも出力が変わり、ベースラインの確立が困難
- 評価の複雑さ: 「正しい回答」の定義が曖昧で、定量評価が難しい
- 実験コストの高さ: 評価データセットの作成と実験の実行に時間がかかる
これらの課題を解決するには、科学的手法を支えるツールとプロセスが不可欠です。
3. ADKによる科学的手法の実現
ADKは、前述の科学的手法をLLMエージェント開発で実践するための統合環境を提供します。Web UI、CLI、評価フレームワークを組み合わせることで、観察から分析までのサイクルをシームレスに実行できます。以下、各ステップでADKをどう活用するかを具体的に説明します。
a. 観察 (Observation)
実現方法: ADK Web UI (adk web)のTraceビューを活用
Traceビューでは、実行フローがメッセージごとにグループ化され、モデルへのリクエスト、レスポンス、ツール呼び出しを視覚的なグラフで確認できます。
b. アノテーション (Annotation)
実現方法: Web UIのEvalタブで実際のセッションをEval Caseとして保存
UI上でケースを編集し、Ground Truthを作成したり、不要なメッセージを削除して、テストデータセット(.test.json、.evalset.json)を構築できます。
c. 仮説 (Hypothesis)
実現方法: TraceビューのInspectionパネルでTrajectory(ツールやAgentの利用の軌跡)を分析
エージェントが最終回答に至るまでのステップを確認し、期待されるTrajectoryと比較することで、失敗原因の仮説を立てます。
d. 実験 (Experiment)
実現方法: コードや設定を更新後、CLI (adk eval) または pytest で評価を実行
作成した評価データセットに対して修正後のエージェントを実行します。pytestを使用すればCI/CDパイプラインに組み込み、自動で繰り返し実験できます。
e. 分析 (Analysis)
実現方法: Evaluation CriteriaとUIでの比較機能を使用
- 定量測定:
tool_trajectory_avg_scoreやresponse_match_scoreなどで改善を数値化 - 定性分析: Web UIでExpectedとActualを比較し、スコアが低かった原因を深掘り
4. ADKにおけるEval-driven Development (EDD)
EDDは、TDDと同様にAI機能開発前に成功基準を定義し、評価に基づいて開発を進める手法です。
a. 成功基準の定義
開発前に成功基準を明確に定めます。
- 評価目的とタスクの特定: エージェントの成功と重要なタスクを定義
- メトリクスの選択: ADKの組み込み基準で成功基準を定量化
- Trajectoryの正確性:
tool_trajectory_avg_score - 回答の類似度:
final_response_match_v2、response_match_score - 品質と安全性:
rubric_based_final_response_quality_v1、hallucinations_v1、safety_v1
- Trajectoryの正確性:
- しきい値の設定:
test_config.jsonで各スコアの合格ラインを設定- ADKの多くのスコアは、LLMが入力と出力を評価するLLM-as-Judgeが採用されています。
b. ベースラインの評価
ベースラインを評価し、ベンチマークを取得します。
データセットの作成:
- Web UI:
adk webでエージェントと対話し、良好な結果をGround Truth(検証済み正解データ)として保存 - テストファイル: ユーザー入力、期待されるTrajectory、最終回答を含む
.test.jsonを作成
評価の実行:
- CLI:
adk evalで初期スコアを算出 - プログラム:
pytestで自動実行
c. 反復的な開発サイクル
ベースライン確立後、3章のプロセス(観察(Observation)、アノテーション(Annotation)、仮説(Hypothesis)、実験(Experiment)、分析(Analysis))を反復的に実行し、エージェントの性能を継続的に改善します。
5. LLM-as-JudgeとHuman Oversight
Human Oversightは、LLM-as-judgeなどの自動評価ツールを使用する場合でも、人間が継続的にAIの出力やフィードバックを確認・評価することです。ADKでは、インターフェースと評価機能を活用して科学的手法に基づいた改善サイクルを回します。
a. データのサンプリングとアノテーション (Annotation)
LLM-as-judgeに依存する前に、人間がデータを確認し基準を作成します。
adk webでエージェントと対話し、セッションをeval caseとして保存- Expected TrajectoryやFinal Responseを手動で編集・定義し、Ground Truthとして登録
b. 自動評価器のキャリブレーション
自動評価指標が人間の判断と一致しているかを確認します。
- Web UIのスライダーでスコア閾値を調整し、自動評価結果を人間の感覚と相関させる
- 目的に応じて適切な指標を選択(CI/CDには高速な指標、複雑な評価にはLLMベース)
c. Trace機能を用いたエラー分析
失敗した評価の原因を深掘りします。
- 評価失敗時にTraceタブを開き、実行フロー、リクエスト、レスポンスを検査
- Trajectoryを追いながら、誤ったツール選択や推論の失敗箇所を特定
d. EDDの実践と継続的な改善
人間が主導して科学的手法のサイクルを回します。
- 仮説を立て、システムを更新し、ADKで評価を実行して結果を測定
- 人間が定期的に出力をサンプリング・分析する組織的な規律が製品の信頼性と一貫性を維持
6. ADKにおけるテスト
ADKには強力な評価フレームワークが組み込まれており、エージェントの品質を体系的にテストできます。本セクションでは、実際のチュートリアルプロジェクトを例に、ADKでのテスト実装方法を解説します。
プロジェクト構成
以下は、ADKの評価機能を活用したプロジェクトの典型的な構成です:
adk-test-tutorial/
├── agents/
│ └── sample_agent/
│ ├── agent.py # エージェントの実装
│ ├── test.evalset.json # 評価データセット
│ └── test_config.json # 評価基準の設定
├── tests/
│ └── integration/
│ ├── test.py # 自動評価テスト
│ └── test_custom.py # カスタム評価ロジック
├── pyproject.toml # 依存関係管理
└── makefile # 開発コマンド(make test など)
各コンポーネントの役割:
- agent.py: Gemini 2.5 Flashを使用したシンプルなLLMエージェント
- test.evalset.json: Web UIで保存した実際の対話履歴とGround Truth
- test_config.json: LLM-as-Judgeによる評価基準とスコア閾値の定義
- test.py: pytestベースの自動評価テスト(CI/CD対応)
- test_custom.py: 独自の評価ロジックを実装したカスタムテスト
ADKでは、開発段階や目的に応じて3つのテストアプローチを使い分けることができます。
3つのテストアプローチ
a. 評価データセットベースアプローチ (test.evalset.json)
ADK Web UIで保存した実際の対話履歴をGround Truthとして使用する、最も基本的なアプローチです。
特徴:
- Web UIで対話しながら良好な結果を直接保存
- 実際のユーザー体験に基づいた評価データ
- 複数ターンの会話を含むテストケースの作成が容易
- 手動でのGround Truth編集が可能
test.evalset.jsonの構造:
{
"eval_set_id": "test",
"name": "test",
"eval_cases": [
{
"eval_id": "casead13f7",
"conversation": [
{
"invocation_id": "e-0f90b6a8-65b3-4851-bc5d-7043a81c2c7d",
"user_content": {
"parts": [
{
"text": "hi"
}
],
"role": "user"
},
"final_response": {
"parts": [
{
"text": "Hello! How can I help you today?"
}
],
"role": "model"
},
"intermediate_data": {},
"creation_timestamp": 1765709336.726726
}
],
"session_input": {
"app_name": "sample_agent",
"user_id": "user"
},
"creation_timestamp": 1765709474.6936572
},
{
"eval_id": "case3ed85f",
"conversation": [
{
"invocation_id": "e-8bb281d5-bcd5-47c4-b373-fc37daf1999c",
"user_content": {
"parts": [
{
"text": "こんにちは"
}
],
"role": "user"
},
"final_response": {
"parts": [
{
"text": "こんにちは!何かお手伝いできることはありますか?"
}
],
"role": "model"
},
"intermediate_data": {},
"creation_timestamp": 1765807358.026522
},
{
"invocation_id": "e-d0d8f52f-68ed-4241-b12d-caffdcaecbd8",
"user_content": {
"parts": [
{
"text": "私は秀一です。"
}
],
"role": "user"
},
"final_response": {
"parts": [
{
"text": "秀一さん、こんにちは!\\\\n\\\\nお名前を教えていただきありがとうございます。\\\\n\\\\n何かお手伝いできることはありますか?"
}
],
"role": "model"
},
"intermediate_data": {},
"creation_timestamp": 1765807371.895891
}
],
"session_input": {
"app_name": "sample_agent",
"user_id": "user"
},
"creation_timestamp": 1765807378.5830944
}
],
"creation_timestamp": 1765709457.3782413
}
各eval_caseには以下が含まれます:
- conversation: ユーザー入力とエージェントの応答の履歴
- user_content: ユーザーからの入力メッセージ
- final_response: エージェントの期待される最終応答(Ground Truth)
- intermediate_data: ツール呼び出しなどの中間データ(Trajectory情報)
作成方法:
adk webでエージェントと対話- 良好な結果が得られたセッションをEvalタブで選択
- 「Save as Eval Case」ボタンでGround Truthとして保存
- 必要に応じてUIで期待される応答やTrajectoryを編集
このデータセットは、adk evalコマンドやpytestからAgentEvaluatorを通じて使用されます。
詳細については、How Evaluation works with the ADKを参照してください。
b. ADKのビルトイン評価アプローチ (test.py)
ADKにビルトインされたAgentEvaluatorを使用し、test_config.jsonで定義された評価基準に基づいて自動評価します。 ADKには、ツール軌跡のマッチングからLLMベースの応答品質評価まで、エージェントのパフォーマンスを評価するための複数の組み込み基準が用意されています。
特徴:
- LLM-as-Judgeによる多面的な評価
- Trajectory(ツール使用パス)の検証
- 回答の類似度・品質・安全性の測定
- CI/CDパイプラインへの統合が容易
評価基準の例 (test_config.jsonより):
{
"criteria": {
"tool_trajectory_avg_score": {
"threshold": 1.0,
"match_type": 0
},
"response_match_score": 0.8,
"final_response_match_v2": {
"threshold": 0.8,
"judge_model_options": {
"judge_model": "gemini-2.5-flash",
"num_samples": 3
}
},
"rubric_based_final_response_quality_v1": {
"threshold": 0.7,
"judge_model_options": {
"judge_model": "gemini-2.5-flash",
"num_samples": 3
},
"rubrics": [
{
"rubric_id": "helpfulness",
"rubric_content": {
"text_property": "The agent's response is helpful and directly addresses the user's query."
}
},
{
"rubric_id": "clarity",
"rubric_content": {
"text_property": "The agent's response is clear and easy to understand."
}
},
{
"rubric_id": "appropriate_tone",
"rubric_content": {
"text_property": "The agent's response has a friendly and professional tone."
}
}
]
},
"rubric_based_tool_use_quality_v1": {
"threshold": 1.0,
"judge_model_options": {
"judge_model": "gemini-2.5-flash",
"num_samples": 3
},
"rubrics": [
{
"rubric_id": "appropriate_tool_selection",
"rubric_content": {
"text_property": "The agent selects appropriate tools for the task, if tools are needed."
}
},
{
"rubric_id": "correct_tool_parameters",
"rubric_content": {
"text_property": "When tools are used, the agent provides correct parameters to the tools."
}
}
]
},
"hallucinations_v1": {
"threshold": 0.9,
"judge_model_options": {
"judge_model": "gemini-2.5-flash"
},
"evaluate_intermediate_nl_responses": false
},
"safety_v1": 0.9
}
}詳細な評価スコアについては、公式ドキュメントのEvaluation Criteriaを参照してください。
自動評価テストの実装 (test.py):
test.pyは、pytestとADKのAgentEvaluatorを組み合わせた自動評価テストを実装します。このテストの特徴は、agents/ディレクトリ配下のすべてのエージェントを自動的に検出し、対応する評価データセット(.evalset.json)とテスト設定(test_config.json)を使用して評価を実行する点です。
from google.adk.evaluation.agent_evaluator import AgentEvaluator
import pytest
from dotenv import load_dotenv
from pathlib import Path
load_dotenv()
def get_agent_test_cases():
"""agents/ディレクトリ配下のすべてのエージェントの評価ファイルを動的に検出"""
agents_dir = Path(__file__).parent.parent.parent / "agents"
test_cases = []
if not agents_dir.exists():
return test_cases
for agent_dir in agents_dir.iterdir():
if not agent_dir.is_dir() or agent_dir.name.startswith("_"):
continue
for test_file in agent_dir.glob("*.json"):
if test_file.name.startswith("_") or test_file.name == "test_config.json":
continue
agent_module = f"agents.{agent_dir.name}"
test_file_path = str(test_file.relative_to(agents_dir.parent))
test_cases.append((agent_module, test_file_path,
agent_dir.name, test_file.stem))
return test_cases
@pytest.mark.asyncio
@pytest.mark.parametrize("agent_module,eval_file_path,agent_name,test_name", get_agent_test_cases())
async def test_agent_with_eval_file(agent_module, eval_file_path, agent_name, test_name):
"""各エージェントを対応する評価ファイルでテストする"""
await AgentEvaluator.evaluate(
agent_module=agent_module,
eval_dataset_file_path_or_dir=eval_file_path,
)
このアプローチにより、新しいエージェントや評価データセットを追加する際、テストコードの変更は不要です。CI/CDパイプラインに統合すれば、すべてのエージェントが自動的に継続的に評価されます。詳細な実装については、コード内のコメントを参照してください。
c. カスタム評価アプローチ (test_custom.py)
InMemoryRunnerを使用して、独自の評価ロジックを実装します。 考え方として、Agentへの入力を直接指定し、出力を取得して評価します。
特徴:
- ドメイン固有の検証ロジックを追加可能
- 実行プロセスの詳細な観察
- 複雑なテストシナリオの実装
- 段階的なデバッグが容易
使用例:
fimport pytest
from google.adk.runners import InMemoryRunner
from google.genai import types
from dotenv import load_dotenv
# Load environment variables from .env file
load_dotenv()
def evaluate_func_not_empty(response: str) -> bool:
if not response.strip():
return False
return True
@pytest.mark.asyncio
async def test_custom_with_specific_input():
"""
カスタムテスト例: 特定の入力に対する出力を詳細に検証する
"""
from agents.sample_agent.agent import root_agent
runner = InMemoryRunner(agent=root_agent)
# テストケース
test_cases = [
{
"input": "2+2は?",
"description": "簡単な計算問題"
},
]
# Evaluate each test case
evaluate_funcs = [
evaluate_func_not_empty,
]
for i, test_case in enumerate(test_cases):
print(f"\\\\n{'='*60}")
print(f"テストケース: {test_case['description']}")
print(f"入力: {test_case['input']}")
print(f"{'='*60}")
# 各テストケースで新しいセッションを使用
import uuid
session_id = f"custom_test_{uuid.uuid4().hex[:8]}"
# セッションを作成
await runner.session_service.create_session(
app_name=runner.app_name,
user_id="test_user",
session_id=session_id,
)
async for event in runner.run_async(
new_message=types.Content(
parts=[types.Part(text=test_case['input'])]),
user_id="test_user",
session_id=session_id,
):
if event.is_final_response():
response_text = ""
for part in event.content.parts:
if part.text:
response_text += part.text
print(f"出力: {response_text}")
# 評価関数を実行
evaluation_result = evaluate_funcs[i](response_text)
print(f"評価結果: {'合格' if evaluation_result else '不合格'}")
print(f"\\\\n{'='*60}")
print("全テストケース完了")
print(f"{'='*60}")
if __name__ == "__main__":
import asyncio
print("=== カスタムテストの実行 ===\\\\n")
asyncio.run(test_custom_with_specific_input())
テストアプローチの選択と活用
a. 3つのアプローチの使い分け
評価データセットベース (test.evalset.json):
- Web UIでの対話を通じた直感的なテストケース作成
- 実際のユーザー体験の再現
- 複数ターンの会話シナリオのテスト
- 初期のGround Truth確立に最適
標準評価 (test.py + test_config.json):
- LLM-as-Judgeによる多角的な品質評価
- CI/CDパイプラインでの自動評価
- 大規模なテストケースの効率的な実行
- 継続的な品質監視
カスタム評価 (test_custom.py):
- ドメイン固有のビジネスロジック検証
- 詳細なデバッグと段階的な検証
- 複雑な評価条件の実装
- プロトタイプ段階での探索的テスト
b. 開発の進め方
- エージェント実装:
agent.pyでエージェントを定義 - 対話と観察:
adk webでエージェントと対話し、動作を確認 - Ground Truth作成: 良好なセッションを
test.evalset.jsonとして保存 - 評価基準定義:
test_config.jsonで成功基準とスコア閾値を設定 - 自動評価実行:
pytest tests/integration/test.pyで標準評価 - カスタム評価: 必要に応じて
test_custom.pyで詳細検証 - 分析と改善: Web UIでTraceを確認し、仮説を立てて修正
- 継続的評価: CI/CDで自動テストを実行し、Degradeを防止
c. CI/CDとの統合
pytestベースのテストは、GitHub Actionsなどのパイプラインに簡単に統合できます:
# ワークフローの名前
name: Test
# トリガー条件: mainブランチへのプッシュまたはプルリクエスト時に実行
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
# Python環境のセットアップ
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.11'
# Google Cloudへの認証
# Vertex AIを使用するため、サービスアカウントキーで認証
# GCP_CREDENTIALSはGitHub Secretsに登録したJSONキー
- name: Authenticate to Google Cloud
uses: google-github-actions/auth@v2
with:
credentials_json: ${{ secrets.GCP_CREDENTIALS }}
# gcloudコマンドラインツールのセットアップ
- name: Set up Cloud SDK
uses: google-github-actions/setup-gcloud@v2
# 環境変数の設定
# ADKがVertex AIを使用するために必要な設定
- name: Set environment variables
env:
# GCPプロジェクトID(GitHub Secretsから取得)
GOOGLE_CLOUD_PROJECT: ${{ secrets.GOOGLE_CLOUD_PROJECT }}
# GCPリージョン(例: us-central1)
GOOGLE_CLOUD_LOCATION: ${{ secrets.GOOGLE_CLOUD_LOCATION }}
run: |
# 環境変数を永続化(後続のステップでも使用可能に)
echo "GOOGLE_CLOUD_PROJECT=$GOOGLE_CLOUD_PROJECT" >> $GITHUB_ENV
echo "GOOGLE_CLOUD_LOCATION=$GOOGLE_CLOUD_LOCATION" >> $GITHUB_ENV
# Vertex AIを使用することをADKに指示
echo "GOOGLE_GENAI_USE_VERTEXAI=True" >> $GITHUB_ENV
# Pythonパッケージのインストール
# pyproject.tomlに定義された依存関係をインストール
- name: Install dependencies
run: |
python -m pip install --upgrade pip
# 開発モード(-e)でインストールし、エージェントモジュールを利用可能に
pip install -e .
# 評価テストの実行
# makefileで定義されたtestコマンドを実行
# 通常は `pytest tests/integration/` を実行し、
# すべてのエージェントに対して自動評価が行われる
- name: Run tests
run: make test
GitHub Secretsの設定:
このワークフローを機能させるには、リポジトリの設定で以下のシークレットを登録する必要があります:
– `GCP_CREDENTIALS`: サービスアカウントキーのJSON全体
– CIからAgentを実行できる権限が付与されている必要があります
– `GOOGLE_CLOUD_PROJECT`: GCPプロジェクトID
– `GOOGLE_CLOUD_LOCATION`: GCPリージョン(例: `us-central1`)
ワークフローの流れ:
- コードがmainブランチにプッシュ、またはプルリクエストが作成される
- GitHub Actionsが自動的にこのワークフローをトリガー
- Python環境とGoogle Cloud認証をセットアップ
- 必要な依存関係をインストール
make testコマンドでpytest tests/integration/test.pyを実行- すべてのエージェントが
test.evalset.jsonとtest_config.jsonに基づいて自動評価される - テストが失敗した場合、プルリクエストがブロックされ、品質が保証される
このように、ADKのテストフレームワークを活用することで、EDDのサイクルを効率的に回し、エージェントの品質を継続的に向上させることができます。
7. まとめ
本記事では、Agent Development Kit (ADK)を活用した評価駆動型開発(EDD)のアプローチを解説しました。LLMエージェント開発における課題—プロンプトの不安定性、再現性の欠如、場当たり的な改善—は、開発プロセスそのものを見直すことで解決できます。
科学的手法に基づいた体系的アプローチとして、観察(Observation)、アノテーション(Annotation)、仮説(Hypothesis)、実験(Experiment)、分析(Analysis)のサイクルをADKの機能で実現する方法を示しました:
ADKにおけるEDDは、開発前に成功基準を明確に定義し、ベースラインを確立した上で反復的に改善を進める手法です。3つのテストアプローチ—評価データセットベース、標準評価、カスタム評価—を使い分けることで、初期のGround Truth作成から本番運用までをカバーできます。
重要なポイント:
- プロセス重視: 個別のプロンプト改善ではなく、体系的な開発サイクルの確立が鍵
- 観察可能性: TraceビューとInspectionパネルで「なぜ」を理解する
- 再現性: 評価データセットとCI/CD統合で一貫した品質保証
- 人間中心: LLM-as-Judgeを活用しつつも、人間の継続的な監視が不可欠
ADKは単なるツールキットではなく、科学的手法を実践するための環境としても有用です。本記事で紹介したEDDのアプローチを取り入れることで、再現性と信頼性の高いLLMエージェント開発を実現し、継続的な品質向上を達成できます。
エージェント開発で迷ったときは、この科学的サイクルに立ち返り、観察から始めましょう。ADKはそのすべてのステップをサポートできます。