
はじめに
Sreake事業部アプリケーション開発チームの角谷です!
最近、機械学習やディープラーニング、特に生成AIの分野で、GPUの活用がますます重要になってきています。 Stable DiffusionやChatGPTのような大規模モデルは、ものすごい計算リソースを必要としますが、NVIDIAのCUDAを使えば、GPUの力をフルに引き出すことができるのです!
GPUを使ったアプリケーションの開発では、Dockerコンテナを使うと、開発環境のセットアップや管理がとても楽になります。 この記事では、DockerコンテナでNVIDIAのGPUを使うためのnvidia/cudaコンテナについて、簡単に解説していこうと思います。
nvidia/cudaとは?
nvidia/cudaは、NVIDIAが公式に提供しているDockerイメージで、CUDA環境を簡単にセットアップできるように作られています。
このコンテナを使えば、ホストマシンに直接CUDAをインストールしなくても、コンテナ内でCUDAを動かすことが可能となっています。
CUDAについて
そもそも、CUDA(クーダ)ってなんなんすかね?という話。
CUDA(Compute Unified Device Architecture)は、NVIDIAが開発した並列コンピューティングプラットフォームおよびプログラミングモデルで、以下のような特徴があります。
- GPUの計算能力を汎用的な用途で活用可能にする技術(GPGPU)
- C/C++言語をベースとした開発環境を提供
- 画像処理、機械学習、科学計算など、並列処理が効果的な処理に特に有効
- PyTorchやTensorFlowなどの主要な機械学習フレームワークでサポート
CUDAを使うと、今までCPUでやっていた計算をGPUで並列に処理できるので、処理速度がグッとアップします。
特に、深層学習のモデル学習や推論、画像生成などでその力を発揮します。
ユースケース
- 生成AI(Generative AI): Stable Diffusion、GPT、BERT、Llamaなどの大規模モデルの推論・学習
- 機械学習・ディープラーニング: TensorFlow, PyTorch, JAX などのフレームワークをGPU上で高速に実行
- HPC(高性能計算): 科学技術計算、シミュレーションなどの計算処理
nvidia/cudaで使用されている技術
nvidia/cudaは、CUDAだけでなく、いろんな技術が組み合わさってGPUの計算リソースを効率的に活用できるようになっています。
- cuDNN(CUDA Deep Neural Network library)
- ディープラーニング向けに最適化されたライブラリ。
- 畳み込み層、プーリング層、活性化関数などの計算を最適化し、高速化を実現。
- 特にCNN(畳み込みニューラルネットワーク)の学習と推論の効率を向上。
- 生成AIにおいて、画像生成や音声合成などのディープラーニングモデルの学習で頻繁に活用される。
- TensorRT
- 推論処理を最適化するためのNVIDIA製ライブラリ。
- モデルの量子化、最適化を行い、推論速度を向上。
- 低レイテンシーかつ高スループットな推論が求められる生成AIアプリケーションに最適。
- GPTなどの大規模言語モデル(LLM)の推論時に使用される。
- cuBLAS(CUDA Basic Linear Algebra Subprograms)
- 線形代数演算を高速化するためのライブラリ。
- 行列計算、ベクトル演算、行列分解などの基本的な線形代数操作を最適化。
- 生成AIでは、モデルのパラメータ更新や推論時の計算に利用される。
Dockerfile, compose.yamlを書いてコンテナでGPUを使ってみよう
今回はコンテナ上でComfyUIを動作させるための設定を行ってみましょう。
動作環境
EC2を使用しています。インスタンスタイプは g5.2xlarge を使用。
# OSの情報
$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 22.04.5 LTS
Release: 22.04
Codename: jammy
# CPUの情報
$ sudo lshw -class processor
description: CPU
product: AMD EPYC 7R32
vendor: Advanced Micro Devices [AMD]
physical id: 4
bus info: cpu@0
version: 23.49.0
slot: CPU 0
size: 2800MHz
capacity: 3300MHz
width: 64 bits
clock: 100MHz
capabilities: lm fpu fpu_exception wp vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp x86-64 constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf tsc_known_freq pni pclmulqdq ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand hypervisor lahf_lm cmp_legacy cr8_legacy abm sse4a misalignsse 3dnowprefetch topoext ssbd ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 clzero xsaveerptr rdpru wbnoinvd arat npt nrip_save rdpid
configuration: cores=4 enabledcores=4 microcode=137367679 threads=8
# GPUの情報
$ lspci | grep -i nvidia
00:1e.0 3D controller: NVIDIA Corporation GA102GL [A10G] (rev a1)
$ lspci -s 00:1e.0 -v
00:1e.0 3D controller: NVIDIA Corporation GA102GL [A10G] (rev a1)
Subsystem: NVIDIA Corporation GA102GL [A10G]
Physical Slot: 30
Flags: bus master, fast devsel, latency 0, IRQ 10
Memory at c0000000 (32-bit, non-prefetchable) [size=16M]
Memory at 1000000000 (64-bit, prefetchable) [size=32G]
Memory at 840000000 (64-bit, prefetchable) [size=32M]
Capabilities: <access denied>
Kernel driver in use: nvidia
Kernel modules: nvidiafb, nvidia_drm, nvidia
# GPUの使用状況
$ nvidia-smi (base)
Tue Mar 4 18:04:47 2025
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.183.01 Driver Version: 535.183.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA A10G Off | 00000000:00:1E.0 Off | 0 |
| 0% 17C P8 9W / 300W | 0MiB / 23028MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+NVIDIA Container Toolkitのインストール
NVIDIA Container Toolkitは、DockerコンテナでNVIDIAのGPUを使うためのツールキットです。
sudo apt update
sudo apt install -y nvidia-container-toolkit
sudo systemctl restart docker
Dockerfileのサンプル
# ベースイメージとしてnvidia/cudaを使用
FROM nvidia/cuda:12.1.0-devel-ubuntu22.04
# 必要なパッケージのインストール
RUN apt-get update && apt-get install -y \
python3 \
python3-pip \
git \
&& rm -rf /var/lib/apt/lists/*
# ComfyUIのリポジトリをクローン & 必要なPythonパッケージをインストール
WORKDIR /app
RUN git clone https://github.com/comfyanonymous/ComfyUI.git ComfyUI && \
cd ComfyUI && \
pip3 install -r requirements.txt
# コンテナ起動時に実行するコマンド
CMD ["python3", "/app/ComfyUI/main.py", "--listen", "0.0.0.0", "--port", "8188"]外部のローカルマシンからEC2で起動するComfyUIに接続するため、ホストを 0.0.0.0 に設定しています。
compose.yamlのサンプル
services:
cuda-container-comfyui:
build:
context: .
dockerfile: Dockerfile
ports:
- "8188:8188"
deploy:
resources:
# GPUデバイスの予約設定
reservations:
devices:
# NVIDIAドライバを使用するデバイスの設定
- driver: nvidia
device_ids: ["0"]
capabilities: [all]capabilities の設定は、DockerコンテナがGPUリソースを使用するために必要な指定です。 以下のような個別の設定項目があります。
gpu: この設定を有効にすると、コンテナはGPUリソースを使用することが許可されます。これにより、GPUを利用した計算や処理が可能になります。例えば、深層学習モデルのトレーニングや推論を行う際に必要です。compute: コンテナがGPUの計算能力を使用することを許可します。これは、GPUを使用した計算を行うアプリケーションにとって必須の設定です。特に、数値計算や行列演算を行う際に重要です。display: GUIアプリケーションなど、GPUの表示機能を使用する必要がある場合にこの設定を有効にします。これにより、コンテナ内でグラフィカルなインターフェースを持つアプリケーションを実行することができます。video: ビデオ処理を行うアプリケーションに必要な設定です。コンテナがビデオデバイスにアクセスできるようにすることで、ビデオのエンコードやデコード、ストリーミングなどの処理が可能になります。graphics: グラフィックス処理を行うアプリケーションに必要な設定です。これにより、コンテナがグラフィックスデバイスにアクセスでき、3Dレンダリングや画像処理などが行えるようになります。all: 上記のすべての機能を一度に許可します。この設定を使用することで、特定の機能を個別に設定する手間を省き、コンテナが必要とするすべての機能を一度に有効にすることができます。
コンテナの起動
$ docker compose up --build
これでコンテナが起動するはずです
$ docker ps (base)
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9632ffc6d636 nvidia_cuda_docker-cuda-container-comfyui "/opt/nvidia/nvidia_…" 48 minutes ago Up 48 minutes 0.0.0.0:8188->8188/tcp, :::8188->8188/tcp nvidia_cuda_docker-cuda-container-comfyui-1コンテナが正しくGPUを使うことができてるか確認する
nvidia-smi コマンドを実行して、GPUの使用状況を確認します。
$ nvidia-smi
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.183.01 Driver Version: 535.183.01 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA A10G Off | 00000000:00:1E.0 Off | 0 |
| 0% 25C P0 59W / 300W | 256MiB / 23028MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 34674 C python3 248MiB |
+---------------------------------------------------------------------------------------+上記の Processes の箇所を見てみると、PID = 34674 がComfyUIのプロセスとして使用されているようです。
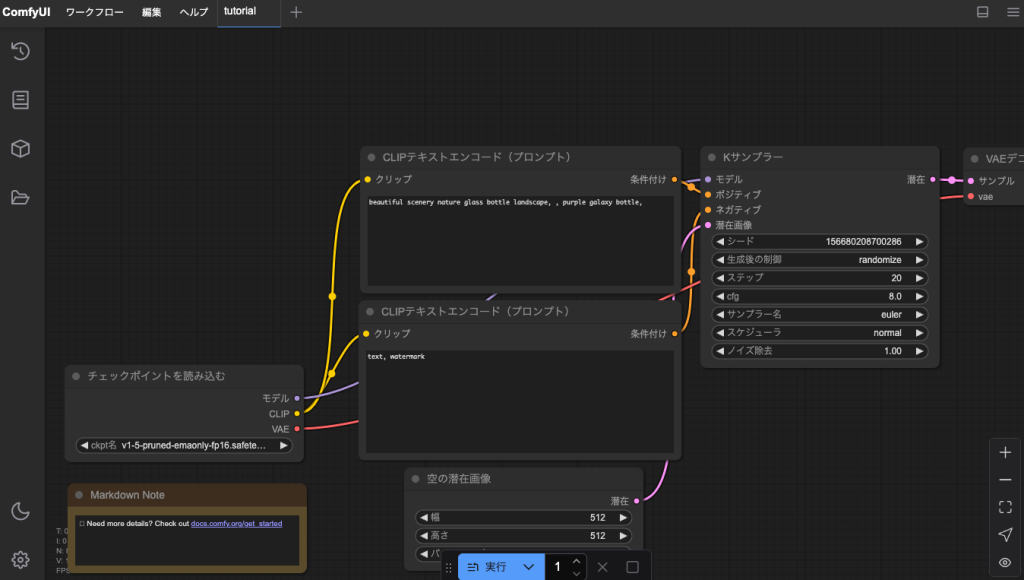
ローカルのマシンからComfyUIに接続
この状態で http://EC2のIPアドレス:8188 にブラウザからアクセスするとこのようにComfyUIを使うことができます。
その他
GPUリソースの管理方法について
今回の環境は1つのGPUしか搭載していません。
複数のGPUを搭載している場合、IDを指定することで、使用するGPUを指定して割り当てることが可能です。 docker-compose.yamlでは以下のように記述することで指定できます。
services:
cuda-container-comfyui:
build:
context: .
dockerfile: Dockerfile
ports:
- "8188:8188"
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ["0", "1"] # GPU 0, GPU 1 の両方を使用
capabilities: [all]GPUの使用状況の測定について
AWSのCloudWatchでGPUのモニタリング等もありますが、nvidia-smi dmon コマンドを実行してGPUの使用状況をリアルタイム監視することが可能になっています。
$ nvidia-smi dmon
# gpu pwr gtemp mtemp sm mem enc dec jpg ofa mclk pclk
# Idx W C C % % % % % % MHz MHz
0 58 29 - 0 0 0 0 0 0 6250 1710
0 58 29 - 0 0 0 0 0 0 6250 1710
0 58 29 - 0 0 0 0 0 0 6250 1710
...
出力される項目はそれぞれ以下のようになっています。
| 項目 | 説明 |
|---|---|
| gpu Idx | GPU のインデックス(複数 GPU がある場合は 0, 1, 2… と続く) |
| pwr (W) | 現在の消費電力(Watt)。高負荷時に上昇する |
| gtemp (C) | GPU 温度(℃)。高温になりすぎるとサーマルスロットリングが発生する |
| mtemp (C) | メモリ温度(℃)。一部のGPUでは取得できず - になることもある |
| sm (%) | Streaming Multiprocessors(SM)の使用率。GPUの演算リソースの使用状況 |
| mem (%) | GPUメモリの使用率。VRAM使用状況を示す |
| enc (%) | ハードウェアエンコーダー(NVENC)の使用率。動画エンコード時に増加 |
| dec (%) | ハードウェアデコーダー(NVDEC)の使用率。動画デコード時に増加 |
| jpg (%) | JPEGエンジンの使用率。画像処理に関連 |
| ofa (%) | Optical Flow Accelerator(光学フローアクセラレータ)の使用率。機械学習やビデオ処理で利用 |
| mclk (MHz) | メモリクロック(MHz) |
| pclk (MHz) | GPUコアクロック(MHz) |
まとめ
nvidia/cudaコンテナを使用することで、複雑なCUDA環境の構築が容易になって嬉しみが発生します。
今回の環境構築手順や設定例が、みなさんのGPUを活用したアプリケーション開発の参考になれば幸いです。 特に生成AIやディープラーニングの分野では、GPUの活用が不可欠となっていますので、本記事の知識を基に、より効率的な開発環境の構築にお役立てください〜。