
はじめに
Sreake 事業部の芳賀雅樹 (@silasolla) です.普段はアプリケーションの開発支援を担当していますが,今回はその基盤となるデータベースの裏側の仕組みが気になり,深掘りしてみました.
早速ですが,Google Cloud には Cloud Spanner というフルマネージド RDB サービスがあります.実際に料金試算をしたことがある方なら,特に本番環境で推奨されるマルチリージョン構成などの見積もりを見て「Cloud Spanner はハイエンドで高価なサービスだ」という印象を持たれたのではないでしょうか.
しかしながら,それだけのコストがかかる理由は,裏を返せば「一般的な RDB では原理的に困難だったことを,マネージドサービスとして提供している」という Cloud Spanner の価値そのものでもあります.
マルチリージョン構成の Cloud Spanner は,以下の3点を同時に満たしています.
- 読み書き双方のグローバルな水平スケールアウト
- マルチリージョンでの強力な整合性 (外部整合性) と ACID トランザクション
- 99.999% (年間停止時間5分以下) の可用性
データベースのアーキテクチャに詳しい方ほど,この3点を「グローバル規模」かつ「厳密」に維持し続けることの困難さを理解できるはずです.「分散型 NoSQL のように書き込み性能を大規模に水平スケールするなら整合性は緩むはずだし,RDB のように厳密に整合させるならスケールには物理的な限界があるはずだ」と.
これは分散システムの宿命とも言える CAP 定理の制約であり,本来であればどこかを犠牲にしなければなりません.(あるいは,犠牲にならないほどお金をかけてインフラを増強する必要があります)
数千台のサーバにデータを分散させつつ,それらがあたかも「1台の巨大なコンピュータ」であるかのように矛盾なく振る舞うことは,物理的に極めて困難だからです.
Cloud Spanner が画期的だったのは,この難問に対し「ネットワークを速くする」といった素朴な性能向上だけでなく「分散システムにおける『時間』の概念を定義しなおす」というアプローチで解決を図った点にあります.
Cloud Spanner のコストは単なるサーバ代ではありません.アプリケーションの開発者が本来背負うはずだった「分散システムの整合性保持」という極めて重い技術的負債や運用コストを肩代わりする,Google の特殊なハードウェアインフラと分散アルゴリズムへの対価と言えます.
この記事では,普段はブラックボックスとして扱われている Cloud Spanner の内部で一体何が起きているのか,その仕組みを技術的な視点から紐解いていきます.
本記事の解説について
本記事の解説や用語は Spanner のアーキテクチャを定義した原論文 (OSDI 2012) に基づいています.そのため,現在の Cloud Spanner のコンソールで見かける用語などとは一部異なる場合があります.(原論文の Zone は現在の Region/Zone に,Tablet は Split の概念に相当するなど)
数式やタイムスタンプの定義に関しても,記事の可読性を優先し,原論文における厳密なイベント定義 (e_{i}^{start} や e_{i}^{server} など) を簡略化して記載しています.
しかしながら,その根底にある「TrueTime を用いた整合性の担保」や「Paxos による分散合意」といったコアアーキテクチャは,現在の Cloud Spanner にもそのまま受け継がれています.
また Spanner の全体像は,ストレージ層 (Colossus) の詳細なアーキテクチャやクエリ処理エンジンを含め多岐にわたりますが,本記事では Spanner の強靭さを支える「分散合意 (Paxos) による複製」と,整合性の核となる「時間の概念 (TrueTime)」に焦点を絞って紹介します.
なぜ RDB のスケールは本質的に難しいのか
RDB (MySQL や PostgreSQL) は,本来「単一ノードで処理が完結する」ことを前提とした設計です.AlloyDB (Google Cloud) や Amazon Aurora に代表されるモダンなクラウド RDB は,コンピュートとストレージを分離することで,大規模な「読み取り」の水平スケールを実現しています.その一方で「書き込み」に関しては,あくまで単一のプライマリインスタンスに依存しています.
これを複数ノード,複数リージョンへ素朴に広げようとすると,避けられない壁にぶつかります.
シャーディングの運用負荷と限界
データベースの書き込み性能を向上させようとして,データの水平分割 (シャーディング) を行うことがよくありますが,その運用には重い負荷が伴います.
たとえば,アプリケーション設計への影響として,どのデータがどのデータベースに保存されているかというルーティング処理を,アプリケーションやミドルウェア自身が担わなければなりません.User ID 1〜1000 は DB-A でそれ以降は DB-B といった具合です.これはロジックの漏洩や複雑化を招いています.
複数のシャードにまたがるデータ間で整合性を保つのも骨が折れることでしょう.異なるサーバー上のデータを同時に更新しなければならないため,その一貫性の担保は技術的に難しい話です.
さらに,将来的なスケーリングに伴うリシャーディングも容易ではありません.データ量の増加に応じて分割構成を見直す際,たとえ Vitess のようなミドルウェアを利用したとしても,サービスを停止させずにテラバイト級の大きなデータを移行して管理し続けるには,とても高度な運用技術が求められます.
分散トランザクションでのコミットの重さ
複数サーバの整合性を保つために素朴な「2-フェーズコミット (2PC)」を用いると,通信回数が増え,全ノードの合意が取れるまでロックが解放されません.特に距離の離れたリージョン間 (東京 〜 大阪間など) では,物理的なネットワーク遅延がそのままロック時間に加算されるため,システムの性能が大きく低下してしまいます.
また,合意形成中に1台でもサーバが応答しなくなると,システム全体が停止してしまうリスクも抱えています.
時間のずれ
分散システムにおける最大の問題は「全ノードで完全に一致する時計が存在しない」ことです.NTP で同期しても数ミリ秒の誤差は避けられず,このわずかなずれが致命的な矛盾 (因果関係の逆転) を引き起こします.
具体例:サーバ A, B の時計がずれている場合
- サーバ A で「処理 a」が完了 (t=10)
- サーバ B で「処理 b」を実行 (t=11 のはずだが,B の時計が遅延して t=9 と記録される)
- これにより「b は a の後に起きたのに,タイムスタンプは b の方が古い」という矛盾が発生
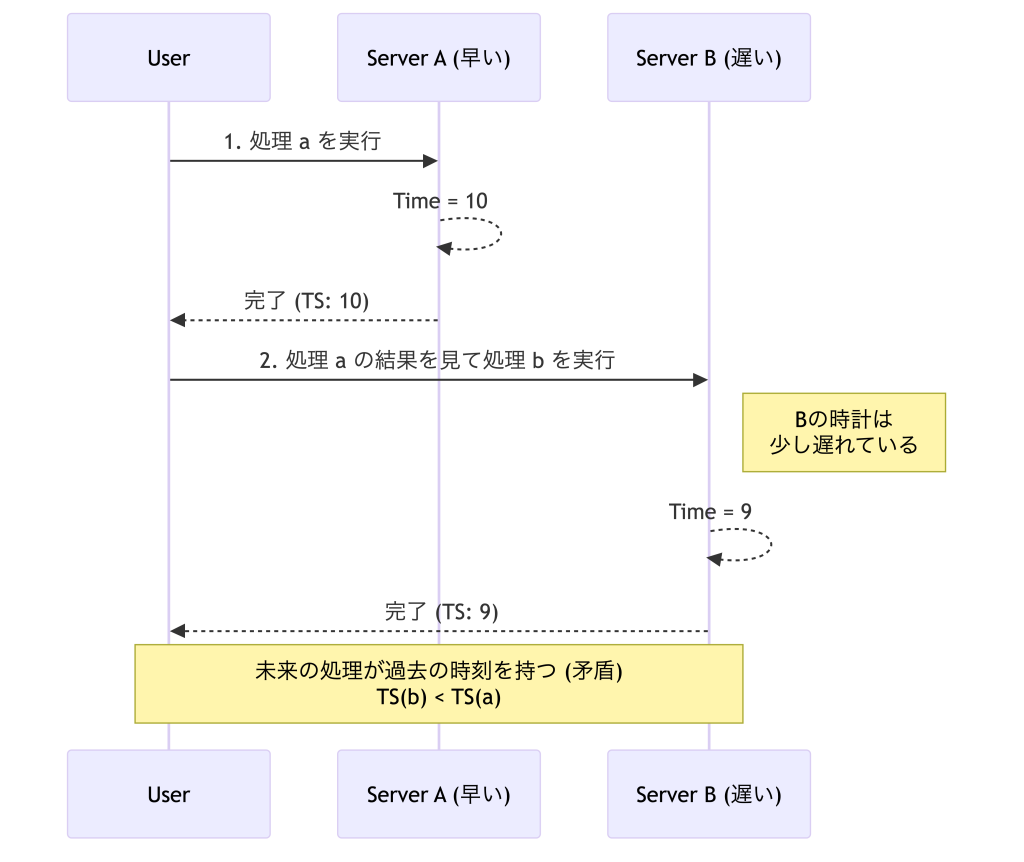
RDB において,このような順序の逆転はデータの整合性 (ACID) の崩れを意味します.
妥協としての NoSQL と諦めない Spanner
こうした問題を踏まえて,グローバルに書き込みをスケールさせたければ Cassandra や DynamoDB といった NoSQL を採用することが現実的でした.
しかしながら,これらはパフォーマンスとのトレードオフで,RDB ならば当たり前だったことを諦めなければなりません. その最たる例がデータの一貫性です.特にリージョンを跨ぐような分散環境では,書き込みのレイテンシを抑えるために「結果整合性」を採用せざるを得ず,一時的にデータが古くなることを許容しなければなりません.
また,機能面でも制限は多く,一般的な SQL のように柔軟な JOIN はサポートされませんし,ACID トランザクションも範囲が限定的になることがほとんどです.
このように「スケールしないが整合性のある RDB」か「スケールするが整合性を緩めた NoSQL」か,CAP 定理のトレードオフが長らく存在しましたが,ここで Spanner は「RDB の顔をして NoSQL のようにスケールする」ことを目指しました.
また Spanner のアーキテクチャは一つの転換点となり,後に CockroachDB や TiDB といった “NewSQL” と呼ばれる,新しいデータベース群が生まれる原点ともなりました.
Spanner の全体像
Spanner は,数百のデータセンターと数百万台のサーバーを跨いで動作する,巨大な分散データベースです.その実体は,単一のデータベースというよりも,無数の小さなデータベース (Tablet) が協調動作する巨大な集まりです.
物理・論理アーキテクチャ
Spanner の内部は,物理的な配置 (Zone) と論理的なデータ管理 (Tablet) の階層構造として定義されています.
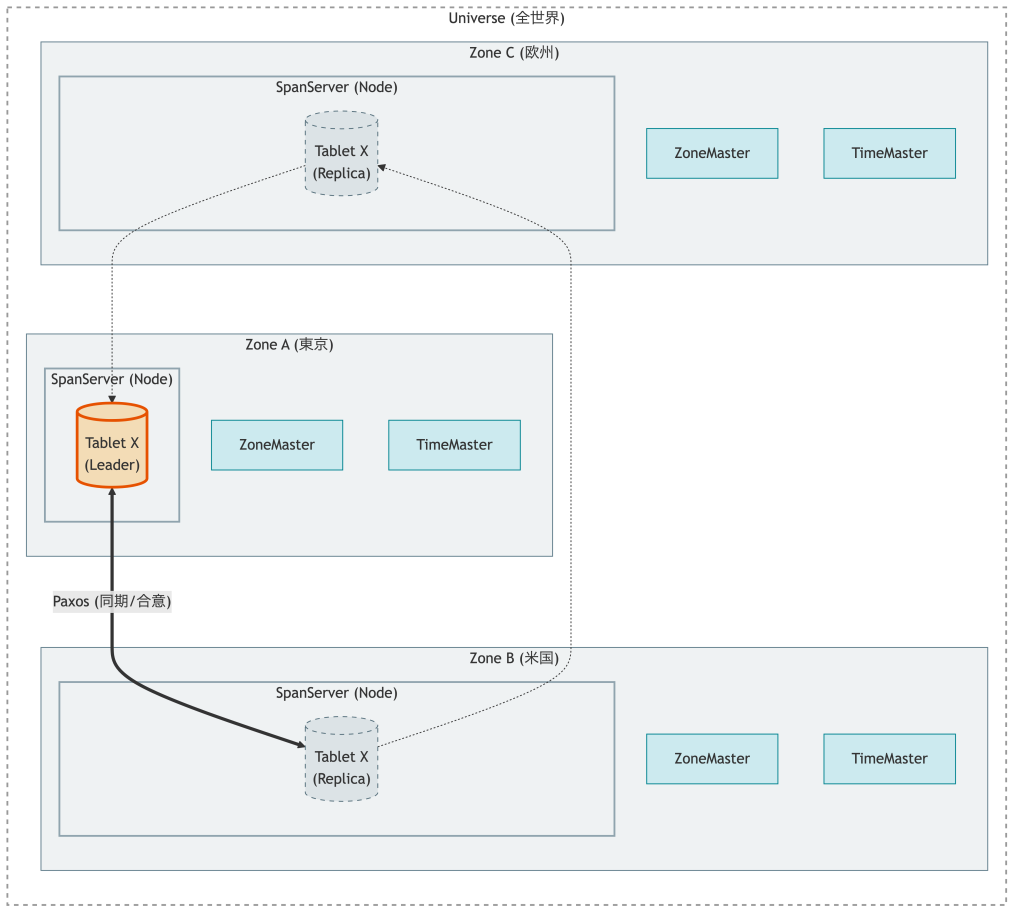
Universe
Spanner の全展開環境です.世界に数個しか存在しません.(本番環境やテスト環境など)
SpanServer
クライアントのリクエストを処理し,データを保存するワーカーノードです.重要な点として,SpanServer 自身は永続データを持たず,その実体は Google の分散ファイルシステム (Colossus) 上にあります.SpanServer は,それをネットワーク越しにマウントすることで利用しています.(ストレージとコンピュートの分離)
Zone
データセンター単位の物理的な隔離領域です.1つの Zone が停電や火災で全滅しても,他の Zone が生きていればシステムは止まりません.
ZoneMaster
Zone 内のデータをどの SpanServer に配置するかを管理する司令塔です.負荷の偏りを検知して,後述する「自動シャーディング (データの移動)」を指示します.
Tablet
データの保存単位であり,一般的な RDB における「パーティション」や「シャード」に近い概念です.Spanner のテーブルは,主キーの範囲によって数 GB 単位の Tablet と呼ばれるバッグに分割されます.巨大なテーブルも,内部では数千〜数万の Tablet に分割され,世界中の SpanServer へとバラバラに配置されます.
重要な仕組み
Spanner が壊れずに自動でスケールするのは,以下の仕組みが自律的に動いているからです.
自動シャーディング
データ量の増加だけでなく,特定の範囲へのアクセス集中 (CPU 負荷) が増えると,Spanner は自動的に Tablet を分割し,負荷の低い SpanServer へ移動させます.従来の RDB では人間が手動で行っていた「シャーディング」や「リバランシング」を,システムが数秒〜数分単位で勝手に行います.
データの実体は共有ストレージ (Colossus) にあるため,リバランシングの際に物理的なデータコピーを待つ必要はありません.データのポインタを別の SpanServer に付け替えればよいため,極めて高速にスケールアウトします.
Paxos による同期レプリケーション
Spanner は,分割されたデータ単位である Tablet を,常に複数の Zone (通常 3 つ以上) へ複製することで可用性を担保しています.この分散したレプリカ間で整合性を保つために採用されたのが,分散合意アルゴリズムとして実績のある Paxos です.
ただし,巨大なデータベース全体で一つの合意形成を行っていたのでは,それらがボトルネックとなってしまいます.そこで Spanner は Tablet ごとに独立した Paxos Group を稼働させるアプローチをとりました.これにより,あるデータの合意形成プロセスが,全く関係のない他のデータの書き込み性能には悪影響を与えません.
具体的な書き込み処理は,各グループから選出された「リーダー」が統括します.リクエストはログとして全レプリカに送られますが,コミット完了とみなされるのは,レプリカの過半数が「ログを順序通りに書き込んだ」と合意した瞬間です.
これは単なるノードの生存確認レベルの話ではなく,データの物理的な書き込み順序を多数決で保証する仕組みです.万が一リーダーがいる Zone がダウンしても,残りのメンバーから新しいリーダーが即座に選出されて,矛盾なく処理を継続できます.
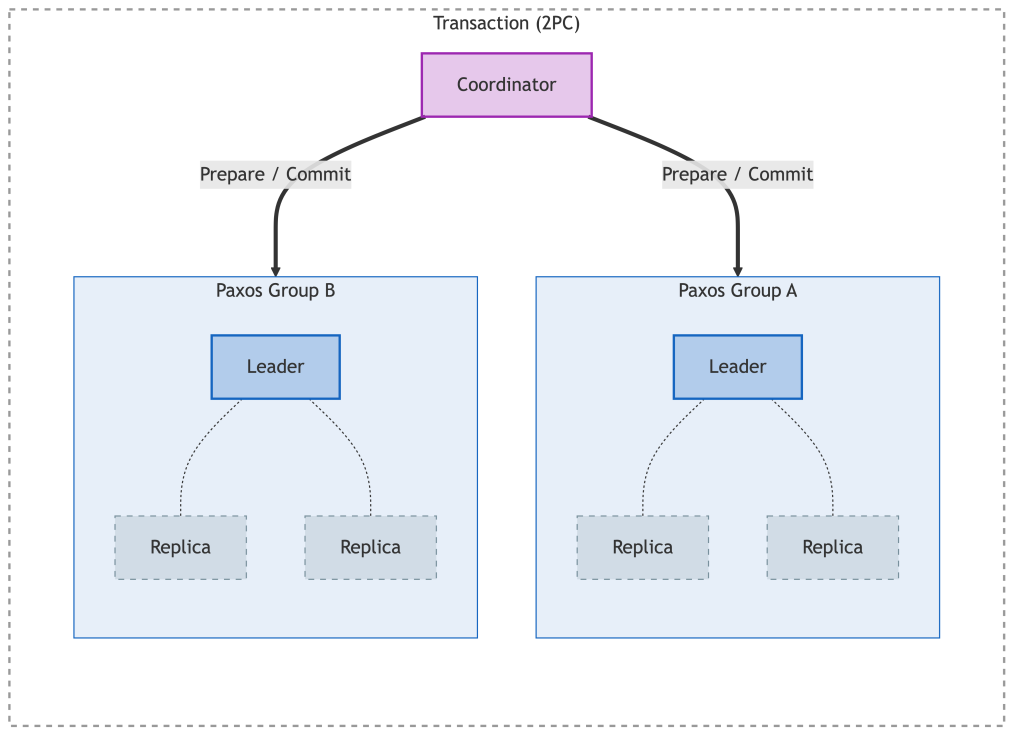
Paxos Group を参加者とした 2PC
複数の Tablet にまたがるトランザクションにおいて,Spanner は 2-フェーズコミット (2PC) を使用しています.(単一の Tablet で完結する書き込みであれば 2PC は不要であり Paxos の合意のみで高速に完了します) 前述した通り,素朴な 2PC では,参加しているサーバが1台でも応答しないと,全体がロックされたまま止まってしまいます.(単一障害点)
これに対して,Spanner の 2PC における参加者は Paxos Group (i.e. 複数台のチーム) であり,チーム内の誰かがダウンしても,過半数が生きていればチームとしては正常に稼働し続けます.つまり Spanner は,2PC の最大の弱点である可用性の低さを Paxos の強靭さでカバーすることで,止まらない 2PC を実現しているわけです.
これにより「東京リージョンが丸ごとダウンしても,データロストせずにサービスを継続する (\text{RPO} = 0, \text{RTO} \approx 0)」という,これまでの RDB では成し得なかった可用性を実現しつつ,ACID トランザクションを完遂できるのです.
TrueTime API (時間をずれごと扱う)
Paxos を採用した同期レプリケーションによって,分散したノード間での「合意 (何を決めるか)」は形成できるようになりました.しかしながら,分散データベースにはもう一つ,解決しなければならない難問があります.それは「イベントの順序付け (いつ起きたか)」です.
分散システムの歴史において,各サーバの物理的な時計は「信頼できないもの」として扱われてきました.物理時計にはどうしてもズレが生じるため,Lamport Clock に代表される「論理時計 (Logical Clock)」というカウンタを用いて,擬似的に順序を管理するのが定石でした.現実の時刻は不正確なので,例えば「カウンタが 10 の処理は 11 の処理より前である」と定義することで,因果関係の矛盾を防いできたのです.
この「現実の時刻との乖離」を Spanner は良しとしませんでした.グローバルなシステムであっても,アプリケーション開発者が扱うのは,直感的な現実の時刻 (UTC) であるべきだと考えたのです.なぜならば,データベース外の通信によって生じる因果関係 (A が B に更新完了を報告した後で B がアクセスするなど) をアプリケーション側の実装なしに矛盾なく保証できるのは,物理時刻に基づいた整合性 (外部整合性) に他ならないからです.
ここで立ちはだかるのが,物理的な壁です.
前述した通り,分散システムにおいて「全サーバの時刻を完全に一致させる」ことは物理的に不可能です.(NTP でもミリ秒単位のずれは避けられません)
しかしながら,一般的な OS やプログラミング言語の API (Date.now() や clock_gettime(2)) は,この「ずれ」を無視して,あたかも正確な時間が一点に定まっているかのような値を返します.
我々はこれをあたりまえのものとして日々利用していますが,Spanner の目指す分散システムにおいてはこれが問題だと考えました.Spanner の設計では,このような時計のずれ (不確実性) を隠蔽せず,API の戻り値として明示的に返します.これが TrueTime API です.
時間を「区間」で返す API
TrueTime API では,現在時刻を一点ではなく「区間」として返します.
これは「具体的な現在時刻は不明だが earliest から latest の間にある」という保証です.
ハードウェアによるパワープレイ
ここで重要なのが,この区間の幅です.Spanner は後述する仕組みにより,この幅の分だけ書き込み時に待機時間が発生します.
もし一般的な NTP サーバを使っていて誤差が 100 ms あったとすると,書き込みのたびに 100 ms 待たされることになり,データベースとして実用的な速度が出ません.
そこで Google は,物理的な時計のズレを最小化するための力技を選びました.各データセンターに TimeMaster と呼ばれる専用サーバーを設置し,そこへ衛星からの正確な UTC 時刻を受信するための GPS アンテナを接続しています.さらに,アンテナの故障や電波障害といった万が一の事態でも高精度に自走できるよう,原子時計まで配備して GPS と併用する二重構成です.
ソフトウェアの工夫だけでなく,こうした高価なハードウェアを惜しみなく投入することで,時刻の不確実性は平均数ミリ秒に抑え込まれています.
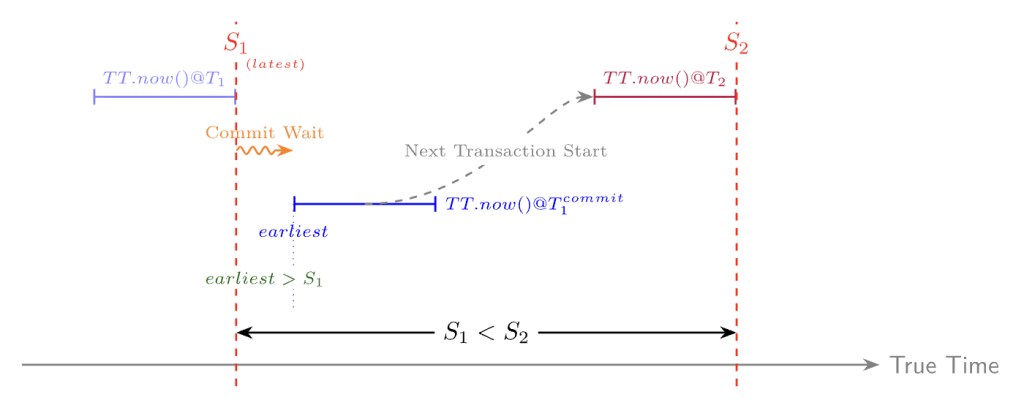
Commit Wait (ずれが過ぎるまで待つ)
TrueTime API が提供するのは,曖昧さを残した「幅のある現在時刻」に過ぎません.この不確実性を抱えたまま,Cloud Spanner はどのように厳密な整合性 (外部整合性) を守っているのでしょうか? それは「Commit Wait (コミット待機)」という愚直な方法です.
シンプルなルール
トランザクションをコミットする際に,Spanner は以下のような動作をします.
1. 書き込みタイムスタンプ S を,現在の不確実な時間の未来側 (latest) に設定
2. 現実の時間が,確実に S を追い越すまで待機 (S < TT.now().earliest をチェック)
「時計がずれているかもしれないなら,そのずれの分だけ待てばいい」という発想です.
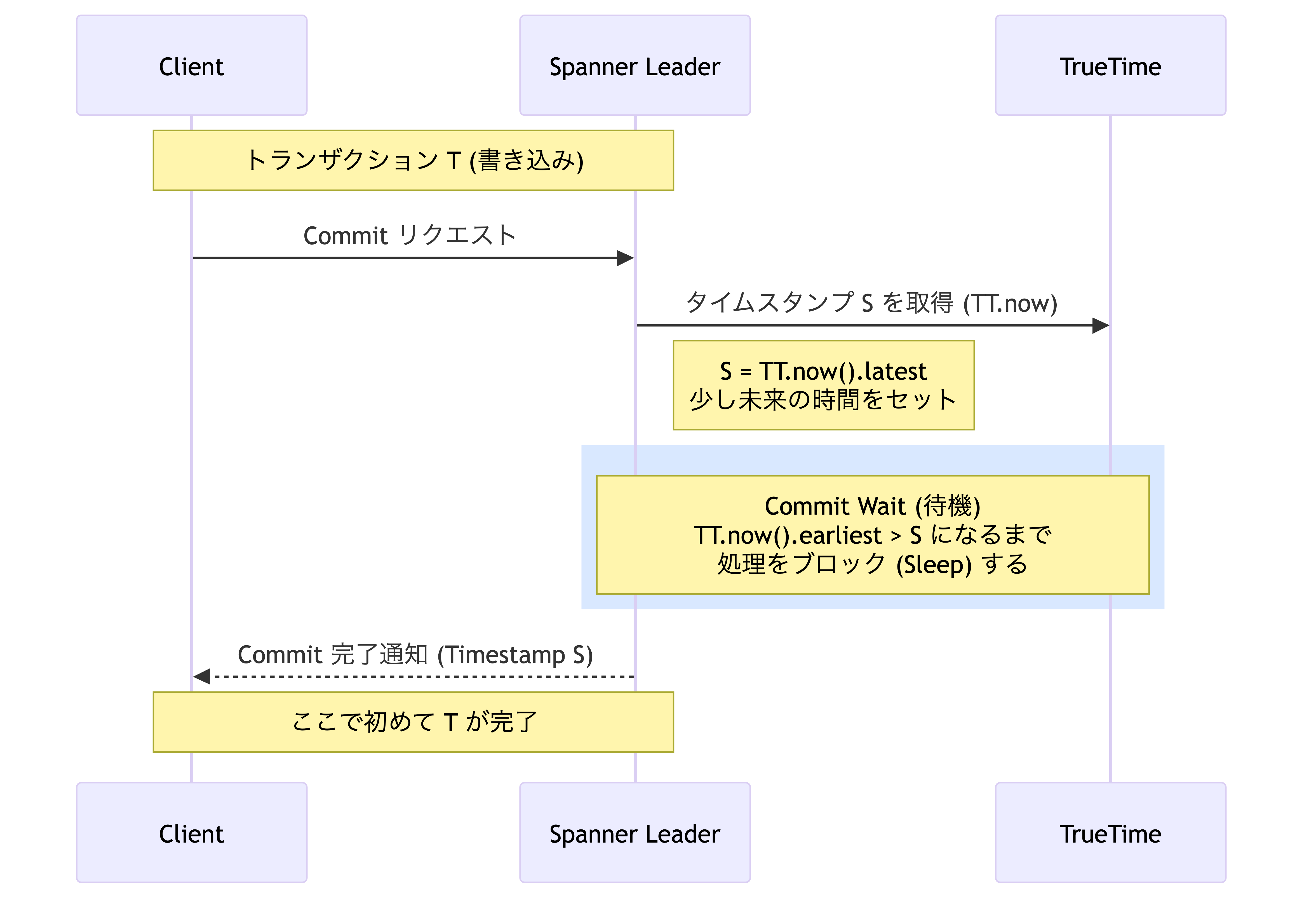
整合性が保たれる理由
この「待ち時間」を入れることで,T_1 が完了した瞬間の実時間は物理的にタイムスタンプ S_1 より未来であることが保証されます.
実時間で T_1 が終わった後 T_2 が開始すると仮定します.
Cloud Spanner は T_2 のタイムスタンプ (S_2) を決定する際,その時点の不確実な区間の「未来側 (latest)」を採用していました.つまり S_2 は,必ずその瞬間の実時間以上の値になります.
したがって,どんなに時計がずれていても,以下の順序は崩れることがありません.
Spanner は「時計のずれをなくす」のではなく「ずれている時間分だけ待つことでずれを無効化する」という愚直な方法で,RDB の厳しい整合性を実現しているのです.
整合性のためのコストと見返り
Commit Wait は整合性を保つための重要な仕組みですが,待つということは当然ながら,書き込みレイテンシを増加させます.一般的な RDB がトランザクションログへの書き込みだけでレスポンスを返せるのに対し,Spanner はそれに加えて「時計のずれが過ぎ去るまでの待ち時間 (平均数ミリ秒)」や「Paxos の合意形成の通信時間」といったオーバーヘッドを必要とします.
誤解を恐れずに言えば,単発の書き込みレイテンシに限って比較すると,物理的に近い単一リージョンの MySQL の方が理論上は高速です.データを光の速さで運んだとしても,海底ケーブルで海を渡れば,物理的な移動時間はどうしても掛かります.このような距離の壁が存在する以上,Spanner のアーキテクチャには物理的な下限値が存在するわけです.
Spanner が「速い」と言われる所以は,数万ノードにスケールすることで得られる大きなスループット (処理量) であり,単発の書き込みレイテンシ (応答速度) ではありません.「個々の書き込みで数ミリ秒待つ」代わりに「世界中から毎秒数百万件の書き込みがあってもパンクせず,青天井にスケールする」のが Spanner の設計思想です.
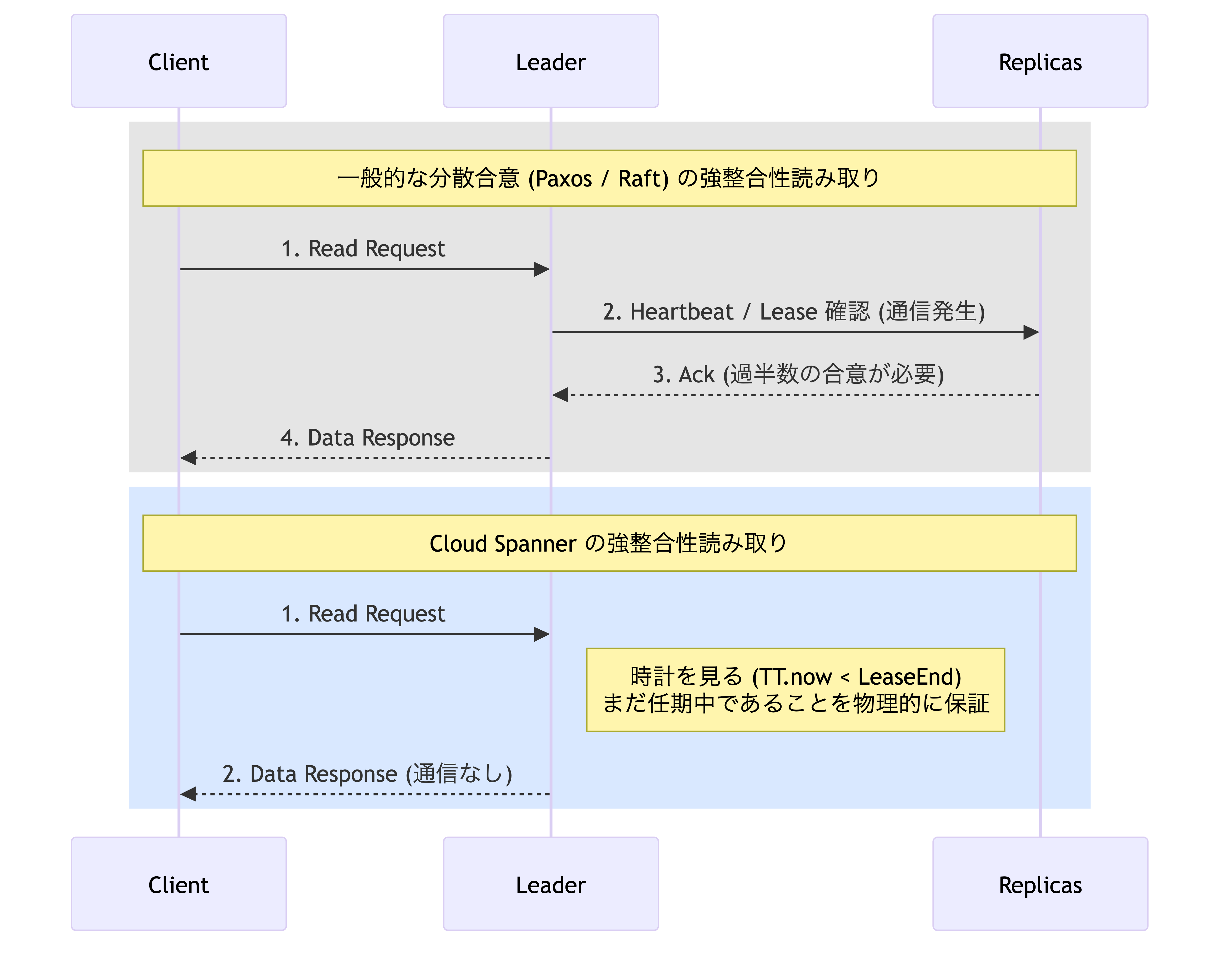
しかしながら,書き込み時に支払った待ち時間のコストは,(強整合性) 読み取りにおける高速化という形で回収されます.
通常,分散システム (Paxos) で厳密な最新データを読み取るには,リーダーが「自分が今もリーダーであること (Leader Lease)」を過半数のメンバーに通信して確認する必要があります. ところが Spanner は,ここでも TrueTime の精度を利用します.リーダーは自分の手元の時計を見て Lease 期間内であれば,誰にも確認せず即座にメモリからデータを返します.
原子時計の最大誤差を考慮しても,物理的にまだ自分の任期中であることは確実だ,情報が光の速さを超えて伝わることはないため,自分の知らないところで別のリーダーが選出されているはずがないという保証を根拠に,本来は必要な通信をスキップしているわけです.これが Spanner の選択したトレードオフです.また「数秒前のデータで良い (Stale Read)」と指定すれば,ロック待ちすら一切せずに,最寄りのリードレプリカから更に低レイテンシで取得することも可能です.
物理デバイス (原子時計) への投資で,アルゴリズムの通信回数を減らすという極めて富豪的なアプローチこそが,Spanner が高いスループットと読み込み性能を両立できる理由です.
まとめ (Cloud Spanner がもたらしたもの)
Cloud Spanner の凄みは,魔法のような技術で物理法則を無視したことではなく,その物理法則 (光の速さと時間のずれ) を直視し,真正面から殴り合って解決した点にあります.
「時は金なり (Time is Money)」という言葉があります.この古くからの格言を Cloud Spanner は物理的に実装してしまいました.我々が支払う決して安くない利用料は,原子時計やグローバルネットワークへの投資といった,本来は制御できない「時間 (Time)」をうまく扱うために投じられた「お金 (Money)」そのものだと言えます.
物理法則には逆らえないが,予算で殴れば解決できる問題が一つ増えた.そう考えれば,このコストもあながち理不尽なものではなく,むしろ合理的な投資と言えるかもしれません.
参考文献
- Corbett, J. C., et al. (2012). Spanner: Google’s Globally-Distributed Database. Proceedings of OSDI 2012.
- Brewer, E. (2017). Spanner, TrueTime and the CAP Theorem. Google Research.
- TrueTime and external consistency. Google Cloud Documentation.
- Cloud Spanner Service Level Agreement (SLA). Google Cloud Terms.
- What is Cloud Spanner? Google Cloud Blog.
- Lamport, L. (1998). The Part-Time Parliament. ACM Transactions on Computer Systems, 16(2):133–169.
- Lamport, L. (2001). Paxos Made Simple. ACM SIGACT News (Distributed Computing Column) 32(4):51-58.