
はじめに
「なんか遅い」「たまにエラーが出る」――マイクロサービスのシステムでこんな報告を受けたとき、皆さんはどこから調べ始めますか? Sreake事業部インターン生の小林です。2025年11月-12月の間インターンに参加しております。 今回の検証のきっかけは、「マイクロサービスのネットワーク障害は見えにくい」という課題意識でした。単一のアプリケーションなら、ログを見ればエラーの原因がすぐに分かります。しかし、十数個のサービスが連携して動くマイクロサービスでは、どのサービス間の通信が遅いのか、なぜエラーが起きているのかを特定するのが非常に困難です。 そこで、意図的にネットワーク障害を起こして、その影響を可視化する「カオスエンジニアリング」の手法を用いて、マイクロサービスの弱点を洗い出す検証を行いました。
カオスエンジニアリングについて
カオスエンジニアリングとは、稼働中のシステムに意図的に障害を起こして、その挙動を分析することで、システムの耐障害性を調べるものです。
目的
マイクロサービスのような分散システムでは、以下のような予測困難な事態が起こり得ます。
- サービス障害時に誤ったフォールバック設定により、期待通りに動作しない
- ダウンストリームの過度のトラフィックを受けたことによる障害
- 単一障害点のクラッシュによるカスケード障害
分散システムにおける個々のサービスはすべて正常に機能していても、それらのサービス間の相互作用が予測不可能な結果を引き起こす可能性があります。これらの弱点を「顧客に影響が出る前に、自分たちで障害を起こして発見する」のが目的です。しかし、障害を起こしても何が起きているのかが見えなければ意味がありません。そこで重要になるのが「可観測性(Observability)」です。
観測のための基礎知識
障害の影響を把握するために、今回は分散トレーシングの仕組みとツールを導入しました。分散トレーシングで用いられる用語について簡単に説明します。
トレースとスパン
- トレース(Trace): 一つのリクエスト全体の処理の流れ(例:「購入ボタン」を押してから「完了画面」が出るまで)
- スパン(Span): トレースを構成する個々の処理単位(例: checkoutサービスからpaymentサービスへの通信)
{kind=link}
画像で言うと、この一連のリクエストの流れをトレースといい、個々の処理をスパンと言います。
Jaeger
今回は、トレースを可視化するツールとしてJaegerを採用しました。Kubernetesのような環境では、ログだけではリクエストの全体像が見えません。Jaegerを使用することで、「どのサービス間の通信でなん秒かかっているか」をウォータフォールグラフで直感的に把握できます。
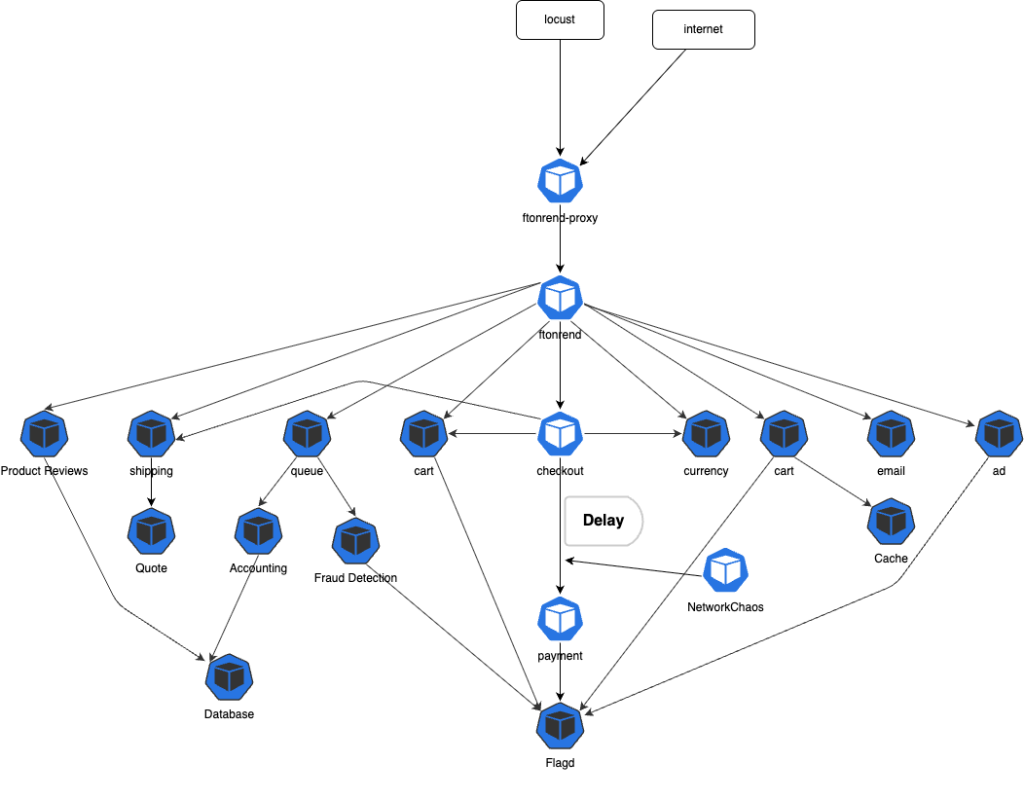
Chaos Mesh について
Chaos Mesh とは
Chaos Mesh は、Kubernetes ネイティブなカオスエンジニアリングプラットフォームです。YAML マニフェストで障害を定義して、Kubernetes リソースとして管理できるため、GitOps との親和性も高いです。
主な機能
- NetworkChaos: ネットワーク障害(遅延、パケットロス、帯域制限など)
- PodChaos: Pod の障害(強制終了、障害注入など)
- StressChaos: リソースストレス(CPU、メモリ負荷)
- IOChaos: ディスク I/O 障害
本検証では、主に NetworkChaos を使用しました。
Chaos Mesh のアーキテクチャ
Chaos Mesh は以下のコンポーネントで構成されています。
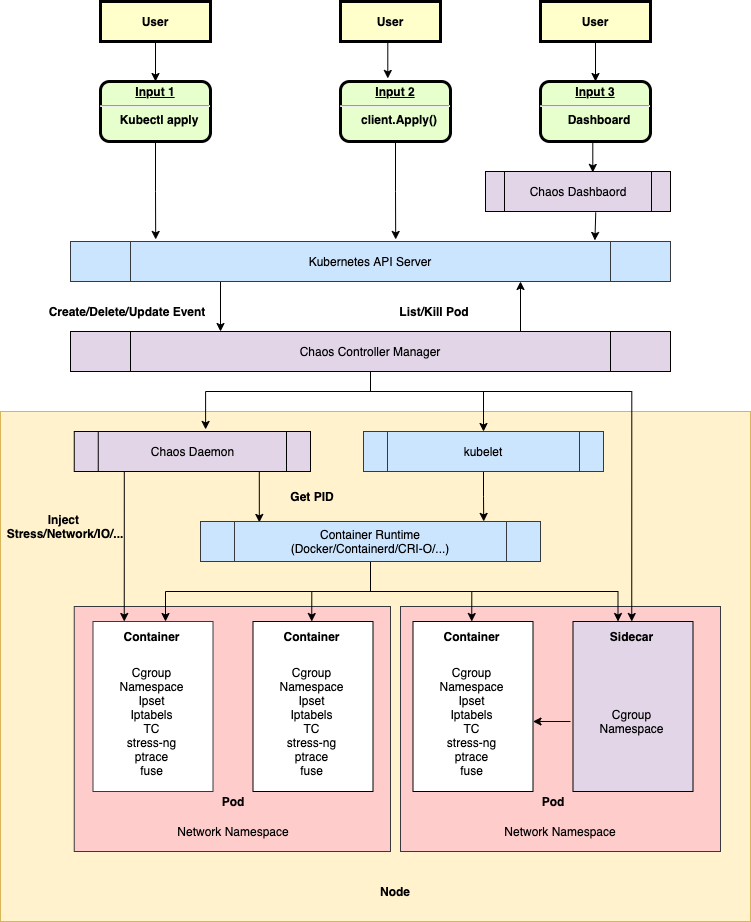
重要なポイント
- Chaos Mesh は Kubernetes CRD(Custom Resource Definition)として実装されている
- 各 Pod のネットワーク名前空間に入り込んで操作する
Chaos Meshの使い方
Chaos MeshはYAMLマニフェストとして定義できます。以下がマニフェストの例です
# このマニフェストにより、checkoutサービスからpaymentサービスへの通信に300msの遅延を発生させるNetworkChaosを作成する。
apiVersion: chaos-mesh.org/v1alpha1
kind: NetworkChaos
metadata:
name: delay
namespace: otel-demo
spec:
action: delay # 障害の種類をここで指定する
# 障害には以下のものがある。
# delay: ネットワーク遅延
# reorder: パケットの順序入れ替え
# loss: パケットロス
# duplicate: パケットの重複
# corrupt: パケットの破損
# rate: 帯域制限
# bandwidth: 帯域制限
mode: all # 対象のPodの選択方式
# modeの選択肢
# - one: ランダムに1つのPodを選択
# - all: 全てのPodを選択
# - fixed: 指定した数のPodを選択
# - fixed-percent: 指定した割合のPodを選択
# - random-max-percent: 指定した最大割合のPodを選択
selector:
namespaces:
- otel-demo # otel-demo名前空間内のPodが対象になる
labelSelectors:
app.kubernetes.io/component: checkout
# ラベルがapp.kubernetes.io/component=checkoutのPodを選択する
# checkout Podから出る通信に障害を起こす。
delay:
latency: "200ms" # 遅延時間を指定 -> 200ms (診断用)
correlation: "100" # 遅延が発生する確率を指定(100%なら必ず遅延が発生)
jitter: "0ms" # 遅延のばらつき(ジッター)を指定
direction: to # 通信の方向を指定
# directionの選択肢
# - to: selector->targetに障害
# - from: target->selectorに障害
# - both: 双方向に障害
externalTargets:
- 172.20.15.185:8080
# target:
# mode: all # 対象のPodの選択方式
# selector:
# namespaces:
# - otel-demo
# labelSelectors:
# app.kubernetes.io/component: payment
# # ラベルがapp.kubernetes.io/component=paymentのPodを選択する
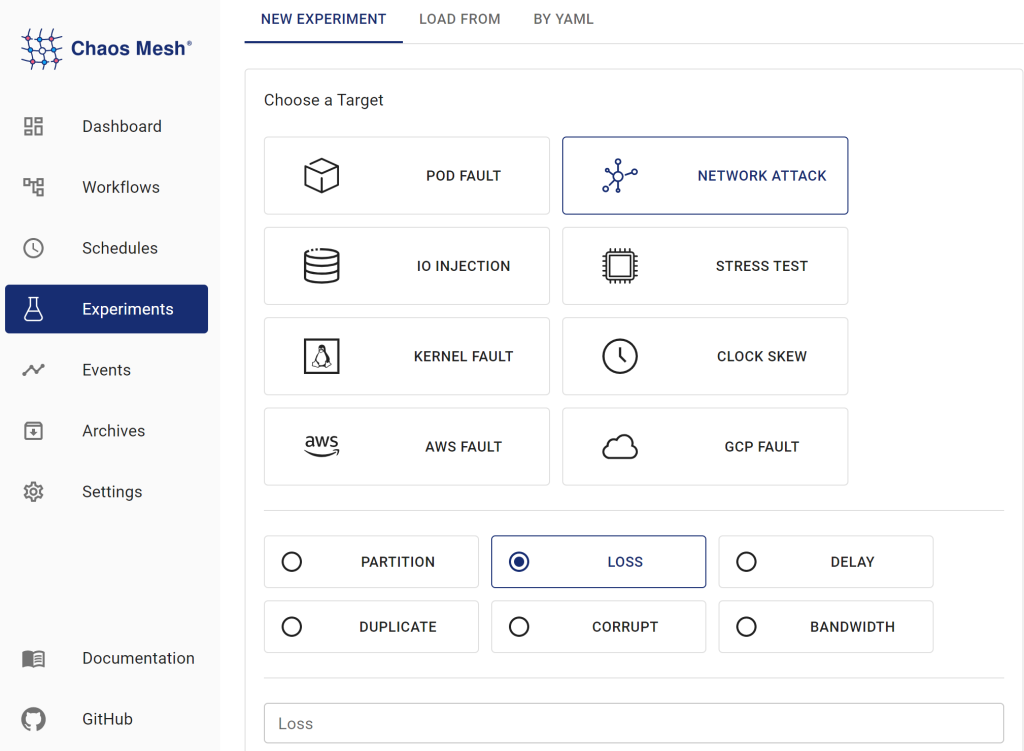
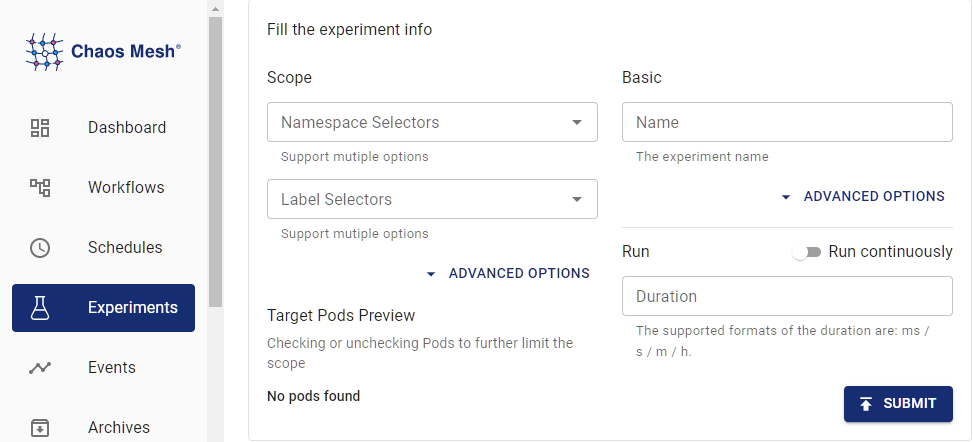
duration: "30m" # 障害を発生させる時間また、ChaosMeshにはGUIが用意されており、GUIから障害の注入、管理を行うことができます。
実験計画
ここからが本題になります。今回は、マイクロサービスの通信において一般的な問題である「ネットワーク品質の劣化」に焦点をおき、以下の二つの実験を行いました。
実験の目的
- ネットワーク遅延実験: 通信が遅くなった時、ユーザ体験やシステム全体にどう影響するのか
- パケットロス実験: 通信が不安定になった時に、エラー率はどのように変化するのか。
検証環境
環境はTerraformとHelmを用いて以下の構成で構築しました。
- 基盤: Amazon EKS
- 対象アプリ: OpenTelemetry Demo(マイクロサービスのサンプルアプリ)
- 障害注入: Chaos Mesh
- 観測: Jaeger, Grafana, Locust
- 負荷生成: Locust
今回実験で使用するアプリケーション「OpenTelemetry Demo」はOpenTelemetryプロジェクトが公式に提供しているマイクロサービスアーキテクチャで構築されたECサイトのデモアプリケーションになります。このアプリケーションには、Jaeger,Prometheus,Grafanaなどのツールも含まれているため、簡単にトレース、メトリクス、ログの可視化を行うことができます。
ベースライン測定
障害を注入する前にシステムの正常な状態を記録しました。
測定した指標
- Total duration(全体の処理時間)
- checkout → paymentのスパン時間
- checkoutとpaymentのError Rate
checkoutは、ユーザのショッピングカートの内容を取得し、注文の準備や決済処理、配送手配及びメール通知を統括しているサービスです。paymentは、指定されたクレジットカード情報に指定された金額を請求し、トランザクションIDを返すサービスになっております。
JaegerトレースでTotal durationとスパンの確認、Grafanaで2つのサービスのError Rateを確認します。
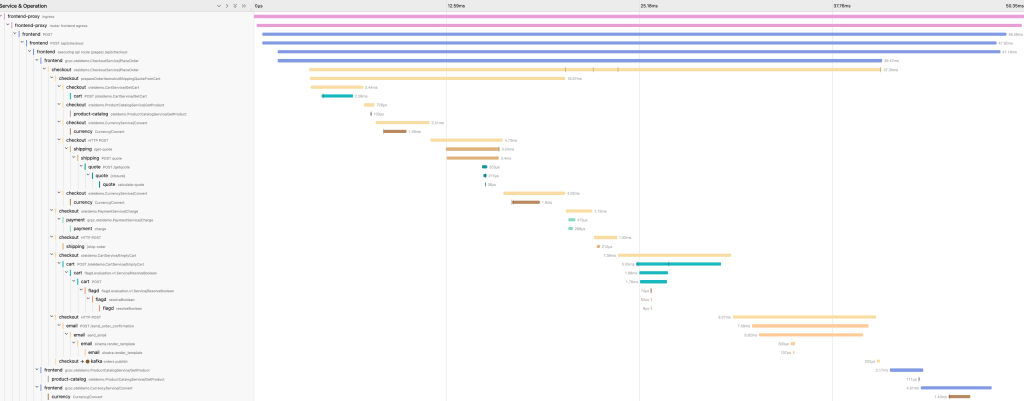

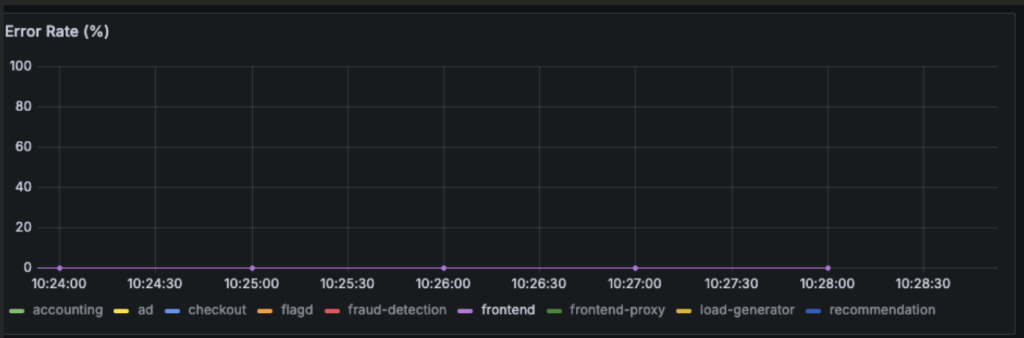
トレースが約50ms、checkoutのスパンが1.73ms,paymentのスパンが473μs
実験1: ネットワーク遅延注入
実験の目的
checkoutとpaymentの間の通信に遅延が発生した場合、ユーザ体験にどのような影響があるのかを検証しました。
200msの遅延の挿入
200msの遅延は、主観としては若干決済のときに遅延を感じたものの、そこまで気になるものではありませんでした。また、実験を行った13:35:40付近ではエラーが出ていないことがわかります。
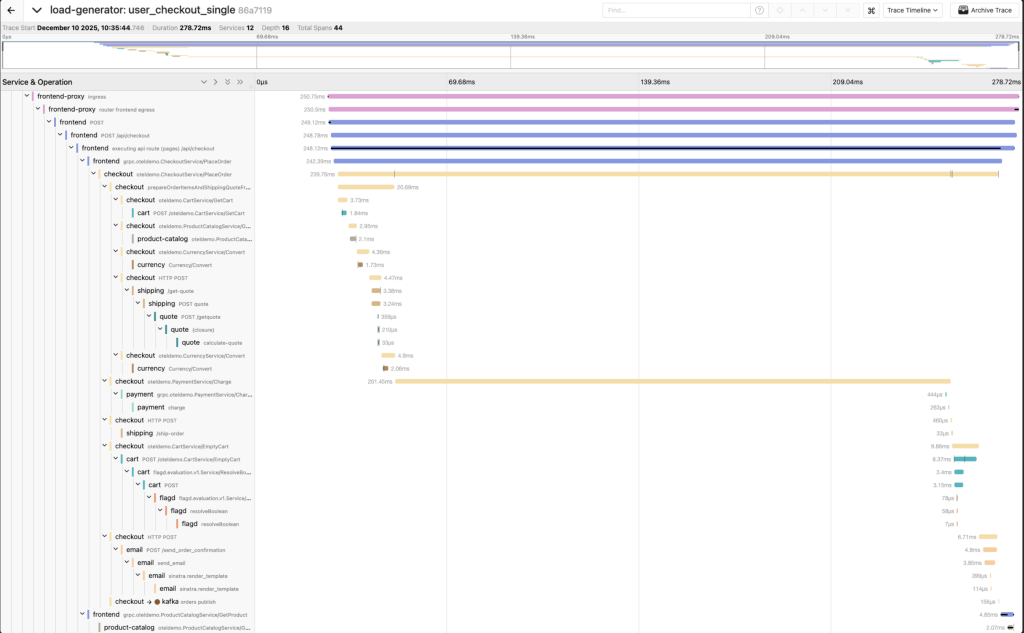

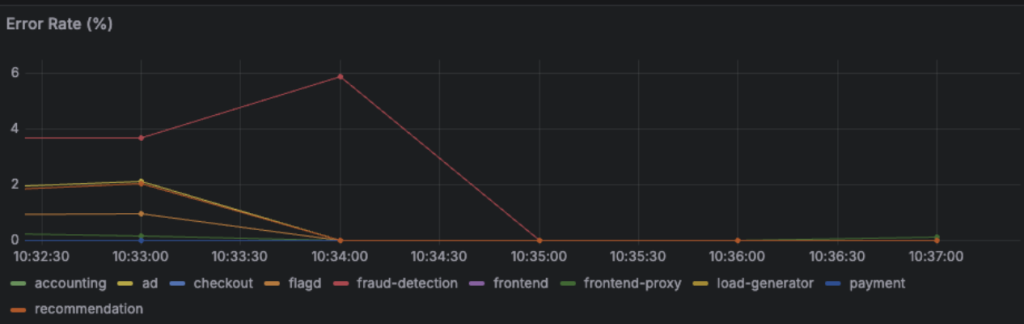
1000msの遅延の挿入
1000msの遅延では、決済時に不快に思う遅延を感じられました。また、Jaeger側で”A segment on the critical path of the overall trace/request/workflow”と表示されました。これは、checkoutからpaymentへのスパンがトレースの全体の処理時間を決定していることを意味します。1000msの遅延によって、全体に影響を及ぼしていることがわかりました。また、1000msの遅延ではエラーが出ないことがわかりました。

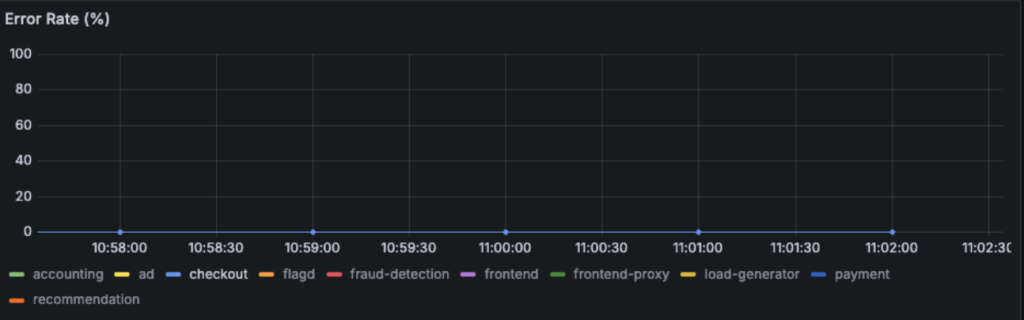
10000msの遅延の挿入
エラーが出るまで遅延を入れてみることにしました。checkout→payment,payment→checkoutの双方向に10000msの遅延を入れました。
結果
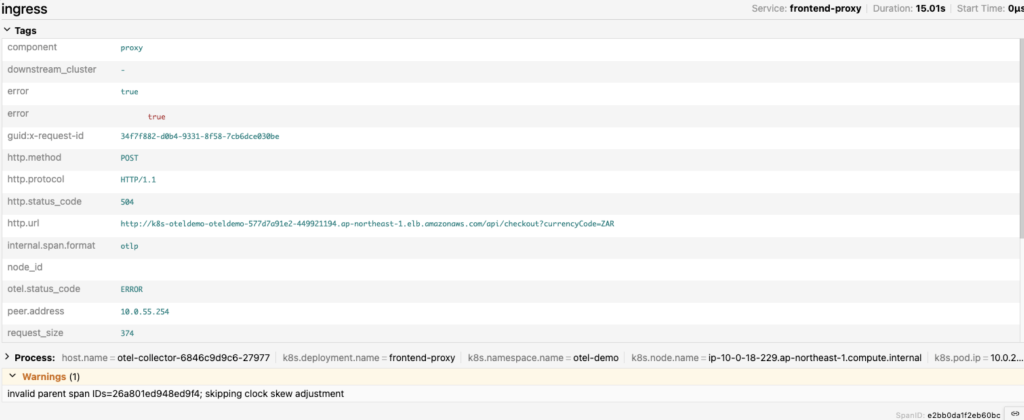
- Service: frontend-proxy
- Duration: 15.01s
- HTTP Status Code: 504(Gateway TImeout)
この結果からfrontend-proxyに15秒のタイムアウトが設定されていることがわかりました。
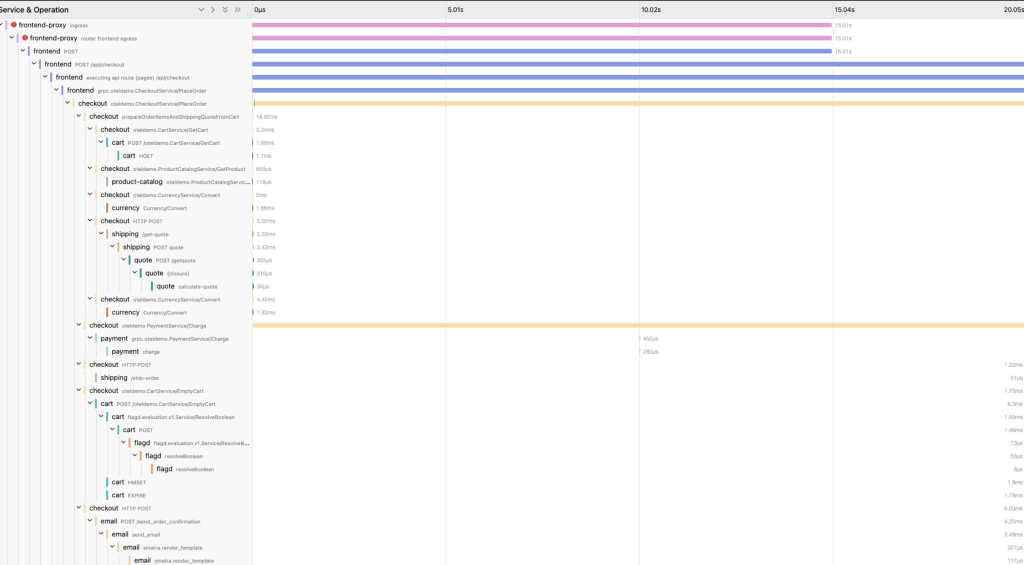
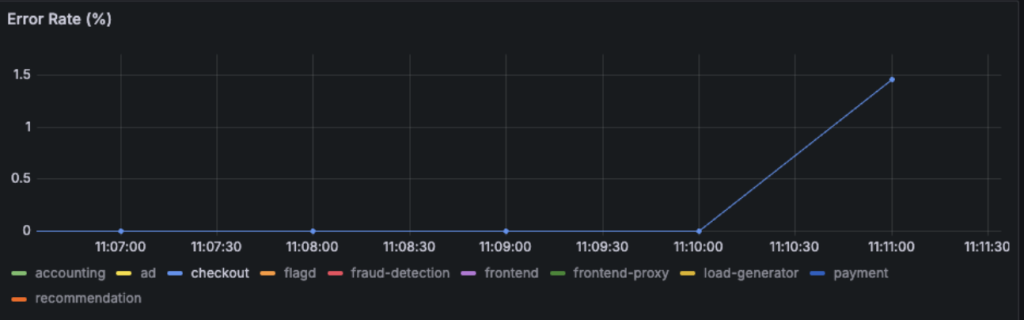
追加実験で、30s,40sの遅延を入れたが、frontend-proxyでしかエラーが確認できませんでした。
考察: なぜタイムアウトが発生しなかったのか
多くのサービスでタイムアウトが発生せず、延々と待ち続けてしまった原因として、 gRPCクライアントのデフォルト機能が考えられます。Go言語などのgRPCクライアントは、明示的に設定しないかりぎタイムアウトが無制限になることが多いです。
マイクロサービスでは、あるサービスが遅延・停止すると、依存している他のサービスにも影響し、最終的にシステム全体の性能低下や障害へとつながる可能性があります。
実験2: パケットロスの注入
実験の目的
ネットワークでパケットが失われる場合、システムがどのように振る舞うのかを検証しました。今回の実験では、エラー率とレイテンシーをLocustでリクエストを自動で送って確認しました。仮想のユーザを1000人まで、1秒に10人増やすように設定しています。frontendからの通信にパケットロスが起こるように設定しました。
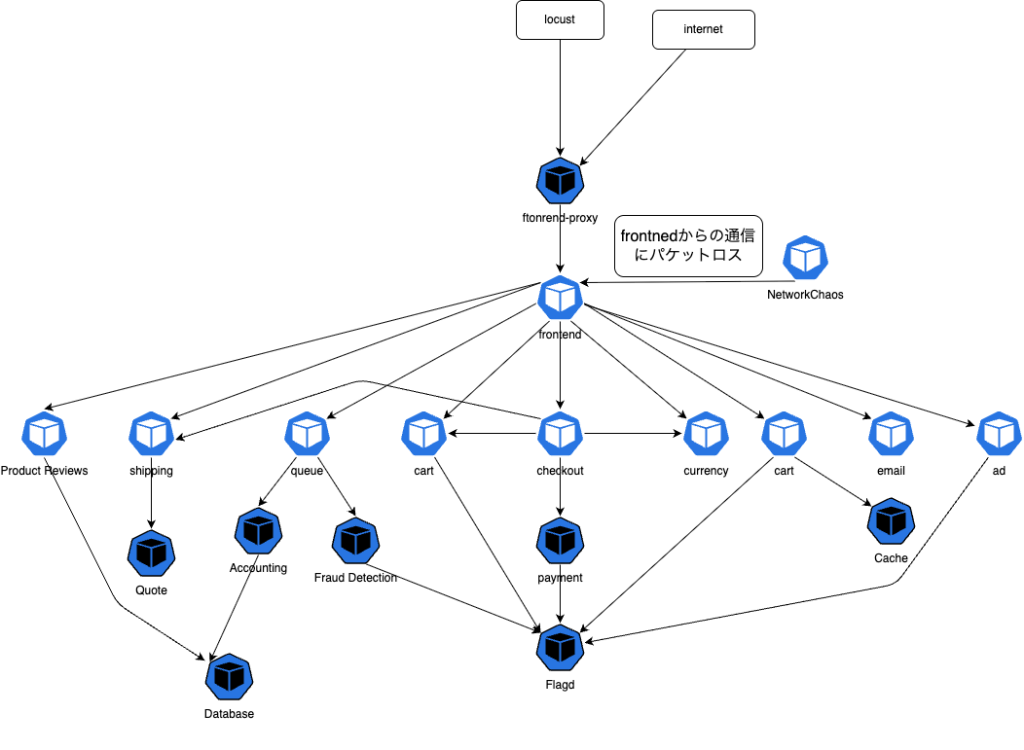
全実験結果のまとめ
以下の表は、パケットロス率を段階的に上げた全6回の実験結果です。
| 実験 | パケットロス率 | Correlation | Error Rate | Response Time (P95) | 状態 |
|---|---|---|---|---|---|
| ベースライン | 0% | – | 0% | 約800ms | 正常 |
| 実験1 | 10% | 0 | 0% | 約1,200ms | 正常 |
| 実験2 | 10% | 100 | 0% | 約1000-2000ms | 正常 |
| 実験3 | 30% | 100 | 0% | 約2,500ms | 使用困難 |
| 実験4 | 50% | 100 | 0.05-0.06% | 約2,000-2,500ms | 機能不全 |
| 実験5 | 70% | 100 | 20-50% | 約3,000-5,000ms | ほぼ停止 |
パケットロスなし
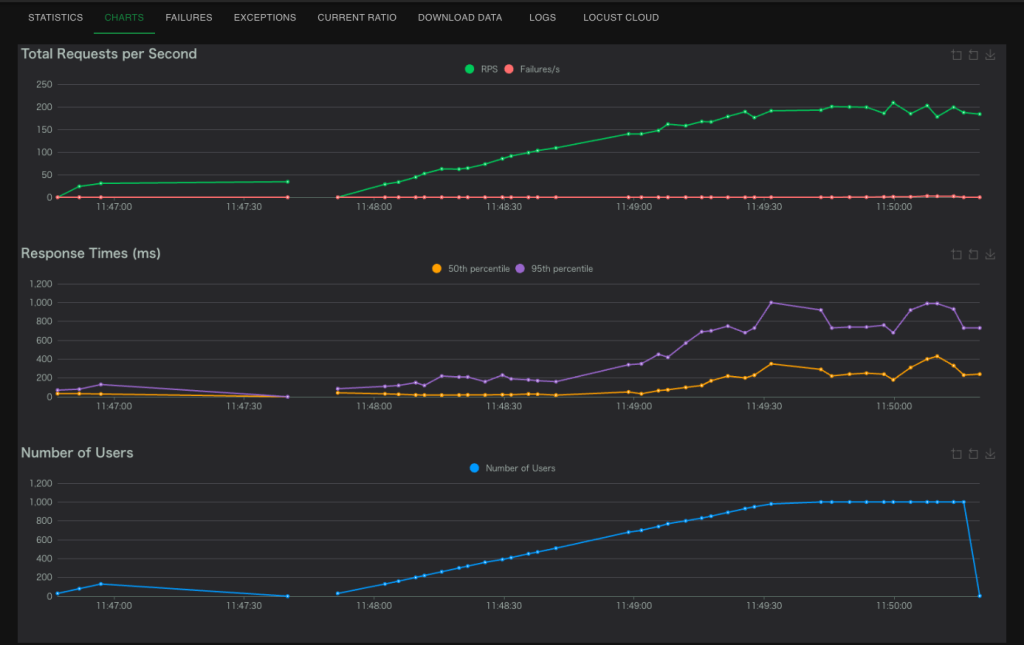
正常な状態では、Response Time(P95)は約800msでした。
10%のパケットロス(correlation:0)
Correlationパラメータを0に設定すると、パケットロスがランダムに発生します。
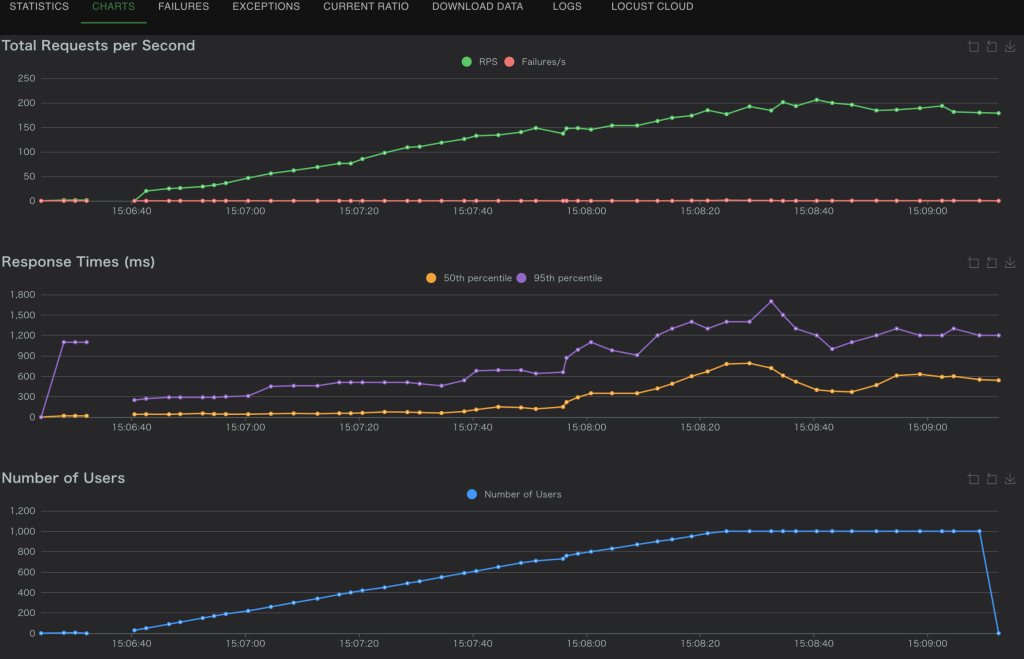
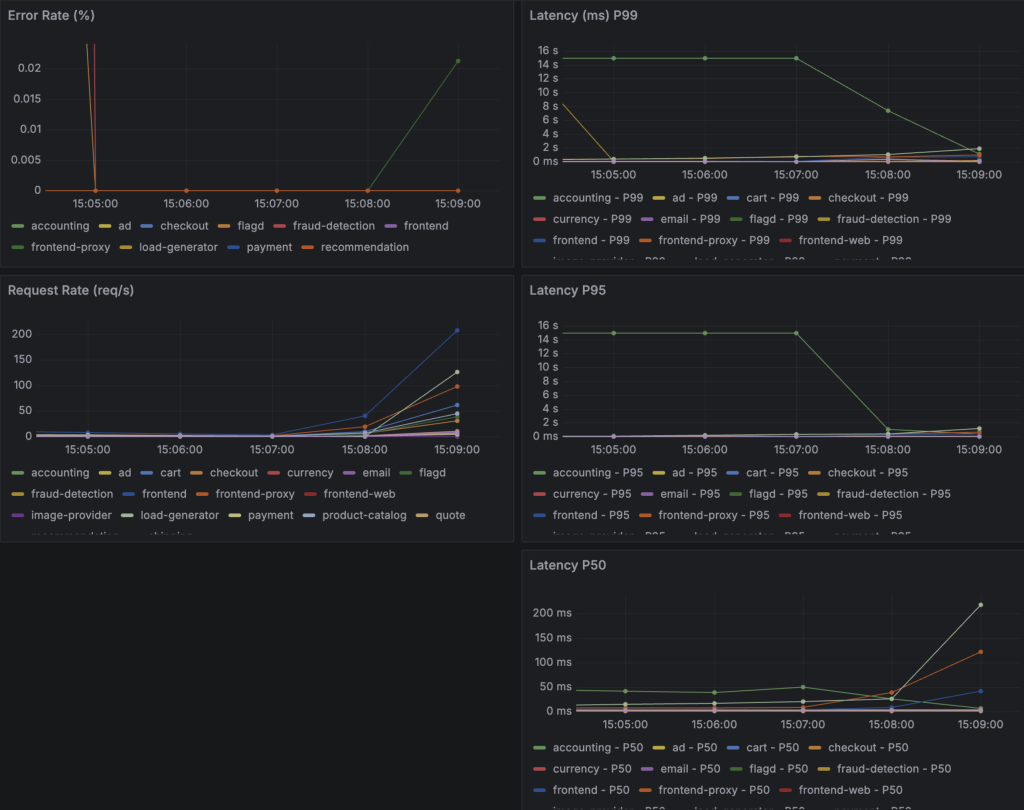
- Response Time(95): 1200sになって、若干遅くなった。
- Error Rate: 0%
- システムはほぼ正常に動作
10%のパケットロス(correlation 100%)
Correlationを100にすると、パケットが連続して失われます(バースト的)。
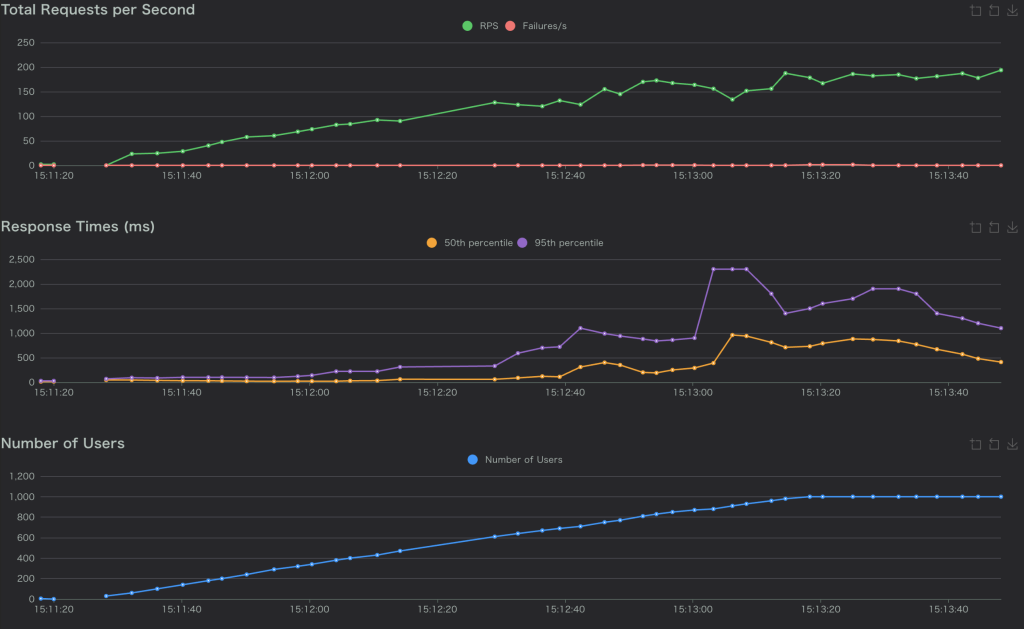
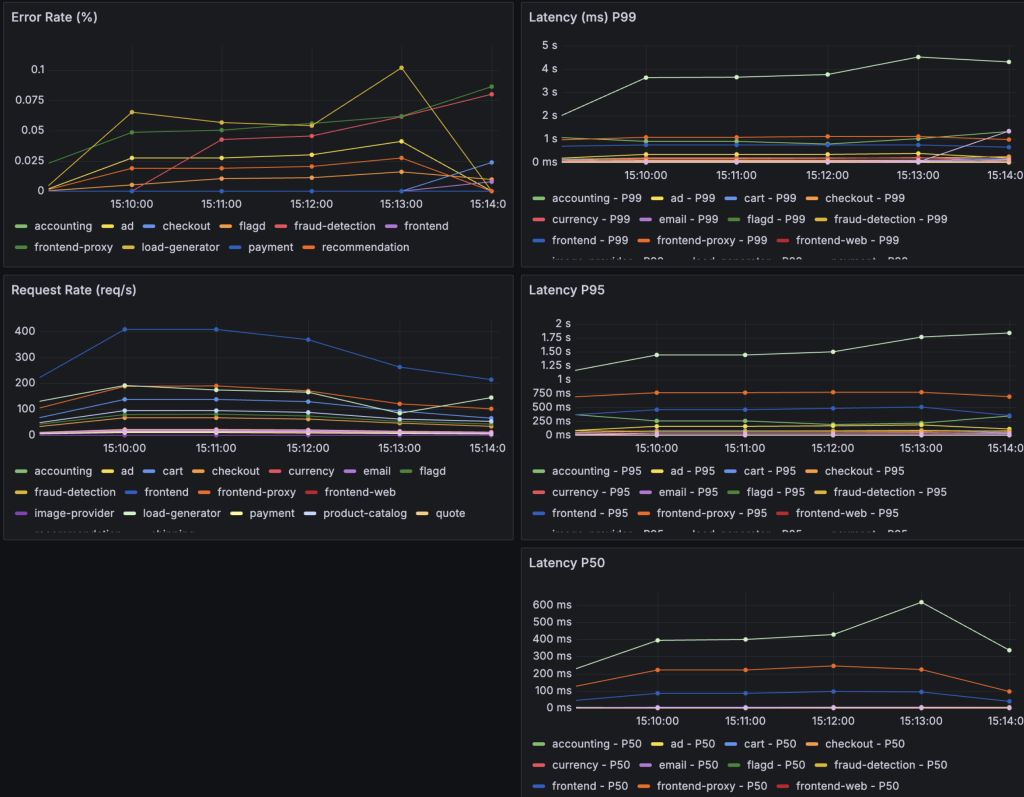
- Response Time(P95): 1000ms-2400ms程度となった
- Error Rate: ほぼ0%
- サイトも正常に動作していた
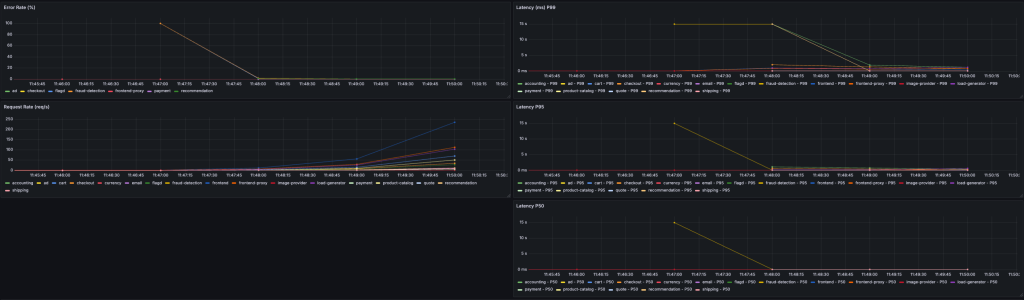
30%のパケットロス(correlation 100%)
ここから異変が起きました。
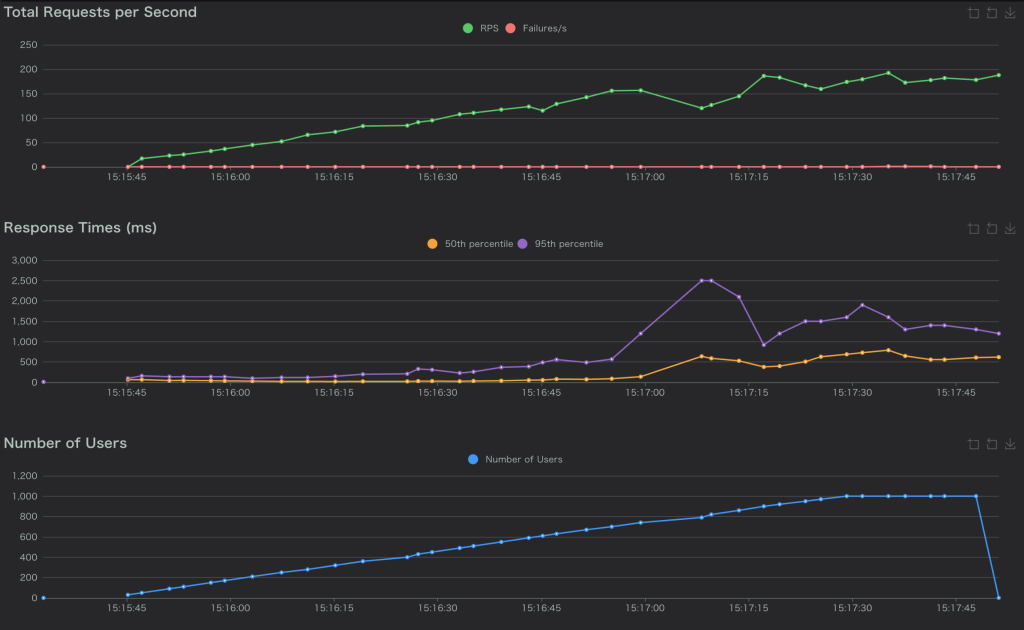
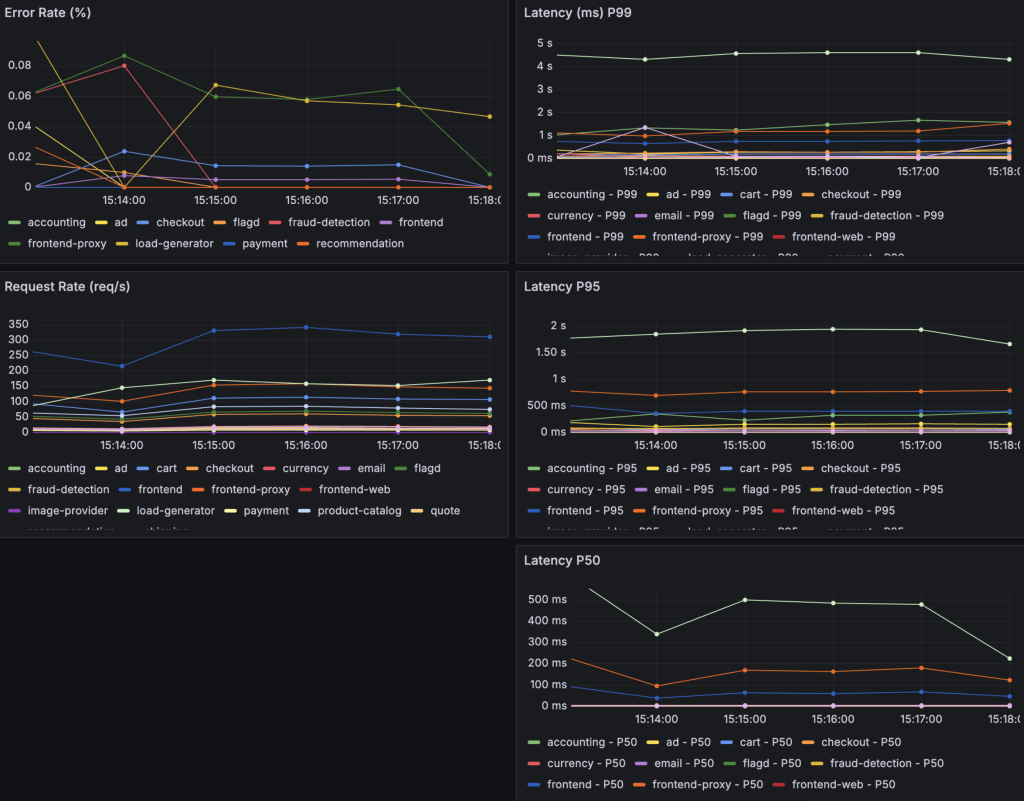
- Response Time(P95) :1000ms-2500ms
- Error Rate:30%の時より下がった
- 画像が表示されなくなったり、レスポンスがなくなったりした。
これは、予想外でした。エラー率は0%付近なのに、実際にサイトにアクセスすると明らかに使えない状態でした。
50%のパケットロス(correlation100)
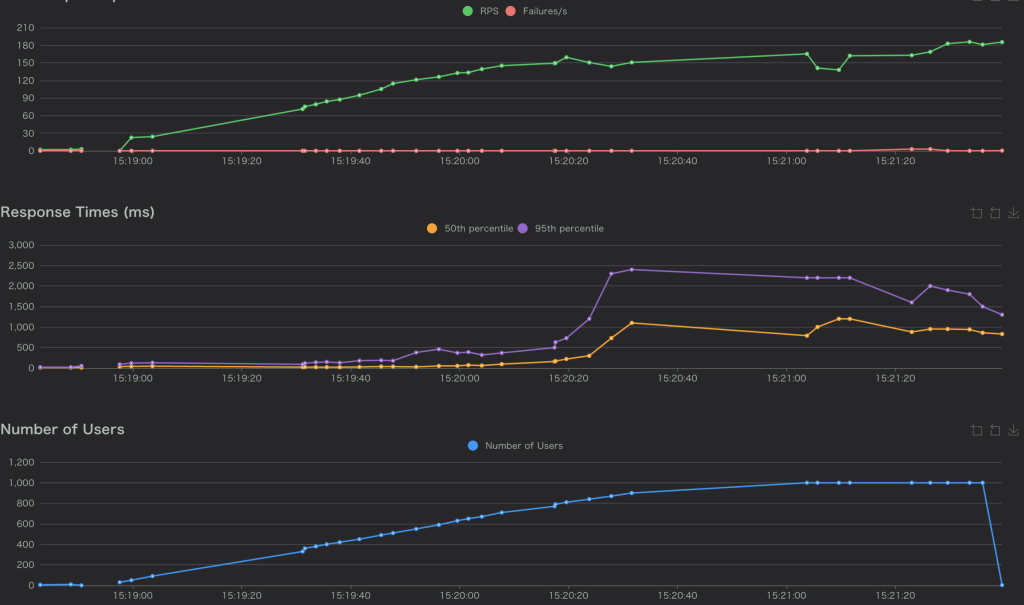
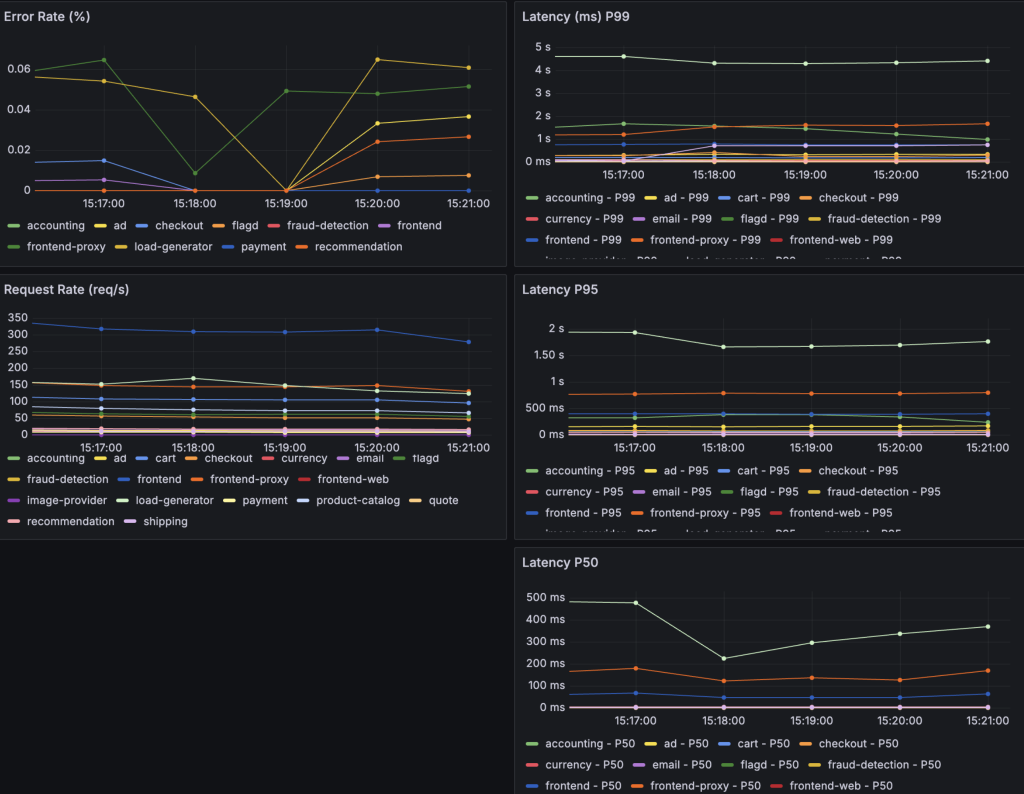
- Response Time(P95): 1500ms-2500msに平均的に数値が大きくなった。
- Error Rateがあまり変わっていないように思える。
- サイトがダウンした。
70%のパケットロス(correlation70)
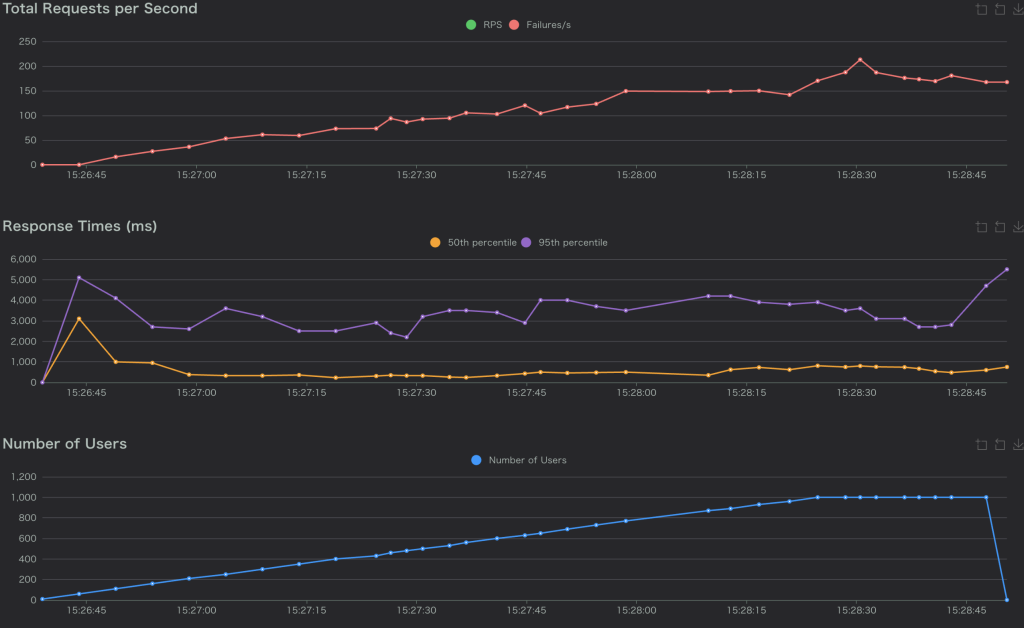
- Response Time(P95): 3000ms以上になっていた。
- リクエストがすべてFailureになっていた。
考察: なぜエラー率0%なのに使えないのか
Grafana上ではエラー率がほぼ0%と正常に見えているのに、実際にはサービスが使用できない状態になっていました。この原因として、通信プロトコルの再送やアプリケーションのリトライによってエラーが隠れてしまっている可能性が考えられます。
TCPはパケットロスを検知すると自動的に再送を試みます。例えば、単純化したモデルとして1回の送信成功率を70%(パケットロス 30%)とし、再送を最大3回まで行うと仮定した場合は次のように考えられます:
- 一回の通信成功率: 70%
- 3回リトライして全て失敗する確率: 0.3 * 0.3 * 0.3 = 0.027(2.7%)
- 最終的な成功確率: 100% – 2.7% = 97.3%
上記の計算はあくまで単純な確率モデルでの計算であり、実際のTCPの再送挙動や成功確率を正確に表すものではないことはご注意ください。この計算に基づくと、97%以上のリクエストは最終的に成功します。これによりモニタリング上のエラー率は低くでます。しかし裏側では再送を繰り返しているため、以下のようなことが起こり得ます。
- レスポンスタイムが数秒から数十秒に膨れ上がる
- ブラウザからは読み込み中のまま固まって見える
- 画像やAPIレスポンスが断続的にしか返ってこない
今回の実験で明らかになったのは「エラー率が低い=システムが健全」とは限らないと言うことです。パケットロスのような断続的な障害では、再送によってエラーが隠蔽されることがあり、ユーザ体験は著しく悪化します。
こうした気づきを踏まえると、Jaeger でリトライに関するエラーも確認しておくべきだったと感じています。また、成功リクエスト数やスループットといった指標についても併せて監視していれば、より正確に挙動を把握できたはずであり、これらは今回の反省点です。
ネットワーク障害にどう立ち向かうか
今回の実験結果を踏まえ、マイクロサービスの信頼性を高めるために必要な対策を3の観点でまとめました。
1. 早期発見: 死活監視だけでは不十分
実験2で見たように、HTTPステータスコード(200 OK)だけを監視していても、リトライによって隠蔽された障害には気づけません。ユーザ体験を守るためには、以下の指標を監視する必要があります。
- パーセンタイルレイテンシ(P95, P99): 平均応答時間は異常値を丸めてしまいます。前リクエストのうち最も遅い上位5%, 1%の動きを見ることで一部の通信が詰まっている兆候を早期に検知できます。
- SLO(Service Level Objective)の設定: 「エラー率1%以下」だけでなく、「99%のリクエストを500ms以内に返す」と言ってレイテンシベースの目標値を設定し、これを超過したらアラートを鳴らす運用が必要です。
2.回避策: サーキットブレーカー
リトライは一時的な瞬断には有効ですが、障害が継続している場合(今回のようなパケットロス)、何度も再試行することでシステム全体のリソースを浪費し、復旧を遅らせてしまします。
これを防ぐには、サーキックブレーカーパターンの導入が有効です。正常時には通信を通し、異常時には、回路を遮断しリトライせずにエラーを返すようになります。これによりユーザを待たせることなく、「混み合っています」と返答でき、バックエンドシステムの負荷を下げることができます。
3.データ整合性: 二重決済を防ぐ
今回の実験では触れませんでしたが、ネットワーク障害時に最も怖いのがデータの不整合です。例えば、checkoutサービスがpaymentサービスに決済リクエストを送り、決済は完了したが完了したレスポンスがパケットロスで消えた場合を考えます。
- checkoutサービスは、タイムアウトと判断する
- リトライを行い、もう一度決済リクエストを送る
- 結果、ユーザに二重課金が発生する
このような悲劇を防ぐには、ネットワークは信頼できないものという前提に立ち、アプリケーション側で冪等性を担保する必要があります。具体的には、トランザクション設計を適切に行うことことが必要になるでしょう。
感想
当初は「障害が見えにくい」という課題意識からスタートしましたが、検証を通じて「見えている数字(エラー率0%)が真実とは限らない」ということを学びました。
- エラー率だけでなくレイテンシ(P99)を見る
- リトライに頼りすぎず、サーキットブレーカーやタイムアウトを適切に設計する
- ネットワークは切れる前提で、冪等性を担保する
SREとして信頼性の高いシステムを作るためには、こうした「泥臭いネットワークの現実」を直視し、コードとインフラの両面からアプローチする必要があることを学びました。短い期間でしたが、教科書だけでは学べない「分散システムの痛み」を体験できた貴重なインターンでした。