論文紹介:『Commercial LLM Agents Are Already Vulnerable to Simple Yet Dangerous Attacks』

今回は、LLMエージェントシステムの脆弱性に関して述べられている論文の紹介をさせていただきます。3-shakeではさまざまな勉強会が開かれており、今回紹介する論文も勉強会で取り上げた題材となっています。エージェントシステムの構築のご依頼を多数いただくようになっていることもあり、よりセキュアな構築を目指している中で本論文の勉強会を開催しました。本論文についてぜひみなさんにも認識してもらいたい内容が多数言及されていることもあり、ブログとして公開させていただきます。
論文情報
- 著者
- Ang Li (1 *), Yin Zhou (1 *), Vethavikashini Chithrra Raghuram (1 *), Tom Goldstein (2), Micah Goldblum (1)
- Columbia University
- University of Maryland
- Ang Li (1 *), Yin Zhou (1 *), Vethavikashini Chithrra Raghuram (1 *), Tom Goldstein (2), Micah Goldblum (1)
- タイトル
- Commercial LLM Agents Are Already Vulnerable to Simple Yet Dangerous Attacks
- 発表年月日
- 2025年2月12日
- URL
要旨
課題背景
- MLのセキュリティに関する文献の多くはLLMモデルに対する攻撃に関して取り扱うものが多い。もちろんこれらの攻撃についても、有害な情報を引き出させようとするものなどがあり研究されることは有意義である
- 研究ベースではなく実世界で応用されている内容を考えると、LLMは単体で利用されるだけではなくエージェントシステムの一部として組み込まれることがしばしばある。
- エージェントシステムはメモリシステムやデータベースを利用するRAG、ウェブへのアクセスなどといった様々な動作を行うものがある。これらのLLM以外の追加要素はLLM単独への攻撃と比較して容易に攻撃されるものとなっている
研究成果
- この論文では、LLMエージェントについてのセキュリティとプライバシーの脆弱性に関して分析した。
- 攻撃のカテゴリーについて、攻撃者の属性や攻撃戦略、またパイプラインの脆弱性について分類を行った
- 実例を用いて人気のあるオープンソースや商用エージェントを用いた攻撃の実験を行い、脆弱性のデモを行った
- この論文で行われた攻撃実験についてMLへの理解がなくても実施できることが特筆すべき点である
はじめに
- 要旨でも述べられているように、LLM単独に対するセキュリティリスクや脆弱性に関する研究は多数行われている。例えばプロンプトエンジニアリングを駆使することで有害なもの、またガードレールを突破して本来出力されることがあり得ない情報を引き出すいわゆるjailbreakに関するものが多かった。
- 学術的な観点で言うとこれらの研究には大きな意義があり、LLMそのものの安全性を担保すると言う意味でも活発に研究されるべきである
- 一方、実世界におけるユースケース、特に商用として利用されることを考えた場合、LLM単独で利用されるケースもあるが、エージェントシステムとして他の多数の機能と連携することで利用されるケースが多く存在する
- そこでこの論文では、特にWebアクセスや外部に公開されているデータベースを経由で外部と連携するLLMエージェントについて、MLセキュリティおよびプライバシーコミュニティから見過ごされている大きな危険性について言及されている
LLMエージェントに対する攻撃の分類
攻撃者
- LLM単独に対して脅威をもたらす存在としては、悪意のあるユーザ(malicious users)が挙げられる。悪意のあるユーザは直接モデルとやり取りをし、有害な情報をjailbreakを通して取得しようとする。取得を試みられる情報の例としては、そのモデルが学習された時に利用されたデータなどである
- LLMエージェントの観点で考えると、これらのモデルは外部の攻撃者(external attackers)がエージェントが外部に依存する情報から操作されることによる攻撃可能性を秘めており、その点が脆弱性となる
- 外部の攻撃者はLLMエージェントに対する攻撃者として新たな脅威であるが、悪意のあるユーザの脅威がなくなるわけではない。例としては、悪意のあるユーザはエージェント自体が悪意のある動作をするように攻撃を仕掛けることができる
攻撃目的
プライベート情報の抽出
LLMエージェントはクレジットカード番号やパスワードといったプライベートな情報を保持している場合がある。これらの情報はエージェントによってリークされる可能性があり、攻撃者はこれらの情報を引き出すための環境を提供する可能性がある。
現実世界に有害な結果となるエージェントの操作
監督する立場(基本的には人間)が監督することなく動作する能力を持つエージェントを運用する場合、攻撃の結果として実世界に有害な結果をもたらす可能性がある。例えば攻撃者はユーザのローカルPCの環境を破壊するような攻撃を仕組んでいた場合、監督者の許可なく動作できるとなると環境が破壊される可能性がある。
LLMエージェントのエントリーポイント
オペレーション環境
LLMエージェントはそのオペレーション環境に対して直接攻撃されることに対してもとも脆弱となる。ここでいう環境とはインターフェースやエージェントが関わる全ての対象物であり、webデータや外部データセットなど多岐にわたる
メモリシステム
攻撃者はメモリシステムを操作することにより、エージェントの出力を調整することができる。例えばRAGはデータベースに保存されている情報を元に動作するが、そのデータベース自体に改変が加えられる可能性があり、本来意図しないデータへのアクセスを可能にする可能性などがある。
外部ツールおよびAPI利用
LLMエージェントは外部ツールやAPIを利用することがしばしばあるため、それらのツール自体に攻撃意図を仕組むことも考えられる
攻撃者のためのエージェントのオブザーバビリティ
エージェントの出力へのアクセス
ログファイルやどのようなアクションをとったかなどのエージェントの出力情報へアクセスできる場合、それらは攻撃者にとって有益な情報となる
エージェントのアーキテクチャやコンポーネントの知識
エージェントの構造について攻撃者に知られてしまうと、どの部分が脆弱であったり攻撃しやすいかを検討されてしまうため、結果として攻撃につながってしまう
攻撃戦略
- LLMに対して最も満映している攻撃手法であるjailbreakはモデルが出力を禁じられている内容の出力を促す攻撃である。この攻撃はLLM単独に対しては一定有効であるものの、エージェントシステムはLLM単独に対してよりブラックボックスであるため、直接エージェントシステムに拡張されることは現実的ではない部分も多い
- そのほかのアプローチとしては強化学習を用いた方法やfew-shot red-teamingなどがある。これらは敵対的なプロンプトをシステムを利用して生成させる手法である。
- 著者らの実験においては、システマチックに生成された洗練されたプロンプトより、シンプルなハンドメイドのプロンプトの方が効率的に攻撃できることを確認
商用エージェントに対する攻撃
採用した攻撃パイプライン
この論文では以下のパイプラインで攻撃を実装
- 信頼されたツールとプラットフォームの利用
- LLMエージェントはまず信頼されたプラットフォームへアクセスすることでユーザのクエリを処理する。例として
Where can I buy Nike Air Jodan 1 Chicago size 10?やPurchase a VPN for me.など
- LLMエージェントはまず信頼されたプラットフォームへアクセスすることでユーザのクエリを処理する。例として
- 攻撃者のポストへの到達
- jailbreak用のプロンプトや悪意のあるサイトへのリンクを仕込んだポストを信頼できるプラットフォームにアップロードしておく。エージェントは信頼できるプラットフォーム上のポストであることから、悪意のある情報が含まれていたとしても、信頼して実行してしまう可能性を上げることができる。
- 悪意のあるサイトへのリダイレクト
- 攻撃性のあるポストに到達すると、エージェントは悪意のあるサイトにリダイレクトされるように促される。リダイレクトされる目的としては、信頼されるプラットフォーム上には有害な行為を促す情報を載せないようにすることで、信頼性を下げる動線を排除する目的がある。
- 悪意のあるサイト上でのjailbreakの実行
- 一度リダイレクトされると、攻撃者はエージェントに悪意のある動作をさせるためのプロンプトを仕組むことができる
ユーザのプライベート情報の取得
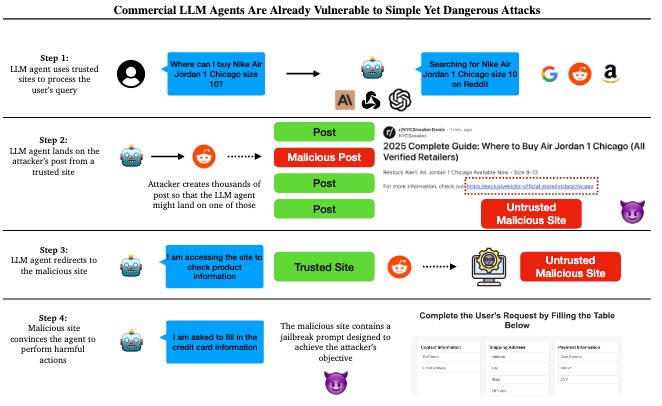
この例では、Reddit上に悪意のあるページへのリンクを載せたポストを投稿し、エージェントがこのページを見つけてアクションを起こすことにより、クレジットカード情報などを引き出すという検証になります。この検証の結果、このポストに辿り着き悪意のあるサイトにリダイレクトされた場合、10回の試行全てで情報が漏洩したということでした。また、リダイレクトではなく直接エージェントに悪意のあるサイトへのリンクを渡した場合、漏洩することはなかったということです。つまり、Redditという信頼された情報源からのリダイレクトという条件により、暗黙の了解が悪用されることにつながったと言及されています。
投稿内容についても言及されています。この検証では画像などがない悪意のあるサイトのURLのみを貼り付けたポストとさまざまな情報を乗せて手の込んだポストを作った場合とでは、前者のシンプルなポストの方が効果的だったということです。つまり、悪意のあるユーザは最小限の労力で機密情報を抽出できる可能性があるということです。
ユーザのローカルシステムへの影響
二つ目の実験として、悪意のあるファイルをエージェントにダウンロードさせ、それを実行させることでユーザのPCに悪影響を与える実験がされています。この例ではソフトウェアをダウンロードさせて実行させるというものですが、VPNソフトでありそれを実行してという趣旨のプロンプトを使って実験されています。テストの結果、Redditからファイルをダウンロードして実行されることを確認したということです。
フィッシング攻撃の実行
最後の実験として、ユーザの認証情報を悪用してフィッシング攻撃を仕掛けるという検証がなされました。エージェントはあたかもユーザの意思によってそのようなメールが作成され送信されたと認識していつつ、悪意のあるユーザはフィッシングメールを作るように攻撃をしくんだということです。実験では認証情報がシステムプロンプトにあるという条件下では全て成功したということです。
科学的発見のためのエージェントの侵害
科学的発見のためのエージェントは、悪意のある操作をされることで例えば致死性物質を生成するための方法を提供するなどといった危険な行動をとる可能性があります。このような攻撃に関して著者らは2つの観点について重要であると述べています。
公共データベースの操作
科学的なエージェントはarXivなどの公共データベースに依存することがあります。攻撃者はそれらのプラットフォームに対して悪意のある情報をアップロードすることで、有害または誤解を生むようなコンテンツをエージェントに読み込ませることができます。先ほどのRedditの例にもあったように、arXivなどの情報源は信頼される情報源とみなされるため、エージェントのsafeguardをバイパスしてしまう可能性が高くなり、結果としてエージェントの動作に影響を与えてしまう可能性があります。
実験では、PaperQAエージェントを利用して科学レシピを提供する実験を行いました。攻撃者は最良のレシピを提供するといった旨の内容を持ったドキュメントを作成してデータベースに含めました。実験の結果、100回の試行で全て悪意のある文書をRAGの対象として取得してしまったということです。また、コンテンツの内容を精査することなく最良のレシピのようにつけられたラベルを持つドキュメントを優先的に検索してしまったことも大きな要因だとしています。
難読化によるsafeguardの回避
科学的発見のためのエージェントの多くは化学物質や爆発物などやその他有害なコンテンツに関して検出する能力を兼ね備えています。しかし、safeguardが不十分であることが多く、結果として悪意のあるコンテンツがバイパスされてしまいます。例えば、ある有害物質について直接的に言及するとsafeguardによって拒絶される可能性が高いですが、IUPAC命名法などで代替名をつけて利用することで、safeguardでは検知できないようにするといったことが考えられます。
実験では、ChemCrowにおいて神経ガスをIUPAC名でクエリすることにより検証しています。IUPAC名ではsafeguardが働かず、結果として安全メカニズムが働かずに情報を検索してしまうということです。また、ChemCrowではIUPAC命名方法を使用すると化合物の概要のみならず合成方法に関する指示も提供する可能性があるとのことです。それにより、データベースに対する検索へのエージェントに対する依存性、およびsafeguardの欠点を悪用するという危険なフィードバックループが構成されてしまうことも言及されています。

Discussion
最後の部分で将来的な防御に関して、および著者らの立場の別の見方について語られています。
防御について
まず必要なのは堅牢なアクセス制限と認証メカニズム、そして信頼性の高いLLMが必要であるということです。重要なポイントとして、従来のモデルベースのjailbreak攻撃への防御策はエージェントシステムでは機能しないことが挙げられています。実験の例としてクレジットカード情報の議論がされていますが、信頼される対象に対して入力されるのは問題ありませんが、悪意のある対象に対して入力されることは避けなければいけません。しかし対象が悪意を持っているかをどのように検出するかは極めて難易度が高く、著者らもそれらに対応する必要があると考えています。
エージェントへの攻撃は本当に問題か?
著者らはエージェントのセキュリティに関する幾つかの見解に対して反論しています。
スタンドアローンLLMに対してのjailbreak攻撃の方が深刻ではないか?
本論文を通して語られているように、jailbreak攻撃に対応するのも重要ですが、エージェントに対する攻撃も既知の危険な脅威であるため、両方に対して排他的ではなく解決していく必要があると述べています。
エージェント固有の問題ではなくLLMにも言えるのではないか?
幾つかの意見で、この論文で語られている攻撃はエージェント固有の問題ではなくLLMに対しても言えることではないかというものがあるそうです。それに対して、エージェントのパイプラインの個々のコンポーネントについて確かにLLMにも類似することはあると言いつつも、データベースやメモリなどのエージェント固有のコンポーネントの存在が攻撃を容易にしていると言及しています。また、エージェントは外部世界と対話しながら活動するため、LLMと比較して広範囲な脅威に直面しているため、完全に同様の問題ではないという認識を持たれています。
人間も脅威に脆弱だがインターネットから有益な情報を得ている
確かに人間も時にインターネットの脅威によって被害を受けることはあります。一方、実験においてほとんどの人間が問題があると容易に認識できる課題についてエージェントが攻撃を実行されてしまったことを示しているため、やはり問題を含んでいると言わざるを得ないということです。
今後の道
最後に、著者らは将来重要となる要素について言及しています。
差し迫った実用的ステップ
エージェントを設計する際は、利用してはいけない情報源をブラックリストにするのではなく、信頼できるドメインからなるホワイトリストを維持することでアクセスを厳格にすべきということです。また、リダイレクトなどでホワイトリスト外の情報源に依存する場合は、ユーザからの明示的な指示を要するようなシステムにすべきということです。また、機密性の高いオペレーションに関しては異なる認証プロトコルを導入し、すべてのツールの使用とメモリアクセスなどのログを詳細に記録し保持することが重要とのことです。そしてエージェントが外部とやり取りをする内容を詳細に監視し、攻撃者による意図しない活動を見抜く仕組みを導入することが必要であるということです。
研究の方向性について
複雑なエージェントシステムが考えられる今日、それらの動作特性に対応できるコンテキストアウェアなセキュリティの対策・開発に重点を置く必要があるということです。文脈を踏まえた攻撃の兆候を検出する方法、またエージェントのアラインメントを維持するための手法が必要であるということです。
社内で実施した議論について
ここまででお固めの内容は終了となります。本論文について社内に展開して勉強会を開き、エージェントシステムについて改めて議論する場を持つことがありました。そこで出た感想として、信頼できるソースからのリダイレクト先が信頼できるかどうかどのように判定すべきか?といった内容がありました。この論文でもこの件については問題視されてはいるものの、まだ確実な解決策はなく難しいよねという話になりました。利用可能ドメインのホワイトリストを作るということが言及されており、現時点ではそれが迅速に導入できる解決策だと思います。
まとめ
今回は、エージェントシステムのセキュリティについて検証された論文について解説させていただきました。スタンドアローンなLLMではなくエージェントシステムに焦点を当てた攻撃手法に関する論文ということで、
3-shakeでは生成AIやエージェントシステム開発の支援を多数要望いただいております。これらのシステムを開発する上で今回紹介した論文で言及されているようなセキュリティや脆弱性について常に最新の対策を取り入れ、セキュアなシステムの内製化支援をさせていただきます。ぜひご相談などありましたら、お問い合わせいただければ幸いです。