
はじめに
Sreake 事業部の芳賀雅樹 (@silasolla) です.
以前の記事で Spanner が Paxos による分散合意と TrueTime を使って,データの整合性といったストレージ層の難しい問題をどう解いているのか紹介しました.TrueTime のおかげで,Spanner は世界中に散らばったノード間でもイベントの前後関係を正しく判定し,外部整合性を保証できます.
ただし,データの整合性が保たれることと,クエリが実用的な速さで返ってくることは,別の問題です.Paxos や TrueTime はデータの矛盾を防ぐ仕組みであって,ノード間の距離そのものを縮めてくれるわけではありません.
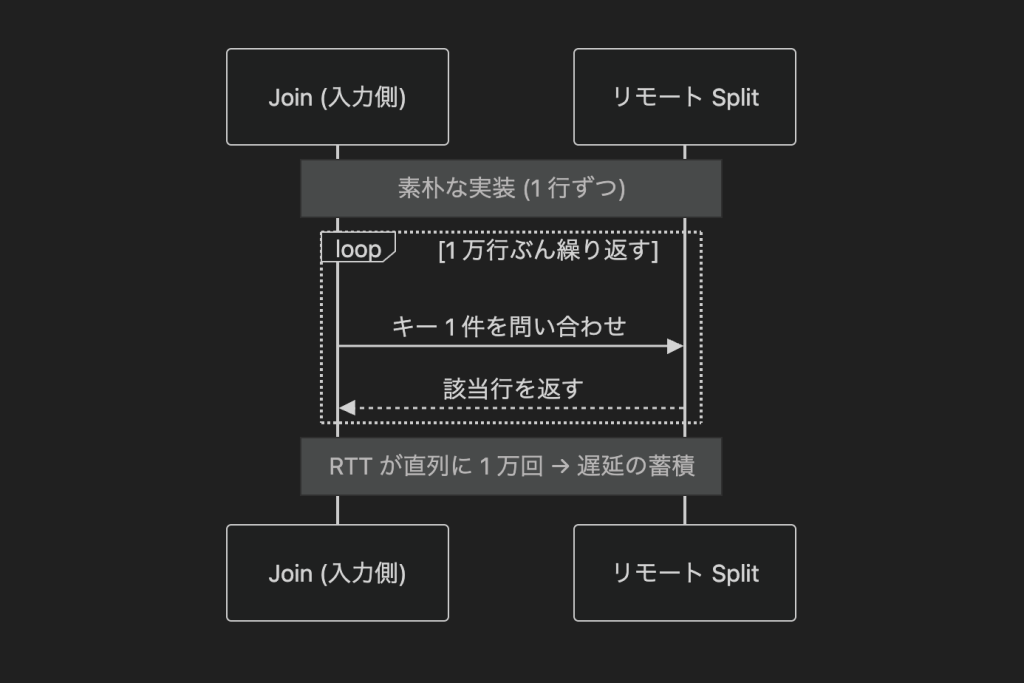
東京のサーバから米国にあるデータを読みに行けば,光速をもってしても往復には遅延が生じます.日米間の往復遅延 (RTT) を仮に 100 ms としましょう.かなり極端な例ですが,もしも JOIN が 1 行ごとにリモートへ問い合わせるような実装だったらどうなるでしょうか.単純計算で 100 ms × 10,000 回 = 1,000,000 ms ≈ 16.6 分 と,1 万行を結合するだけで 16 分以上掛かり,アプリケーションはタイムアウトしかねません.TrueTime はデータが正しいことを保証してくれますが,データを「速く持ってくること」については何もしてくれないわけです.
この記事では,こうした距離の問題を Spanner がどう乗り越えているのか,ソフトウェアの工夫を見ていきます.F1 から受け継いだクエリ処理のやり方や,データを動かさずにその場で計算する仕組み,通信回数をまとめて待ち時間を隠す結合アルゴリズム,そして分析クエリのコストを下げるストレージ形式と,“Spanner: Becoming a SQL System” [1] に沿って,整合性を維持するストレージ層ではなく,性能を稼ぐコンピュート層の工夫を順に見ていきます.
分散 KVS が SQL を獲得するまで
Spanner のクエリエンジンを掘り下げる前に,Spanner 自身がどう育ってきたのかを振り返ります.2012 年に OSDI で論文が発表された当時,Spanner はまだ SQL をネイティブサポートしていませんでした [2].当時の Spanner は「ACID トランザクションを備えた分散 Key-Value Store (論文の表現では semi-relational)」であり,API も Read や Commit といったプリミティブなものに限られていました.多くの開発者がこの強力な KVS の上にアプリケーションを組もうとしましたが,スキーマ定義やまともなクエリ言語がないことは,開発生産性を大きく損なってしまいます.
そこで Google の広告システム (AdWords, 現 Google Ads) は Spanner の上に “F1” という別のサービスを載せて,これを SQL エンジンとして使っていました [3].F1 が SQL を解釈し Spanner がデータを保持するという役割分担です.F1 は Spanner のキー範囲を取得する API の上で動く疎結合な構成で,この形のまま,広告データを sharded MySQL から移行しきりました.トランザクショナルな NoSQL コアの上に,スケールする SQL システムが作れることを実証したわけです.
しかしながら,ストレージから切り離された場所でクエリを処理する構成には弱点があります.フィルタや集計をするのに,必要な生データを一旦ネットワーク越しに引き抜かなければならず,計算をデータの近くに寄せる余地を活かせません.これは F1 に限った話ではなく,Spanner が最初に「後付けで」作った自前のクエリ層 (高レベル API を外部アプリのように叩くだけの実装) にも当てはまる弱点でした.
この反省を踏まえて,Spanner は F1 で得た知見を取り込みつつ,SQL をアーキテクチャにネイティブかつ密結合に組み込む方向へ進みました.そして,クエリプロセッサが Spanner のストレージ構造を直接活用し,データのある場所まで計算を押し込めるようになりました.データを計算ノードに集めてくるのではなく,計算をデータ側に送るという発想の転換です.
これを支えているのが,コプロセッサフレームワークと呼ばれる仕組みです.名前に「コプロセッサ」とありますが,これはハードウェアのことでも,HBase のように「サーバ側でユーザのコードを実行する仕組み」のことでもありません.Spanner のそれは,リクエストを「どのサーバへ」ではなく「どのキー (範囲) へ」という形で投げられるようにする RPC の抽象です.宛先のキーを持つ Paxos グループ (データの複製を管理する単位) を特定し,整合性の要件を満たす最寄りのレプリカにリクエストをルーティングします.実行の途中でデータが分割されたり移動して持ち主が変わったりしても,透過的に繋ぎ直してくれます.クエリプロセッサは,この抽象の上で各シャードにサブクエリを配っていきます.
Distributed Union と分割可能性
Spanner が受け取る SQL は,論理的には 1 つのテーブルに対する操作です.しかしながら,その実体は行の範囲ごとに分割され,数千台のサーバに散らばっています.この分割の単位を Spanner では Split と呼びます (論文中では Shard と表記されています).クエリコンパイラがまずやるべきことは,こういった「論理的には 1 つ」という情報と「物理的には分散している」という事実とのギャップを埋めていく作業です.
ユーザからクエリを受け取ったコンパイラは,論理的なテーブルスキャンを「各 Split に対するスキャンの集まり」に変換します.このとき挿入されるのが Distributed Union という演算子です.各 Split にサブクエリを配って,返ってきた結果を連結するのが,この演算子の役割です.実際に Spanner のクエリ実行計画を眺めてみると,テーブルスキャンのすぐ上に Distributed Union が載っているのを見かけるはずです.
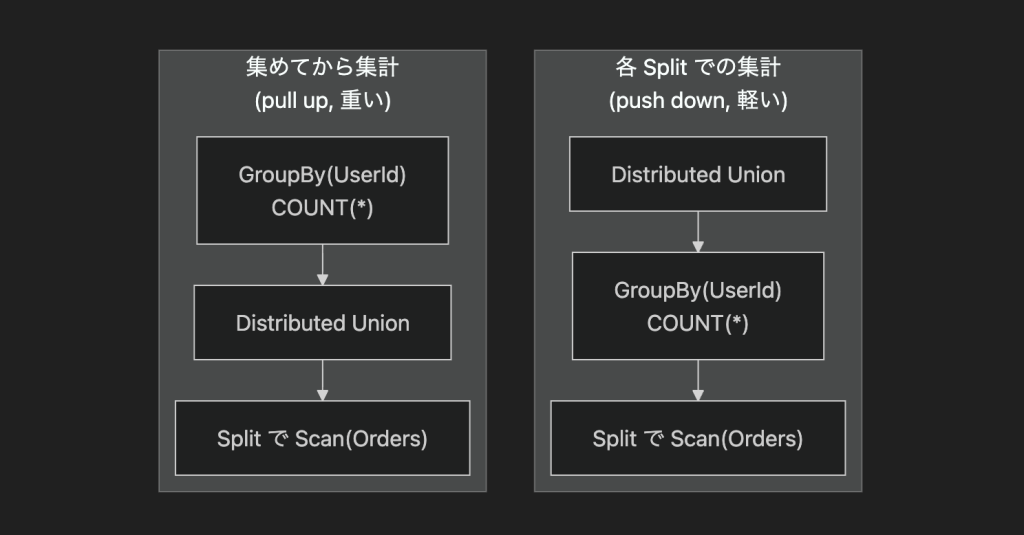
計算を効率化するために,コンパイラはクエリツリーを大きく書き換えます.ここでやることは,結果を束ねる Distributed Union をツリーの上のほうに引き上げること (pull up) と,フィルタや集計といった演算子を各 Split のローカル処理に押し下げること (push down) の 2 つに大きく分けられます.イメージとしては,全ての支店での売上明細を一旦本社に集めてから集計するのではなく,各支店で先に集計し,その小さな結果だけを本社に送るようなものです.重い処理をデータに近い Split 側に寄せることで,ネットワークを流れるデータ量を抑え,分散したリソースを使い切るというのが Spanner の基本戦略です.
ただし,この押し下げが常にできるとは限りません.ある演算子を Split 側に押し込んでよいかどうかの判定基準を,論文では分割可能性 (partitionability) と呼んでいます.たとえば,次のようなテーブルとクエリを考えてみましょう.
CREATE TABLE Orders (
UserId INT64,
OrderId INT64,
Amount INT64,
) PRIMARY KEY (UserId, OrderId);
-- ユーザごとの注文件数
SELECT UserId, COUNT(*)
FROM Orders
GROUP BY UserId;
データは主キーの先頭にある UserId でシャーディングされ GROUP BY も同じ UserId で行われます.Spanner は範囲シャーディング (キーの連続した範囲ごとにデータを分割する方式) を採るため,ある UserId の行は全て同じ Split に収まります.つまり各 Split の中だけで集計を完結でき,この演算は分割できるとコンパイラが判定します.結果として GROUP BY は Distributed Union の下に押し下げられ,Spanner がネットワーク越しに集めるのは,Split ごとに集計済みの小さな結果のみになります.
ルーティングを担う Range Extraction
クエリを効率よく分散させるためには,そのデータがどの Split にあるのかを正しく知る必要があります.これを担うのが Query Range Extraction と呼ばれるプロセスです.
Extraction (抽出) といっても,データそのものを取り出すわけではありません.クエリの WHERE 句といった条件を解析して,アクセスすべき主キーの範囲を割り出す処理を指します.論理的なクエリを,物理的なデータへのアクセス経路に翻訳する工程だと考えてください.この抽出は,目的に応じて段階的に行われます.
まず,クエリをどの Split に送るかを決めるための Distribution Range Extraction です.ここではシャーディングキーだけを見て,ルーティング先を絞り込みます.
次に,リクエストがサーバに届いた後の Seek Range Extraction です.今度は主キー全体を対象に,ストレージ上のフルスキャンを必要な範囲へのシーク (狙った位置への直接アクセス) に変換して読み出すデータ量を小さくします.
トランザクションでは Lock Range Extraction も効いてきます.ロックする範囲を絞り込み,必要のない広い範囲までロックして並行性を落とさないよう,必要な行だけをピンポイントでロックするためのものです.
フィルタ条件をコンパイラが相関自己結合 (correlated self-join) のツリーに書き換えて処理しているのも興味深い点です.難しそうな名前ですが,やっていることは「前の列で絞り込んだ結果を使って次の列の探索範囲を狭める」という素直なモチベーションです.たとえば主キーが (ProjectId, DocumentPath, Version) の 3 列なら,まず ProjectId を確定し,その値のもとで DocumentPath の範囲を求め,さらに Version を決めるというふうに,列を 1 つずつ手繰っていきます.
実行時には,この考え方に沿ってキー範囲をボトムアップで計算する Filter Tree というデータ構造が使われます.たとえば WHERE ProjectId = 1 AND DocumentPath LIKE '/A%' という条件なら,Filter Tree はProjectId = 1 のもとでのみ有効な DocumentPath の範囲を計算し,条件を満たしようがない枝は「充足不能」として即座に切り捨てます.こうして,複雑なクエリでもアクセス範囲をピンポイントに絞り込めるわけです.
Batched Apply Join によるレイテンシ削減
分散データベースで,性能への影響が大きく,実装も難しいのが JOIN です.
Spanner にはインターリーブという機能があります.親子関係にあるテーブル (たとえば Customers と Invoices) のデータを物理的に隣り合わせて配置し,その間の JOIN をローカル処理だけで完結させようとする仕組みです.インターリーブされたテーブル同士の JOIN は速くなりますが,一つの親に子が偏るとホットスポットになり得るので注意が必要です.
… とはいえ,全てのテーブルが親子関係にあるわけではありません.インターリーブされていない独立したテーブル同士の結合や,セカンダリインデックスを辿ってベーステーブルの列を取りに行く結合 (back-join と呼ばれます) も当然あります.こうなると,ネットワーク越しのデータ取得は避けられません.冒頭で述べた「1 万行で 16 分」といった数字が現実味を帯びてくるのは,まさにこのような場面でしょう.
この問題に対して Spanner は Batched Apply Join を用います.Distributed Apply という演算子で実現されており,大まかな処理の流れは次のようなものです.
- 結合の左側 (入力) の行を 1 行ずつ処理せず,ある程度の量がたまるまで待つ.
- たまった行から必要なキー範囲を取り出してまとめ,1 回の RPC でリモートノードへ一括送信する.
- 送られたキーの一覧をリモート側で展開し,ローカルのテーブルに対して短い範囲スキャン (シーク) をまとめて実行する.
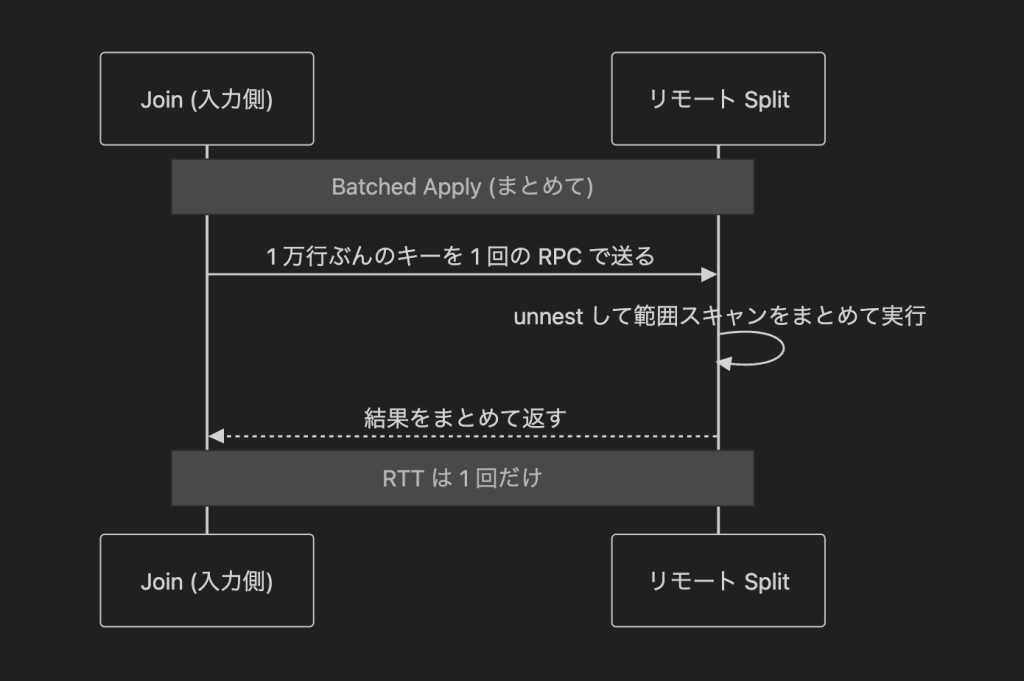
1 通の手紙を出すのも 100 通まとめて出すのも,自分が郵便局に足を運ぶ時間は変わりません.それと同じで,RPC の回数を減らして 1 回ずつ往復するときの待ち時間をまとめて消すことで,レイテンシの影響を小さく抑えています.
Restart Token と透過的な再起動
数千台のサーバが関わる分散クエリでは,途中でどこかのサーバが再起動したりネットワークが一瞬切れたりするのも珍しくありません.Spanner では特に,負荷分散のためにデータが実行中にも動的に再分割あるいは再配置され,クエリの最中にデータの持ち主が変わることさえあります.
こうした一過性の障害を,Spanner は Restart Token という仕組みでアプリケーションから隠します.結果セットには,データと一緒に Restart Token が定期的に含まれます.これは「ここまで処理が進んだ」ことを表す不透明なマーカーです.実行中にエラーが発生すると,クライアントライブラリがこのトークンを用いて自動的に再接続し,新しい接続先のサーバに「中断した地点からの続き」を要求します.
ただし,ここで隠せるのはあくまでも一過性の障害です.deadline 超過やスナップショットが GC されたといった一過性でないエラーは,これまで通りクライアント側で扱う必要があります.また,ロックを伴う read-modify-write トランザクションは,失敗するとロックを失って abort し得るため,リトライ不要の恩恵が効くのは主にスナップショット (読み取り専用) のクエリです.
この仕組みは一見すると「カーソル位置を覚えておくだけ」に見えますが,実際はもっと厄介です.任意の SQL を途中から再開するには,分散したクエリプラン全体の進捗状態を捉えておく必要があります.さらに,並列実行で結果の順序が毎回変わりうる非決定性や,再分割によって同じキー範囲のリクエストが別のサーバに再び届き得ることや,サーバをローリングアップグレードしてもプランや演算子の挙動を前後のバージョンと互換であるよう保つことなど,こういった全てに対処して,ようやく「中断しても結果が壊れない」ことが保証できます (Query Restart にかなりの紙幅が割かれており難所だったことが伺えます).
こういった仕組みで,アプリケーション側はバックオフ制御や冪等性の担保といった分散システムの面倒ごとから解放され,クエリを投げることに専念できます.リトライループは正しく書くのが難しくバグの温床になり易いかと思うので,これを書かなくてよいのは大きな利点でしょう.
エコシステムの発展
Spanner が “Becoming a SQL System” を名乗る上で避けて通れないのが,SQL 方言の統一とストレージ形式の刷新です.
かつて Google 社内には複数の SQL 方言が乱立していました.Spanner は F1 や Dremel/BigQuery のチームと協力し,共通の方言として Standard SQL (現在の GoogleSQL) を定義しました.データモデルや型システムから構文や意味論や関数ライブラリまで揃えて共有したことで,エンジニアはシステムごとの方言の差に悩まされず,複数のシステムを横断できるようになりました.現在では PostgreSQL インターフェースもありますが,エコシステムを揃えるうえで Standard SQL の策定は大きな転換点でした.
SQL システムとしての要求は,最下層のストレージ形式にも変更を迫りました.初期の Spanner は,Bigtable から受け継いだ SSTable を使っていました.SSTable はキーと値を並べた自己記述的な形式で,スキーマのない大きな文字列を扱うのには向いていますが,その自己記述性ゆえに冗長で,特定の列だけをまとめて読むような分析クエリには不向きです.
そこで導入されたのが Ressi です.Ressi は SSTable と同じく LSM ツリー (書き込みを追記中心にして高いスループットを出すデータ構造) を土台にしつつ,データの並べ方を変えました.ブロック単位では行をまとめて並べ (行優先),ブロックの内部では列ごとにまとめて並べる (カラムナ) という,2 段構えのレイアウトで PAX (Partition Attributes Across) と呼びます.この並べ方のおかげで,書き込み中心の OLTP (トランザクション処理) 的な性能を保ったまま,OLAP (分析処理) では必要な列だけを効率よく読み出せるようになりました.これは BigQuery のように「データを完全に列ごと保存する」方式とは異なり,行のまとまりを残したハイブリッドで,OLTP と OLAP の両方を 1 つの形式でこなすための折衷案という位置づけです.
現在の Spanner はさらに進んで,統計情報を使った実行計画の選択や,ユーザ自身によるオプティマイザのバージョン管理もできるようになっているかと思われます.SQL エンジンを土台に,Spanner Graph や Vector Search といった複数のデータモデルを扱うマルチモデルデータベースに成長しているようです.
まとめ
Paxos による分散合意や TrueTime は,Spanner のストレージ層でデータの整合性を支える役割ですが,今回見てきたクエリエンジンは,その制約の上で可能な限り性能を引き出すコンピュート層の工夫です.Batched Apply Join による RPC の削減も,Restart Token による再試行の隠蔽も,Ressi へのストレージ形式の変更も,分散アーキテクチャのもとで RDBMS としての性能を担保するためのアプローチでした.
Spanner というと原子時計や TrueTime ばかりが話題になりがちですが,整合性を守るストレージ層と性能を稼ぐコンピュート層をうまく噛み合わせているところにこそ,このシステムの本質があるのでしょう.
参考文献
- Bacon, D. F., et al. (2017). Spanner: Becoming a SQL System. SIGMOD ’17.
- Corbett, J. C., et al. (2012). Spanner: Google’s Globally-Distributed Database. OSDI ’12.
- Shute, J., et al. (2013). F1: A Distributed SQL Database That Scales. VLDB ’13.