
はじめに
Sreake 事業部の芳賀雅樹 (@silasolla) です.
アプリケーションがオフラインに対応している場合,二つの端末が同じデータを別々に編集した上でまたオンラインに戻るということがあります.こうして通信が遮断された間に積もった差分がぶつかったとき,システムがどう差分を解決させるのか考えることになります.
たとえば,Cloud Firestore はこれを last write wins (LWW) として解決します (オンラインならトランザクションで競合を避けられますが,オフラインでは LWW です).これは,複数の書き込み操作があったとき,後から届いた方で上書きするという方針です.この戦略は時として,黙ってユーザの編集を捨てることがありますが,これも競合解決の一つの戦略です.
独立して更新されたレプリカ同士を,決定論的なマージで矛盾なく一つに合流させられるデータ構造を CRDT (Conflict-free Replicated Data Types) [1] と総称します.分散データベースや共同編集ツールなどの土台となっており,Firestore の一部の書き込みにも,この発想との共通点を見ることができます.この記事では,オフラインの編集を一つにまとめる際に,それぞれの方針で何が期待できて何を考慮すべきなのかを見ていきます.Firestore の競合解決を CRDT と並べながら,その仕組みとデータモデルの選択がどのように結び付いているのかを考えます.
last write wins で失われるもの
まずは Firestore において,オフラインの競合がどうやって解決されるのかを見ておきましょう.Firestore の last write wins は,利用している API によって粒度が異なります.ドキュメント全体を書き換える set() に対して,update() や set({ merge: true }) は,指定されたフィールドのみを更新します.別々のフィールドに対するオフライン更新であれば,互いに衝突せず,両方の編集が残ってくれます.逆に,同じフィールドを二つの端末が同時に書き換えれば,更新の取りこぼしが生まれます.
たとえば,同じドキュメントの本文 (文字列フィールド) を二人で同時にオフライン編集したとしましょう.一人は猫の種類を詳しくするために「黒猫」と書き足し,もう一人は過去の出来事だと分かるよう語尾を修正します.意図としては別々の箇所に対する編集でしょう.
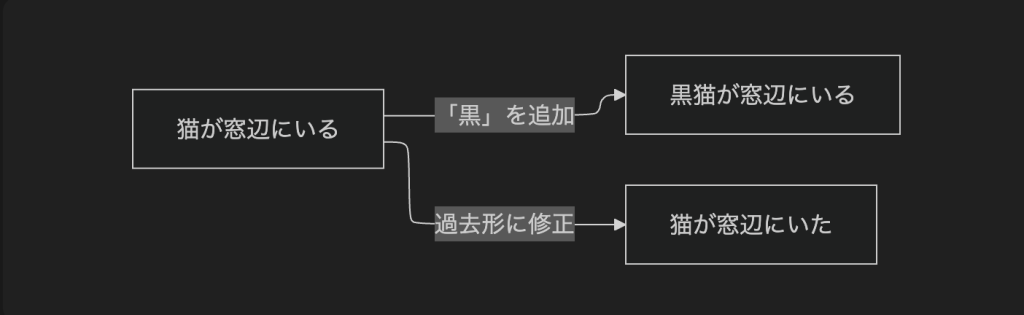
オンラインに戻ると,溜まった書き込みがサーバに送られますが,Firestore から見ると,どちらも body フィールドの全体を書き換える更新です.そのため,同じフィールドの更新として競合し,後から届いたものが先のものを丸ごと上書きしてしまいます.この例では端末 B の更新「猫が窓辺にいた」が残り,端末 A が追加した「黒」は失われます.
update() が「新しい値」を書き込んでいるのが根本的な問題です.サーバに届くのは「”黒猫が窓辺にいる” にせよ」と「”猫が窓辺にいた” にせよ」という命令だけで,これらをどう混ぜるかの情報は含まれていません.サーバから見れば,どちらか一方を選ぶしかないわけです.どうすれば取りこぼさずに合流させられるのでしょうか.
G-Counter の取りこぼしを防ぐ仕組み
まずは話を単純にして,カウンタの例を考えてみます.G-Counter (増加だけのカウンタ) は,複数のノードが独立してカウントを増やせるデータ構造です.
レプリカ同士を合流させるたびに,大きい方の値を残すものだと考えてみましょう.共通の状態 3 から,二つのノードが自分のカウントを増やしたとします.ノード A が 2 つ増やして 5 に,ノード B が 1 つ増やして 4 になった場合,両方を取りこぼさなければ最終的な値は 6 のはずです.ところが合流時に \max(5,4) = 5 を採ると,B の増加分が消えてしまいます.単なる一つの数で状態を表している限り,どのノードがどれだけ増やしたのかを区別できません.
G-Counter は,カウントを一つの数として持つのではなく,どのノードが増やしたのかを分けて記録します.各ノードごとに専用のスロットを持ち,自分のスロットだけを更新します.合流させるときは,各スロットごとに大きいものを採ります.先ほどの例を考えましょう.初期値の 3 は全て A による増加だとして,共通の状態を [3, 0] とします.ここから A が 2 増やすと [5, 0] に,B が 1 増やすと [3, 1] になります.合流させると [5, 0] \sqcup [3, 1] = [5, 1] で,その総和は 6 です.
どのノードがどれだけ増やしたのかを状態の中に持ち込んでいるため,それぞれの増加が互いを上書きしなくなります.更新を中央で整列させなくても,各ノードが受け取った状態をその場でマージすれば,最終的には全てのノードの状態が一致します.G-Counter は,冒頭で触れた CRDT (特に CvRDT) の単純な例の一つです.
Firestore での Field transform
Firestore には,値そのものではなく Field transform という操作を送る書き込みがあります.
二つの端末がオフラインで同じ likes を増やす場合を,値の書き込みと操作とで並べてみましょう.どちらも likes = 0 から始めます.update({ likes: 1 }) で送られるのは「likes を 1 にしなさい」という値そのものです.両端末がこれを送れば,後着が先着を上書きして,2回押してもリプレイ後は 1 のままです.一方で increment(1) とすることで「1 を足しなさい」という操作を送ることができます.切断中の操作はキューに溜まり,再接続したときにサーバで順番に適用されます.足し算は順序を入れ替えても結果が変わらないため,どちらの端末が先に復帰しても 0 → 1 → 2 と更新され,最終的には両方の加算が残って 2 に落ち着きます.
G-Counter は状態の持ち方を工夫して取りこぼしを防いでいましたが,Firestore は一部の更新を操作として表現することで,同じ問題を避けています.送るものは違っても「並行した変更を取りこぼさないようにする」という発想は共通しています.違うのは順序をどこで決めるかです.Firestore ではサーバが操作を受け取った順に適用し,その順序がそのまま正となります.一方で CRDT は中央の整列点を持たず,各レプリカが同じ規則で状態を合流させます.その意味で Field transform は CRDT (CmRDT) そのものではありませんが,可換な操作を送るという部分でアイデアは重なります.
そうはいっても,このような操作として表現できるものには限りがあります.increment による加算や arrayUnion による要素の追加などは扱えますが,追加と削除を並行して行った場合は適用順によって結果が変わります.文字列の共同編集のような複雑な更新にも対応していません.こういったケースでは,Firestore は last write wins に頼ることとなります.
サーバ無しで順序をどう揃えるか
では,本文の共同編集を取りこぼさず残すにはどうすればよいでしょうか.文字列のような「並び順」を持つデータは,Sequence CRDT が扱います.
代表的な RGA (Replicated Growable Array) [2] では,本文を要素の列として扱い,各要素を識別できるようにします.文字の挿入は「どの要素の後ろに入れるか」という形で表現され,同じ位置への並行挿入では識別子の大小に基づいて順序が決まります.削除では即時に消してしまうのではなく,削除済み (tombstone) として残します.こうすることで,先ほどの「黒」の挿入と文末の修正も,別々の要素に対する独立した操作として矛盾なく両立できます.
ここで,順序を決める仕組みをサーバに置かないことが重要です.各レプリカは同じ規則を持っていて,手元で同じ順序を再現します.Firestore がサーバでの受信順という一点で順序を決めていたのに対し,RGA は規則を分散して共有することで順序をそろえています.こういった方式では,順序を維持するための情報がデータ側に残ります.要素の識別子や,削除状態の記録です.構造が豊かになるほど,こうした付加情報は増えます.単純なカウンタであればほぼ不要ですが,集合で並行する追加と削除を取りこぼさず扱うには OR-Set のような要素ごとのタグが要るし,挿入や削除や順序を扱う列では識別子や tombstone が必要です.
Firestore の transform が軽く見えるのは,こうした構造を必要とする操作を扱わないためです.カウンタの加算のように,サーバで順番に適用しても結果が自然に定まる操作だけを提供し,それ以外は last write wins に委ねます.順序を中央で決めるのか,それとも規則として分散するのかというのが設計の大きな違いです (こういった構造を Firestore で扱いたい場合は,たとえば Yjs や Automerge のような CRDT ライブラリの状態をドキュメントに載せて,マージはライブラリに委ねる手もあるでしょう).
まとめ
Firestore はサーバを基準にすることで設計を単純にしていますが,競合する変更を自動的に統合できる操作は一部に限られ,それ以外は last write wins に委ねられます.一方で CRDT は,競合解決のルールをデータ側に移すことで,より広い表現を扱えるようにしています.どちらも競合を扱う仕組みですが,本質的な違いはアルゴリズムではなく,どこにその責任を持たせるかという設計にあります.
同じ「競合解決」といっても,選ぶデータ型によって意味は変わります.収束することと,混ざった結果が意図どおりかどうかは,別の話だからです.LWW レジスタは CRDT の一種ですが,合流時には新しいタイムスタンプの方を採るだけです.状態は一致しますが片方の更新は失われます.「いいね」を数えるだけならカウンタで十分ですが,誰が押したかまで扱うなら別の表現が必要になります.競合解決は後付けの仕組みではなく,データモデルの選択そのものに含まれています.
参考文献
- Shapiro, M., Preguiça, N., Baquero, C., & Zawirski, M. (2011). A comprehensive study of Convergent and Commutative Replicated Data Types. INRIA Research Report RR-7506.
- Roh, H.-G., Jeon, M., Kim, J.-S., & Lee, J. (2011). Replicated abstract data types: Building blocks for collaborative applications. Journal of Parallel and Distributed Computing, 71(3), 354-368.
- Kleppmann, M. (2017). Designing Data-Intensive Applications. O’Reilly. Chapter 5: Replication.
- Google Firebase Documentation. Access data offline / Add data to Cloud Firestore. https://firebase.google.com/docs/firestore