
はじめに
Sreake事業部インターン生の高島陸斗です。インターン生としてSRE技術の調査・検証を行っています。私は、情報系の大学院生で、普段は数値解析に関する研究をしています。学部時代は、今回のブログ内容とも関係する並列化や高速化についての研究を主にしていました。
今回は、CUDAについてまとめました。以下では、C言語によるCUDAでのプログラム方法や高速化案、ライブラリについて記載します。また、インフラ関連技術として、NvidiaのGPUをコンテナで利用できるようにするNvidia Container Toolkitについても少し触れておこうと思います。
CUDAを始める前に
CUDAとは
CUDA(Compute Unified Device Architecture)は、Nvidiaが開発するGPU用のプログラムモデルです。C/C++でのプログラムやライブラリ、APIによって使用することができます。GPUを用いた並列処理に特化しており、画像処理や科学技術計算、近年のAIブームを支える柱の一つになっている技術です。
CUDAの構築
パフォーマンスに影響がでないように、仮想環境でないUbuntu22.04での構築を行います。CUDAは前提として、Nvidia製のGPUを利用していることが必要になります。
1. Nvidia Driverのダウンロード
まず、GPUを適切に機能させるために、以下のコマンドから専用のDriverを入れます。上記のコマンドで、オープン版の適切なドライバーを選択してインストールすることができます。
$ sudo apt-get install -y nvidia-openうまく入れば、以下のコマンドから使用しているGPUの情報を確認することができます。
$ nvidia-smi Tue Sep 17 17:44:48 2024 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI ...注意点として、Ubuntuで構築する際、セキュアブートをONのまま構築するとうまくいかない場合があるようです。基本的には、自動的にセキュアブート下での動作が確認されているドライバーを入れるようになっているため、インストール中にセキュアブートに関する設定ガイドからうまくいくはずです。しかし、うまく行かない場合は、手動でMOKというセキュアブート環境で動作させるためのツールの設定をするか、セキュアブートをOFFのまま構築する必要があります。
参考:
Ubuntu公式 NVIDIA drivers installation
Secure BootのままNvidiaドライバをaptからインストールする
2. CUDA Toolkitのダウンロード
次に、CUDAを入れていきます。CUDA Tookitのダウンロードページから適切にプラットフォームの選択をしてダウンロードをします。表示されたCUDA Toolkitのダウンロード用のスクリプトを実行します。
3. PATHを通す
このままでは、nvccなどのCUDAを動かすためのコマンドが使えないため、PATHを通して構築完了です。以下のコマンドを.profileや.bashrcなどの初期設定用のファイルに書き込み,環境変数を設定します。
export PATH="/usr/local/cuda/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda/lib64:$LD_LIBRARY_PATH"うまく入れば、以下のコマンドから使用するCUDAコンパイラのバージョンを確認することができます。
$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation ...行列積のサンプルコード
今回、解説に行列積を計算するプログラムを利用します。正方行列を計算する際の式は以下のような式になります。下図では、特に行列のC[1][1]の要素についての計算を記載しています。
行列積計算は、上記の図に示すように、行列Cの各要素を計算するために、大量の和積演算が必要になります。ただし、これらの要素を計算する際に順番に計算する必要はなく、依存関係が少ないので、多くの並列性を見出すことができます。以下に記載したプログラムは、CUDAを利用しないプログラムです。このプログラムをベースにして作成していきます。
/* 行列積 A*B = C のプログラム */
#include <stdio.h>
#include <stdlib.h>
// 行列を出力する関数
void printMatrix(int n, float *M, int precision)
{
for(int i=0;i<n;i++){
for(int j=0;j<n;j++){
printf("%.*f ", precision,M[i*n+j]);
}
printf("\n");
}
}
// 行列積を計算する関数
void CPUmatrixProduct(int n, float *A, float *B, float *C)
{
for(int i=0;i<n;i++)
for(int j=0;j<n;j++)
for(int k=0;k<n;k++)
C[i*n+j] += A[i*n+k]*B[k*n+j];
}
//==== Main ======
int main(int argc, char *argv[]) {
int i,j;
int n = (argc==1)?1024:atoi(argv[1]); //正方行列のサイズ設定(コマンドライン引数を参照)
float *h_A, *h_B, *h_C;
int msize = n*n*sizeof(float); //使用するメモリサイズ
srand(1);
printf("matrix size: %d\n", n);
//メモリの確保
h_A = (float*)malloc(msize);
h_B = (float*)malloc(msize);
h_C = (float*)malloc(msize);
//行列の各要素にランダムな値を設定
for(i=0;i<n;i++){
for(j=0;j<n;j++){
h_A[i*n+j] = (float)rand()/RAND_MAX*20-10;
h_B[i*n+j] = (float)rand()/RAND_MAX*20-10;
h_C[i*n+j] = h_P[i*n+j] = 0;
}
}
//行列積の計算 h_A * h_B = h_C
CPUmatrixProduct(n, h_A, h_B, h_C);
printf("CPU finish!\n");
//結果の確認
printf("host A:\n");
printMatrix(n, h_A, 6);
printf("\nhost B:\n");
printMatrix(n, h_B, 6);
printf("\nhost C:\n");
printMatrix(n, h_C, 6);
}CUDAによるGPUプログラム
CUDAを利用して、GPUのリソースを使ったC言語のプログラムをします。例として、行列積を計算するプログラムを作成してみます
行列積のCUDAプログラム作成
CUDAのプログラムは、基本的なC言語のプログラミング方法を理解していれば難しくありません。まず、基本的なGPU実行の流れを理解しておく必要があります。上記の図は、実行の流れを示した図です。
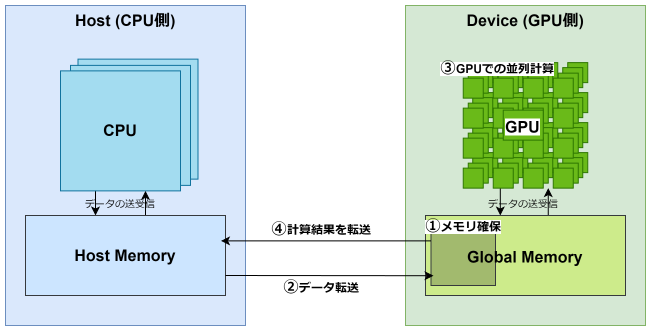
- GPUデバイス上のメモリを確保 GPUデバイスも専用のメモリを持ちます。デバイス内のマルチプロセッサは、この専用メモリからデータを取得して処理します。このため、まずは利用するデバイス側のメモリを確保します。
- デバイス上のメモリにホストからデータを転送 GPUデバイスで計算させたいデータをデバイス上のメモリに転送します。
- デバイス上でプログラムを並列に処理 転送したデータを、GPUで計算します。プログラムでは、GPU上の1つのプロセッサが行う処理を記述します。
- 計算結果をデバイスからホストに転送 計算結果となるデータをデバイスからホストに転送することで、ホスト側が結果を確認できます。
次に、CUDAで並列化する際に必要になるスレッドの構成についても知る必要があります。CUDAは、並列化の際にスレッドを最小単位として、各スレッドでの処理内容を記述します。スレッドを複数まとめたブロック、ブロックを複数まとめたグリッドという概念を利用してプログラムしていきます。この階層構造は、GPUのハードウェア的な特徴とも深くかかわっており、どの程度のスレッド数やブロック数で処理を実行していくかが並列化をする上で重要になります。
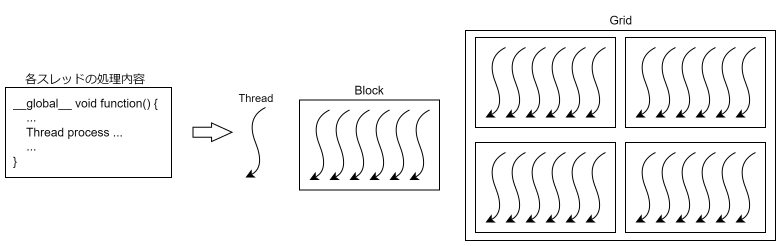
CUDAのプログラムでは、これらの項目の動作をそれぞれ定義していきます。
0. 前準備のプログラム
CUDAを利用するために必要になるヘッダーファイルをincludeします。
#include <stdio.h>
#include <stdlib.h>
#include <cuda_runtime.h>使用するGPUの設定と、GPUに関する情報をプログラム側で呼び出せるようにします。以下の設定は、記載せずともプログラムは動作しますが、あるとデバッグやGPUの情報を利用したプログラムがしやすくなります。
...
int main(int argc, char *argv[]) {
...
/* Setup GPU Device */
int dev=0;
cudaDeviceProp deviceProp;
CHECK( cudaGetDeviceProperties(&deviceProp,dev) ); // GPUに関するプロパティの取得
printf("Using Device %d: %s\n", dev,deviceProp.name); // 使用するGPUデバイス名の表示
CHECK( cudaSetDevice(dev) ); // 使用するデバイスのセット
...
}上記ではGPUデバイス名のみの表示ですが、このcudaGetDeviceProperties関数で取得してくる値は様々なものがあります。以下を参考にしてください。
参考:Nvidia公式 7.9. cudaDeviceProp Struct Reference
また、CUDAのライブラリの関数は、実行がうまくいったかを返却値として返すため、結果をもとに処理がうまくいったかを確認するCHECK()という関数マクロを作成しておきます。こちらもなくても動作に問題はありませんが、デバッグがしやすくなります。
//エラー表示用関数マクロ
#define CHECK(call) \
{ \
const cudaError_t error = call; \
if(error != cudaSuccess) { \
printf("Error: %s:%d, ", __FILE__, __LINE__); \
printf("code:%d, reason: %s\n", error, cudaGetErrorString(error)); \
exit(1); \
} \
}1. GPUデバイス上のメモリを確保
まず、GPUデバイス上のメモリ確保を行います。メモリの確保には、cudaMallocという関数を利用します。引数として、アクセス時に利用する変数のアドレスと取得したいメモリサイズを渡します。注意点として、変数がポインタ型なので、そのアドレスはダブルポインタ型になります。
int main(int argc, char *argv[]) {
...
int msize = n*n*sizeof(float);
float *h_P; // 結果を格納するための変数
float *d_A,*d_B,*d_C; // GPUデバイス用の変数
// メモリ確保
h_P = (float*)malloc(n*n*sizeof(float));
CHECK( cudaMalloc((void**)&d_A,msize) );
CHECK( cudaMalloc((void**)&d_B,msize) );
CHECK( cudaMalloc((void**)&d_C,msize) );
...
}2. デバイス上のメモリにホストからデータを転送
メモリの確保ができたので、ここにホスト側で作成した行列のデータを転送します。転送には、cudaMemcpyという関数を利用します。この関数は、「ホスト → デバイス」、「ホスト ← デバイス」どちらの方向へのデータ転送にも利用します。
引数について、h_A内に行列データを作成したので、このデータをd_Aに転送します。また、「ホスト → デバイス」なので、cudaMemcpyHostToDeviceを設定します。
int main(int argc, char *argv[]) {
...
// Host to Device
CHECK( cudaMemcpy(d_A, h_A, msize, cudaMemcpyHostToDevice) );
CHECK( cudaMemcpy(d_B, h_B, msize, cudaMemcpyHostToDevice) );
CHECK( cudaMemcpy(d_C, h_P, msize, cudaMemcpyHostToDevice) );
...
}3. デバイス上でプログラムを並列に処理
転送したデータを基に、行列積計算をGPUで行っていきます。まず、GPUでの並列化方法を考えます。以下のプログラムから、GridとBlockの最大サイズを確認します。
/* checker.cu */
#include <stdio.h>
#include <cuda_runtime.h>
int main()
{
cudaDeviceProp dev;
cudaGetDeviceProperties(&dev, 0);
printf("max size of each dim. of block : (%d, %d, %d)\n", dev.maxThreadsDim[0], dev.maxThreadsDim[1], dev.maxThreadsDim[2]);
printf("max size of each dim. of grid : (%d, %d, %d)\n", dev.maxGridSize[0], dev.maxGridSize[1], dev.maxGridSize[2]);
}上記をコンパイルして実行します。
$ nvcc checker.cu && ./a.out
max size of each dim. of block : (1024, 1024, 64)
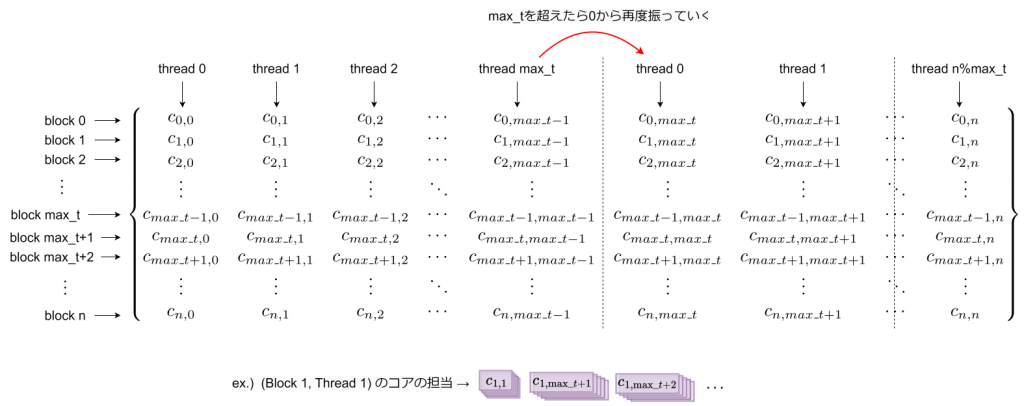
max size of each dim. of grid : (2147483647, 65535, 65535)これにより、Blockの最大サイズが1024とあまり大きくないことがわかります。これを考慮して、今回、以下のように行列を並列化して計算していこうと考えています。
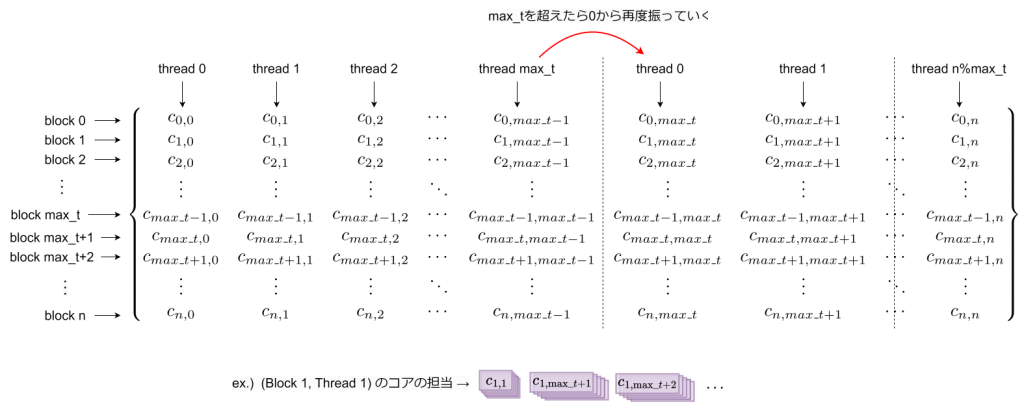
基本的に、行列Cの各要素番号に対応するブロック、スレッドが計算を担当します。ただし、行列サイズが1024以上の場合、これでは対応できなくなります。このため、Blockの最大サイズを超える場合は、0番目のスレッドから再度番号を振っていき、計算をしてもらうようにします。このため、各スレッドが担当する計算は、2重ループになります。
考えた並列化アルゴリズムをプログラムします。CUDAでのプログラムは、GPU内の各プロセッサで処理したい内容を記述していきます。
__global__ void GPUmatrixProduct(float *A,float *B,float *C)
{
int loop = 1;
int n = gridDim.x;
int i = blockIdx.x;
int j = threadIdx.x;
if(n - blockDim.x > j)
loop += n/blockDim.x;
for(int l=0;l<loop;l++){
for(int k=0;k<n;k++)
C[i*n+j] += A[i*n+k]*B[k*n+j];
j += blockDim.x;
}
}作成した関数を呼びだす際、dim3型というCUDAで利用する型を利用して、blockとgridのサイズを設定し、function<<<grid, block>>>(args);の形で呼び出します。cudaDeviceSynchronize関数を呼び出すと、CPUとGPUの処理の流れの同期を取ることができます。CPUとGPUは非同期にプログラムが進んでいくため、処理の流れ上の依存関係がある場合は必要な処理になります。
int main(int argc, char *argv[]) {
...
int max_t = deviceProp.maxThreadsDim[0];
dim3 block( (n > max_t) ? max_t : n );
dim3 grid(n);
GPUmatrixProduct<<<grid,block>>>(d_A,d_B,d_C);
CHECK( cudaDeviceSynchronize() );
...
}4. 計算結果をデバイスからホストに転送
最後に、計算結果をデバイスからホストに返します。cudaMemcpy関数を利用し、「ホスト ← デバイス」なので、cudaMemcpyDeviceToHostを設定します。
int main(int argc, char *argv[]) {
...
// Device to Host
CHECK(cudaMemcpy(h_P,d_C,msize,cudaMemcpyDeviceToHost));
printf("GPU finish!\n");
...
}CPUでの計算結果と同じになるかを確認しておきます。行列の各要素の誤差の最大値を取得し、0に近ければ、計算がうまくいっていると言えます。
int main(int argc, char *argv[]) {
...
CHECK( cudaGetLastError() ); // 最後にGPU側のエラーを確認
printf("\nDevice C:\n");
printMatrix(n, d_P, 6);
// 誤差の確認
float max = 0;
for(i=0;i<n;i++) {
for(j=0;j<n;j++) {
float error = fabs( h_C[i*n+j] - h_P[i*n+j] );
if(max < error)max = error;
}
}
printf(">> max error : %f\n",max);
}注意点として、行列積の計算結果にもよりますが、おそらく今回の場合、誤差が0にはなりません。理由として、計算にfloat型という有効数字が7桁の浮動小数点を利用しており、7桁から先の値はほぼ乱数に近い値になっているためです。精度を上げるためには、double型という倍精度の型を利用するのが良いですが、処理速度が低下します。
5. プログラムの実行
作成したプログラムを実行して、動作を確認してみましょう。行列サイズを大きくすることで、CPU側での計算がなかなか終了しませんが、GPU側はすぐに終わることが確認できます。
$ nvcc -O2 -gencode arch=compute_89,code=sm_89 matrixProduct.cu -o matrixProduct.out
$ ./matrixProduct.out計算時間の速度を比較してみましょう。
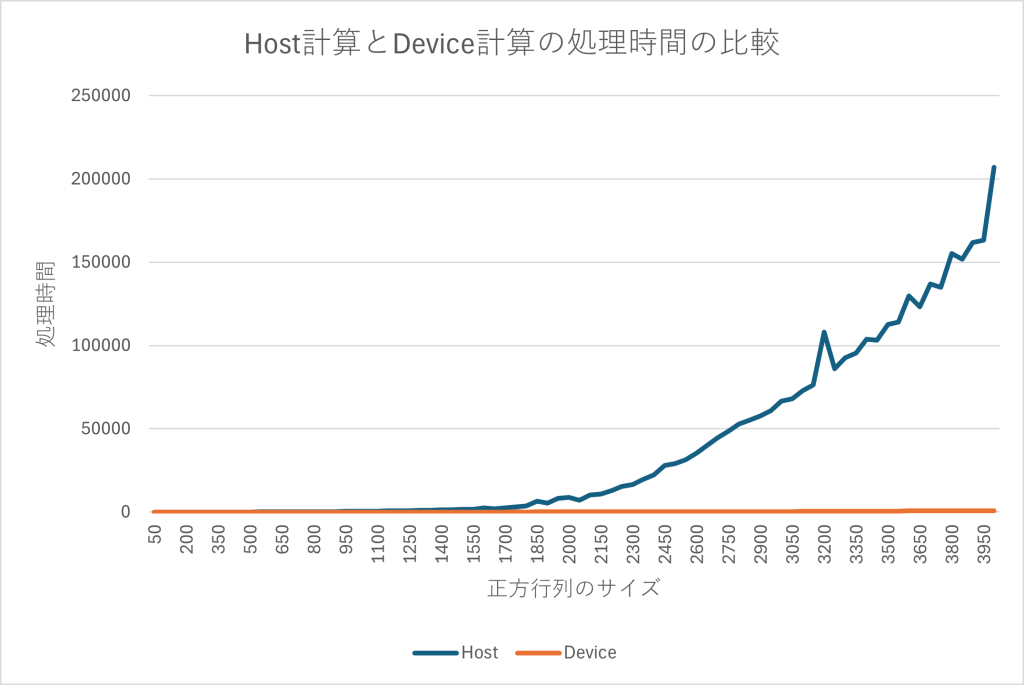
行列サイズが大きくなるほど、ホスト側での計算は多くなっていますが、それに比べてGPUでの計算は遥かに小さいことがわかります。
さらなる高速化
上記では、とにかくGPUを利用して、正しい計算結果となるようにプログラムを作成しました。これだけでもGPUによる並列化により、大きく計算時間を縮めることができていることが確認できました。
しかし、これだけでは十分にGPUの能力を発揮しているとは言い切れません。以下に、さらなる高速化が期待できる高速化手法をまとめます。
- ブロックやグリッドサイズの調整 ブロックやグリッドサイズの値を調整するだけでも、実行時間を短縮する場合があります。今回は、ブロックサイズを最大の1024で設定していますが、最大値を512に変更したり、32×32というような2次元にすることで高速になる可能性があります。 細かい調整では、Nsight ComputeやNsight Systemsを利用することで最適化をバランスよく行うことが可能です。
- 高速なGPUメモリの利用 上記では、グローバルメモリというGPU内で一番容量の大きいメモリを使用した処理をしていますが、さらに高速なメモリがGPUにはいくつか存在します。その中でも特に、各ブロックごとに用意されるシェアードメモリという高速なメモリがあります。容量がその分小さいですが、メモリアクセス時間を短縮することができます。
- 転送回数の軽減 ホストとデバイス間のデータ転送は、GPGPUの全体処理において時間がかかる処理の1つです。このため、転送回数を極力減らし、GPU側のデータだけで処理が完結できるようにすることも重要です。今回の例では、1度しか転送しないため、問題はありません。
- 条件分岐の考慮 条件分岐は、GPUの処理において相性が悪いです。GPU内の各プロセッサは、複雑な処理に対応していない場合が多く、条件がtrueの場合と、falseの場合で並列に処理していない場合があります。このような問題を、ワープダイバージェンスと呼びます。
- GPUのハードウェアの特徴を理解して最適化 深層学習や行列積などの特殊な計算において、テンサーコアと呼ばれるより特化したコアが有効な場合があります。このように、コアやメモリの種類や配置を理解することでさらに高速化することができます。
- プログラムの並列性を更に見出す そもそも、上記の並列化アルゴリズムが適切とは限りません。行列の分割方法や、複雑な処理をCPUに任せてGPUが必要な処理を減らすなど、考えうるアルゴリズムは複数存在します。これらは問題によっても大きく異なります。
これらの手法を適応し、計算速度を最適化していくことで、何倍もさらなる高速化が期待できます。
最適化されたライブラリ
上記のように、単に行列積と言えども、複雑でさらなる高速化手法が存在します。また、これを様々なシステムに対して考え、適応させていくことは大変です。このため、Nvidiaが開発をした最適化ライブラリを利用してしまうと便利です。いくつか紹介します。
- 線形代数: cuBLAS, cuSPARSE, cuSOLVER
- 信号処理: cuFFT
- 乱数生成: cuRAND
- 深層学習: cuDNN, TensorRT
以下では、最適化された行列積の関数を持つcuBLASを利用して、計算を行ってみます。
#define BLAS_CHECK(call) \
{ \
const cublasStatus_t error = call; \
if(error != CUBLAS_STATUS_SUCCESS) { \
printf("Error: %s:%d, ",__FILE__, __LINE__); \
printf("code:%d\n",error); \
exit(1); \
} \
}先ほど同様に、cuBLASでのデバッグ用に以下の関数マクロを用意します。CHECK関数マクロでは、cuBLASのエラーチェックができないので、専用に作成する必要があります。
...
#include <cublas_v2.h>
...
int main(int argc, char *argv[]) {
...
cublasHandle_t handle;
BLAS_CHECK( cublasCreate(&handle) );
float alpha = 1.0f;
float beta = 0.0f;
BLAS_CHECK( cublasSgemm(handle, CUBLAS_OP_T, CUBLAS_OP_T, n, n, n, &alpha, d_A, n, d_B, n, &beta, d_C, n) );
CHECK( cudaDeviceSynchronize() );
//転置状態で帰って来るので調整
for(i=0;i<n;i++){
for(j=0;j<n;j++){
if(i!=j){
float t = h_P[i*n+j];
h_P[i*n+j] = h_P[j*n+i];
h_P[j*n+i] = t;
}
else break;
}
}
...
}cuBLASを利用するために、cublas_v2.hをインクルードしておきます。基本的に、データの転送などは先ほどと違いはありません。変更があるのは、”3. デバイス上でプログラムを並列に処理”の部分のプログラムです。行列積の計算には、cublasSgemm関数を利用します。この関数では、ハンドルを利用するため、これを定義しておきます。cublasSgemm関数の必要な引数の説明は以下を参照ください。
参考:Nvidia公式 cuBLAS
cublasSgemm関数の仕様で、fortranと同じようなメモリアクセス方法を行うため、転置して計算をする必要があります。このため、計算結果が転置されて出てきてしまうため、それを直して処理終了です。このため、この関数を複数回使用する場合は、初めからデータの置き方を工夫しておく必要があります。
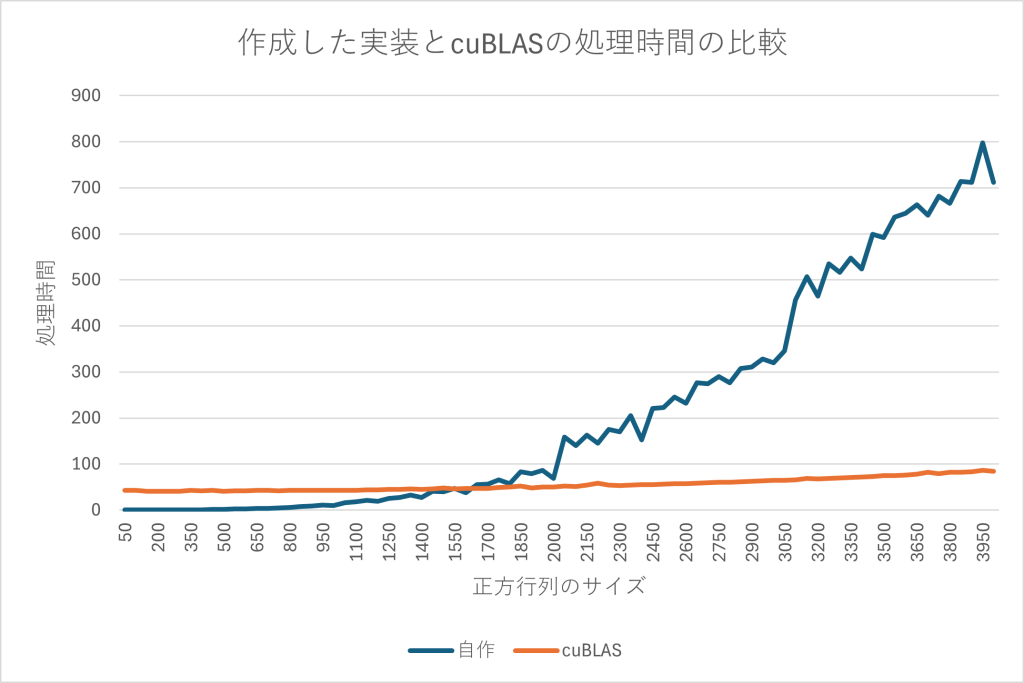
最後に先ほどのプログラムと比較をしてみましょう。nvccでコンパイルする際に、-lcublasオプションが必要になります。
Nvidia Container Toolkit
Dockerなどのコンテナプラットフォームにおいて、GPUリソースを利用できるようにするツールです。これを利用するとKubernetesからでも、GPUのリソースを呼び出すことができるようになります。
- インストール方法 Ubuntuなのでaptでのインストールをします。専用のリポジトリを追加して、そこからインストールするだけです。
$ curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
$ sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
$ sudo apt-get update
$ sudo apt-get install -y nvidia-container-toolkit参考:Nvidia公式 NVIDIA コンテナ ツールキットのインストール
- Dockerでの実行方法 コンテナランタイムに依存しないように設計されているため,Docker, Podman, containerd, cri-o, LXCなど様々なものに互換性があります。Nvidia Container Toolkitを入れたあと,Dockerに以下のオプションをつけるとGPUにアクセスできるようになります。
docker run --gpus all --runtime=nvidia ...GPUを使用したい場合、--runtimeオプションでnvidiaに設定する方法、--gpusオプションを設定する方法があります。--gpusオプションのほうが新しい方法のようで、使用するGPUデバイスの選択などの設定が容易です。--runtimeオプションの方が互換性があるツールが多く、KubernetesでGPUを利用する場合はこちらが必須になります。
- 構成コンポーネント 様々なコンテナランタイムをサポートできるように、大まかに以下の4つから構成されています。
- Nvidia Contaienr Library と Nvidia Contaienr CLI コンテナが、Nvidia DriverつまりCUDAやNVMLと行ったGPUリソースを利用するのに必要なツールを利用できるようにするためのコンポーネントです。コンテナランタイムに依存しないように設計されており、コンテナのプロセスでgpuが利用できるようにAPIやCLIを搭載しています。
- Nvidia Container Runtime Hook コンテナへのフックに利用するためのインターフェイスが実装されているコンポーネントです。
- Nvidia Container Runtime runcのラッパーとして実装されており、nvidia container用のランタイムです。
- Nvidia Container Toolkit CLI ユーザがNvidia Continer Toolkitに対する設定や構成を与えるため、利用されるCLIを実装してあるコンポーネントです。このコンポーネントはコンテナ実行時には関係ありません。参考:Nvidia公式 アーキテクチャの概要
- 速度比較 ホストでのGPU処理とコンテナ内でのGPU処理の速度を比較しておきましょう。計測する際に、使用するコンテナは以下のコマンドから作成します。CUDAのプログラムがあるフォルダをマウントしておきます。
$ docker run --rm -it --gpus all --name gpu-test -v ./gpu_test_field:/mnt nvidia/cuda:12.6.1-cudnn-devel-ubuntu24.04ホストでのcuBLASとコンテナでのcuBLASの処理時間の違いを見てみます。
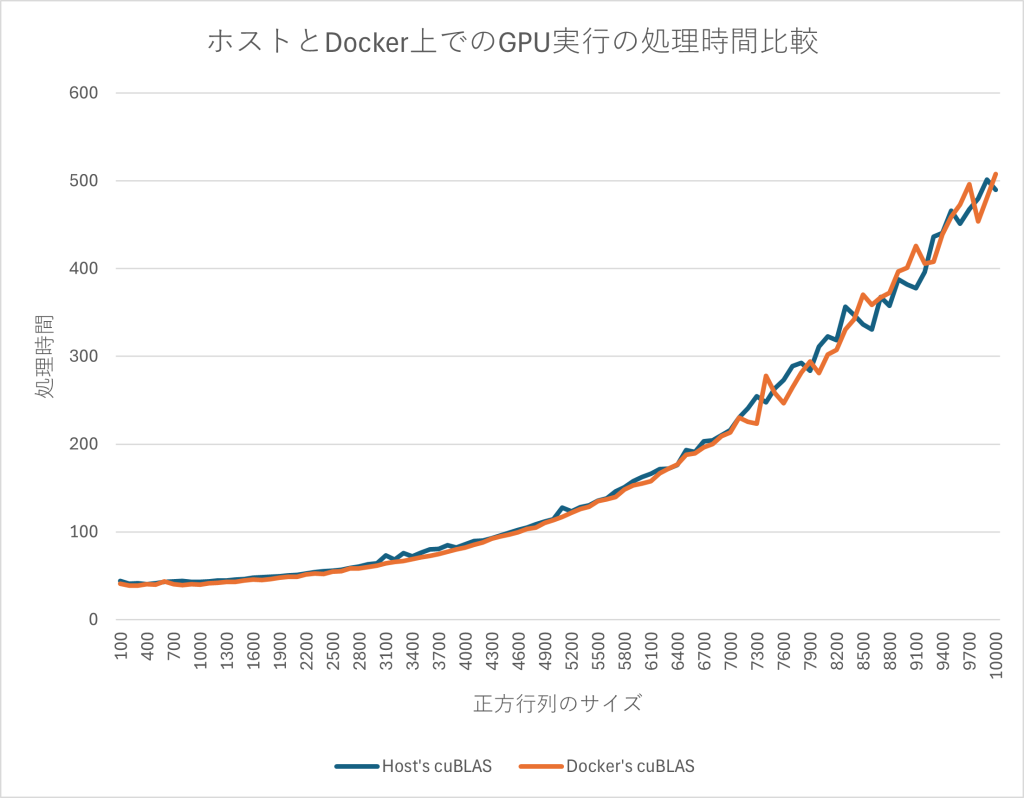
グラフのように、どちらで計算したとしても有意な差は見受けられません。
おわりに
CUDAの利用方法や、高速化、Nvidia Container Toolkitについて説明してきました。近年のシステムにおいて、ライブラリやDockerなどでGPUを手軽に利用してもパフォーマンスを下げず、場合によってはより高速にシステムを処理できる点が興味深かったです。

SreakeではSREや関連する情報を発信していきます。