
Sreake事業部インターン生の荒木です。先日Generative AI Summit Tokyo ’24 Fallに参加してまいりました!本イベントで得られた知見や、セッションの様子などを紹介します。
内容としては開発者やビジネスパーソン向けのセッションが中心で、RAGを活用したソリューションに関する発表が多数を占め、やや専門的な内容が多かったです。
はじめに
Generative AI Summit Tokyo ’24 Fallとは
Google Cloud には生成 AI 技術を扱うリソースとして2つのものがあります。1つはAI 開発プラットフォームのVertexAI。そして、マルチモーダル生成 AI モデルのGeminiです。このイベントではこれらツールを活用したビジネスの成功事例や実際の導入事例を紹介し、その可能性を多くの人に知ってもらうことを目的としています。

Gemini

最新モデルのGemini 1.5の特徴は入力に用いることのできるトークン数が200万という、非常に膨大なコンテキストウィンドウを持つ点です。これにより、グランディング時にデータ量の大きいファイルを入力することができ、LLMの課題の一つであるハルシネーションのリスクを低減させることができます。
Google Workspacesとの相性
Google CloudはGemini for Google WorkspaceというSaas型のGeminiエージェントサービスを提供しています。
この機能を利用することで、
- 英語で記述したメールをより自然な英語に修正する
- ドキュメントの選択範囲を要約する
- Google Meetの内容を翻訳する
等、Google Workspace上のアクティビティをGeminiでサポートすることができます。
https://workspace.google.com/intl/ja/solutions/ai/#plan
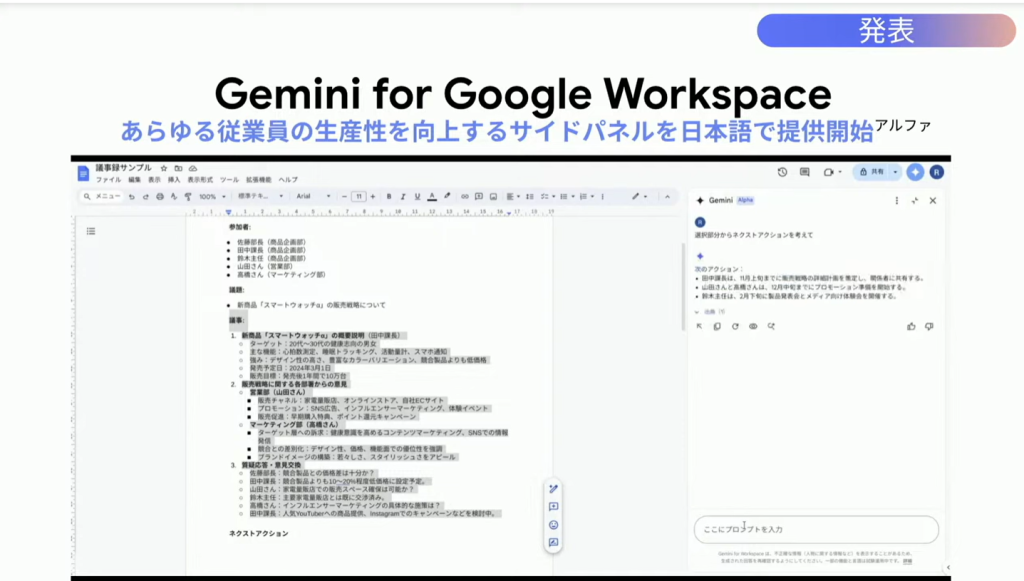
また、サイドパネル機能が日本語対応しました。
これにより、同じ画面内でシームレスにGeminiと対話できます。
Gemini Code Assistant
GithubやGitlabにある独自のコードベースをコンテキストとして読み取り、単一の関数生成ではなくほかのファイルや関数との関係性を把握したうえでのコード生成が行えるようになりました。
https://cloud.google.com/products/gemini/code-assist?hl=ja
VertexAI Model Garden
最適なユースケースに合うモデルを選択、使用できるサービスです。独自データでトレーニングするなどカスタマイズして、そのままアプリケーションに組み込むことができます。
例えば、Text To imageモデルのImagen3が紹介されていました。

このモデルは入力画像の編集が可能です。
具体的な例としては、商品の画像を入力として商品自体は変更せずに著作権の保証付きで背景画像を挿入できるとのことです。
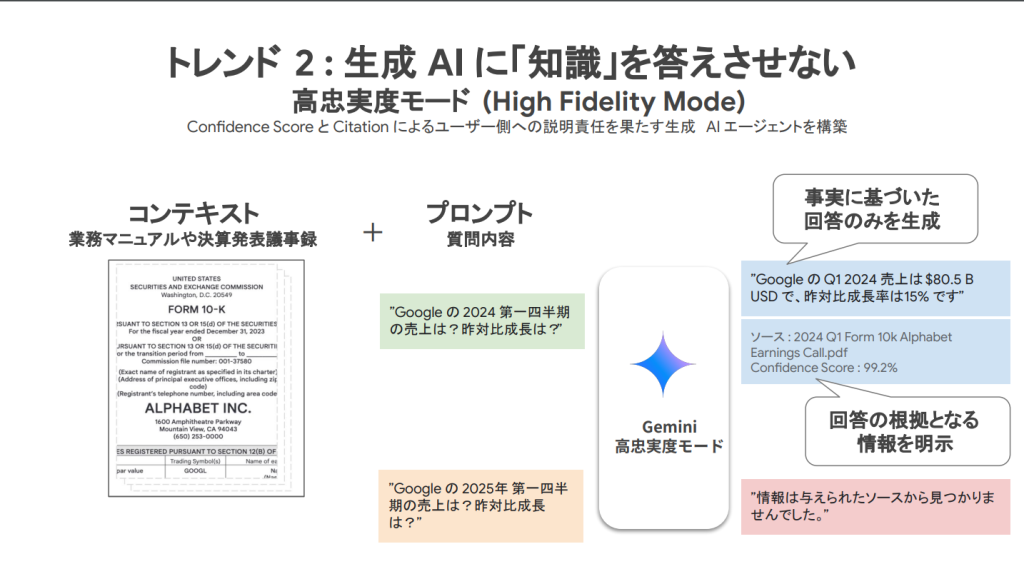
高忠実度モード
LLMが持つ独自の知識を答えたことによって、与えたコンテキストには存在しない情報や事実とは異なる出力を行うことがあります。この高忠実度モードを使用することで、与えられたコンテキストのみから回答を生成するよう強制することができるモードで、ハルシネーションのリスクを抑えてGeminiを利用できるようになります。
イベント中に紹介されていた活用事例について
基調講演では以下2社様の事例が紹介されていました。
TBSテレビ 様
テーマ:膨大な数の映像素材にメタ情報を作成する。
撮影された動画素材は将来の番組作成の素材として保管されます。動画素材にはメタという、説明情報を検索のために付与しますが、このメタの作成は人間作業で行われていました。
これを長尺の動画を扱うことができるGeminiを用いて、作業を効率化します。
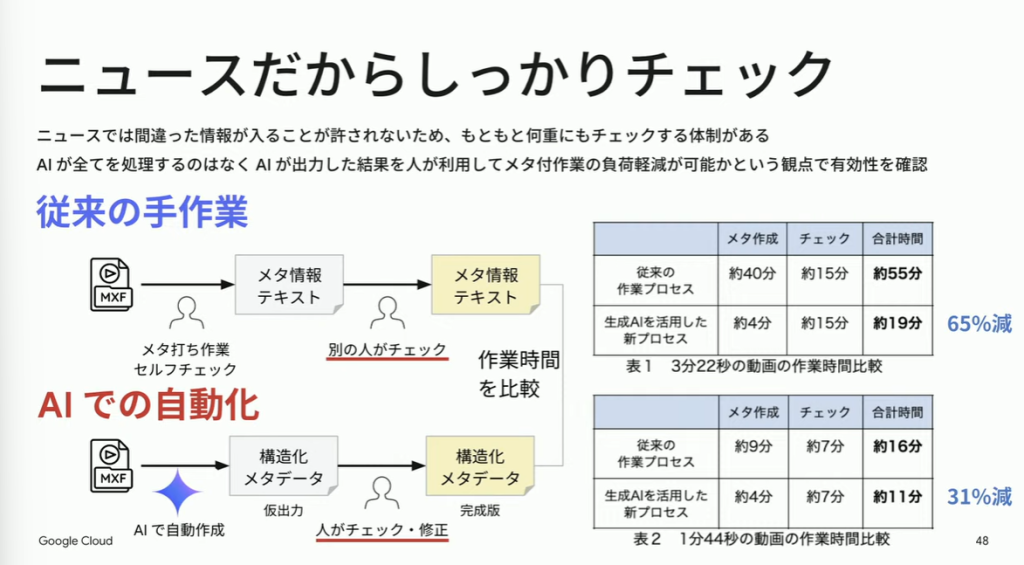
人の手で3分の動画にメタ付けを行うのに約40分かかるのに対し、Geminiを用いると約4分で完了するとのことです。
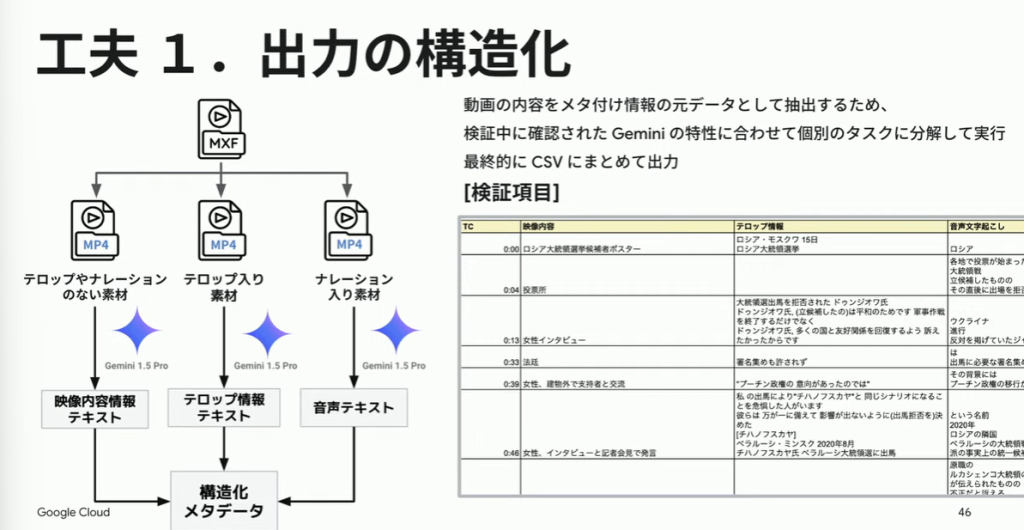
課題1. 動画内のテロップに影響を受けやすい。
この課題を解決するために処理を工夫し、オリジナルのデータにおける、テロップ、ナレーションの処理を個別のタスクとして実行しました。
AIの課題2:ハルシネーション
メタ作成は絶対に間違ってはいけない作業です。だからこそあえて、人間によるチェックの体制がすでに確立している「ニュース」でのメタ作成を行いました。
カインズ 様
テーマ:商品検索
店舗の売り場面積は非常に広大です。そのうえ、店舗の商品数13万を誇る中で、自分の欲しい商品を探すことには煩わしさを伴っています。ユーザーが商品を検索しやすくする施策の中で、Vertex AI を用いた対応策がいくつか挙げられます。
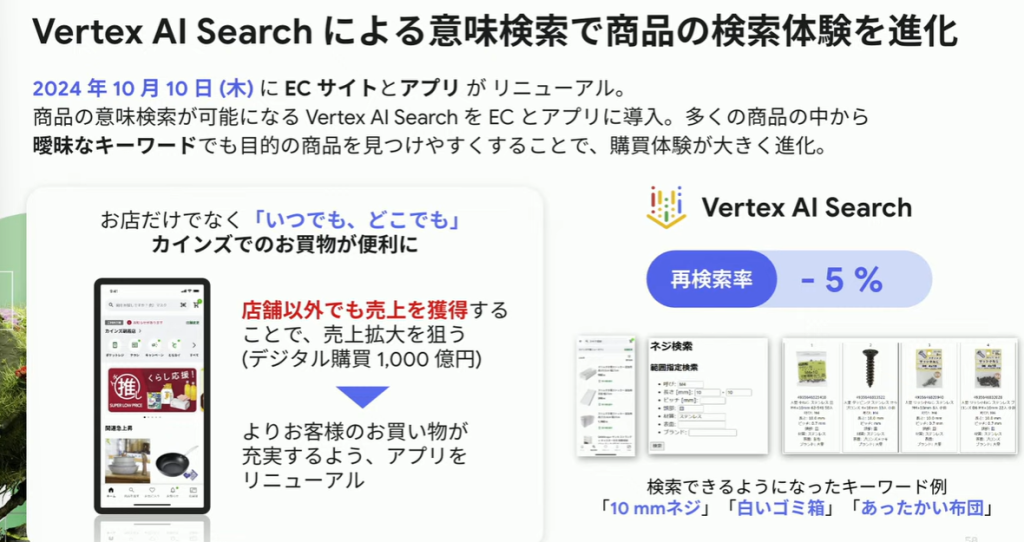
改善事例. 1:Vertex AI Searchによる意味検索で商品検索体験を進化
これにより、曖昧なキーワードでの検索が行えるようになり、再検索率は5%低下しました。
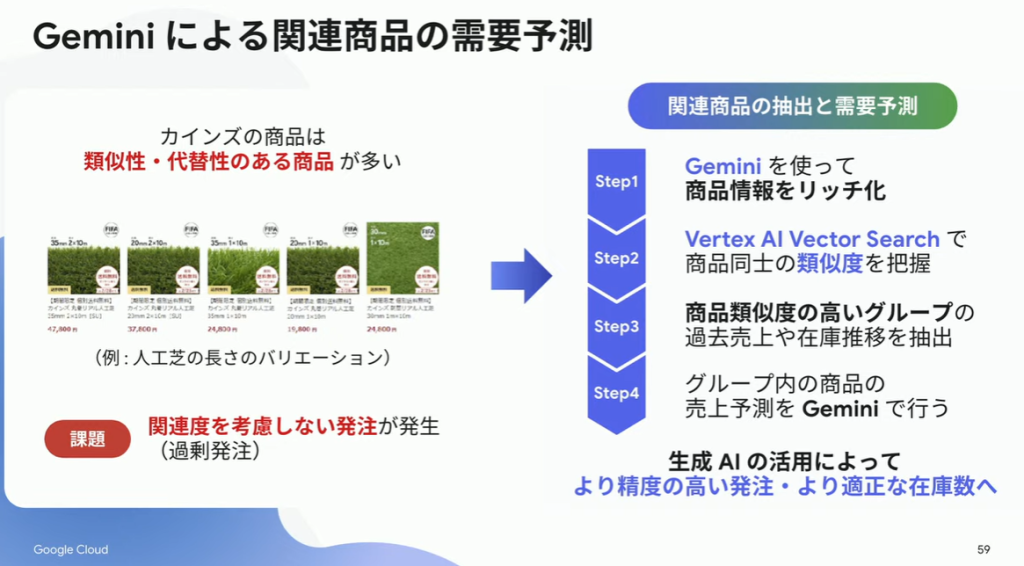
改善事例. 2:需要予測
類似性、代替性のある商品を多く扱っています。これまでは、個々の商品で需要予測を行っていたのですが、類似する商品との関係度は考慮されておらず、過剰発注の原因になっていました。
そこで、Geminiを用いた商品情報のリッチ化、Vertex AI Vector Searchで類似度を算出して似た商品同士でグループ化したことにより、より適正な商品管理が行えるようになりました。
セッション
現地では4つのセッション会場が設けられ、各自が聞きたい講演を選んで参加しました。自社での生成AIの導入事例の紹介やRAGの最適化について、生成AIを利用したアプリケーション開発に関する講演等が行われました。
それらの中でRAGとグラウンディングに関しての2つの講演が印象的だったので紹介します。
RAG の検索品質を高めるハイブリッド検索とエンべディング最適化
このセッションは、ハイブリッド検索の具体的な仕組みとRAG向けのエンベッディングにおける技術についてのお話でした。
ハイブリッド検索
RAGとして内部情報を扱うにあたり、エンベッディングによる類似度検索では、独自のキーワードや識別番号を検索にヒットさせることができません。なぜならば、それらの情報は学習モデルが意味として理解できないからです。なので、文字列として検索するキーワード検索を併用することが重要です。
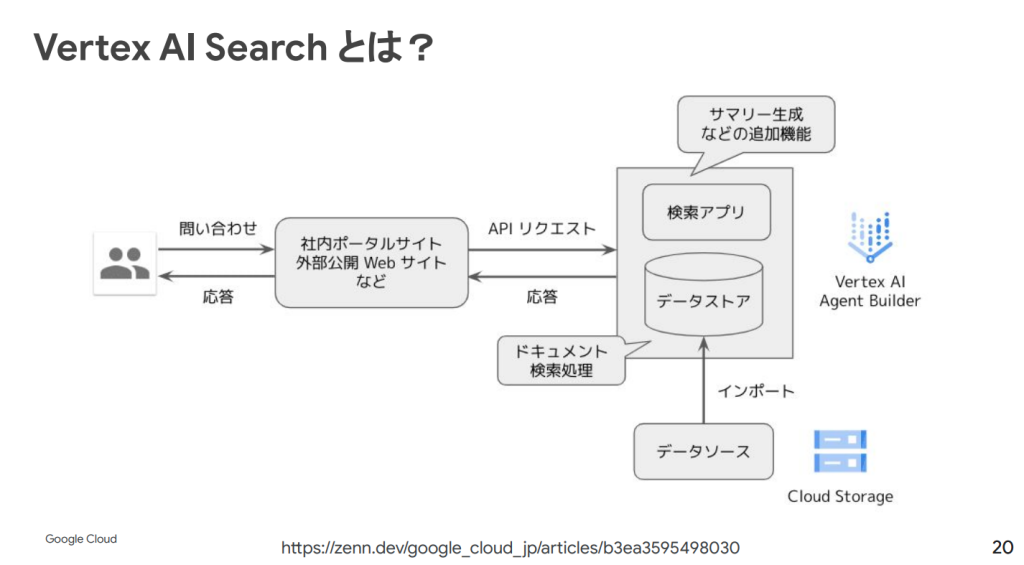
なお、Vertex AI において検索アプリケーションを作ることができるものは Vector Search と Vertex AI search の2つがあります。
前者はベクトル検索のみの機能を提供するリソースで、独自の検索システムを構築したい開発者向けです。後者は、Google検索のようなフル機能の検索サービスを提供するもので、ユーザーのデータソースと接続すると、すぐに検索アプリケーションとして利用できます。ここではハイブリット検索がすでに利用可能になっています。
セッション中ではキーワード検索の仕組みと、具体的にどのようなPythonのコードで実装できるかの説明がありました。
ここで作成したキーワードの出現頻度のエンベッディングで検索した結果と、Vertex Embedding等で作成した、文章の意味に関係するエンベッディングでの検索結果をマージすることでハイブリッド検索は行われています。
エンベッディング最適化
コンテキスト取得の際に、うまく関連文書を取得できない場合があります。質問クエリでそのままベクトル検索を行っている場合、これが原因になっているかもしれません。
そもそもの話、質問文とその回答は意味が似ていません。
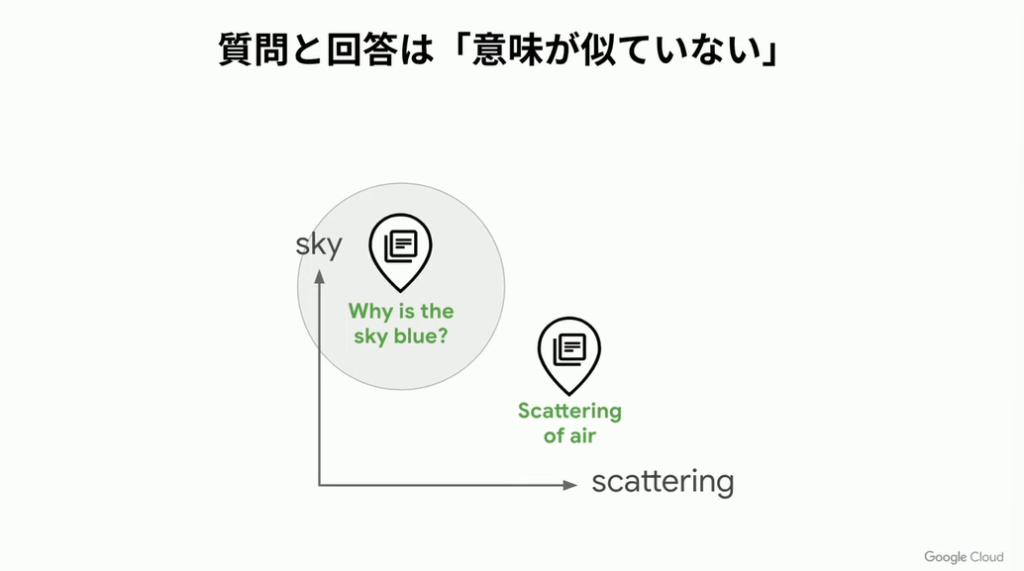
「なぜ空は青いのか?」をエンベッディングしたベクトルと「空気の散乱」をエンベッディングしたベクトルの間類似度は小さいものになり、うまく答えを取得することができないのです。
Google検索では、デュアルエンコーダーモデルを用いたNeural matchingというDeep Leaningモデルモデルを用いていますが、簡単に行えるテクニックとしては、アドバンスドRAGがあります。これは質問クエリを別のプロンプトが与えられたLLMによって処理することで、検索を行いやすいクエリに変換するというものです。これは最も簡単に行えますが、コストと遅延がその分かかってしまうことが課題です。
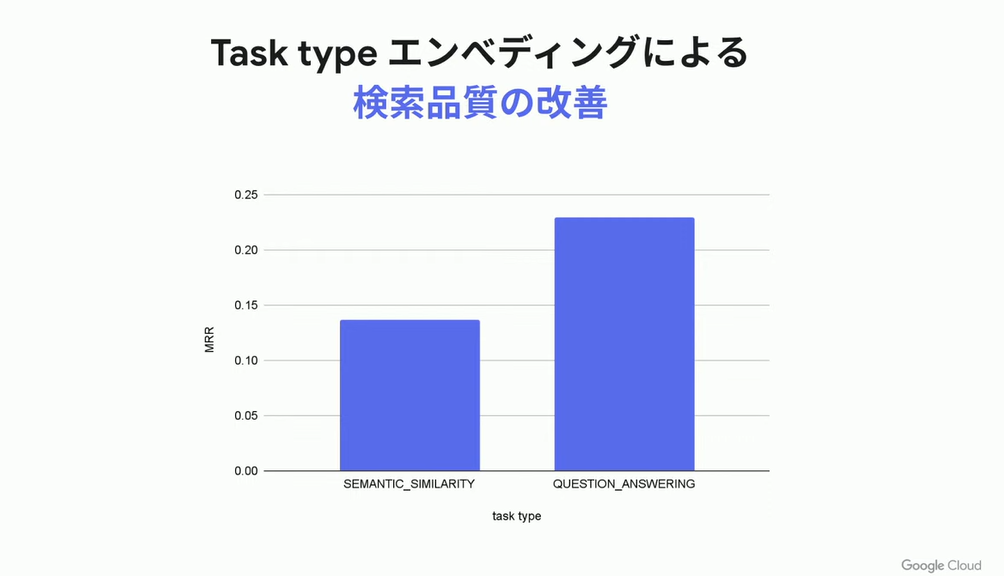
Vertex AI Embeddingsでは Task typeエンベッディング という機能によって質問と回答をエンベッディング空間内の近い位置に配置することで検索品質を向上させています。
これはデータソースに応じて内部で自動的にLLMがQ&Aを作成して、デュアルエンコーダーを自動的に学習するというものです。
エンベディングのタスクタイプを選択する | Vertex AI の生成 AI | Google Cloud
なので、開発者はデュアルエンコーダーを意識することなく、RAGとエンベッディングシステムを利用することができます。
Google Search でハルシネーションに立ち向かえ!〜Gemini のグラウンディング機能徹底活用
このセッションではGeminiの機能に関して、アプリケーション開発者向けの内容が含まれていました。LLMの課題の一つとして誤った情報を出力するハルシネーションがあげられます。正確な情報を出力させるためにグランディングが行われますが、Gemini単体で自動的にグラウンディングを行う機能を備えています。それらの紹介やコードを交えた実装方法等の説明がありました。
Gemini 1.5のグランディング機能
Gemini は Google 検索と Vertex AI search からのグランディングを可能にしています。これはプロンプトが与えられた際に自動的に内部でデータの検索と取得が行われ、応答の根拠として用いられるというものです。
- Google 検索
APIをコールする際のパラメータを設定するのみで、複雑な実装なしで使用することができます。
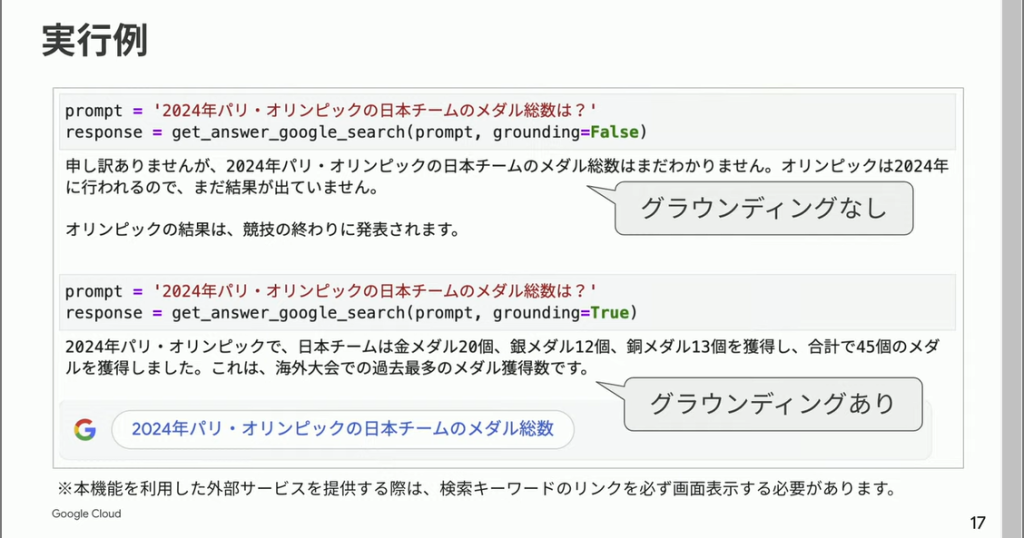
この機能を用いるとLLMが最新トレンドの情報を用いてテキストを生成するほか、根拠として用いたデータのHTMLとGoogle検索のクエリがレスポンスで得られます。
- Vertex AI search
Google 検索ではインターネット上のパブリックな情報からのデータ取得ですが、これは独自にユーザーが作成したデータソースからの検索とグラウンディングを可能にするものです。
Vertex AI Search の Answer APIを用いてグラウンディングを行うと、出力に出典情報が付与され、データソース内のどのデータから参照された情報かを知ることができます。

High Fidelity (高信頼性) モードの開発
グランディングによって誤った情報の出力は避けることができますが、現状LLMの独自知識による回答が生成されることがあります。ユースケース次第ですが、出典のない情報を出力しない高信頼性モードの開発を公開しています。

ピッチコンテスト
生成AIを活用したアイディアやソリューション発掘の目的でピッチコンテストが行われました。12組のプレゼンテーションが行われ、生成AIの可能性を追求した革新的な提案を発表しました。
最優秀賞:中外製薬株式会社 様 ~ AI が育てる次世代創薬イノベーター

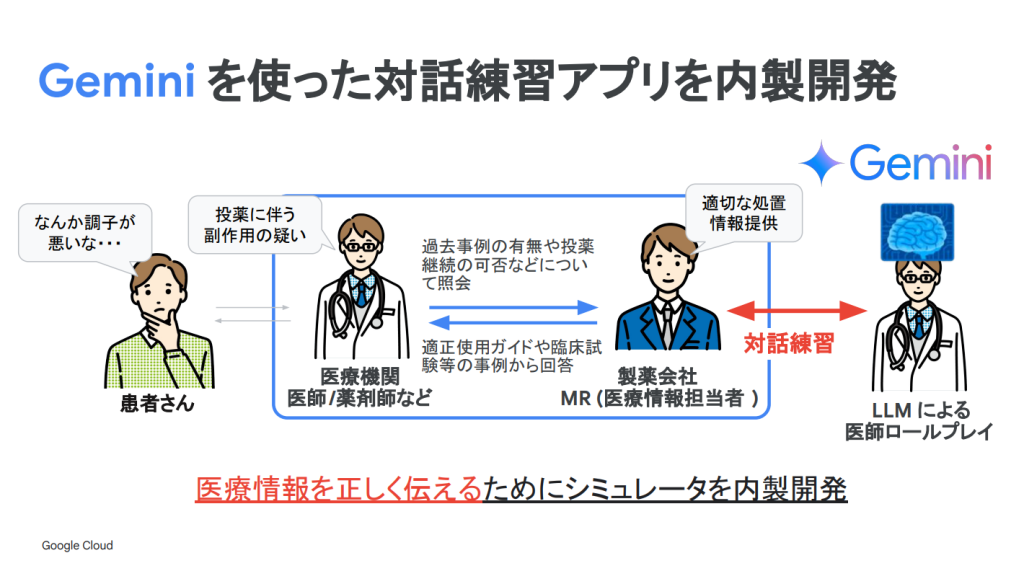
複雑な医療情報や疾患・医薬品に関する正しい情報の提供は添付文書や適正使用ガイドに基づくものですが、そのドキュメント量は膨大です。それゆえ、医療関係者に向けて、医薬品の情報提供を行うMRの果たす役割は非常に大きいです。
このアプリケーションは、MRの知識強化と、情報提供を最適化する目的で使用することができる面談シュミレーターです。Geminiを用いて質問と回答集を作成、質問文を生成、会話履歴からアドバイスを生成して、実際に医療関係者の方に資料を提示しながら情報提供をする際の練習ができるというものでした。
その他、個人的に興味深かった発表としては、クラスメソッド株式会社 様のGeminiを用いた、Zenn上のスパムコンテンツへの対応についての発表です。
エンジニアのための情報共有コミュニティである、Zennに特定URLを誘導するなどのスパムコンテンツが投下されるようになりました。読者体験のために、このスパム投稿への対応を要しますが、人力チェックだと工数がひっ迫する上、機械学習の専門知識がメンバーには不足していました。
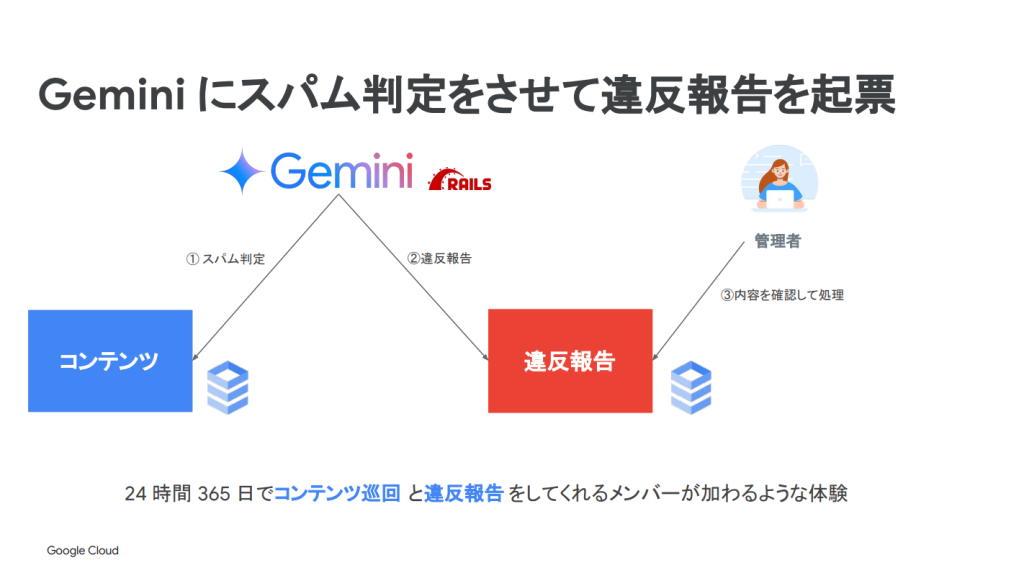
そこで、Geminiを活用した取り組みとして、24時間365日でコンテンツ巡回と違反報告を行うアプリケーションを作成しました。このアプリはコンテンツが格納されたCloud SQLからデータを取得し、Geminiにコンテンツとプロンプトを渡すことで、スパム判定をさせるというものです。これは人力チェックと比較して75%のコスト削減になりました。
実際のサービスアプリケーションのインフラの一部にGeminiがデータを処理するというフローが組み込まれているという点が、最新の生成AI活用の形態として非常に興味深かったです。
まとめ
RAGの利用と活用事例に関して多くを知ることができたイベントでした。LLMからの出力を信頼できるものにするうえでRAGを効果的に活用することは必須の要件といえるでしょう。その点、Geminiはアプリに組み込まれることが前提で考えられており、そのためのRAGシステムを構築する手段を手厚く揃えています。
今回網羅的に昨今の生成AIの活用事例とGoogle Cloud の機能を知ることができ、今後アプリケーション開発に携わるときの知識が深まりました!
ギャラリー

現地ではアンケート回答者に抽選でGemini Tシャツを配布していました。

懇親会の様子