
はじめに
データ分析において、データガバナンスは必要不可欠な取り組みの1つと言って過言ではないでしょう。
今回は「Snowflakeで始めるデータガバナンス」と題しまして、新規既存関係なく、どのタイミングからでも導入可能でデータガバナンスを取り入れることができるSnowflakeの機能をご紹介します。
また今回ご紹介する機能はGetting_Started_with_Horizon_for_Data_Governance_in_Snowflakeと呼ばれるQuickStartを参考にしています。
機能についてより詳細な情報を知りたい方は是非公式ドキュメントとQuickStartをご参考ください。
データガバナンスの重要性について
組織にとってガバナンスの重要性が増す中、データは多様なソースや形式で拡散し、生成AIやLLMは機密情報を含む大規模データを扱っています。
企業はこれらのデータを活用しつつ、セキュリティや規制順守も求められています。
2023年8月のDeloitteのレポートでは、強力なデータガバナンスがなければ、生成AIの価値は限定され、リスクが高まると警告されています。
Snowflakeは、クロスクラウドで一貫したガバナンスモデルを提供し、顧客の複雑なデータ管理を支援しており、さらにその機能を「Snowflake Horizon」で強化しています。
Snowflake Horizonの紹介
Snowflake Horizonは、統合されたコンプライアンス、セキュリティ、プライバシー、相互運用性、アクセス機能を通じて、組織がデータやアプリケーションなどを管理し、発見できるようにします。
この機能は、追加の設定やプロトコルを必要とせずに顧客に提供されます。以下はその仕組みです。
今回ご紹介する機能は、大枠として次の3つです。
- データ品質監視
- データ保護
- アクセスと監査
Snowflake Horizonの機能紹介
データ品質監視
データ品質は、データ駆動型の意思決定を行うために、データの状態や整合性(データの鮮度や、列のヌル値や空白フィールドと比較した真のデータ値に関する正確性など)を把握することに重点を置いています。
データメトリック関数(DMFs)を使ってデータの品質を測定できます。Snowflakeは、一般的なメトリックを定義しなくても測定できるように、SNOWFLAKE.COREスキーマで組み込みシステムDMFsを提供します。
また、独自のカスタムDMFsを定義して、データ品質測定をより正確に微調整することもできます。これらのDMFsは、選択したデータベースとスキーマに保存されます。
データメトリック関数
データメトリック関数 | Snowflake Documentation
詳細については公式ドキュメントをご確認いただければと思いますが、簡単にデータメトリック関数(DMF)の紹介をします。
メリット:
- コンプライアンスを促進する:
データの状態を把握することで、コンプライアンスや規制基準を遵守していることを示しやすくなります。 - サービスレベル目標(SLO)の遵守:
FRESHNESSなどのデータメトリックにより、データの最新性を担保します。 - 信頼性:
信頼できるデータ主導の意思決定を促進するデータ検証を提供します。 - 一貫性:
システムDMFsを使用し、適切なカスタムDMFsを繰り返し使用することで、長期にわたって一貫したデータ品質評価が実現します。これにより、データの信頼性が向上します。 - 特定のユースケースのための最適化:
カスタムDMFsを使用することにより、データエンジニアはデータを測定するための正確なメトリックを設計することができ、データのターゲットアプリケーションのためのより正確な最適化につながります。 - 自動測定:
DMF をテーブルまたはビューに割り当て、 DMF の実行スケジュールを指定すると、 DMF の呼び出しが自動化されます。データ品質を積極的に測定するための追加作業は必要ありません。
サポートされるテーブルの種類
以下の種類のテーブルオブジェクトに DMF を設定できます:
- 動的テーブル
- イベントテーブル
- 外部テーブル
- Apache Iceberg™ テーブル
- マテリアライズドビュー
- テーブル(CREATE TABLE)、仮および一時テーブルを含む
- ビュー
ハイブリッドテーブルやストリームオブジェクトに DMF を設定することはできません。
システムデータメトリック関数(システムDMFs)
Snowflakeは、共有 SNOWFLAKE データベース の CORE スキーマでシステムDMFsを提供します。
システムDMFsは Snowflake によって管理され、システムDMFの名前や機能を変更することはできません。
Snowflakeにより提供されるシステムDMFsは次のとおりです。
| カテゴリ | システム DMFs | メモ |
| 精度 | – BLANK_COUNT – BLANK_PERCENT – NULL_COUNT – NULL_PERCENT | |
| 鮮度 | – FRESHNESS – DATA_METRIC_SCHEDULE_TIME | – 列データの鮮度を判定します。 – カスタム鮮度メトリックを定義します。 |
| 統計 | – AVG – MAX – MIN – STDDEV | |
| 独自性 | – DUPLICATE_COUNT – UNIQUE_COUNT | – NULL値を含む、列内の重複値の数を決定します。 – 列内のNULL以外の値の数を決定します。 |
| ボリューム | – ROW_COUNT |
今回は比較的取り組みやすい次のシステムDMFsの動作について紹介します。
- NULL_COUNT
- UNIQUE_COUNT
- DUPLICATE_COUNT
検証用データとしては次のデータを利用します。

NULL_COUNT関数はテーブル内にある指定した列のNULL値の合計数を返します。
以下のクエリはCUSTOMERテーブルのEMAILカラムに存在するNULL値を合計して結果として返します。

UNIQUE_COUNT関数はテーブルにある指定された列の非 NULL の一意な値の合計数を返します。

DUPLICATE_COUNT関数はNULLの値を含む、重複する列値の数を返します。

システムDMFsのスケジュール実行の設定も可能です。
--スケジュールを設定
--TRIGGER_ON_CHANGESは新しい行の挿入など、一般的な DML 操作でテーブルが変更されたときに実行されます
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER SET DATA_METRIC_SCHEDULE = 'TRIGGER_ON_CHANGES';
--CUSTOMERテーブルのEMAILカラムにNULL_COUNT関数を設定
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER ADD DATA METRIC FUNCTION SNOWFLAKE.CORE.NULL_COUNT on (EMAIL);
--CUSTOMERテーブルのEMAILカラムにUNIQUE_COUNT関数を設定
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER ADD DATA METRIC FUNCTION SNOWFLAKE.CORE.UNIQUE_COUNT on (EMAIL);
--CUSTOMERテーブルのEMAILカラムにDUPLICATE_COUNT関数を設定
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER ADD DATA METRIC FUNCTION SNOWFLAKE.CORE.DUPLICATE_COUNT on (EMAIL);;
--CUSTOMERテーブルのEMAILカラムにROW_COUNT関数を設定
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER ADD DATA METRIC FUNCTION SNOWFLAKE.CORE.ROW_COUNT on ();DATA_METRIC_SCHEDULEの設定を確認します。

カスタムデータメトリック関数(カスタムDMFs)
CREATE DATA METRIC FUNCTION コマンドを使用して自身の DMFs を作成することができます。
正規表現(RegEx)を使用して無効なメールアドレスをカウントするカスタムデータメトリック関数も作成してみます。
CREATE DATA METRIC FUNCTION HRZN_DB.HRZN_SCH.INVALID_EMAIL_COUNT(IN_TABLE TABLE(IN_COL STRING))
RETURNS NUMBER
AS
'SELECT COUNT_IF(FALSE = (IN_COL regexp ''^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,4}$'')) FROM IN_TABLE';現在無効なメールアドレスがいくつ存在するか確認してみます。

無効なメール数データメトリック関数(DMF)をテーブルに追加します。
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER ADD DATA METRIC FUNCTION HRZN_DB.HRZN_SCH.INVALID_EMAIL_COUNT ON (EMAIL);
データメトリクスの動作検証
動作検証目的で次のデータをINSERTしてみます。
INSERT INTO HRZN_DB.HRZN_SCH.CUSTOMER (
ID,
FIRST_NAME,
LAST_NAME,
STREET_ADDRESS,
STATE,
CITY,
ZIP,
PHONE_NUMBER,
EMAIL,
SSN,
BIRTHDATE,
JOB,
CREDITCARD,
COMPANY,
OPTIN
) VALUES
(999, 'Alice', 'Johnson', '742 Evergreen Terrace', 'CA', 'Springfield', '90210', '555-123-4567', 'alice@example.com', '123-45-6789', '1985-07-20', 'Software Developer', '4111111111111111', 'Acme Corp', 'Y');
すると、SNOWFLAKE.LOCAL.DATA_QUALITY_MONITORING_RESULTS テーブルにシステムDMFsのログが記録されます。実行されたことがわかります。
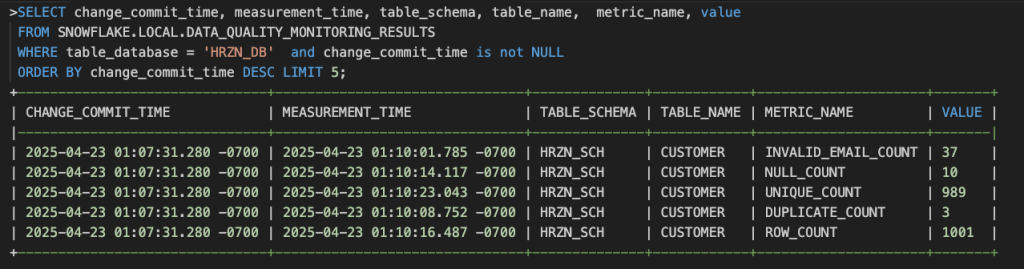
以上でデータメトリクス関数の紹介になります。
本番環境のシナリオでは、データ品質の変化が発生した際に通知するアラートを設定することが論理的な次のステップとなります。DMFとアラート機能を組み合わせることで、測定対象テーブルのデータ品質に関する一貫したしきい値通知が可能になります。
データの保護
データガバナンスにおいてデータの保護は非常に重要な要素です。
特に個人情報、機密情報、クレジットカード情報など扱いがデリケートなものがあります。
これらのデータを保護運用し、ガバナンスを効かせることを目指すことでデータに対するあらゆるリスクを軽減できます。
今回はデータ保護における次の機能を紹介します。
- オブジェクトへのタグ付け
- 手動タグ付け
- 動的タグ付け
- ダイナミックマスキングポリシー(列レベルマスキングポリシー)
- 行レベルマスキングポリシー
- 集約ポリシー
- 投影ポリシー
CUSTOMERテーブルを利用して、動作の紹介をします。
オブジェクトへのタグ付け
オブジェクトのタグ付け | Snowflake Documentation
オブジェクトにタグを付与することでどのようなメリットがあるでしょうか。
コンプライアンス、検出、保護、およびリソースの使用状況のユースケースに関する機密データをモニターできるようになります。
他にもタグを定義し、Snowflakeオブジェクトにタグを割り当てた後に、タグをクエリしてオブジェクトの使用状況をモニターして、モニター、監査、レポートなどのデータガバナンス操作を容易にすることができます。
今回はタグをもとにデータ保護を制御(タグベースのマスキングポリシー)することを目的としています。
次にタグ付けの2つの手法についてご紹介します。
1.手動タグ付け
タグベースのマスキングポリシーは、オブジェクトのタグ付け機能とマスキングポリシー機能を組み合わせ、ALTER TAGコマンドを使用してタグにマスキングポリシーを設定できます。
マスキングポリシーシグネチャのデータ型と列のデータ型が一致する場合、タグ付けされた列はマスキングポリシーの条件によって自動的に保護されます。
例として機密データタグを作成し、コメントを追加してみます。
create tag HRZN_DB.TAG_SCHEMA.confidential allowed_values 'Sensitive','Restricted','Highly Confidential';
alter tag HRZN_DB.TAG_SCHEMA.confidential set comment = 'Confidential information';
create tag HRZN_DB.TAG_SCHEMA.pii_type allowed_values 'Email','Phone Number','Last Name';
alter tag HRZN_DB.TAG_SCHEMA.pii_type set comment = 'PII Columns';タグを作成するときに、allowed_values で付与できる値を制限することができます。 これは誤って意図しない値をconfidential タグに付与させないようにするためです。
こうすることでデータガバナンスの一貫性と信頼性を保つのに役立ちます。
ちなみに、意図しない値を付与しようとすると次のエラーが発生します。
>alter table customer set tag HRZN_DB.TAG_SCHEMA.confidential = 'Top Secret';
391826 (23001): Value 'Top Secret' is not allowed by the specified allowed_values for tag 'CONFIDENTIAL'.次に、テーブルと列レベルでタグを適用する
テーブルにタグを設定する意図としては、テーブル全体の意味・分類を明示することができ、テーブル単位のコスト配賦や権限管理と連動することでコストやアクセス権限の設計がしやすくなります。
--Table Level
alter table HRZN_DB.HRZN_SCH.customer set tag HRZN_DB.TAG_SCHEMA.confidential ='Sensitive';
alter table HRZN_DB.HRZN_SCH.customer set tag HRZN_DB.TAG_SCHEMA.cost_center ='Sales';
--Column Level
alter table HRZN_DB.HRZN_SCH.customer modify email set tag HRZN_DB.TAG_SCHEMA.pii_type ='Email';
alter table HRZN_DB.HRZN_SCH.customer modify phone_number set tag HRZN_DB.TAG_SCHEMA.pii_type ='Phone Number';
alter table HRZN_DB.HRZN_SCH.customer modify last_name set tag HRZN_DB.TAG_SCHEMA.pii_type ='Last Name';カラムに付与したタグを使って動的マスキングポリシー、行レベルのマスキングポリシーを制御可能となります。 ただし、このように手動でのタグ付与は大変です。 次に SYSTEM$CLASSIFY を使ったタグの自動分類をご紹介します。
2.タグの自動分類
以下はCUSTOMERテーブルを分類し、カラムにシステムタグを設定します。
CALL SYSTEM$CLASSIFY('HRZN_DB.HRZN_SCH.CUSTOMER', {'auto_tag': true});
-- SYSTEM$CLASSIFY_SCHEMAを利用することで、スキーマ単位での自動分類もサポートしています。
CALL SYSTEM$CLASSIFY_SCHEMA('HRZN_DB.HRZN_SCH', {'auto_tag': true});ただし、SYSTEM$CLASSIFY が自動で付与するタグはシステムタグ のみになります。
システムタグ
| システムカテゴリ | 説明 |
| セマンティックカテゴリ | セマンティックカテゴリは、個人の属性を識別します。 分類がサポートする個人属性の非網羅的なリストには、名前、年齢、性別が含まれます。 これら3つの属性は、 SEMANTIC_CATEGORY タグを列に割り当てるときに使用可能な文字列値です。 分類により、オーストラリア、カナダ、英国など、さまざまな国から情報を検出することができます。 たとえば、テーブルの列に電話番号の情報が含まれている場合、分析プロセスでは、それぞれの国の異なる電話番号の値を区別することができます。 |
| プライバシーカテゴリ | 分析により、列データがセマンティックカテゴリに対応すると判断された場合、Snowflakeはさらに列をプライバシーカテゴリに分類します。 プライバシーカテゴリには、識別子、準識別子、機密の3つの値があります。 これら3つの値は、 PRIVACY_CATEGORY 分類システムタグを列に割り当てるときに指定できる文字列値です。 識別子: これらの属性は、個人を一意に識別します。 属性の例には、名前、社会保障番号、電話番号などがあります。 識別子属性は 直接識別子 と同義です。 準識別子: これらの属性は、2つ以上の属性が組み合わされた場合に、個人を一意に識別することができます。 属性の例には、年齢と性別が含まれます。 準識別子は 間接識別子 と同義です。 機密: これらの属性は、個人を識別するのに十分とは見なされませんが、個人がプライバシー上の理由で開示を望まない情報です。 現在、Snowflakeが機密と評価する唯一の属性は給与です。 非機密: これらの属性には個人情報や機密情報は含まれません。 |
SYSTEM$CLASSIFYによって自動的に適用された新しいタグを見てみます。
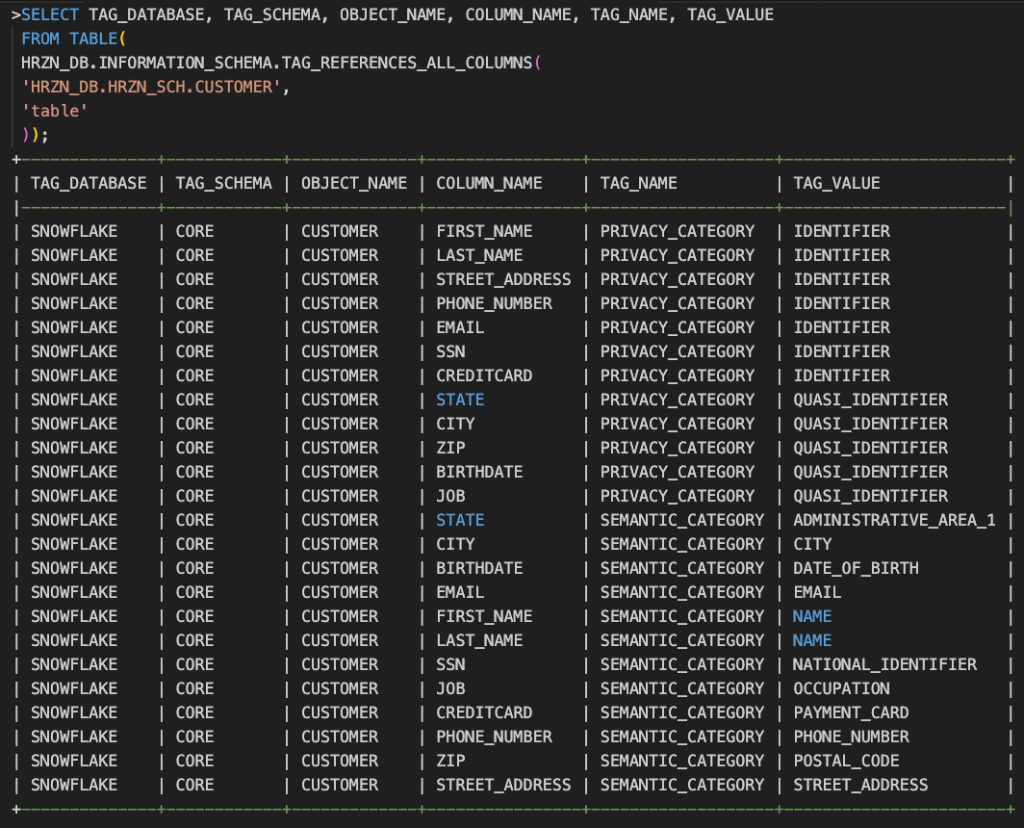
カスタム分類
custom_classifierを使って、CREDITCARDという名前のカスタム分類子を作成します。 c
create or replace snowflake.data_privacy.custom_classifier CREDITCARD();CREDITCARD カスタム分類にMC_PAYMENT_CARD(マスターカード)とAMX_PAYMENT_CARD(アメリカン・エキスプレス)を分類する正規表現を定義します。
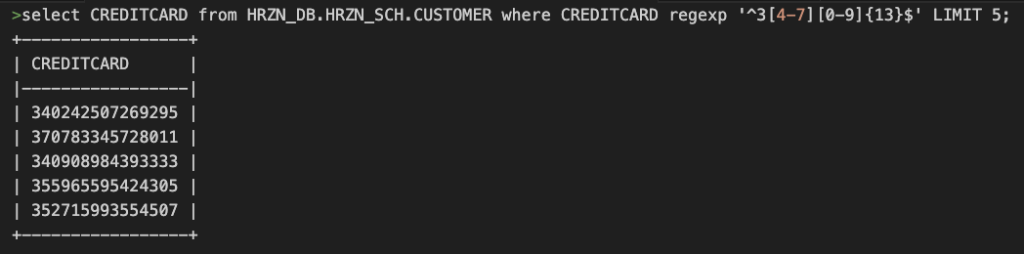
Call creditcard!add_regex('MC_PAYMENT_CARD','IDENTIFIER','^(?:5[1-5][0-9]{2}|222[1-9]|22[3-9][0-9]|2[3-6][0-9]{2}|27[01][0-9]|2720)[0-9]{12}$');
Call creditcard!add_regex('AMX_PAYMENT_CARD','IDENTIFIER','^3[4-7][0-9]{13}$');AMX_PAYMENT_CARDの分類が期待する結果となることを確認する。
カスタム分類を適用
CALL SYSTEM$CLASSIFY('HRZN_DB.HRZN_SCH.CUSTOMER',{'auto_tag': true, 'custom_classifiers': ['HRZN_DB.CLASSIFIERS.CREDITCARD']});SYSTEM$GET_TAG関数を使って、CREDITCARDカラムのTAG分離類がどうなったか確認してみます。 CUSTOMERテーブルのCREDITCARDカラムに対して、PAYMENT_CARDタグが付与されています。

動的データマスキング
列レベルのセキュリティについて | Snowflake Documentation
Snowflakeでは、列レベルのセキュリティを使用して動的なマスキングと条件付きポリシーの作成が可能です。
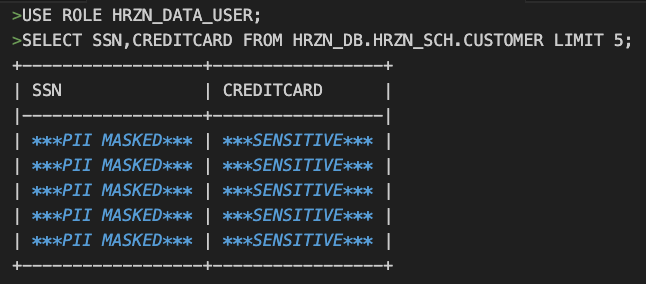
例として、ACCOUNTADMINとHRZN_DATA_GOVERNORロール以外からのアクセス時は***PII MASKED*** のマスク表示になるようなMASK_PII というマスキングポリシーを作成します。
MASK_SENSITIVE も同様です。
それぞれのマスキングポリシーをSSNとCREDITCARDカラムに適用します。
-- Create masking policy for PII
CREATE OR REPLACE MASKING POLICY HRZN_DB.TAG_SCHEMA.MASK_PII AS
(VAL CHAR) RETURNS CHAR ->
CASE
WHEN CURRENT_ROLE() IN ('ACCOUNTADMIN', 'HRZN_DATA_GOVERNOR') THEN VAL
ELSE '***PII MASKED***'
END;
CREATE OR REPLACE MASKING POLICY HRZN_DB.TAG_SCHEMA.MASK_SENSITIVE AS
(VAL CHAR) RETURNS CHAR ->
CASE
WHEN CURRENT_ROLE() IN ('ACCOUNTADMIN', 'HRZN_DATA_GOVERNOR') THEN VAL
ELSE '***SENSITIVE***'
END;
--Apply policies to specific columns
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER MODIFY COLUMN SSN SET MASKING POLICY HRZN_DB.TAG_SCHEMA.MASK_PII;
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER MODIFY COLUMN CREDITCARD SET MASKING POLICY HRZN_DB.TAG_SCHEMA.MASK_SENSITIVE;ポリシー通り、HRZN_DATA_GOVERNORロールであれば参照できています。
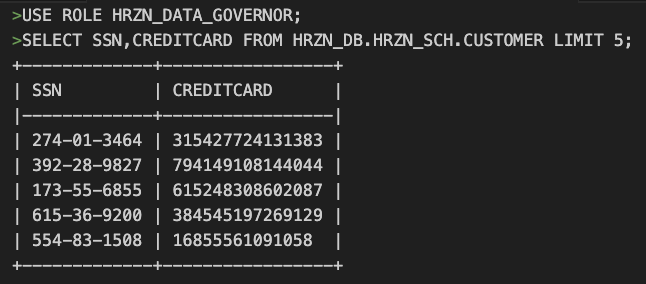
ロールをHRZN_DATA_USERへ変更して、確認してみるとマスキングされています。
オプトイン(同意)によるマスキング
マスキングポリシーの派生系として、オプトインによるマスキングもできます。
これは対象テーブルのカラムにoptinを用意しておき、参照可or負荷をoptinの値によって制御する仕組みです。
以下のオプトインマスキングの例ですと、optin = 'Y' の部分でYなら参照できる、Nならマスキングするという定義となっています。
create or replace masking policy HRZN_DB.TAG_SCHEMA.conditionalPolicyDemo
as (phone_nbr string, optin string) returns string ->
case
when optin = 'Y' then phone_nbr
else '***OPT OUT***'
end;
alter table HRZN_DB.HRZN_SCH.CUSTOMER modify column PHONE_NUMBER set masking policy HRZN_DB.TAG_SCHEMA.conditionalPolicyDemo using (PHONE_NUMBER, OPTIN);実際にアクセスしてみると次のような結果となります。
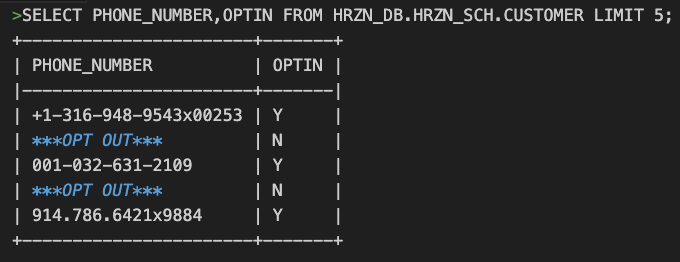
ただし、先ほどのオプトインマスキングだとロール制御を取り入れていないため、最上位権限のACCOUNTADMINでもオプトイン処理されてしまいます。
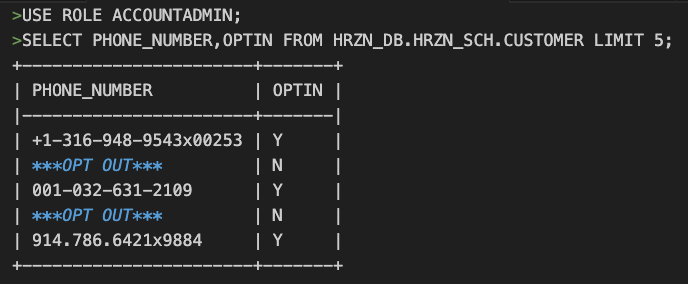
ロールによる制御を入れたい場合はcaseの条件文にROLEでの条件を追加します。
create or replace masking policy HRZN_DB.TAG_SCHEMA.conditionalPolicyDemo
as (phone_nbr string, optin string) returns string ->
case
when current_role() in ('ACCOUNTADMIN', 'HRZN_DATA_GOVERNOR') and optin = 'Y' then phone_nbr
else '***OPT OUT***'
end;
alter table HRZN_DB.HRZN_SCH.CUSTOMER modify column PHONE_NUMBER set masking policy HRZN_DB.TAG_SCHEMA.conditionalPolicyDemusing (PHONE_NUMBER, OPTIN);次のような結果となります。
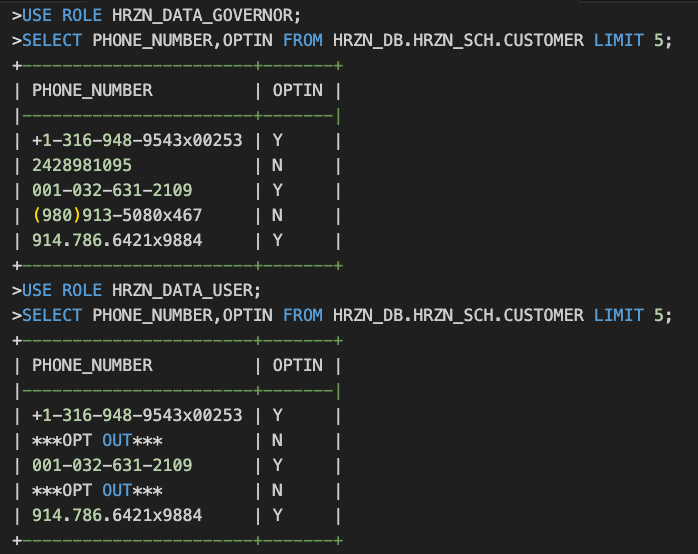
最後は柔軟なマスキングポリシー設定の例をご紹介します。
PII_COLというタグを作成し、PII_DATA_MASK マスキングポリシーを定義します。
マスキングポリシー定義内で特定のタグと値を持つカラムを対象とした条件を設定することでわざわざカラムにマスキングポリシーを設定せずとも適用することが可能となります。
--Create a Tag
CREATE OR REPLACE TAG HRZN_DB.TAG_SCHEMA.PII_COL ALLOWED_VALUES 'PII-DATA','NON-PII';
--Apply to the table
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER MODIFY COLUMN LAST_NAME SET TAG HRZN_DB.TAG_SCHEMA.PII_COL = 'PII-DATA';
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER MODIFY COLUMN BIRTHDATE SET TAG HRZN_DB.TAG_SCHEMA.PII_COL = 'PII-DATA';
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER MODIFY COLUMN STREET_ADDRESS SET TAG HRZN_DB.TAG_SCHEMA.PII_COL = 'PII-DATA';
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER MODIFY COLUMN CITY SET TAG HRZN_DB.TAG_SCHEMA.PII_COL = 'PII-DATA';
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER MODIFY COLUMN STATE SET TAG HRZN_DB.TAG_SCHEMA.PII_COL = 'PII-DATA';
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER MODIFY COLUMN ZIP SET TAG HRZN_DB.TAG_SCHEMA.PII_COL = 'PII-DATA';
--Create Masking Policy
CREATE OR REPLACE MASKING POLICY HRZN_DB.TAG_SCHEMA.PII_DATA_MASK AS (VAL string) RETURNS string ->
CASE
WHEN SYSTEM$GET_TAG_ON_CURRENT_COLUMN('HRZN_DB.TAG_SCHEMA.PII_COL') = 'PII-DATA'
AND CURRENT_ROLE() NOT IN ('HRZN_DATA_GOVERNOR','ACCOUNTADMIN')
THEN '**PII TAG MASKED**'
ELSE VAL
END;
--Apply Masking policy to the tag
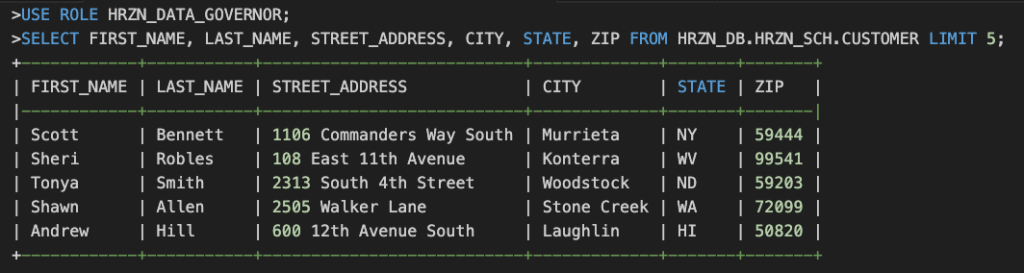
ALTER TAG HRZN_DB.TAG_SCHEMA.PII_COL SET MASKING POLICY HRZN_DB.TAG_SCHEMA.PII_DATA_MASK;HRZN_DATA_USERロールで動作確認してみましょう。
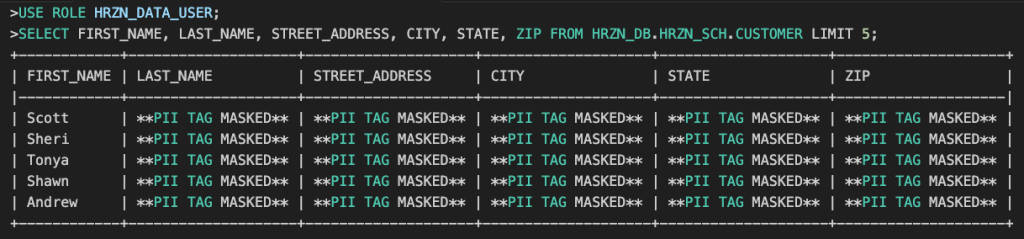
HRZN_DATA_GOVERNORロールに変更すれば、マスキングなしで参照できます。
行アクセスポリシー
HRZN_DATA_GOVERNORがタグ ベースの動的マスキングによる列レベルでのマスキングの制御を実現できましたので、次はHRZN_DATA_USERロールの行レベルでのアクセスを制限する方法をご紹介します。
今回ご紹介する行アクセスポリシーは マッピングテーブルルックアップ 方式となります。
CUSTOMERテーブル内で、HRZN_DATA_USERロールロールにはマサチューセッツ州 (MA) に拠点を置く顧客のみ(STATEカラムがMAのみ)表示させたいとします。

まず、ROW_POLICY_MAPテーブルに次のようなデータを定義しておきます。
このテーブルがマッピングテーブルです。
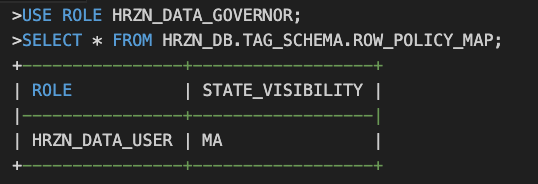
そしてCUSTOMER_STATE_RESTRICTIONS マスキングポリシーを作成します。
簡単にマスキングポリシーの定義説明をすると、CURRENT_ROLE() IN() で定義されたロールでのアクセスは全てのデータを返しますが、OR EXISTS 内部のサブクエリでマッチしたロールの場合は AND 条件にマッチしたデータのみを返します。
CREATE OR REPLACE ROW ACCESS POLICY HRZN_DB.TAG_SCHEMA.CUSTOMER_STATE_RESTRICTIONS
AS (STATE STRING) RETURNS BOOLEAN ->
CURRENT_ROLE() IN ('ACCOUNTADMIN','HRZN_DATA_ENGINEER','HRZN_DATA_GOVERNOR')
OR EXISTS
(
SELECT rp.ROLE
FROM HRZN_DB.TAG_SCHEMA.ROW_POLICY_MAP rp
WHERE 1=1
AND rp.ROLE = CURRENT_ROLE()
AND rp.STATE_VISIBILITY = STATE
)
COMMENT = 'Policy to limit rows returned based on mapping table of ROLE and STATE: governance.row_policy_map';
-- CUSTOMERテーブルのSTATEカラムに対して、CUSTOMER_STATE_RESTRICTIONSマスキングポリシー適用
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER ADD ROW ACCESS POLICY HRZN_DB.TAG_SCHEMA.CUSTOMER_STATE_RESTRICTIONS ON (STATE);
挙動を確認してみます。
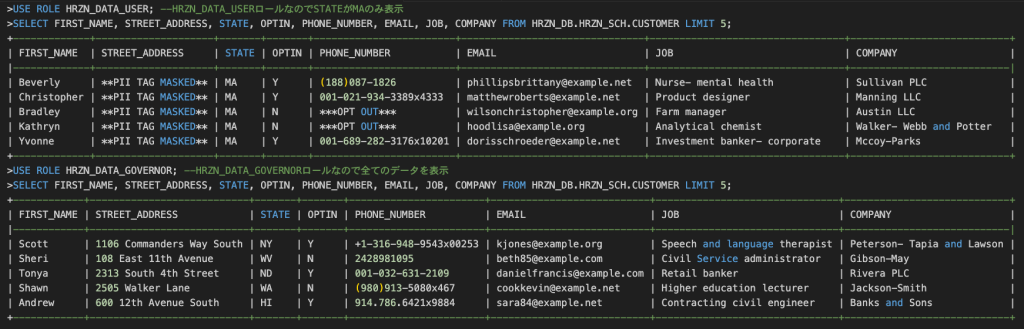
集計ポリシー
集計ポリシー | Snowflake Documentation
集計ポリシーは、テーブルまたはビューのデータにアクセスできるクエリの種類を制御する、スキーマレベルのオブジェクトです。集計ポリシーがテーブルに適用されている場合、そのテーブルに対するクエリは、結果を返すためにデータを最小サイズのグループに集計する必要があり、それによってクエリが個々の記録から情報を返すことを防ぎます。集計ポリシーが割り当てられたテーブルまたはビューは、 集計制約付きであると言われます。
集計ポリシーを作成するとき、プロバイダ-のポリシー管理者は、最小グループサイズ(つまり、グループに集計する必要がある行の数)を指定します。最小グループサイズが大きければ大きいほど、コンシューマーがクエリ結果を使用して1つの記録の内容を推測できる可能性が低くなります。
内容の推測を阻止することで、データの個人情報などの情報漏洩を防ぐことができます。
次のクエリは集計ポリシーの作成例です。
ポリシー自体の引数はなく、CURRENT_ROLE() によるロール条件で制御を行います。
条件にマッチしない場合、ELSE の通り、各集計グループに含める必要がある行数を指定します。
集計クエリの結果、グループの行数が指定したかずに届かない場合、クエリは実行されません。
CREATE OR REPLACE AGGREGATION POLICY HRZN_DB.TAG_SCHEMA.aggregation_policy
AS () RETURNS AGGREGATION_CONSTRAINT ->
CASE
WHEN CURRENT_ROLE() IN ('ACCOUNTADMIN','HRZN_DATA_ENGINEER','HRZN_DATA_GOVERNOR')
THEN NO_AGGREGATION_CONSTRAINT()
ELSE AGGREGATION_CONSTRAINT(MIN_GROUP_SIZE => 100)
END;
集計ポリシーを作成したので、それを注文ヘッダーテーブルに適用してみましょう。
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER_ORDERS SET AGGREGATION POLICY HRZN_DB.TAG_SCHEMA.aggregation_policy;
動作確認をしてみます。
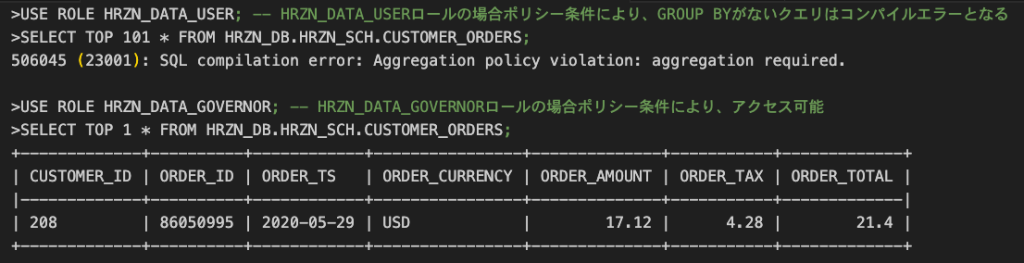
HRZN_DATA_USERロールの場合、SELECT * のような集計関数のないクエリはクエリ結果から個人を特定できてしまう可能性があるため、禁止されています。
次に集約関数を使った場合の動作を確認してみます。
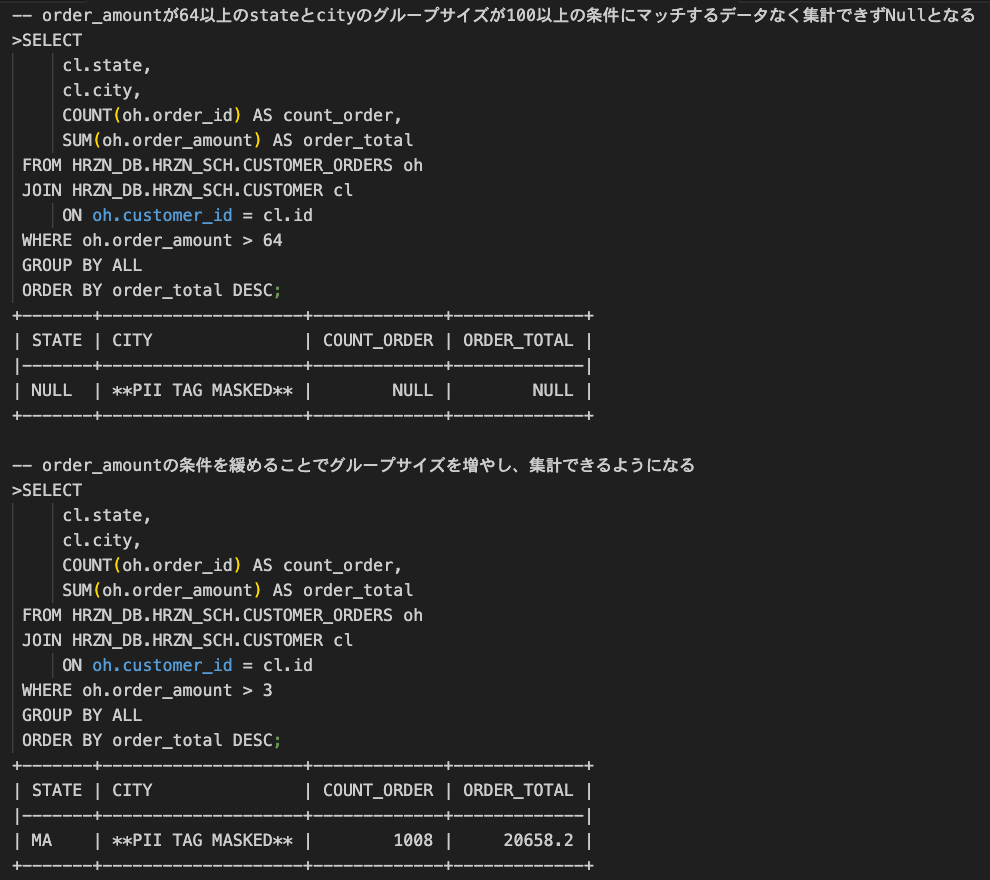
投影ポリシー
投影ポリシー | Snowflake Documentation
投影ポリシーは、クエリが SELECT ステートメントを使用して列から値を投影(出力)することを防ぎます。
投影ポリシーは、SQLクエリ結果の出力において列を投影できるかどうかを定義する、スキーマレベルのファーストクラスのオブジェクトです。 投影ポリシーが割り当てられた列は、投影制約付きと呼ばれます。
TAG_SCHEMAスキーマに条件付き投影ポリシーを作成し、任意のロールにのみ割り当て先の列を投影できるようにします。
USE ROLE HRZN_DATA_GOVERNOR;
CREATE OR REPLACE PROJECTION POLICY HRZN_DB.TAG_SCHEMA.projection_policy
AS () RETURNS PROJECTION_CONSTRAINT ->
CASE
WHEN CURRENT_ROLE() IN ('ACCOUNTADMIN','HRZN_DATA_ENGINEER', 'HRZN_DATA_GOVERNOR')
THEN PROJECTION_CONSTRAINT(ALLOW => true)
ELSE PROJECTION_CONSTRAINT(ALLOW => false)
END;投影ポリシーを設定したら、ZIPカラムに割り当てます。
ALTER TABLE HRZN_DB.HRZN_SCH.CUSTOMER MODIFY COLUMN ZIP SET PROJECTION POLICY HRZN_DB.TAG_SCHEMA.projection_policy;HRZN_DATA_USERロールはポリシー違反となりZIPカラムの参照において、SQL compilation error となります。

この投影ポリシーは、HRZN_DATA_USERロールが SELECT 句に郵便番号列を含めることをブロックしますが、分析を支援するために WHERE 句で引き続き使用できます。
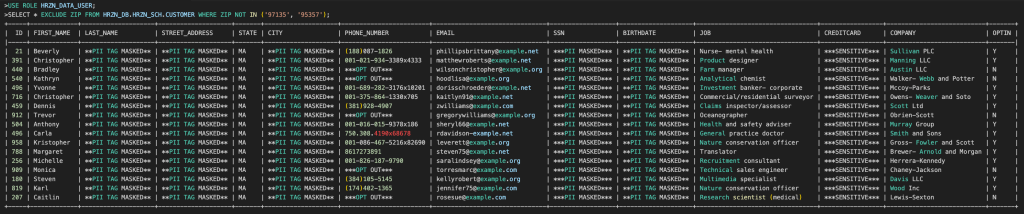
アクセスと監査
概要
アクセス履歴は、ユーザークエリに関する洞察を提供し、どのデータがいつ読み取られたか、またどのステートメントが書き込み操作を実行したかなどを把握できます。
アクセス履歴は、コンプライアンス、監査、ガバナンスにおいて特に重要です。
例えば「HRZN」から始まるオブジェクトへどのようにアクセスされているか確認することができます。
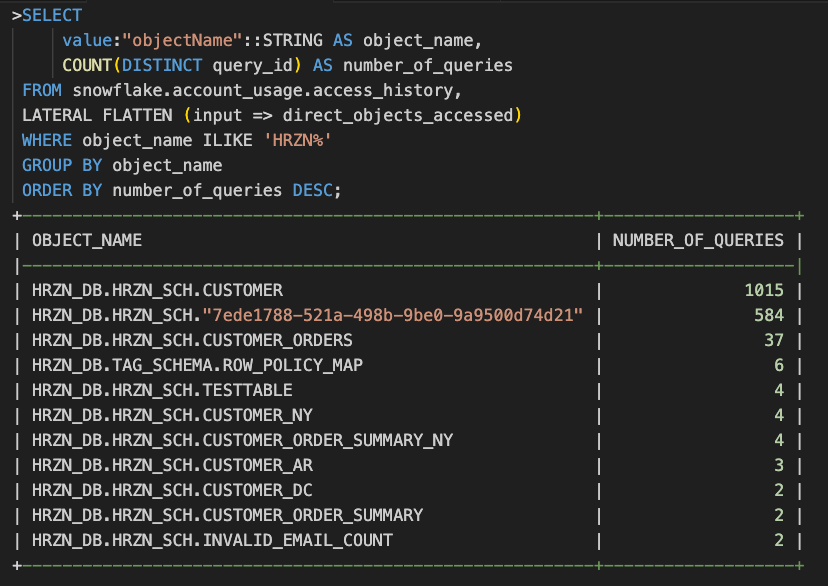
別の角度として、読み取りクエリと書き込みクエリの内訳を確認することもできます。
ここから多く利用されているテーブルから全くアクセスされていないテーブルなどの洞察を得ることができ、全く利用がないデータは何故利用されていないのか?の深掘りをすることでそもそも需要がないのか、データに不備があり誰からも信用されず利用されないのか、その結果によっては次のアクションを計画できます。
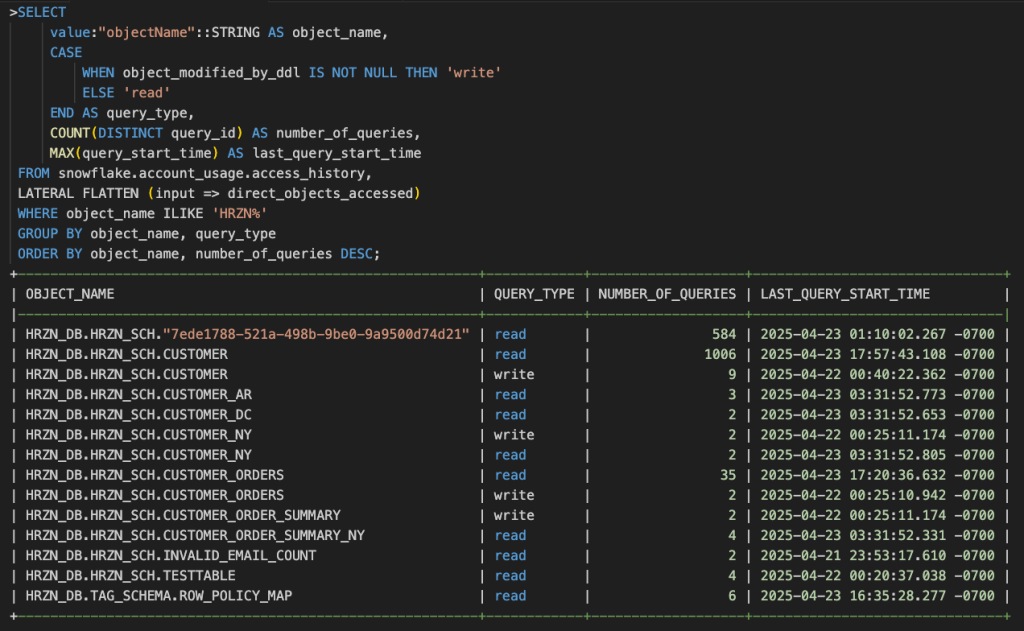
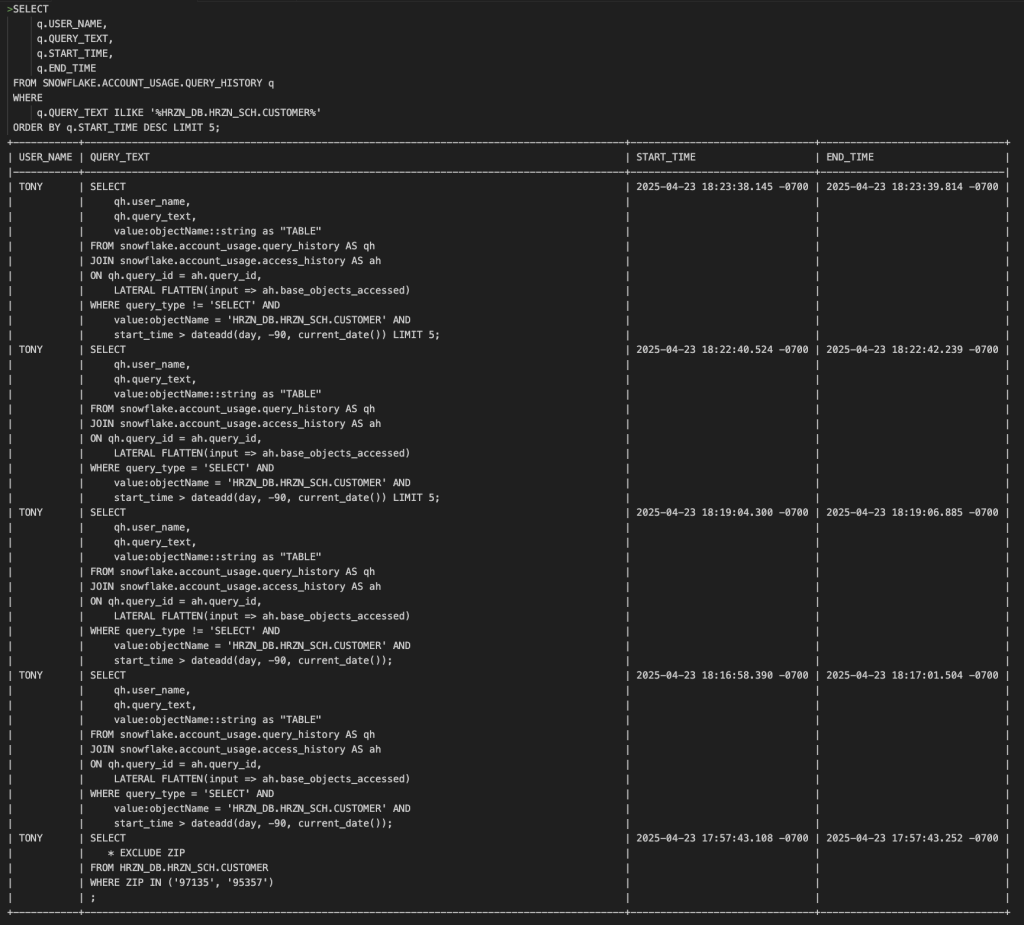
さらに直近90日までで実行されたクエリと対象テーブル、実行ユーザを確認できます。
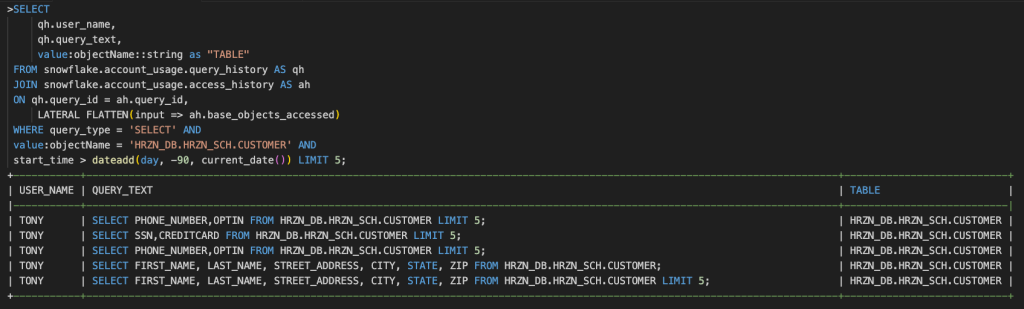
SELECT以外のクエリの実行履歴を確認したい場合は次のようなクエリを実行することで確認することができます。
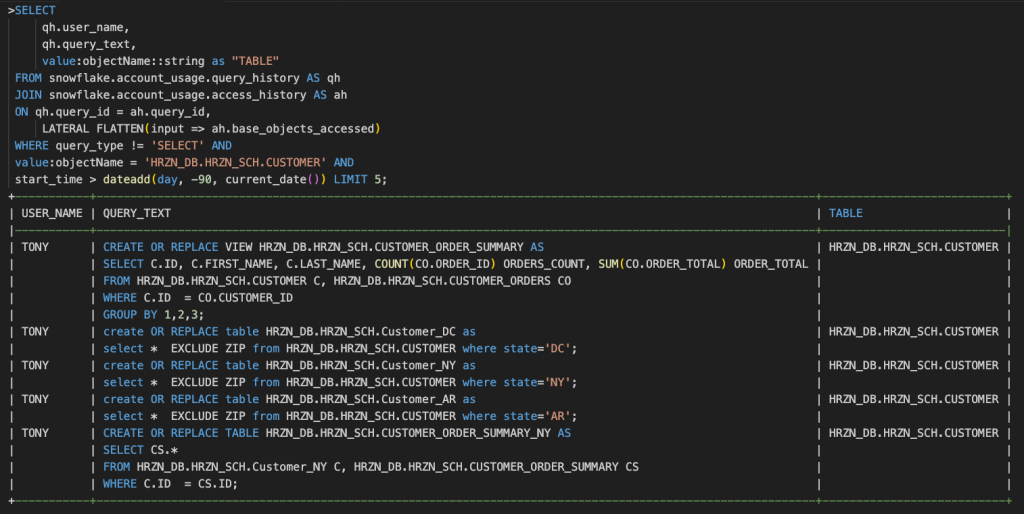
最も長く実行されているクエリを見つけることでクエリパフォーマンス改善のアクションを取るかの判断材料とすることもできます。
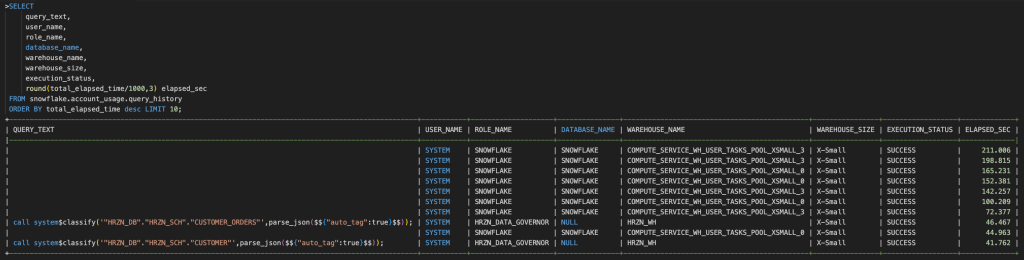
機密データを含むテーブルに対して実行されたクエリを検索することもできます。
まとめ
記事では、「データ品質の監視」「データ保護」「アクセスと監査」の3つの観点から、データガバナンスを強化するための機能をご紹介しました。
まず、データ品質の監視については、データの品質を担保するための「データメトリック関数」をご紹介しました。この機能を活用することで、データの鮮度(新鮮性)、完全性(抜け漏れのなさ)、正確性を確保できます。
「Garbage In, Garbage Out(ゴミを入れれば、ゴミが出る)」という言葉の通り、不確かなデータからは確かな分析結果を得ることはできません。そのためにも、データ品質の監視を徹底し、信頼できるデータに基づいた意思決定が可能な土台を構築することが重要です。
次に、データ保護の観点では、Snowflakeにおけるタグ付け、動的マスキング、行アクセス制御、および集計ポリシーについて体系的に整理しました。
まず「タグ機能」は、カラムやテーブルに対して「個人情報」や「機密情報」などのメタデータを付与できる仕組みであり、ポリシーの条件分岐に活用できる重要な基盤です。
「動的マスキングポリシー」や「行アクセスポリシー」は、これらのタグ情報を参照しながら、ユーザーの権限やロールに応じた柔軟なデータ制御を実現します。
特に行アクセスポリシーでは、「ポリシー条件がTrueである場合に、その行が表示される」という設計思想が重要であり、管理者ロールや条件に合致する特定ロールのみが、意図されたデータにアクセスできる仕組みとなっています。
また、Snowflakeの集計ポリシー(Aggregation Policy)を利用することで、指定した最小グループサイズ(例:100)に満たない場合、集計結果をNULLにすることができ、少人数データに対する情報漏えいを防止できます。
ただし、この機能は WHERE 句でのデータ絞り込みや GROUP BY の粒度によって、意図せず発動する可能性があるため、集計設計時には注意が必要です。
これらの機能を組み合わせることで、Snowflake上において「高いセキュリティ」と「柔軟なデータ活用」を両立できることが確認できました。
最後に、アクセスと監査の観点では、「どのデータに」「誰が」「どのようなアクセスをしているか」を確認できます。
管理者が意図していないユーザーによるアクセスや、意図しないクエリの実行、パフォーマンスの悪いクエリの実行などを監視することは、セキュリティ面だけでなく、コスト管理の観点からも非常に重要です。
今後、これらの機能は、データガバナンスやプライバシー保護を強化したい組織にとって、ますます欠かせない存在となるでしょう。