
はじめに
Sreake事業部で長期インターンをしている竜です。
本記事では、GKEのカスタムコンピューティングクラスについて調査を行いました。
カスタムコンピューティングクラスの概要
GKEのカスタムコンピューティングクラスは、バージョン1.30.3-gke.1451000 以降の GKE Autopilot モードと GKE Standard モードで使用できる、ワークロードの要件に合わせたノード構成をプロビジョニングするための宣言型プロファイルです。特定のインスタンスタイプを利用したい場合はそれを優先するように定義でき、機械学習のような特定の用途ではGPUを活用した構成を優先し、運用コストを抑えるためにはSpot VMを利用するように設定することも可能です。さらに、優先するノードが利用できない場合には代替構成にフォールバックし、リソース不足によるスケジュールの遅延を最小限に抑えます。[1]カスタムコンピューティングクラスを利用することで、各組織の要件に合わせたインスタンスを起動でき、インフラ運用におけるコスト削減が期待できます。
例えば、n2のインスタンスを最優先で利用し2番目にn2dのインスタンスを利用したいというルールをカスタムリソースで作成・適用すると、コンピューティングクラスに関連付けられているPodはn2ノードにスケジューリングされます。
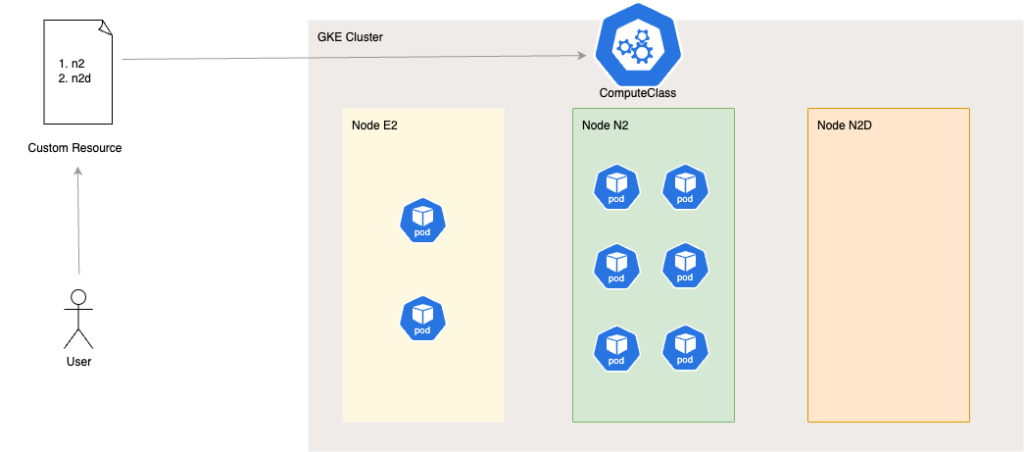
使い方
CRDについて
コンピューティングクラスは、Kubernetesの標準リソースではなく、Kubernetesを機能拡張した独自のリソースを用いて適用するものになります。そのため、ユーザはカスタムリソースを記述してコンピューティングクラスを利用することになります。カスタムリソースの定義がCRD(Custom Resource Definition)であり、CRDを確認することでカスタムリソースの構造や仕様を把握することができます。
コンピューティングクラスのCRDを確認したい場合、以下のコマンドを実行します。
kubectl describe crd computeclasses.cloud.google.com
CRDの中身については後ほど一部確認を行います。
また、カスタムコンピューティングクラスを利用する場合、手動で作成したノードプールを利用する場合と自動プロビジョニングによりノードプールを管理する場合とで利用方法が異なるため、両方の状態における使い方を紹介します。
手動で作成したノードプールを使用する場合
手動で作成したノードプールをコンピューティングクラスに関連付けるためには、ノードプールの作成時または更新時に以下のノードラベルとノードTaintを付与する必要があります。クラスタ内の各ノードプールは1つのコンピューティングクラスに関連付けることができます。
- ノードラベル:
cloud.google.com/compute-class=COMPUTE_CLASS - ノードTaint:
cloud.google.com/compute-class=COMPUTE_CLASS:NoSchedule
なお、COMPUTE_CLASS の部分にはカスタムリソースで定義したコンピューティングクラスの名前(metadata.name)が入ります。[2]
コンピューティングクラスをリクエストするPodに対してはNodeSelectorを付与することで、GKEが自動でtaintsに対するtolerationsを付与します。[3]
実際に、このようにコンピューティングクラスをリクエストしたPodに付与されているTolerationを確認すると、手動で付与していないにも関わらず以下のようなTolerationが自動で付与されています。このTolerationにより、PodはCompute_Classに関するTaintを許容するようになり、該当のノードがスケジュール対象として選択されることになります。
{
"effect": "NoSchedule",
"key": "cloud.google.com/compute-class",
"operator": "Equal",
"value": "dev-class"
}
一方、NodeSelectorを付与せずコンピューティングクラスのリクエストをしていないPodに対しては、このようなTolerationは自動で付与されることはありません。また、このようなPodに対してはコンピューティングクラスのルール適用は行われずにClusterAutoScalerのデフォルトの挙動を取り、e2ノードへのスケジューリングが行われます。手動で作成しているNodeについてはTaintを付与していますが、デフォルトで存在しているe2ノードにはTaintがなくスケジューリングを行うことができるためです。
ただし、クラスタ内において手動で作成したノードプールのみを使用し、ノードプールをコンピューティングクラスに関連付けない場合、コンピューティングクラスをリクエストする Pod は Pending状態となるので注意が必要です。Podに付与しているNodeSelectorを満たすNodeが存在しないためです。また、すべてのノードプールを特定のコンピューティングクラスに関連付ける場合、別のコンピューティングクラスをリクエストする Pod と、コンピューティングクラスをリクエストしない Pod はPending状態のままになります。[4]これは、ノードに付与されているTaintsを許容するようなTolerationsがPodに付与されないためです。
自動プロビジョニングによりノードプールを管理する場合
クラスタでノードの自動プロビジョニングが有効になっていることを確認した上で、enabled: true の値を持つ nodePoolAutoCreation フィールドをコンピューティングクラスのカスタムリソースに追加すれば良いです。[5]
コンピューティングクラス適用時に自動でプロビジョニングされたノードには自動でTaintが付与され、手動で付与したりする必要はありません。
実際、自動でプロビジョニングされたノードに付与されているTaintを確認すると、手動で付与していないにも関わらず以下のようなTaintが自動で付与されています。
{
"name": "gke-sreake-intern-tr-41ba99c1-nhlm",
"taints": [
{
"effect": "NoSchedule",
"key": "cloud.google.com/compute-class",
"value": "dev-class"
}
]
}
ただし、手動で作成したノードプールを使用する場合と同様に、Pod等を作成する際にコンピューティングクラスをリクエストするためには、マニフェストにそのコンピューティングクラスのノードセレクタを追加する必要があります。
カスタムリソースの例
概要
カスタムリソースの例は以下のようになります。
適用後、GKEは以下のような挙動を取ります。
- 既存の N2 ノードプールまたは自動で新たに作成されたノードプールに N2 ノードをプロビジョニング
- GKE が N2 ノードを作成できない場合、既存の N2D ノードプールのスケールアップを行うか、新しい N2D ノードプールを作成する
- 途中でN2ノードがまた利用可能な状態になったらN2ノードプールをスケールしN2ノードへスケジューリングを行う
このように、GKE はコンピューティングクラスに基づいて最適なノード構成を選択し、必要に応じて代替ノードプールをスケールアップまたは新規作成することで、ワークロードの実行要件を満たします。
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dev-class
spec:
priorities:
- machineFamily: n2
- machineFamily: n2d
nodepoolAutoCreation:
enabled: true
activeMigration:
optimizeRulePriority: true
CRDに基づく各フィールドの確認
上記のカスタムリソースに関連して、まずはPriorities配下で定義できるフィールドについて、CRDで確認してみます。Priorities配下では、使用したいマシンの構成を優先順位付けして定義することができます。
例えば、GPUについてはGPUの種類と使用したい個数を定義できます。また、先ほどの例にも挙げましたがノードで使用したいインスタンスについて、インスタンスファミリー(n2やe2など)及び具体的なインスタンスタイプ(n2-standard-2やe2-standard-2など)を指定することができます。
さらに、起動したいノードについて必要な最低CPUコア数やメモリ容量を定義できます。また、スポットインスタンスを使用するか否かや、ノードのストレージ構成を定義することもできます。優先的に使用したい既存のノードプールをリスト形式で指定することもできるようです。
このような内容は公式のドキュメントには書かれていない内容になるため、コンピューティングクラスを利用する際にはCRDの中身を一度確認してみるのが良さそうです。
Priorities:
Description: Priorities is a description of user preferences to be
used by a given ComputeClass.
Items:
Description: Priority is a specification of preferred machine characteristics.
Min Properties: 1
Properties:
Gpu:
Description: Gpu defines preferred GPU config for a node.
Properties:
Count:
Description: Count describes preferred count of GPUs for a node.
Format: int64
Type: integer
Type:
Description: Type describes preferred GPU accelerator type for a node.
Type: string
Type: object
Machine Family:
Description: Machine family describes preferred instance family for a node. If none is specified,
the default autoprovisioning machine family is used.
Type: string
Machine Type:
Description: MachineType defines preferred machine type for a node.
Type: string
Min Cores:
Description: MinCores describes a minimum number of CPU cores of a node.
Minimum: 0
Type: integer
Min Memory Gb:
Description: MinMemoryGb describes a minimum GBs of memory of a node.
Minimum: 0
Type: integer
Nodepools:
Description: Nodepools describes preference of specific, preexisting nodepools.
Items:
Type: string
Type: array
Spot:
Description: Spot if set to true specifies that a node should be a spot instance, on-demand otherwise.
Type: boolean
Storage:
Description: Storage describes storage config of a node.
Properties:
Boot Disk KMS Key:
Description: BootDiskKMSKey defines a key used to encrypt the boot disk attached.
Pattern: projects/[^/]+/locations/[^/]+/keyRings/[^/]+/cryptoKeys/[^/]+
Type: string
Boot Disk Size:
Description: BootDiskSize defines the size of a disk attached to node, specified in GB.
Minimum: 10
Type: integer
Boot Disk Type:
Description: BootDiskType defines type of the disk attached to the node.
Note that available boot disk types depend on the machine family / machine type selected.
Prioritiesフィールド以外の部分について中身を確認してみます。
enabled: true の値を持つ nodePoolAutoCreation フィールドを持っており、自動プロビジョニングが有効になっている場合に適用されます。
また、activeMigrationフィールドでoptimizeRulePriority: true を設定している場合、GKE が最初にそれらの Pod を優先度の低いノードプールのノードで実行する必要がある場合でも、最終的には、実行中のすべての Pod がそのコンピューティング クラスの最も優先度の高いノードプールのノードで実行するよう設定できるようになります。つまり、一時的に利用不可の状態でも利用可能になった段階で再度(途中からでも)優先的に起動させることもできるということです。
該当箇所のCRDは以下のようになります。Active MigrationでKubernetesの制御ループに基づいてリソースやクラスタの状態を監視し、Optimize Rule Priorityにおいて可能な限り最も優先度の高いルールを適用するか否かを決定することができます。そして、制御ループを回す中で優先度の高いルールが利用可能になればそれを適用する、というロジックとなっていることがわかります。
Properties:
Active Migration:
Description: ActiveMigration describes settings related to active reconciliation of
a given ComputeClass.
Properties:
Optimize Rule Priority:
Default: false
Description: OptimizeRulePriority defines whether workloads affected by given
ComputeClass should be migrated to nodepool defined by higher priority rule, if possible.
Type: boolean
Required:
optimizeRulePriority
Type: object
手動でノードプールを管理する場合はcloud.google.com/compute-class=dev-class というノードラベルとcloud.google.com/compute-class=dev-class:NoSchedule というTaintをノードプールに追加します。
シチュエーションごとの動作確認
優先度ルールの適用
先ほども紹介した、以下のカスタムリソースを状態で適用したとします。
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dev-class
spec:
priorities:
- machineFamily: n2
- machineFamily: n2d
nodepoolAutoCreation:
enabled: true
activeMigration:
optimizeRulePriority: true
適用前と適用後のクラスタ内のノードの状態を比較してみます。
コンピューティングクラス反映前に、レプリカ数が10のnginx Deploymentを適用したとします。
この時、以下のようにn2とn2dのノードにPodが分散されて配置されていることが確認できました。 なお、この結果は各ノードとそれに対応するノードプールを示しています。例えば、sreake-intern-tryu-np-n2というノードプールはn2のインスタンスタイプで構成されており、そのノードがn2インスタンスタイプであることを示します。
$ kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\\t"}{.metadata.labels.cloud\\.google\\.com/gke-nodepool}{"\\n"}{end}'
gke-sreake-intern-tr-nap-e2-standard--2144910f-vx72 nap-e2-standard-2-1q3qzkie
gke-sreake-intern-tr-0a622caa-2tlh sreake-intern-tryu-np-n2
gke-sreake-intern-tr-0a622caa-5c8k sreake-intern-tryu-np-n2
gke-sreake-intern-tr-0a622caa-jlqs sreake-intern-tryu-np-n2
gke-sreake-intern-tr-0a622caa-ztr6 sreake-intern-tryu-np-n2
gke-sreake-intern-tr-e6ecfda5-4rfh sreake-intern-tryu-np-n2d
gke-sreake-intern-tr-e6ecfda5-g0sj sreake-intern-tryu-np-n2d
gke-sreake-intern-tr-e6ecfda5-s4z7 sreake-intern-tryu-np-n2d
gke-sreake-intern-tr-e6ecfda5-v452 sreake-intern-tryu-np-n2d
各ノードプールに、ノードラベルとTaintを付与します。
labels = {
"cloud.google.com/compute-class" = "dev-class"
}
taint {
key = "cloud.google.com/compute-class"
value = "dev-class"
effect = "NO_SCHEDULE"
}
Deployment作成時にNodeSelectorをPodに付与するとGKEでMutating Admisson WebhookによりTolerationが差し込まれます。
以下が動作確認時に使用したDeploymentです。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 10
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
**nodeSelector:
cloud.google.com/compute-class: dev-class**
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
resources:
requests:
cpu: 1.5
memory: "4Gi"
コンピューティングクラスとDeploymentの適用後、作成されたPodを確認すると以下のようなTolerationsが付与されていることがわかりました。
Tolerations:
cloud.google.com/compute-class=dev-class:NoSchedule
node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Audit LogでPod作成時のログを確認したところ、以下のようなログが確認でき、Pod作成時にMutating Admission WebhookによりコンピューティングクラスについてのnodeSelectorに付与されているPodに対しTolerationを差し込んでいることが確認できます。
labels: {
authorization.k8s.io/decision: "allow"
authorization.k8s.io/reason: "RBAC: allowed by ClusterRoleBinding "system:controller:replicaset-controller" of ClusterRole "system:controller:replicaset-controller" to ServiceAccount "replicaset-controller/kube-system""
mutation.webhook.admission.k8s.io/round_0_index_3: "{"configuration":"pod-admission-controller.spiffe.gke.io","webhook":"pod-admission-controller.spiffe.gke.io","mutated":false}"
mutation.webhook.admission.k8s.io/round_0_index_4: "{"configuration":"pod-ready.config.common-webhooks.networking.gke.io","webhook":"pod-ready.common-webhooks.networking.gke.io","mutated":false}"
mutation.webhook.admission.k8s.io/round_0_index_5: "{"configuration":"warden-mutating.config.common-webhooks.networking.gke.io","webhook":"warden-mutating.common-webhooks.networking.gke.io","mutated":true}"
patch.webhook.admission.k8s.io/round_0_index_5: "{"configuration":"warden-mutating.config.common-webhooks.networking.gke.io","webhook":"warden-mutating.common-webhooks.networking.gke.io","patch":[{"op":"add","path":"/spec/tolerations/2","value":{"effect":"NoSchedule","key":"cloud.google.com/compute-class","operator":"Equal","value":"dev-class"}}],"patchType":"JSONPatch"}"
pod-security.kubernetes.io/enforce-policy: "privileged:latest"
}
設定を反映後、n2のノードプールがスケールしn2のノードにスケジューリングされることが確認できます。
kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\\t"}{.metadata.labels.cloud\\.google\\.com/gke-nodepool}{"\\n"}{end}'
gke-sreake-intern-tr-nap-e2-standard--2144910f-vx72 nap-e2-standard-2-1q3qzkie
gke-sreake-intern-tr-nap-n2-standard--1d566862-x4sd nap-n2-standard-4-o9jwdznr
gke-sreake-intern-tr-nap-n2-standard--bdf04567-kh8p nap-n2-standard-4-o9jwdznr
gke-sreake-intern-tr-nap-n2-standard--cd85824c-gvzs nap-n2-standard-4-o9jwdznr
gke-sreake-intern-tr-0a622caa-5c8k sreake-intern-tryu-np-n2
gke-sreake-intern-tr-0a622caa-bgk8 sreake-intern-tryu-np-n2
gke-sreake-intern-tr-0a622caa-lt8d sreake-intern-tryu-np-n2
gke-sreake-intern-tr-0a622caa-sfgw sreake-intern-tryu-np-n2
gke-sreake-intern-tr-e6ecfda5-v452 sreake-intern-tryu-np-n2d
スポットインスタンスの利用
CRDにも定義されていたように、カスタムリソースのpriorities配下にspotというオプションを付けることができます。
以下の例では、n2のスポットインスタンスの優先度を最も高く設定し、それが使用できない状況下ではn2dのスポットインスタンスを利用します。
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dev-class
spec:
priorities:
# n2を優先して利用
- machineFamily: n2
spot: true
- machineFamily: n2d
spot: true
nodePoolAutoCreation:
enabled: true
activeMigration:
optimizeRulePriority: true
このカスタムリソースを反映すると、元々n2やn2dのオンデマンドインスタンスにスケジューリングされていたPodはn2のSpotインスタンスに徐々にスケジューリングされていくことが確認できました。
kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-7ddf7cd9b6-cswpf 1/1 Running 0 4m59s 172.17.13.3 gke-sreake-intern-tr-nap-n2-standard--fc8a7fd5-ghvd <none> <none>
nginx-deployment-7ddf7cd9b6-dz6xv 1/1 Running 0 13m 172.17.1.3 gke-sreake-intern-tr-sreake-intern-tr-38d0ce74-mvfl <none> <none>
nginx-deployment-7ddf7cd9b6-jkqkz 1/1 Running 0 5m58s 172.17.12.3 gke-sreake-intern-tr-nap-n2-standard--fc8a7fd5-l6gm <none> <none>
nginx-deployment-7ddf7cd9b6-nng9x 1/1 Running 0 13m 172.17.9.2 gke-sreake-intern-tr-nap-n2-standard--fc8a7fd5-h4jj <none> <none>
nginx-deployment-7ddf7cd9b6-qsqxp 1/1 Running 0 7m19s 172.17.10.3 gke-sreake-intern-tr-nap-n2-standard--fc8a7fd5-nsqz <none> <none>
nginx-deployment-7ddf7cd9b6-sgp9p 1/1 Running 0 13m 172.17.9.3 gke-sreake-intern-tr-nap-n2-standard--fc8a7fd5-h4jj <none> <none>
nginx-deployment-7ddf7cd9b6-t84kr 1/1 Running 0 7m8s 172.17.10.4 gke-sreake-intern-tr-nap-n2-standard--fc8a7fd5-nsqz <none> <none>
nginx-deployment-7ddf7cd9b6-w5bm2 1/1 Running 0 7m19s 172.17.11.3 gke-sreake-intern-tr-nap-n2-standard--fc8a7fd5-hwgh <none> <none>
nginx-deployment-7ddf7cd9b6-wbqsl 1/1 Running 0 13m 172.17.5.3 gke-sreake-intern-tr-6cc96ed8-sswt <none> <none>
nginx-deployment-7ddf7cd9b6-zxj8j 1/1 Running 0 4m59s 172.17.13.4 gke-sreake-intern-tr-nap-n2-standard--fc8a7fd5-ghvd <none> <none>
kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\\t"}{.metadata.labels.cloud\\.google\\.com/gke-nodepool}{"\\n"}{end}'
gke-sreake-intern-tr-nap-e2-standard--0de5930d-vhc5 nap-e2-standard-2-1jo9csrw
gke-sreake-intern-tr-nap-n2-standard--fc8a7fd5-ghvd nap-n2-standard-4-spot-hxfkbndd
gke-sreake-intern-tr-nap-n2-standard--fc8a7fd5-h4jj nap-n2-standard-4-spot-hxfkbndd
gke-sreake-intern-tr-nap-n2-standard--fc8a7fd5-hwgh nap-n2-standard-4-spot-hxfkbndd
gke-sreake-intern-tr-nap-n2-standard--fc8a7fd5-l6gm nap-n2-standard-4-spot-hxfkbndd
gke-sreake-intern-tr-nap-n2-standard--fc8a7fd5-nsqz nap-n2-standard-4-spot-hxfkbndd
gke-sreake-intern-tr-38d0ce74-mvfl sreake-intern-tryu-np-n2
gke-sreake-intern-tr-6cc96ed8-sswt sreake-intern-tryu-np-n2d
フォールバック時の挙動
スポット枯渇等の理由で、最も優先度を高く設定したインスタンスが使用できない状態を再現してフォールバック時の挙動の動作確認を行ってみます。
状況を再現するために、nodePoolAutoCreation を無効にした上でspotインスタンスのノードプールを途中で削除するという方法を考え採用しました。こうすることで、スポットのノードプールを削除した後に新たなスポットノードプールが作成されなくなるため、スポットが中断された状態を再現することができます。
この状況で、以下のカスタムリソースを適用します。
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dev-class
spec:
priorities:
- machineFamily: n2
spot: true
- machineFamily: n2
spot: false
- machineFamily: n2d
spot: false
activeMigration:
optimizeRulePriority: true
優先順位は、n2のspot, n2のオンデマンド, n2dのオンデマンドであり、現在n2のspotインスタンスは利用できないようにしているのでn2のオンデマンドインスタンスが優先的に起動されるはずです。そして、実際にそのような状態になっていることが確認できます。
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-7ddf7cd9b6-55sr2 1/1 Running 0 13m 172.17.4.7 gke-sreake-intern-tr-24a75112-5wbh <none> <none>
nginx-deployment-7ddf7cd9b6-7zhn9 1/1 Running 0 9m34s 172.17.11.2 gke-sreake-intern-tr-24a75112-p78j <none> <none>
nginx-deployment-7ddf7cd9b6-9zctv 1/1 Running 0 6m34s 172.17.13.3 gke-sreake-intern-tr-24a75112-hhwb <none> <none>
nginx-deployment-7ddf7cd9b6-bgsxg 1/1 Running 0 9m34s 172.17.1.3 gke-sreake-intern-tr-24a75112-gkh8 <none> <none>
nginx-deployment-7ddf7cd9b6-bl74g 1/1 Running 0 6m34s 172.17.10.3 gke-sreake-intern-tr-24a75112-r6g8 <none> <none>
nginx-deployment-7ddf7cd9b6-bxctq 1/1 Running 0 6m23s 172.17.0.3 gke-sreake-intern-tr-24a75112-kr5r <none> <none>
nginx-deployment-7ddf7cd9b6-krb86 1/1 Running 0 10m 172.17.8.8 gke-sreake-intern-tr-24a75112-vsbv <none> <none>
nginx-deployment-7ddf7cd9b6-s5c8h 1/1 Running 0 9m34s 172.17.2.2 gke-sreake-intern-tr-24a75112-vj9c <none> <none>
nginx-deployment-7ddf7cd9b6-vld5k 1/1 Running 0 9m34s 172.17.5.3 gke-sreake-intern-tr-1e48c429-2x9q <none> <none>
nginx-deployment-7ddf7cd9b6-vzzrm 1/1 Running 0 9m34s 172.17.12.3 gke-sreake-intern-tr-24a75112-v57j <none> <none>
$ kubectl get nodes -o jsonpath='{range .items[*]}{.metadata.name}{"\\t"}{.metadata.labels.cloud\\.google\\.com/gke-nodepool}{"\\n"}{end}'
gke-sreake-intern-tr-nap-e2-standard--9a93a93c-5llw nap-e2-standard-2-1an6b1lg
gke-sreake-intern-tr-1e48c429-2x9q sreake-intern-tryu-np-n2d
gke-sreake-intern-tr-24a75112-5wbh sreake-intern-tryu-np-n2
gke-sreake-intern-tr-24a75112-gkh8 sreake-intern-tryu-np-n2
gke-sreake-intern-tr-24a75112-hhwb sreake-intern-tryu-np-n2
gke-sreake-intern-tr-24a75112-kr5r sreake-intern-tryu-np-n2
gke-sreake-intern-tr-24a75112-p78j sreake-intern-tryu-np-n2
gke-sreake-intern-tr-24a75112-r6g8 sreake-intern-tryu-np-n2
gke-sreake-intern-tr-24a75112-v57j sreake-intern-tryu-np-n2
gke-sreake-intern-tr-24a75112-vj9c sreake-intern-tryu-np-n2
gke-sreake-intern-tr-24a75112-vsbv sreake-intern-tryu-np-n2
また、whenUnsatisfiable フィールドには、カスタムリソースで定義したインスタンスが全て利用できない場合の挙動を定義することができます。
ScaleUpAnyway : クラスタのデフォルトのマシン構成(e2)を使用する新しいノードを作成します。つまり、通常のClusterAutoScalerの挙動を取ります。
以下のように、問題なく起動されることが確認できます。
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-7ddf7cd9b6-2m9fx 1/1 Running 0 7m17s
nginx-deployment-7ddf7cd9b6-5ztrf 1/1 Running 0 7m17s
nginx-deployment-7ddf7cd9b6-8mlgl 1/1 Running 0 7m17s
nginx-deployment-7ddf7cd9b6-b8xjq 1/1 Running 0 7m17s
nginx-deployment-7ddf7cd9b6-vqkkj 1/1 Running 0 7m17s
DoNotScaleUp : コンピューティング クラスの要件を満たすノードが使用可能になるまで、Pod を Pending ステータスにします。この設定を反映するとデフォルトのe2ノードにはスケジューリングされず、Pending状態のPodが増えるようになります。そして、再度利用可能な状態になった場合スケジューリングが行われます。
$ kubectl get pods -o wide -w
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-7ddf7cd9b6-2m9fx 0/1 Pending 0 2m18s <none> <none> <none> <none>
nginx-deployment-7ddf7cd9b6-8mlgl 1/1 Running 0 2m18s 172.17.5.7 gke-sreake-intern-tr-sreake-intern-tr-1e48c429-2x9q <none> <none>
nginx-deployment-7ddf7cd9b6-b8xjq 0/1 Pending 0 2m18s <none> <none> <none> <none>
nginx-deployment-7ddf7cd9b6-fw9gg 0/1 Pending 0 2m18s <none> <none> <none> <none>
nginx-deployment-7ddf7cd9b6-k6jtp 0/1 Pending 0 2m18s <none> <none> <none> <none>
Namespaceを指定したComputeClassの反映
コンピューティングクラスを利用するためにnodeSelectorを使用していましたが、ComputeClassの設定を反映したNameSpaceを指定することもできます。
例えば、test名前空間にComputeClassのラベルを付与する場合、以下のようになります。
kubectl label namespaces test cloud.google.com/default-compute-class=dev-class
PodやDeploymentをtest名前空間上で適用することでnodeSelectorを指定しなくともコンピューティングクラスを利用できるようになり、nodeSelectorを指定していた場合と全く同じように動作します。
使用率の低いNodeの削除
ComputeClassカスタムリソースの中でautoscalingPolicy フィールドにおいてCPUとメモリの使用率を監視し、使用率の低いとGKEが判断したNodeを削除することができます。
該当箇所のCRDを見てみます。
autoscalingPolicy フィールドの中にはconsolidationDelayMinutes を定義することができ、ノードがスケールダウンの対象となるまでに「未使用」と判断されている必要がある時間を決定します。最小設定可能時間は1分、最大は24時間(1440分)と書かれています。
そして、consolidationThresholdはノードがスケールダウンの対象と見なされるためのリソース使用率(CPUとメモリ)の閾値を決定します。
Autoscaling Policy:
Description: AutoscalingPolicy describes settings related to active reconciliation of
a given ComputeClass.
Properties:
Consolidation Delay Minutes:
Description: ConsolidationDelayMinutes determines how long a node should be unneeded before it is eligible for scale down.
Minimum duration is 1 minute, maximum is 24 hours or 1440 minutes
Maximum: 1440
Minimum: 1
Type: integer
Consolidation Threshold:
Description: ConsolidationThreshold determines resource utilization threshold below which a node can be considered for scale down.
Maximum: 100
Minimum: 0
Type: integer
Gpu Consolidation Threshold:
Description: GPUConsolidationThreshold determines GPU resource utilization threshold below which a node can be considered for scale down.
Utilization calculation only cares about GPU resource for accelerator node, CPU and memory utilization will be ignored.
Maximum: 100
Minimum: 0
Type: integer
Type: object
以下は、CPU とメモリの両方使用率のしきい値を90%に設定し、両方のリソース使用率がこのしきい値を下回ると、GKE はノードの削除を検討するというカスタムリソースです。この例だと2分経つと実際に削除されるノードが存在します。
apiVersion: cloud.google.com/v1
kind: ComputeClass
metadata:
name: dev-class
spec:
priorities:
# n2を優先して利用
- machineFamily: n2
spot: true
- machineFamily: n2d
spot: true
nodePoolAutoCreation:
enabled: true
autoscalingPolicy:
consolidationDelayMinutes: 2
consolidationThreshold: 90
適用前のNodeの数は以下の通り8つです
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
gke-sreake-intern-tr-nap-e2-standard--63851ab7-wcjh Ready <none> 176m v1.30.5-gke.1443001
gke-sreake-intern-tr-nap-n2-standard--2598ac39-g9ck Ready <none> 37s v1.30.5-gke.1443001
gke-sreake-intern-tr-nap-n2-standard--2598ac39-jcws Ready <none> 90m v1.30.5-gke.1443001
gke-sreake-intern-tr-nap-n2-standard--2598ac39-jpjm Ready <none> 43s v1.30.5-gke.1443001
gke-sreake-intern-tr-nap-n2-standard--2598ac39-srl6 Ready <none> 90m v1.30.5-gke.1443001
gke-sreake-intern-tr-nap-n2-standard--2598ac39-xqsf Ready <none> 90m v1.30.5-gke.1443001
gke-sreake-intern-tr-nap-n2-standard--2598ac39-z5q2 Ready <none> 39s v1.30.5-gke.1443001
gke-sreake-intern-tr-nap-n2-standard--2598ac39-zmrn Ready <none> 90m v1.30.5-gke.1443001
適用後、実際に30%程度のNodeが削除されていることが確認できます。カスタムリソースの適用のみを行い他のリクエストをしていない状態であるため、autoscalingPolicy によるものと考えることができます。
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
gke-sreake-intern-tr-nap-e2-standard--63851ab7-wcjh Ready <none> 3h10m v1.30.5-gke.1443001
gke-sreake-intern-tr-nap-n2-standard--2598ac39-jcws Ready <none> 103m v1.30.5-gke.1443001
gke-sreake-intern-tr-nap-n2-standard--2598ac39-srl6 Ready <none> 103m v1.30.5-gke.1443001
gke-sreake-intern-tr-nap-n2-standard--2598ac39-xqsf Ready <none> 103m v1.30.5-gke.1443001
gke-sreake-intern-tr-nap-n2-standard--2598ac39-zmrn Ready <none> 103m v1.30.5-gke.1443001
ただ、PDBを設定している場合、PDB違反になりうる場合はNodeの削除を行わないことを確認しているので、注意が必要です。
「ComputeClassのAutoscalingPolicyは満たしているがPDB違反しているためClusterAutoscalerがノードをスケールインできない」といった状態になるためです。
実際に確認したエラーログになります。PDBに違反しているためスケールインしてくれないとの記述があります。
resource.type="k8s_cluster"
resource.labels.location="asia-northeast1"
resource.labels.cluster_name="sreake-intern-tryu-gke"
logName="projects/ryu-project-441804/logs/container.googleapis.com%2Fcluster-autoscaler-visibility"
(jsonPayload.noDecisionStatus.noScaleDown.reason.messageId="no.scale.down.node.pod.not.enough.pdb" OR jsonPayload.noDecisionStatus.noScaleDown.nodes.reason.messageId="no.scale.down.node.pod.not.enough.pdb")
不正な値を設定した場合
カスタムリソースにおいて本来boolean型が入る部分にstr型を入れて反映すると当然エラーになります。Validating Admission Webhookでそのような検証を行うことができますが、ComputeClassではCRDのOpenAPI Schemaでバリデーションをかけていることがわかります。
The ComputeClass "dev-class" is invalid:
* spec.priorities[0].spot: Invalid value: "string": spec.priorities[0].spot in body must be of type boolean: "string"
* <nil>: Invalid value: "null": some validation rules were not checked because the object was invalid; correct the existing errors to complete validation
Karpenterとの比較
コンピューティングクラスと似たような機能を提供するノードのオートスケーラーとしてKarpenterが挙げられます。Karpenterとの比較を簡単に行ってみたいと思います。
OSSか否か
まず、KarpenterはOSSとなっており内部の実装を把握することができますがComputeClassは内部の実装を直接把握することはできず、挙動や一部の外から見える情報から推測するしかありません。ComputeClassはGKE上でのみ使用できますが、KarpenterはEKS上での使用が多いものの他のクラウドプロバイダー上でも動作します。
導入のしやすさ
コンピューティングクラスの場合、GKEでしか使用できないというデメリットはありますが、カスタムリソースを作成し適用するだけで使用することができます。また、カスタムルールを適用したい場合はPodに対しNodeSelectorを付与するだけで利用できるため、導入が非常に容易です。
Karpenterを利用する場合、事前にhelmを用いてKarpenterをクラスタにインストールする必要があり[6]、コンピューティングクラスと比較すると使用するのに一つ多くの手間がかかります。とは言っても、ドキュメントが詳細に書かれているのでこちらに沿って導入していけば問題無いかと思われます。
Node中断によるコスト最適化
コンピューティングクラスでは、リソースの使用率に関する閾値と時間を指定することで削除するNodeの候補を定義できることを紹介しました。これにより、利用率の低いNodeを削除することができます。Karpenterは、同様、さらにはそれ以上の仕組みを提供します。
Karpenterの主要な機能の一つとして、Consolidationが挙げられます。[7] 使用率の低いNodeを削除するだけはなく、よりコスト効率の良いNodeに置き換えることができるという仕組みです。具体的には、Node内にある全てのPodが、クラスタ内の他のNodeの空き容量と、より低価格の代替Node1台の中でスケジューリングできる場合、そのNodeを置き換えることができるというものです。他のNodeの空き容量のみを使用してスケジューリング可能な場合には既存のNodeを削除し再スケジューリングを行うことでコスト削減を実現します。
組織に合わせた柔軟性
コンピューティングクラスは、インスタンスの優先度を明示的に定義できるという点がKarpenterとは大きく異なります。
Karpenterを用いることで、カスタムリソースにおいてかなり柔軟に、使用したいインスタンスタイプなどの要件を定義することができます。そして、Karpenterは内部のコスト計算アルゴリズムによりコストを最も抑えるようにノードのプロビジョニングやノードの削除・置換を行います。そのため、Karpenterを用いると最低限の条件のみ定義した後は自動的に最適なインスタンス構成を構築してくれるため、運用の手間を大幅に削減できるという利点があります。しかし、例えばReserved Instancesを購入しているなど、場合によっては組織によってKarpenterのコスト計算アルゴリズムが最もコストを抑えられる状況とは限らない場合があります。コンピューティングクラスでは利用したいインスタンスの順位を明示的に定義できるので、組織ごとに利用したいインスタンスに明確な優先順位がある場合は導入するメリットがありそうです。
このような点で、優先度を明示的に設定できるコンピューティングクラスはKarpenterにはない特長を持っており、特定の状況下ではコンピューティングクラスの方が適している場合も考えられます。
まとめ
本ブログでは、GKEのカスタムコンピューティングクラスについての検証と、簡単にKarpenterとの比較を行ってみました。GKEを使用している場合は導入することを考えてみても良いかもしれません。また、使用時には公式ドキュメントだけでなくCRDを併せて確認するのが良さそうです。
参考
[1] カスタムコンピューティングクラスについてhttps://cloud.google.com/kubernetes-engine/docs/concepts/about-custom-compute-classes?hl=ja
[2] GKE Standard ノードプールとコンピューティング クラス [3] ワークロードでコンピューティングクラスをリクエストする [4] Standard モードでコンピューティングクラスを構成する [5] ノードの自動プロビジョニングとコンピューティングクラス [6] Getting Started with Karpenterhttps://karpenter.sh/docs/getting-started/getting-started-with-karpenter/
[7] Karpenter Disruptionhttps://karpenter.sh/docs/concepts/disruption/

SreakeではSREや関連する情報を発信していきます。