
- RAG(Retrieval Augmented Generation)は、LLM(Large Language Model:大規模言語モデル)が知らない情報を外部から与えてあげることで、LLMの知識を拡張する手法です。RAGを用いることで、LLMはより多くの情報に基づいた回答を生成できるようになります。しかし、「コンテキストが長ければ長いほどRAGの精度は向上する」というのは本当でしょうか?
- 本稿で紹介する論文『Long-Context LLMs Meet RAG: Overcoming Challenges for Long Inputs in RAG』は、この通説を覆し、コンテキスト長の増大時に発生する問題と、それを解決するためのRAGの改善策を提案しています。この記事では、RAGの性能を最大化するための重要な発見と、具体的な改善策を解説します。
論文情報
- 著者
- Bowen Jin (1 2 *), Jinsung Yoon (1), Jiawei Han (2) and Sercan Ö. Arık (1)
- Google Cloud AI Research, 2) University of Illinois at Urbana-Champaign
- Bowen Jin (1 2 *), Jinsung Yoon (1), Jiawei Han (2) and Sercan Ö. Arık (1)
- タイトル
- Long-Context LLMs Meet RAG: Overcoming Challenges for Long Inputs in RAG
- 発表年月日
- 2024年10月8日
- URL
前提知識
- 論文のご紹介に入る前に、前提知識のご説明をします。
RAG (Retrieval Augmented Generation)
- RAGとは、GeminiなどLLM (Large Language Model:大規模言語モデル) が知らない情報を外付けして、それらの情報に関する質問にも答えさせられるようにする手法です。
- ユーザーはLLMに対して、質問をして回答を得ますが、LLMの知らない情報を格納して、そこから検索した情報をコンテキストとしてプロンプトに含めます。
- そうすることで、LLMが知らない情報にも回答できるようになるのです。
- 情報を格納した箇所をRetriever、LLMをGeneratorと呼びます
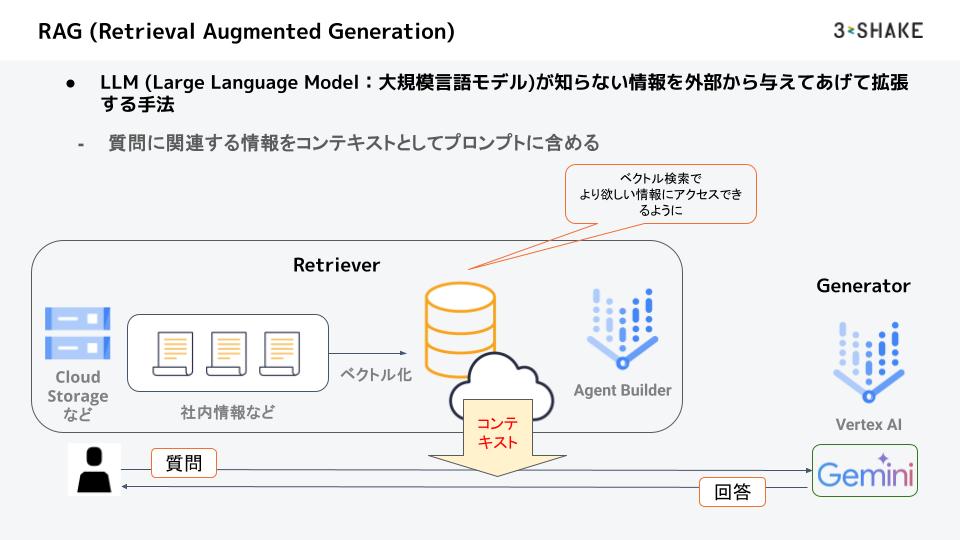
図1 Google Cloudで構築したRAG (Retrieval Augmented Generation)の例
ハードネガティブ
- LLMが誤って正例と判断しやすい負例のことです。
- 正例と非常に似ていて紛らわしいデータです
- 以下のような例があります
例1:感情分析
- 正例:「この映画は最高だった!」
- ハードネガティブ:「この映画は最高だったけど、結末が少し残念だった。」
- このハードネガティブは、全体的には肯定的な意見ですが、否定的な要素も含まれており、モデルが誤ってポジティブと判断してしまう可能性があります。
例2:質問応答
- 質問: 「東京のタワーは何?」
- 正解: 「東京タワーです。」
- ハードネガティブ: 「東京の塔はスカイツリーもあります。」 このハードネガティブは、質問に対する答えとは異なる情報を含んでいますが、質問と文脈的に関連しており、モデルが誤って正解と判断してしまう可能性があります。
例3:スパムメール分類
- スパム: 「【緊急】あなたのアカウントが停止されます。今すぐこちらをクリック!」
- ハードネガティブ: 「【お知らせ】お客様のアカウントのセキュリティ強化のため、パスワードの変更をお願いいたします。」
- このハードネガティブは、スパムメールと似たような文言やフォーマットを使用しており、モデルが誤ってスパムと判断してしまう可能性があります。
ハードネガティブを用いる理由
- モデルの性能向上: ハードネガティブを学習データに含めることで、モデルはより複雑なパターンを学習し、正例と負例をより正確に区別できるようになります。
- 過学習の防止: ハードネガティブを適切に扱うことで、モデルが特定のデータに過度に適合してしまう(過学習)のを防ぐことができます。
汎化
- 汎化は簡単に言うと、「未知のデータに対しても正しく予測や判断ができる能力」です。
- 例えば、学習データで「猫はかわいい」と学習したモデルが、「犬はかわいい」という新しい文に対しても、「かわいい」という感情を正しく理解可能になります。
- 学習データで「東京」という地名に関する情報を学習したモデルが、「大阪」という新しい地名に関しても、場所に関する情報を推測可能です。
- このような能力を generalization (汎化)といます。
汎化が重要な理由
- 現実世界は多様で、学習データに含まれる情報だけではカバーしきれないためです。
- モデルが現実世界の様々な状況に対応できるよう、汎化能力は不可欠となります。
論文の概要
- 論文の中身に入る前に、より中身をご理解いただけるよう、まず初めに論文の全体像をご説明します。
課題
- コンテキストが長くなればなるほど、RAGの性能が上昇し続けると思いきや、劣化することを観察しました。
原因
- ハードネガティブが主要な原因の一つです。コンテキストが長くなればなるほど、ハードネガティブの量も多くなり、性能劣化を招きます。
- なお、これまでの研究では紛らわしくない間違いであるランダムネガティブしか想定していませんでした。
解決法
- コンテキストで最初と最後に関連スコアの高い文書を配置する並び替えを実施します。
・訓練不要で簡単な方法になります。 - 暗黙的なファインチューニングを実施します。
- 中間推論を用いたファインチューニングを実施します。
論文の内容
- 論文の概要をご紹介したところで、論文の中身を各章ごとにまとめてご紹介します。
要旨
- RAG(Retrieval Augmented Generation)の重要性は、LLM(大規模言語モデル)が持ち合わせていない情報に対しても回答できるようになる点にあります。外部知識を活用することで、知識集約型のタスクにおいてLLMの精度向上が期待され、事実誤認やハルシネーションといった課題の軽減にも貢献します。
- 本研究のモチベーションは、LLMのコンテキスト長が拡大の一途を辿る中で、RAGシステムをどのように最適に設計するかが依然として明確になっていないという点にあります。長いコンテキストを持つLLMをその能力を最大限に引き出して効果的に使用するためには、従来の標準的なRAG設計を改めて評価し直す必要があると考えています。
- このような背景を踏まえ、本研究の目的は、長いコンテキストを持つLLMをRAGシステムで活用する際に生じる特有の課題を明らかにすることです。そして、これらの課題に対処し、より効果的なRAGシステムを構築するための新しいアプローチを提案することを目指します。
はじめに
- 背景として、Retrieval Augmented Generation (RAG) は、外部知識を活用することで大規模言語モデル(LLM)の性能を向上させる重要な技術です。近年、Retrieverが登場し、これまで以上に多くの情報を処理できる可能性が示唆されています。しかし、研究を進める中で、直感的な期待とは裏腹に、より多くの情報を取得したとしても必ずしもRAGの性能が向上するとは限らないという現状が明らかになりました。そこで、本研究では、RetrieverにおけるRAGの最適設計に関する未解明な課題を解決することを動機とし、Retrieverを用いたRAGにおける課題を体系的に分析し、その上で効果的な解決策を提案し、実証することを目的とします。
関連研究
- 既存のRetrieval Augmented Generation(RAG)システムにおけるRetriever(検索器)とGenerator(生成器)の独立した改善については、これまで研究が進められてきました。しかしながら、ハードネガティブ(正解と類似度が高い不正解データ)に関する研究は、現状では十分とは言えません。また、長コンテキストLLMに関する研究やそのベンチマークにおいては、現実のRAGシナリオを十分に反映できていないという問題点が指摘されています。特に、RAGのマルチドキュメント設定においては、唯一の完全に正しい情報を含むドキュメントが存在すると見なされることが多く、正解ではないドキュメント(ネガティブドキュメント)として、関連性の低いドキュメントがランダムに選択される傾向にあります。このような背景を踏まえ、本研究では、RAGにおける長コンテキストLLMの利点と最適化に焦点を当て、長いコンテキストを活用したRAGの最適化に関する既存の研究におけるギャップを埋めることを目指します。
長いコンテキストLLMにおけるRAGの課題
- 3章ではRAGにおける問題の説明をしています。
1. コンテキストサイズの影響
- 長いコンテキストが常にパフォーマンスの向上に寄与するとは限りません。実際、検索する文章数を過度に増やすと、ある時点を境に性能が低下する現象が見られます。これは、検索された文章数とパフォーマンスの関係が逆U字型のパターンを示すことを意味します。特に強力なRetrieverを用いた場合、このパフォーマンスの低下はより顕著になることが観測されています。
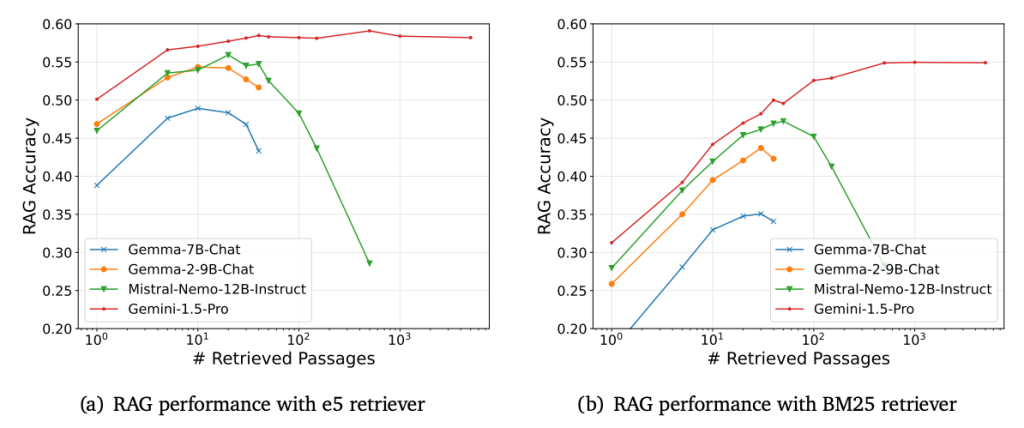
- 左のe5が強いRetriever、右のBM25が弱いRetrieverです。
- Retrieverから検索した文章数が多ければ多いほど、Gemini-1.5-Pro以外のモデルで性能劣化が発生しています。
2. Retrieval品質とLLM能力の相互作用:
- Figure 2は、検索された文章数とRAGの精度との関係を示しています。一般的に、検索された文章数が多ければ多いほど、Recall(関連文書の網羅率)は向上しますが、Precision(関連文書の精度)は低下します。図2(a)の強力なRetriever(e5)を用いた場合、検索された文章数が増えるにつれて、RAGの精度が低下する「逆U字型」のパターンが顕著に現れています。つまり、検索する文章数を増やしすぎると、ある時点から逆に性能が低下してしまうのです。これは、弱いRetriever(BM25)を用いた図2(b)の場合と比較すると、より顕著です。
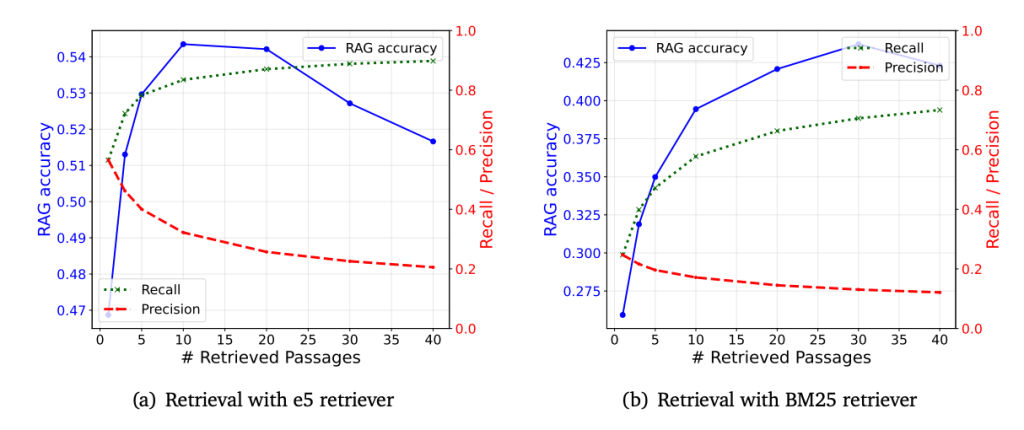
- 3.1と同じく、左のe5が強いRetriever、右のBM25が弱いRetrieverです。
3. ハードネガティブの重要性
- ハードネガティブとは、その関連性の低さから大規模言語モデル(LLM)を混乱させる可能性のある文書を指します。特に、長いコンテキストを用いたRAGにおいては、ハードネガティブが性能に悪影響を及ぼすことが知られています。しかしながら、現状のベンチマーク評価では、このようなハードネガティブの影響を十分に捉えられていないという課題があります。また、Retrieverの強度(検索能力)は、このハードネガティブの難易度に影響を与えると考えられます。一方、ランダムネガティブは、正の例(正しい答えや関連性の高いデータ)に対して無作為に選択された負の例(間違った答えや関連性の低いデータ)を意味しますが、これは現実世界のRAGの状況を必ずしも反映しているとは言えません。
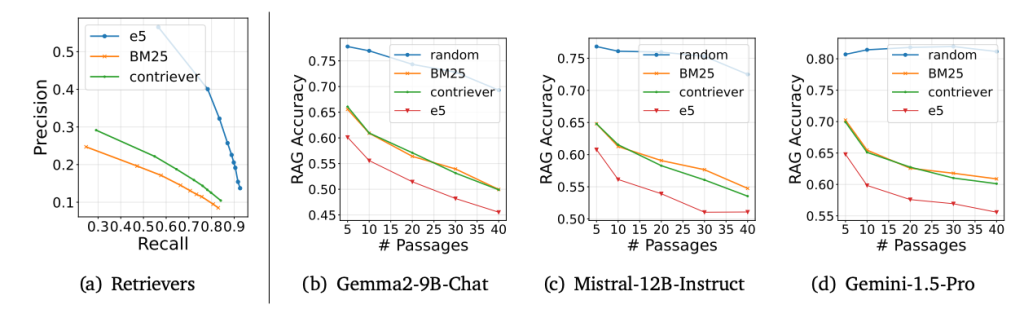
- Recall(関連文書の網羅率)が向上するにつれ、Precision(関連文書の精度)は低下します。
- Retrieverから検索した文章数が多くなるにつれ、RAGの精度は低下します。
シンプルで効果的な訓練不要のRAG改善
- 本章では、前章で説明した問題に対する解決策の1つとして、Retrieval Reordering(検索結果並び替え)という手法を解説します。
- Retrieval Reorderingは、長コンテキストLLMにおける「Lost-in-the-middle」現象を利用します。Lost-in-the-middleとは、LLMが入力テキストの最初と最後の部分に現れる情報を重要と判断し、真ん中の部分の情報を十分に活用できない現象のことです。例えば、長い文章の要約をLLMに依頼した場合、LLMは文章の最初と最後の情報は比較的正確に捉えるものの、真ん中の部分の情報を見落としがちになる、といった現象が起こります。
- Retrieval Reorderingでは、Retrieverから検索された文章のうち、関連スコアの高いドキュメントを最初と最後に配置します。これにより、LLMが重要な情報を認識しやすくなり、ハードネガティブの影響を軽減し、RAGの精度向上に貢献します。
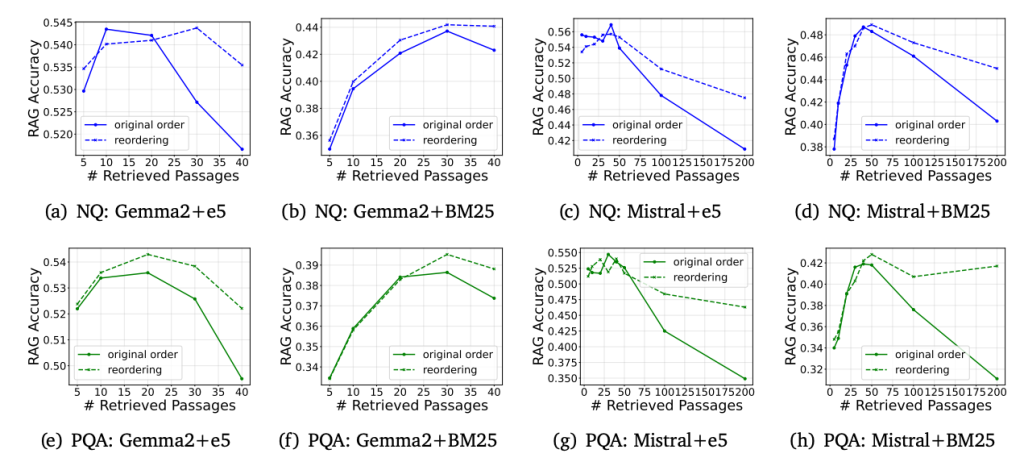
- Retrieval Reordering(点線)の方が、検索結果並び替えをしない元の方法(original order:実線)よりも性能が高くなっています。
データ拡張型ファインチューニングによるロバスト性の向上
- 5章では、問題をファインチューニングで解決する方法を解説しています。
1. ファインチューニングによるLLMのロバスト性の暗黙的な向上
- ファインチューニングは、ハードネガティブに対する大規模言語モデル(LLM)のロバスト性を暗黙的に向上させます。ここでいうロバスト性とは、ノイズや外乱に強い性質を指します。本研究では、特にRetrieval Augmented Generation(RAG)に特化したデータを用いてLLMをファインチューニング(追加学習)しました。この際、複数のRetrievalコンテキストをモデルに提示することで、ノイズの多い状況下でも関連情報を識別する能力を高めることを試みました。実験の結果、他のファインチューニング手法と比較して、RAGファインチューニングが最も高い性能を示すことが明らかになりました。さらに、RAGファインチューニングの性能曲線はより平坦であり、これはハードネガティブに対してもその性能が比較的安定している、つまり強いことを示唆しています。加えて、RAGファインチューニングはモデルの知識抽出能力の向上にも寄与することが確認されました。なお、ここで言及している暗黙的なファインチューニングとは、明示的に教え込むのではなく、学習プロセスを通じてモデルが自然に獲得する知識や能力のことです。RAGにおいては、モデルが大量のデータとRAGによる情報検索を通じて、暗黙的に知識を獲得し、より自然な文章生成を実現していると考えられます。
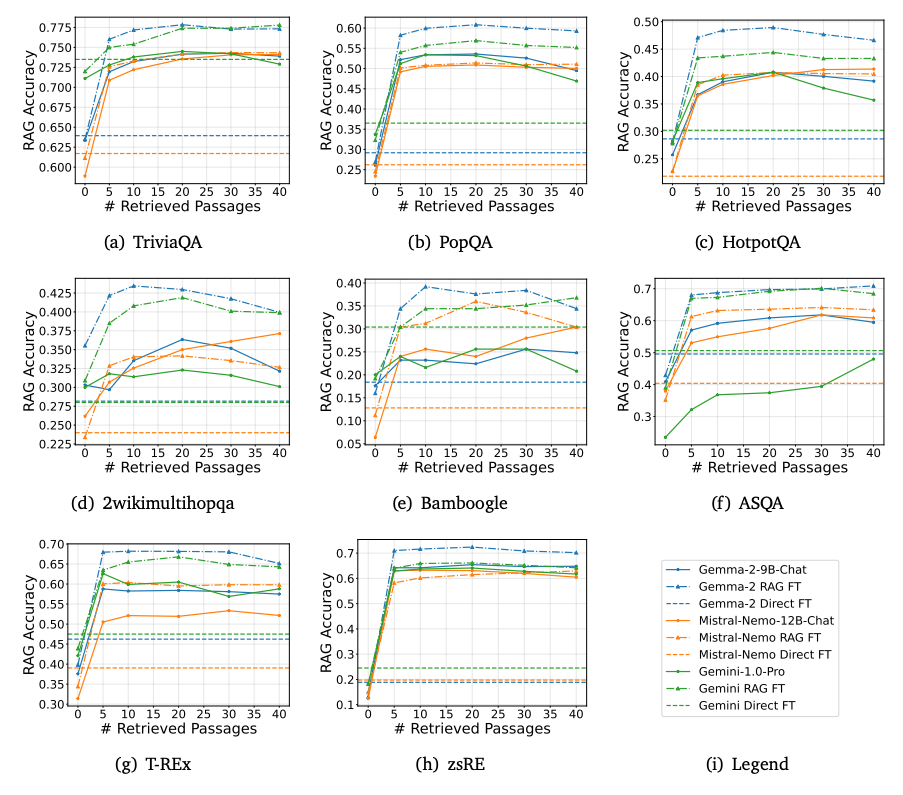
論文中の P.9 Figure 5
- 様々なファインチューニング手法で、3種のどのモデルにおいても、ファインチューニングなし、直接的なファインチューニング、RAGファインチューニングの順で性能が高くなっています。
- また、Retrieverでの検索文章数が多くなっても、性能劣化がなだらかになります。
2. 推論拡張による関連性識別の強化:
- 大規模言語モデル(LLM)において、中間推論ステップを加えることで、関連文書の識別精度を向上させることが可能です。この考えに基づき、まず推論ステップを生成させるという構造化されたアプローチを導入し、その後に適切な関連文書を特定する手法を試みました。実験の結果、中間推論を取り入れたRAGのファインチューニングは、中間推論を用いない暗黙的なRAGファインチューニングよりも高い性能を示すことが明らかになりました。この結果は、明示的な関連性トレーニングが、無関係な情報(ノイズ)の中から重要な情報をLLMが識別する能力を高めることを示唆しています。さらに、構造化された推論プロセスは、LLMの文書内容の理解を深め、ひいてはタスク全体のパフォーマンス向上に貢献すると考えられます。
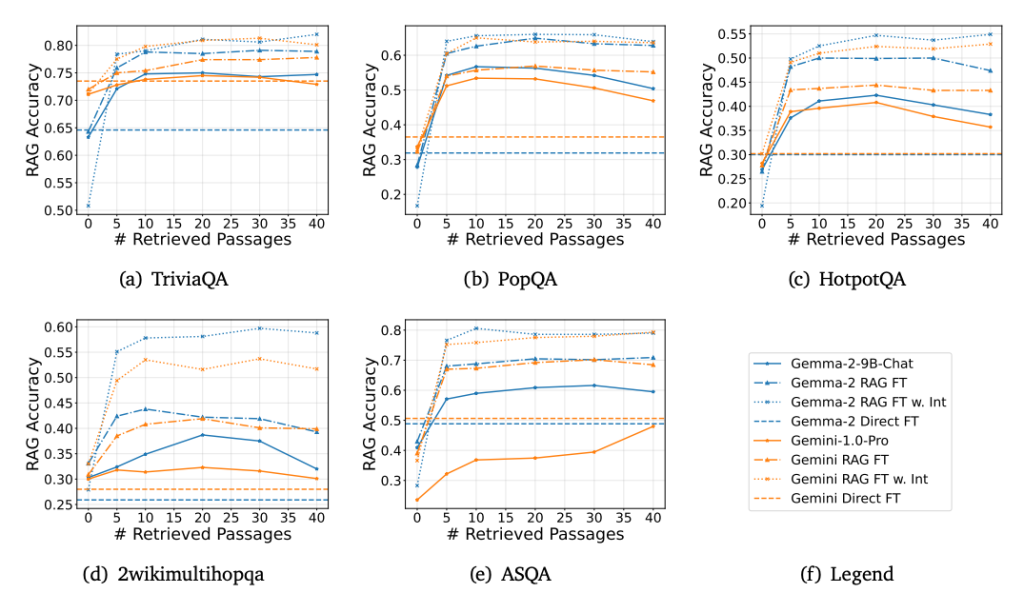
- 様々なファインチューニング手法で、2種どちらのモデルにおいても、推論ありのどちらのファインチューニングでもRAGの性能が高くなっています。
ファインチューニングにおけるデータの影響
- データ分布はモデルの汎化能力に大きな影響を与えます。具体的には、多様なトレーニングデータを用いることで、モデルはより幅広い入力に対応できるようになり、結果として汎化能力が向上します。
- また、Retrieverの選択も重要です。異なるRetrieverから得られたデータを用いてファインチューニングを行うと、未知のRetrieverに対するモデルの汎化性能を高めることができます。一方で、特定のRetrieverで訓練されたモデルは、類似した特性を持つRetrieverに対してより高い汎化能力を示す傾向があります。さらに、「ハードネガティブ」と呼ばれる、正例と紛らわしい負例の特徴は、Retrieverの種類によって異なることが知られています。
- 訓練コンテキスト長の影響も見逃せません。最大コンテキスト長でファインチューニングを行うことで、モデルはさまざまなRetrievalサイズにおいて最適なパフォーマンスを発揮できるようになります。これにより、LLM(大規模言語モデル)は、少量から大量の情報まで、その量に応じて効果的に処理することが可能になります。
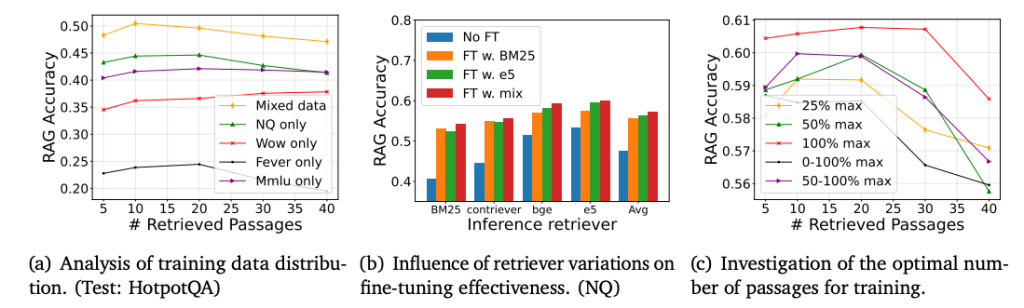
- (a)では、トレーニングデータを混合した方がRAG精度が高いことを示しています。
- (b)では、複数のモデルでファインチューニングした方がRAG精度が高いことを示しています。
- (C)では、最大コンテキスト長でファインチューニングした場合が最もRAG精度が高くなっています。
結論
- 本研究では、Retrieverにおいて、検索結果の増加が必ずしも性能向上に繋がらないことを実証しました。その原因として、「ハードネガティブ」が性能低下の主要因であることを特定し、検索結果の並び替え、暗黙的/明示的なファインチューニングという3つの提案手法の有効性を示しました。
- 今後の展望としては、より高度な検索結果並び替え手法の探求や、より詳細で多段階な推論連鎖を用いたLLMのファインチューニングの効果の実証が挙げられます。
- 本研究は、Retrieverを用いたRAGシステム設計の新たな視点を提供し、よりロバストで高性能なRAGシステムの実現に貢献するものです。
最後に
- スリーシェイクでは、Google Cloudを用いた生成AIアプリケーション開発を得意としています。
- 実証実験のサポートもお任せください。
- 以下のページからお気軽にお問い合わせください。