[KubeCon Japan 2025] Composable Disaggregated Infrastructure(CDI)とは? Kubernetes基盤レイヤーでのHWリソース動的管理

2025年度の新卒エンジニアとして株式会社3-shakeに入社いたしました、荒木と申します。私はまだまだKubernetesの初学者であり、日々の学習を通じてスキルを向上させていきたいと考えています。
そんな折、先日、KubeCon Japan 2025に参加しました。今回はそこで学んだ知見の一部を事後の調査とともに共有いたします。

概要
Composable Disaggregated Infrastructure (CDI)というOSSに関するセッションがありました。この話は、Kubernetesユーザーがリソースを効率的に利用するための手段というよりも、オンプレミス環境でKubernetesを運用する際のハードウェアリソースを効率的に活用する新しい手法についての内容でした。
将来的には、KubernetesクラスタとGPUリソースを提供するクラウドプロバイダーが、このような技術を活用してリソース最適化を裏側で行うようになるかもしれません。
なお、今回のセッションでは、CDI内部のPCIe接続の具体的な構成方法や、CDI Controller自体の実装詳細についてはあまり深く議論されていません。
Composable Disaggregated Infrastructure (CDI)
大規模言語モデルをKubernetes上で運用するというユースケースにおいて、効果的な学習の回し方や、LLMアプリケーションに特化したアーキテクチャや関連コンポーネント、コントローラなどに関しての話が、KubeCon全体でホットな話題だった印象です。また、Kubernetes 1.33でDynamic Resource Allocation (DRA) が一般公開されたこともあり、今後ますます、Kubernetes上でのGPUの効率的な利用が進むことが期待されます。
そんな中、本セッションで説明されたComposable Disaggregated Infrastructure (CDI)はKubernetesより一段階下のレイヤーでGPUなどのリソースの動的な割り当ての管理を可能にします。
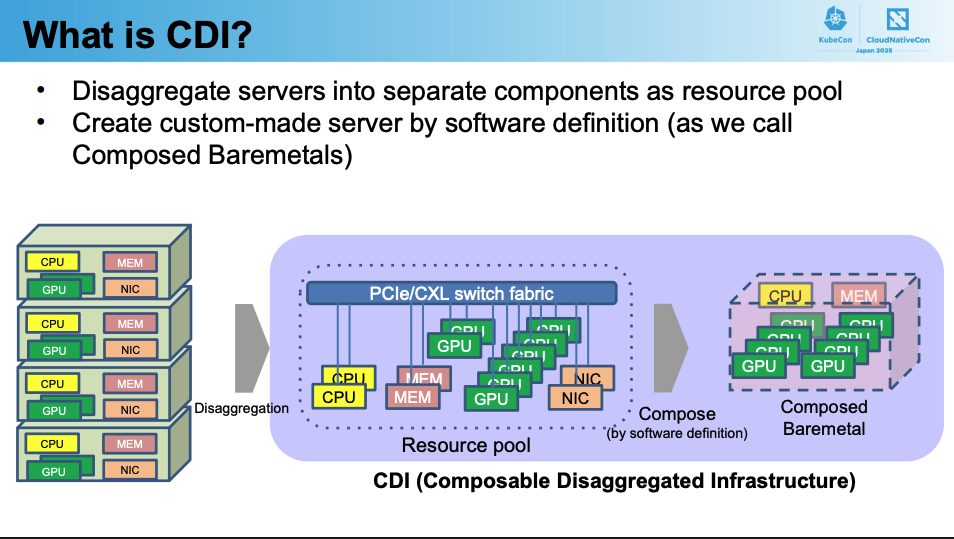
CDIアーキテクチャはPCIe/CXLで接続されたGPU、CPU、メモリなどをリソースプール(ハードウェアボックス)の中に、用意しておき、CDIのコントローラやAPI経由でのリクエストに応じてベアメタルPCとして再構築できるようにするというものです。現時点ではCNCFのプロジェクトではなく、その日本コミュニティであるCNCJ(Cloud Native Community Japan)のプロジェクトとして進められています。
この技術における一番の恩恵はGPUの動的割り当てによる、エネルギー消費とリソース消費の最適化です。ワークロードに応じて動的にサーバーをスケールアップ、スケールダウンすることができます。
CDIのKubernetes上で想定されるユースケース
KubernetesのDRA(Dynamic Resource Allocation)と組み合わせて使用するユースケースが提案されていました。一部コントローラーは開発途上だったり、機能不足なものもあるそうですが、その概要と実現しようとしていることに関してお伝えします。
DRAは、Kubernetesのノードに対して、GPUなどのリソースを動的に割り当てることを可能にする機能です。ResourceSliceに登録された利用可能なデバイスリスト(GPUデバイス等のリスト) から、リソース要求(ResourceClaim)に応じて、Kubernetesのノードに割り当てます。
KubernetesのコントロールプレーンにCDI のカスタムコントローラーを作成することにより、CDIのリソースプールからクラスタ内へのGPUの割り当てがより一層効率化されます。
もっと具体的に言うと、DRAにおけるデバイスプールである、ResourceSlice自体を動的にCDIで拡張し、CDI経由で割り当て可能なデバイスの情報をKubernetes側から認識し、割り当てまでを行えるようになります。
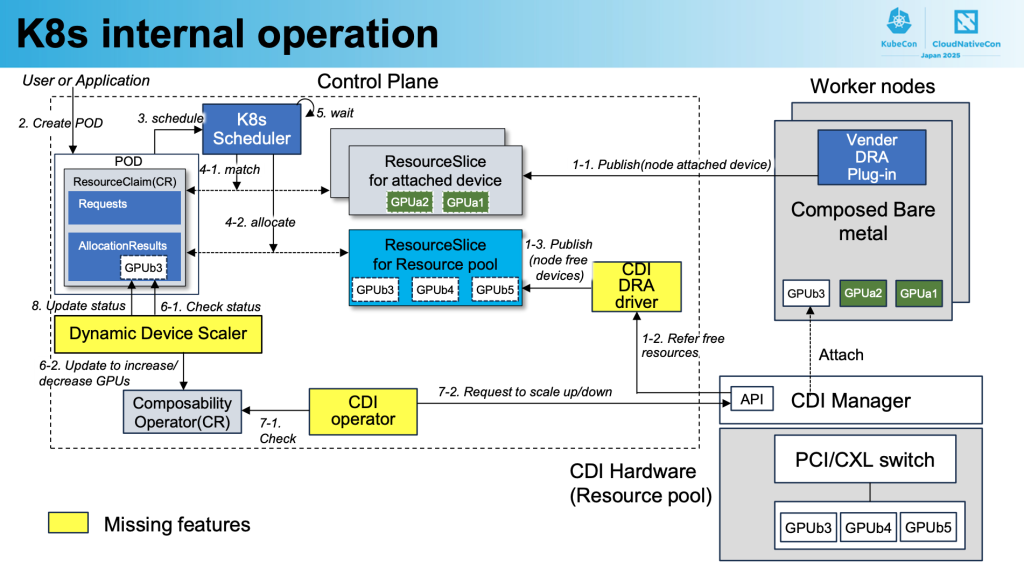
- 図中にあるCDI DRAドライバはCDIのハードウェアボックスに存在するデバイスの情報をResourceSlice(図中: ResourceSlice for Resource pool)としてKubernetesに登録する。
2, 3. ResourceClaim(リソース要求)が作成される。
- ResourceSliceに基づき、ResourceClaimを満足させるデバイスを割り当てようとする。
- もし、ResourceSlice for attached devideに割り当て可能なデバイスがあるならばそれを使用する。(通常のDRAでのデバイス割り当て) ⇒ 割り当て完了
- ResourceSlice for Resource poolに割り当て可能なデバイスがあるならば、デバイスをバインド。準備完了するまで待機 ⇒ 次ステップへ
- CDI operatorがその状態を認識してCDI Managerに割り当てを指示 ⇒ ノードにデバイスがアタッチされる。
- Dynamic Device Scalerがデバイスが接続されていることを認識しスケジューラに通知 ⇒ 4.bステップの待機が終了し、割り当てが完了する。
このCDI DRAによる動的デバイス割り当てプロセスにより、Kubernetesクラスター内でハードウェアリソースを効率的かつ柔軟に管理することが可能になります。まだ機能不足なコンポーネントはあれど、デバイスの物理的な接続状態に関わらず、アプリケーションの要求に応じてリソースを動的に提供する革新的なアプローチです。これにより、クラウドネイティブ環境における特殊ハードウェアの活用がより実用的になることが期待されます。
CDIを活用したAI映像解析システム
実際にCDIを活用した事例として、IOWN Global Forumと大阪万博での事例が取り上げられていました。両方ともオンプレミスインフラの事例です。
IOWN Global Forumでの事例
フォーラム中の混雑検知や、プライバシーマスキング(監視カメラ映像から来場者の顔をマスキングする)などのワークロードに伴い、これらのアプリケーションの要求に応じてCDI Controllerがノードを作成し、リソースの消費を最適化していました。
前項で述べたような、Kubernetes自体がCDIのリソースプールを認識し、能動的にCDI Controllerを制御する方式ではなく、CDI ControllerがKubernetesのノードを作成し、Kubernetesのスケジューラがそれらのノードを認識しているという形です。
セッション中に示された図では、このアーキテクチャの全体像が説明されており、カメラからの映像入力、その映像を実際に処理するKubernetesワーカーノード群、そして、出力としての混雑検知やプライバシーマスキングといったAI処理結果という流れが示されていました。ワーカーノードはCDI Controllerによって動的に構成されます。ワークロードの需要に応じてCDI Controllerが必要なGPUリソースを含むノードを動的に作成・削除し、エネルギー効率を最適化している実際のユースケースとしての紹介でした。
なお、CDIは、NTTが提唱するData-centric Infrastructure (DCI)という概念の実装技術の一つとして位置付けられているそうです。
大阪万博2025での事例
このイベント事例でも、ワーカーノードはCDIによって動的に再構築され、データ分析パイプラインを構成しています。カメラからの映像を処理するAI分析パイプラインを構築しているのですが、各ノードはRDMA(Remote Direct Memory Access)を用いた、高速な処理を実現しています。
CDIはGPUのみならず、NICやメモリも要求に応じて再構築することができるため、この事例では処理要件に応じて最適化されたハードウェア構成が動的に提供されていました。
セッション中に示された図では、映像データの流れとCDIによるリソース割り当ての仕組みが詳細に説明されており、カメラからの映像入力が高速ネットワーク経由でGPUを搭載したワーカーノードに直接転送され、リアルタイム分析が行われる構成が示されていました。特に注目すべき点は、RDMAを活用することで、従来のCPU経由のデータ転送よりも大幅に高速化されている部分でした。
RDMAは情報通信技術の一つで、情報を直接ターゲットのコンピュータのメモリに書き込む技術です。CPUを介さずに送信先がデータを受け取るので非常に高速にデータを送受信できます。この技術により、遅延を最小限に抑えながら、映像データを直接GPUのメモリに送り、リアルタイムでのAI分析処理が可能になっています。
まとめ
CDIは、サーバーの物理コンポーネントを、Kubernetesなどのプラットフォームを問わず、様々なワークロードへ動的に提供するインフラ技術です。
先日のセッションでは、このCDIに関する質疑応答がありました。その中で、「CDIのリソースプールと、それを利用するKubernetesクラスタは、物理的にどのくらい離れていても大丈夫か」という質問が上がりました。この質問に対して、「CDIのパフォーマンスはPCIeの性能に依存するため、将来、通信規格がさらに高速化すれば、遠く離れたリソースプールも利用できるようになる可能性がある」という趣旨の回答がありました。
CDIの関連コントローラが今以上に整備されることによって、より柔軟性の高いインフラストラクチャの構築が可能になるかもしれません。
KubeCon 2025に参加して
ここで紹介した技術はどちらかというと、ユーザーが扱うものというよりは、Kubernetesクラスタを運用するインフラエンジニアや、大規模なオンプレミス環境を管理するプラットフォームエンジニアが主に関わる技術であると感じました。
日常的にKubernetesを使ってアプリケーションを開発・デプロイしている開発者にとっては、CDIは透明性のある下位レイヤーの技術として機能することになるでしょう。つまり、開発者は従来通りにResourceClaimでGPUリソースを要求するだけで、背後でCDIが動的にハードウェアを再構築し、最適なリソース配分を実現してくれるという仕組みです。
今回KubeCon Japan 2025に参加して、Kubernetesエコシステムの幅広さと深さを改めて実感しました。アプリケーション開発に直接関わる技術から、今回のCDIのようなインフラストラクチャの根幹を支える技術まで、様々なレイヤーで革新が続いていることを知ることができました。
特に印象的だったのは、AIワークロードの増加に伴い、GPU等のリソース管理がKubernetesコミュニティにとって重要な課題となっていることです。

セッション会場の外ではスポンサー企業のブースが並び、最新の技術や製品が紹介されていました。非常に多くの人がKubeConに参加しており、コミュニティの活気を感じることができました。
最新技術動向を学ぶことで、価値のあるエンジニアになれるよう、継続的な学習を心がけていきたいと思います!
参考
- KubeCon Japan 2025 CDI セッション概要:
https://kccncjpn2025.sched.com/event/252xe/cdi-composable-disaggregated-infrastructure-bof-unlocking-disaggregated-computing-for-cloud-native-applications - KubeCon Japan 2025 CDI セッション資料:
https://static.sched.com/hosted_files/kccncjpn2025/97/KubeCon Japan 2025 CDI BOF.pdf - dynamic-device-scaler:
https://github.com/InfraDDS/dynamic-device-scaler/tree/main - Data-centric Infrastructure for Supporting Data Processing in the IOWN Era and Its Proof of Concept:
https://www.rd.ntt/e/research/JN202311_23718.html - RDMAとは ~高速化技術とクラウド 第7回~:
https://www.ntt-tx.co.jp/column/240717/