
Kueue
KueueはKubernetesのSIG-Schedulingのサブプロジェクトとして開発が進められている、クラスター内のバッチ・HPC・AI/MLといったジョブのキューイングを提供するAPIとコントローラのセットです。
組織のチーム間でリソースを共有するためのクォータと階層を備えたマルチテナントバッチサービスを構築することができます。
Kueueは既存のKubernetesの機能を置き換えず、Job実行時のリソースのクォータや実行開始タイミングを制御します。そのため、オンプレミスとクラウドの両方で実行することができます。
K8sネイティブなJobリソース以外にも以下のリソースやサードパーティのツールと連携できます。
- RayClusters
- Plain Pods
- Kubeflow Jobs
- RayJobs
- Flux MiniClusters
- Python
- Jobsets
この記事ではKueueを使用する際に設定する基本的な機能について解説します。使用しているバージョンはv0.9.0です。(2024/11)
概念
KueueはJobのSuspend機能を使用してJobの開始タイミングを制御します。kueue-controllerはKueueのCustomResourceを使って定義したクォータとキューを考慮してSuspendを解除し、Jobを実行します。Kueueのアーキテクチャはgihyo.jpで公開されている入門Kueueの記事が参考になります。
JobがデプロイされるとKueueは内部的にWorkloadリソースを生成し、その情報を参照して制御を行います。そのため、Jobリソースに変更を加えることなくKueueによる制御を利用することができます。
CRD
Kueueに同梱されているCustomResourceはv0.9.0時点で以下です。
| scope | version | kind |
|---|---|---|
| cluster | v1beta1 | AdmissionCheck |
| cluster | v1alpha1 | Cohort |
| cluster | v1beta1 | ClusterQueue |
| namespace | v1beta1 | LocalQueue |
| cluster | v1beta1 | MultiKueueCluster |
| cluster | v1beta1 | MultiKueueConfig |
| cluster | v1beta1 | ProvisioningRequestConfig |
| cluster | v1beta1 | ResourceFlavor |
| cluster | v1alpha1 | Topology |
| cluster | v1beta1 | WorkloadPriorityClass |
| namespace | v1beta1 | Workload |
基本
Kueueの使用にあたってまず、ClusterQueue(+ResouceFlavor)・LocalQueue・Workloadを理解することが望ましいです。ClusterQueueとResourceFlavorはクラスタスコープのリソースであり、Kueueの主な機能であるJobに対するリソース割り当ての設定を行うCRです。その背景から、これは管理者が作成するリソースです。
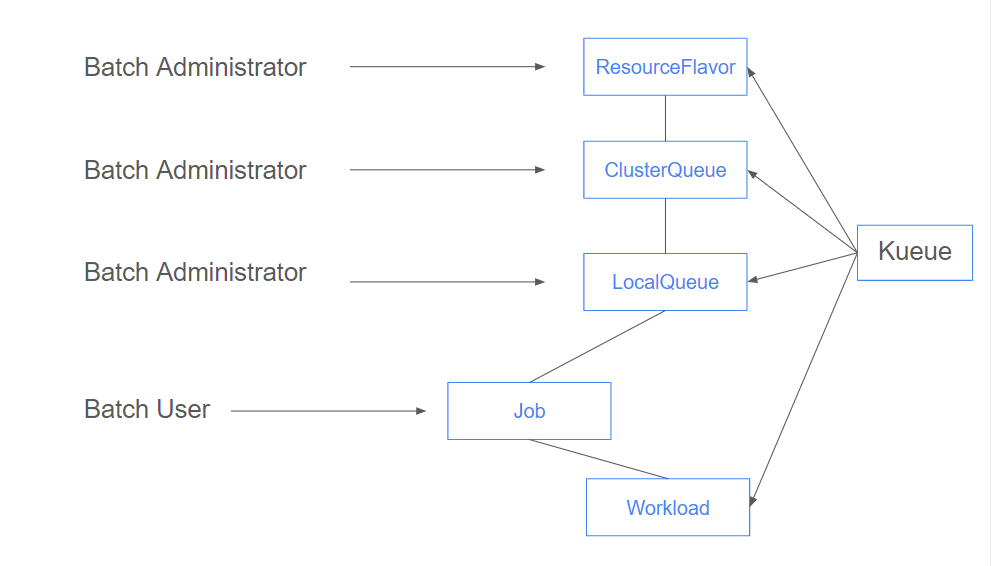
LocalQueueはJobをデプロイするリソースであり、Job作成者はLocalQueueを使用してClusterQueueのリソースを参照します。Kueueの特徴である各種ワークロードの連携はこのLocalQueueとの紐づけを行うだけで利用できます。
KueueはデプロイしたJobを内部的にWorkloadリソースとして管理します。Jobに紐づいたClusterQueueの情報やKueueの処理はWorkloadリソースを用いて間接的にJobを操作します。
設定詳細
Kueueの設定の大部分を占めるClusterQueueについて主に説明しています。
kind: ClusterQueue
クラスタ管理者が設定するもので、CPUやメモリといったリソースのプールを管理する役割を持ちます。ResourceFlavorによるリソースクォータとワークロードが許可される順序を設定します。
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: "cluster-queue"
spec:
namespaceSelector: {} # match all. ワークロードを許可するnamespace
resourceGroups:
- coveredResources: ["cpu", "memory", "pods"]
flavors:
- name: "spot"
resources:
- name: "cpu"
nominalQuota: 9 # リソースの合計値がn以下
- name: "memory"
nominalQuota: 36Gi
- name: "pods"
nominalQuota: 50
- name: "on-demand"
resources:
- name: "cpu"
nominalQuota: 18
- name: "memory"
nominalQuota: 72Gi
- name: "pods"
nominalQuota: 100
- coveredResources: ["gpu"]
flavors:
- name: "vendor1"
resources:
- name: "gpu"
nominalQuota: 10
- name: "vendor2"
resources:
- name: "gpu"
nominalQuota: 10
namespaceSelector
ClusterQueueへアクセスを許可するnamespaceを制限できます。{}と指定した場合は全てのnamespaceを許可します。以下の例はKubernetesがnamespaceの作成時に自動的に付与するラベルを使用しています。namespaceに特定のlabelが設定されている場合はそのlabelを指定することができます。
namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: default
queueingStrategy
BestEffortFIFO (default): ワークロードをできるだけFIFOで許可しますが、先頭のワークロードに割り当てるリソースが不足している場合に次のワークロードを試行します。
StrictFIFO: 優先度による順序付けに準拠するようになり、リソースが不足している場合でも次のワークロードは試行されずブロックされます。
Cohort
ClusterQueueをグループ化する機能で、同じcohortに属するClusterQueueは相互に未使用のクォータリソースを借りることができます。デフォルトではどのcohortにも属しません。.spec.cohortに同じ値を設定することによって、ClusterQueueがグループ化されます。
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: "cluster-queue"
spec:
cohort: "same-keyword" # ClusterQueueの間で同じCohort名である必要がある
namespaceSelector: {}
resourceGroups:
- coveredResources: ["cpu", "memory"]
flavors:
- name: "default-flavor" # ClusterQueueの間で同じFlavor名である必要がある
resources:
- name: "cpu"
nominalQuota: 200m
- name: "memory"
nominalQuota: 1Gi
---
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: "cohort-queue"
spec:
cohort: "same-keyword" # ClusterQueueの間で同じCohort名である必要がある
namespaceSelector: {}
resourceGroups:
- coveredResources: ["cpu", "memory"]
flavors:
- name: "default-flavor" # ClusterQueueの間で同じFlavor名である必要がある
resources:
- name: "cpu"
nominalQuota: 3
- name: "memory"
nominalQuota: 10Gi上記の設定例では、cluster-queueはcohort-queueのリソースを借りてワークロードを実行することができます。他に制限する設定が入っていない場合、default-flavorのリソースはcpuが200m+3(3000m)、memoryは1Gi+10Giまで使用できることになります。
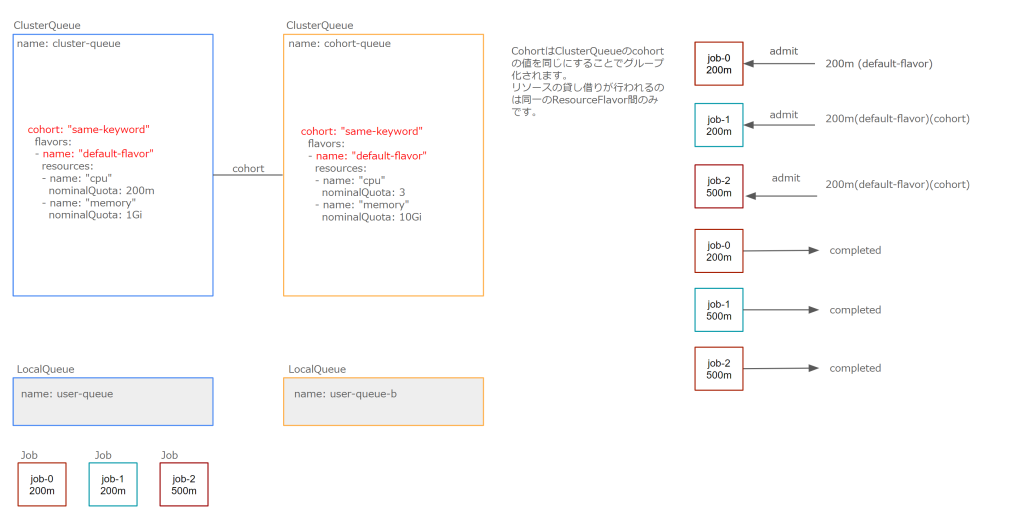
ClusterQueueがcohortに属している場合は次のように動作します。
- ResourceFlavorのリストを調べます。未使用のクォータとcohortの未使用のクォータに従って適合するか評価します。適合しない場合は次のResourceFlavorを評価します。
- 次の条件を満たす場合にワークロードが適合します。
- 未使用のnoinalQuota以下のリソースを要求している (図のjob-0が該当)
- cohort内の未使用のnoinalQuotaを合計した値以下のリソースを要求している (図のjob-1が該当)
- 未使用のnominalQuota + borrowingLimit以下である場合 (borrowingLimitの設定によって他のClusterQueueから借りることができるリソース量に制限がある場合)
- そのClusterQueueで定義してあるResourceFlavorのみ借りることができます。
- ワークロードは1つのResourceFlavorからのみクォータを借りることができます。
cohortを使用しているとき、nominalQuotaに収まるワークロードが優先されます。複数のワークロードがcohortによってスケジュール可能になる場合は、workloadsのpriorityを参照してスケジューリングします。feature gateの PrioritySortingWithinCohort=false が適用されている場合、timestampを参照して古いものからスケジューリングされます。
BorrowingLimit
他のClusterQueueから借りることができるリソースの量を制限できます。フィールドが無い場合やnullの場合は無制限となります。
以下の設定ではcohortを含めてcpuが10まで使えることになります。
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: "team-a-cq"
spec:
namespaceSelector: {} # match all.
cohort: "team-ab"
resourceGroups:
- coveredResources: ["cpu", "memory"]
flavors:
- name: "default-flavor"
resources:
- name: "cpu"
nominalQuota: 9
borrowingLimit: 1LendingLimit (Beta)
cohort内の他のClusterQueueに貸し出すリソース量を制限できます。v0.9からデフォルトで有効化されました。
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: "team-b-cq"
spec:
namespaceSelector: {} # match all.
cohort: "team-ab"
resourceGroups:
- coveredResources: ["cpu"]
flavors:
- name: "default-flavor"
resources:
- name: "cpu"
nominalQuota: 12
lendingLimit: 1Preemption
ClusterQueueや属するcohortに十分なクォータが残っていない場合、条件に合致するワークロードを取り除いてクォータを確保する優先的な割り込み(Preemption)をトリガーすることができます。
Preemptionの各設定のデフォルト値はNeverとなっており、preemptionは発生しません。
Preemptionの各設定とFlavorFungibilityの組み合わせで動作が変化するため、挙動が複雑になる可能性があります。ここでは図を用いて整理してみます。コンセプトや設計については以下のドキュメントを参照します。
- https://github.com/kubernetes-sigs/kueue/blob/main/site/content/en/docs/concepts/preemption.md
- https://github.com/kubernetes-sigs/kueue/tree/main/keps/83-workload-preemption
- https://github.com/kubernetes-sigs/kueue/blob/main/site/content/en/docs/concepts/preemption.md
整理のため、初めに以下の用語を使用します。
- Preemptees: Preemption対象のワークロード.
- Target ClusterQueues: Preempteesが所属するClusterQueue
- Preemptor: Preemptionの起因になったワークロード
- Preempting ClusterQueue: Preemptorが所属するClusterQueue
Preemptionが有効になっている場合、次の条件のいずれかによって発生します。
- PreemptorsとPreempteesが同じClusterQueueに所属しており(Target ClusterQueues = Preempting ClusterQueue)、Preempteeの優先度がより低い
- PreempteesとPreemptorsが同じcohortに所属しており、PreempteeとPreemptorがTarget ClusterQueueのnominalQuotaを超えるリソースを要求している
Kueueはできるだけ少ないワークロードをpreemptするために次の特性を持つワークロードを優先します。
- 借用しているClusterQueueに属するワークロード
- 優先度が最も低いワークロード
- 最近承認されたワークロード
PreemptionのアルゴリズムにはClassic PreemptionとFair Sharingの2種類があります。
これらは同じcohortに所属している他のClusterQueueに対してPreemptionを実行するかどうかの判断基準が異なります。
この記事内の以降で整理する際に動作確認しているアルゴリズムはClassic Preemptionであり、Fair Sharingを使用した場合は動作が異なる可能性があります。
Classic Preemptionでは以下の場合にのみPreemptionが発生します。
- ワークロードの要求リソースがflavorのnominalQuotaを下回っている場合
borrowWithinCohortが有効になっている場合- 全てのPreemption候補がPreemptorと同じClusterQueueに属している場合
また、以下のいずれかに該当するワークロードがPreemptionの候補になります。
- Preemptorと同じClusterQueueに属しており、Preempting CQの
withinClusterQueueポリシーを満たしている - Cohort内の他のClusterQueueに属しており借用を行っているかつ、Preempting CQの
reclaimWithinCohortおよびborrowWithinCohortポリシーを満たしている。
Preemptionの候補はリスト化され、次の優先度に基づいてソートされます。
- cohort内の借用Queueからのワークロード
- 優先度が低く設定されたワークロード
- 最近許可されたワークロード
ここからはClusterQueueのPreemptionのポリシー設定であるreclaimWithinCohort、borrowWithinCohort、withinClusterQueueについて確認します。実験としてcohortに属している2つのClusterQueue、それぞれのClsuterQueueに対応するLocalQueue、優先度と要求リソースが異なる3つのワークロードを用意します。以下のような図を用いて動作を示しますが、例えばこの図では次の情報と前提を意味します。
- Job-0は200mのCPUを要求している
- 赤枠で囲ったJobは青枠で囲ったJobよりも優先度が高い(=job-0とjob-2はjob-1よりも優先度が高い)
- Jobは縦軸上部のClusterQueueに所属している(job-0とjob-2は左側の
cluster-queueのClusterQueueを使用し、job-1は右側のcohort-queueのClusterQueueを使用する) - job-0, job-1, job-2の順番でJobリソースが作成され、ワークロードの許可プロセスが行われる
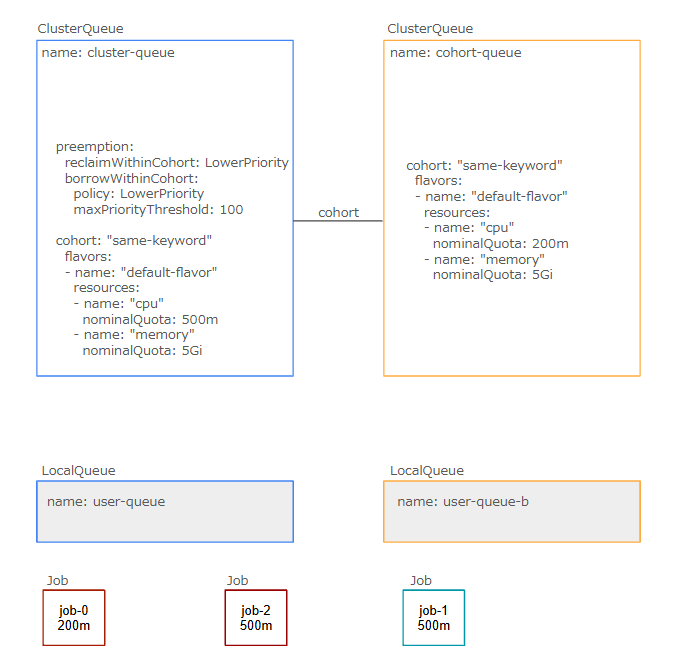
withinClusterQueue
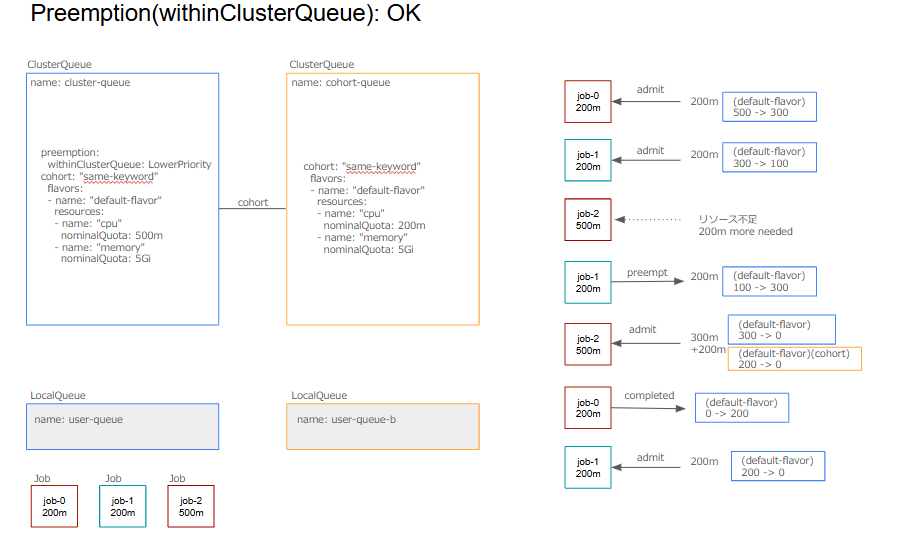
preemptingCQ内のアクティブなワークロードにPreemptionを行うか決定します。デフォルトではNeverになっており、Preemptionは行われません。LowerPriority を指定した場合、実行中の優先度が低いワークロードを保留中のワークロードがpreemptできるようになります。LowerOrNewerEqualPriority を指定した場合は、優先度が同等のものかつpreemptorよりも新しいワークロードにPreemptionが行われます。
preemptees(preempt対象): job-1
targetCQ(preempt対象のCQ): cluster-queue
preemptor(収容されるワークロード): job-2
preemptingCQ(preemptorのCQ): cluster-queue
・preemptingCQ nominalQuota >= preemptor resources: OK (500 >= 500)
・preemptorCQ = targetCQ: OK
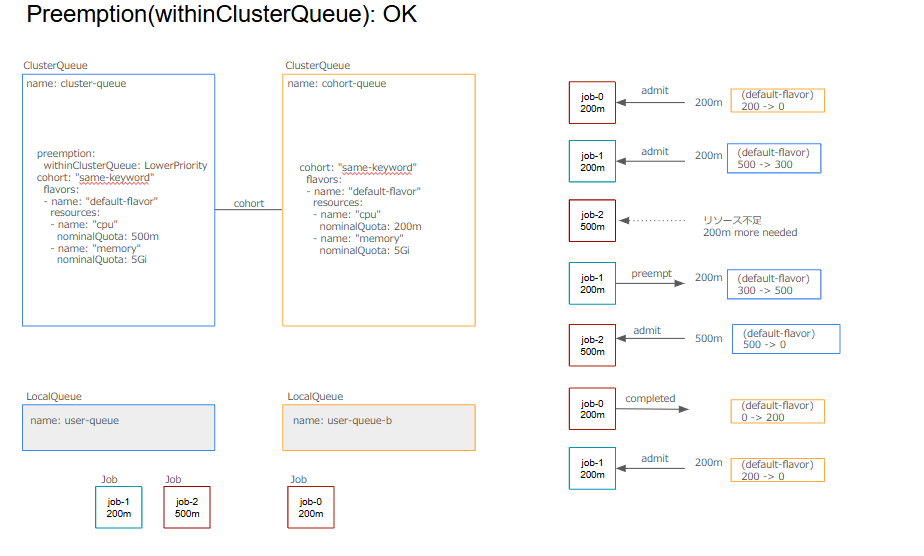
まずは、3つのJobが全て同一のClusterQueueに属する単純なケースを考えます。このケースのように同一のClusterQueueに属する優先度の低いワークロードをPreemptionすることができます。
preemptees(preempt対象): job-1
targetCQ(preempt対象のCQ): cluster-queue
preemptor(収容されるワークロード): job-2
preemptingCQ(preemptorのCQ): cluster-queue
・preemptingCQ nominalQuota >= preemptor resources: OK (500 >= 500)
・preemptorCQ = targetCQ: OK次に、job-0が異なるClusterQueueに属する場合を考えます。この場合、job-1とjob-2は前回と同じClusterQueueに属し、それぞれのJobが要求するリソースも変わりません。このようにjob-1とjob-2が同じClusterQueueである場合にpreemptionが行われることが確認できます。
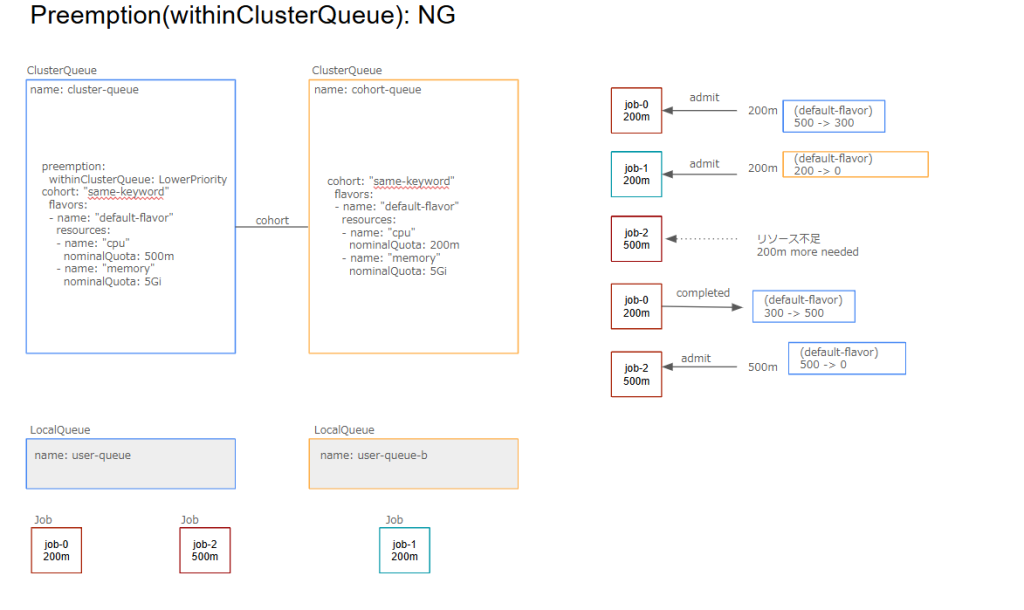
preemptees(preempt対象): job-1
targetCQ(preempt対象のCQ): cohort-queue
preemptor(収容されるワークロード): job-2
preemptingCQ(preemptorのCQ): cluster-queue
・preemptingCQ nominalQuota >= preemptor resources: OK
(500 >= 500)
・preemptorCQ = targetCQ: NGここで試しにjob-1をjob-2とは異なるClusterQueueに属すように変更してみます。すると、premptionが発生しなくなります。このようなケースでpreemptionを発生させるには、後述のreclaimWithinCohortなどを使用する必要があります。
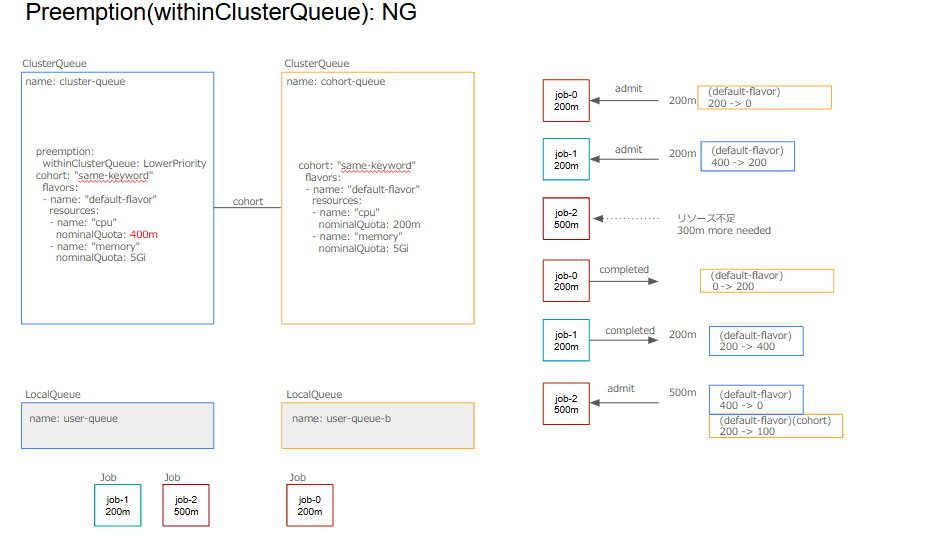
preemptees(preempt対象): X
targetCQ(preempt対象のCQ): X
preemptor(収容されるワークロード): job-2
preemptingCQ(preemptorのCQ): cluster-queue
・preemptingCQ nominalQuota >= preemptor resources: X
(400 >≠ 500)
・preemptorCQ = targetCQ: OK
次にClusterQueueのnominalQuotaの値を減らしてみます。それぞれのJobが要求するリソースは変わりません。この場合、以下のようにClusterQueueのnominalQuotaを超えるjob-2についてはPreemptionが発生しません。このようなケースでPreemptionを発生させるには、後述のborrowWithinCohortを使用する必要があります。
preemptees(preempt対象): X
targetCQ(preempt対象のCQ): X
preemptor(収容されるワークロード): job-2
preemptingCQ(preemptorのCQ): cluster-queue
・preemptingCQ nominalQuota >= preemptor resources: NG(200 >≠ 500)
・preemptorCQ = targetCQ: OK
試しにClusterQueueのFlavorの設定を入れ替えてみます。cluster-queue のCPUのnominalQuotaが200mに変わりました。このように最初にPreemptionできていたJobの配置でも、ClusterQueueのnominalQuotaを超えているため、Preemptionが発生しません。

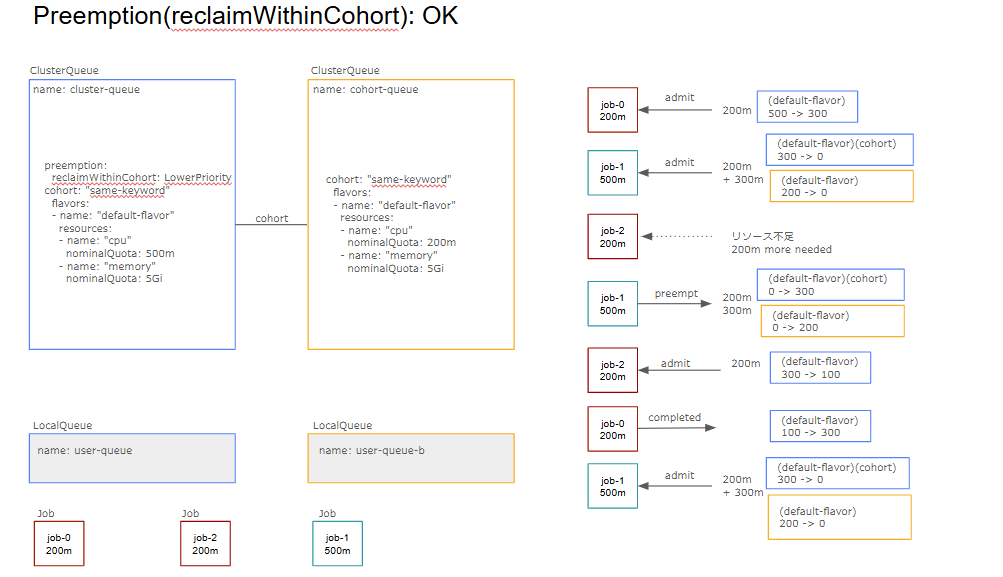
reclaimWithinCohort
cohort内の他のClusterQueueのワークロードをpreemptできるかどうかの設定です。保留中のワークロードがClusterQueueのnominalQuotaに収まる場合にcohort内のワークロードのみをpreemptionします。デフォルトはNeverになっており、preemptionは行われません。
preemptees(preempt対象): job-1
targetCQ(preempt対象のCQ): cohort-queue
preemptor(収容されるワークロード): job-2
preemptingCQ(preemptorのCQ): cluster-queue
・preemptingCQ nominalQuota >= preemptor resources: OK(500 >= 200)
・targetCQ remaining nominalQuota + preemptees borrowing preemptingCQ nominalQuota >= preemptor resources: OK(0 + 300 >= 200)
・targetCQ ≠ preemptingCQ: OK優先度の低いjob-1が異なるClusterQueueに属している状態を考えます。ClusterQueueではjob-1の要求するリソースを満たせないため、cohort内の他のClusterQueueからリソースを借りています。図のように他のClusterQueueによって使用されているnominalQuotaを開放するためにpreemptionを行います。job-1はcohort内の他のClusterQueueに所属している優先度の低いワークロードであるため、preemptionが発生します。
preemptees(preempt対象): X
targetCQ(preempt対象のCQ): X
preemptor(収容されるワークロード): job-2
preemptingCQ(preemptorのCQ): cluster-queue
・preemptingCQ nominalQuota>= preemptor resources: O(500 >= 200)
・targetCQ remaining nominalQuota + preemptees borrowing preemptingCQ nominalQuota >= preemptor resources: OK(0 + 300 >= 200)
・targetCQ ≠ preemptingCQ: NG先ほどの例からjob-1の属するClusterQueueを変更してみます。ここでワークロードの配置だけを変えてみるとpreemptionが発生しなくなります。このパターンではcohort内の他のClusterQueueに属しているワークロードが存在しないため、preemptionが発生しません。この場合にPreemptionを行うにはwithinClusterQueueの設定が必要になります。
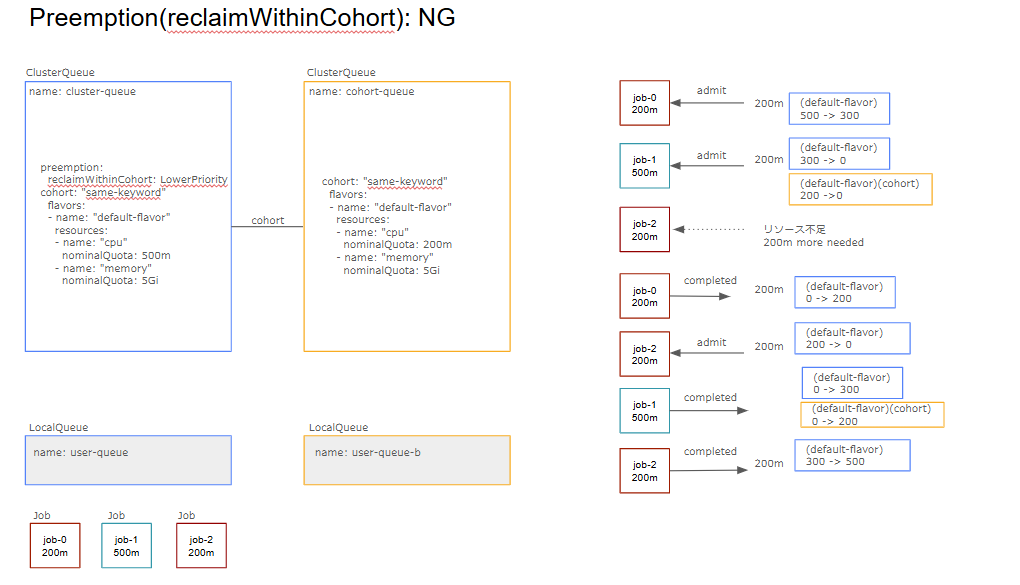
preemptees(preempt対象): job-1
targetCQ(preempt対象のCQ): cohort-queue
preemptor(収容されるワークロード): job-2
preemptingCQ(preemptorのCQ): cluster-queue
・preemptingCQ nominalQuota>= preemptor resources: OK(500 >= 500)
・targetCQ remaining nominalQuota + preemptees borrowing preemptingCQ nominalQuota>= preemptor resources: NG(0 + 300 >= 500) -> OK(200 + 300 >= 500)
・targetCQ ≠ preemptingCQ: OKここで少し変わったケースを見てみます。Preemptionがjob-2の作成時には行われず、job-0の完了時に発生してしまうパターンです。
このケースから分かることは、job-2がPreemptionを行う際にcohort内の別ClusterQueueのnominalQuotaは考慮されていないということです。job-1が使用しているpreemptingCQのnominalQuotaは300mであり、500mには届いていません。
ですが実際にはcohort全体でみると500mのリソースがるため借用を利用してワークロードを許可することができるはずです。job-0が完了したタイミングでpreemptiong後のpreemptingCQが500mを超えるため、preemptionが発生します。
このようなケースでPreemptionを行うには後述のborrowingWithinCohortが適しています。Preemption対象となりうる優先度の低いワークロードはこのような形で進捗が失われる可能性があることを認識しておく必要があります。
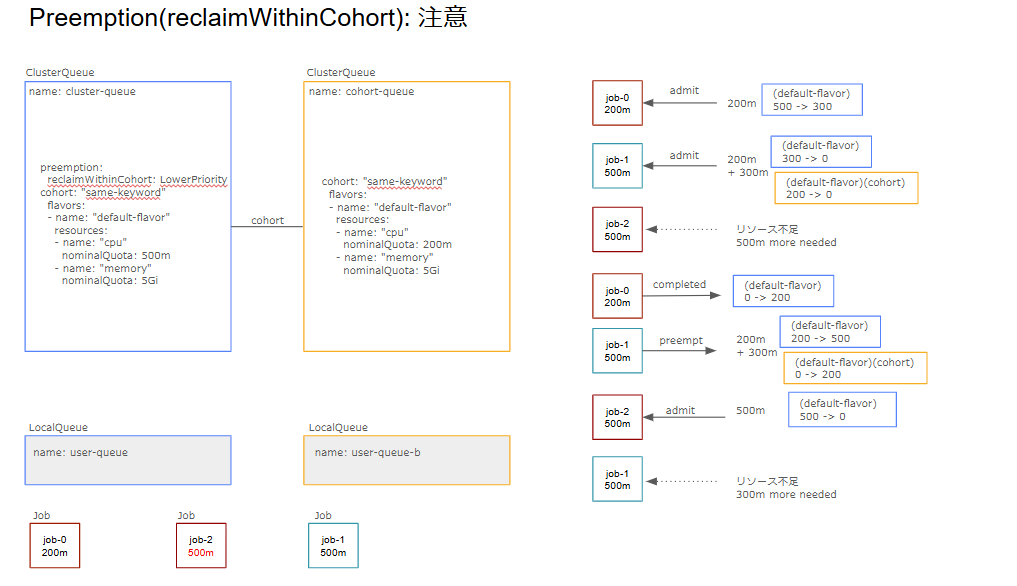
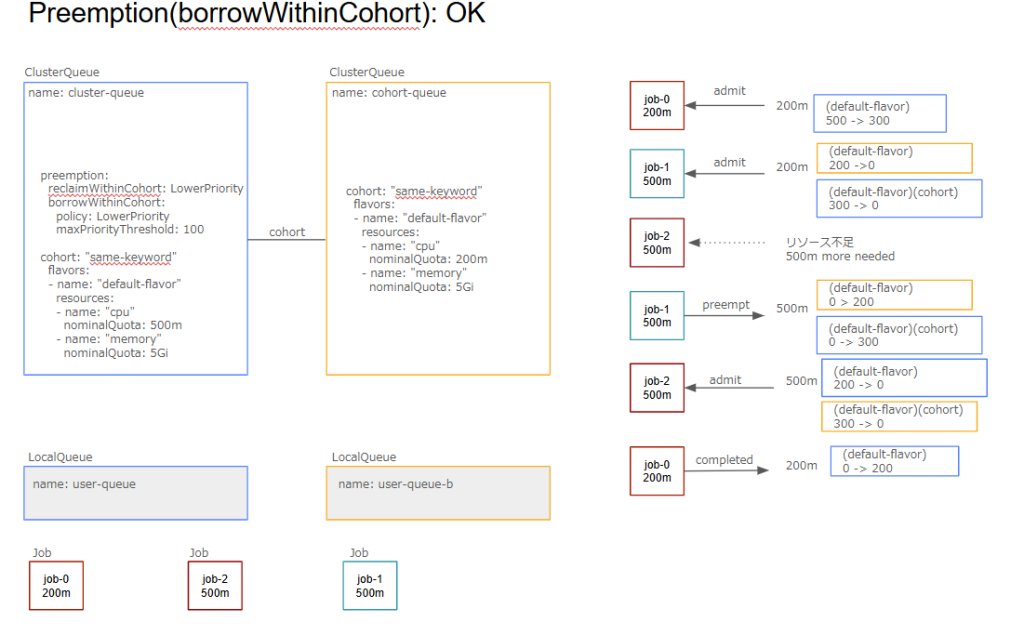
borrowWithinCohort
ワークロードが借用を必要とする場合に他のClusterQueueからワークロードをpreemptionできるかどうかを決定します。
cohort内の他のClusterQueueのnominalQuotaを使用しているjobに対してpreemptを実施します。デフォルトはNeverになっておりpreemptされません。
Never以外の値を設定するためには上記のreclaimWithinCohortの設定が有効である必要があります。LowerPriorityに設定した場合、より優先度が低い場合にのみpreemptされます。maxPriorityThreshold を設定してpreemptされる優先度の上限を制限できます。
preemptees(preempt対象): job-1
targetCQ(preempt対象のCQ): cohort-queue
preemptor(収容されるワークロード): job-2
preemptingCQ(preemptorのCQ): cluster-queue
・cohort remaining nominalQuota + preemptees requests resource>= preemptor resources: OK(0 + 500 >= 500)
・targetCQ ≠ preemptingCQ: OK
・preemptees borrowing from preemptingCQ: OKreclaimWithinCohortと同様に同じClusterQueueに属する優先度の低いワークロードはPreemptionの候補になりません。ここではreclaimWithinCohortのみ設定した場合とは挙動が異なるパターンについて紹介します。
次の例はreclaimWithinCohortの3番目にあった後からpreemptionが発生するパターンとワークロードの配置は同じですが、borrowingWithinCohortによりjob-2の作成時点でpreemptionが発生するようになります。
preemptees(preempt対象): job-1
targetCQ(preempt対象のCQ): cohort-queue
preemptor(収容されるワークロード): job-2
preemptingCQ(preemptorのCQ): cluster-queue
・cohort remaining nominalQuota + preemptees requests resource>= preemptor resources: OK(0+500 >= 500)
・targetCQ ≠ preemptingCQ: OK
・preemptees borrowing from preemptingCQ: OK
こちらも同様にreclaimWithinCohortのみではPreemptionが発生しません。
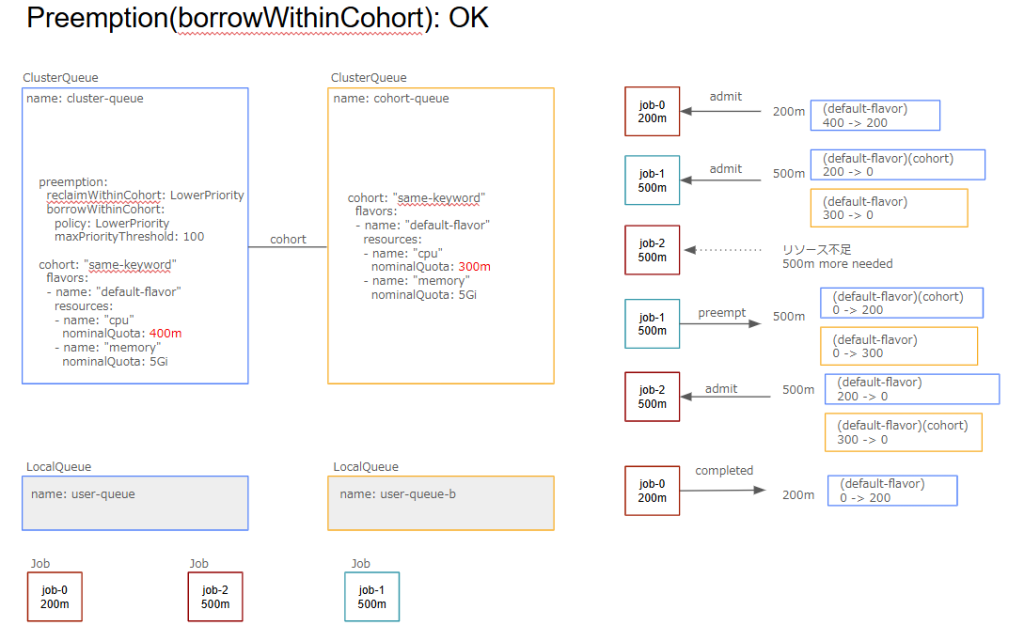
preemptees(preempt対象): X
targetCQ(preempt対象のCQ): X
preemptor(収容されるワークロード): job-2
preemptingCQ(preemptorのCQ): cluster-queue
・cohort remaining nominalQuota + preemptees requests resource>= preemptor resources: OK(300+500 >= 500)
・targetCQ ≠ preemptingCQ: OK
・preemptees borrowing from preemptingCQ: NGただし、以下のようにjob-1が借用を利用していない場合にはpreemptionが発生しません。
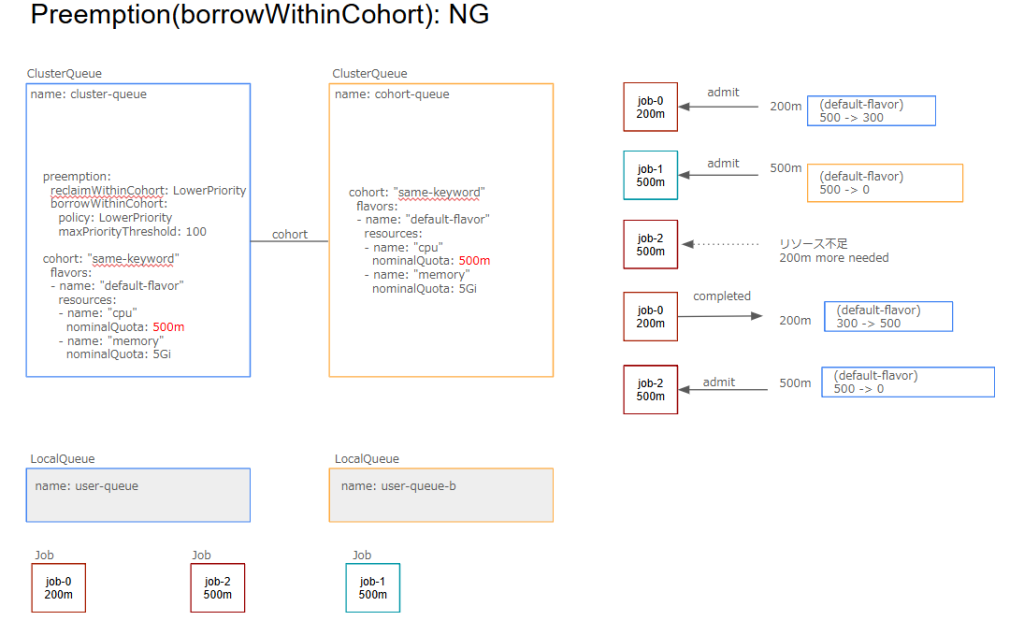
FlavorFungibility
ClusterQueueにcohortや複数のResourceFlavorが設定されている場合の動作を設定します。Preemptの設定と合わせて挙動が変更されるため注意が必要です。
apiVersion: kueue.x-k8s.io/v1beta1
kind: ClusterQueue
metadata:
name: "team-a-cq"
spec:
flavorFungibility:
whenCanBorrow: Borrow
whenCanPreempt: TryNextFlavorwhenCanBorrow
デフォルトはBorrowになっており、Cohortからのリソース借用が可能な場合に借用を行います。TryNextFlavorを設定するとCohort内のリソース借用を行わずClusterQueue内のResourceFlavorが利用可能か試します。
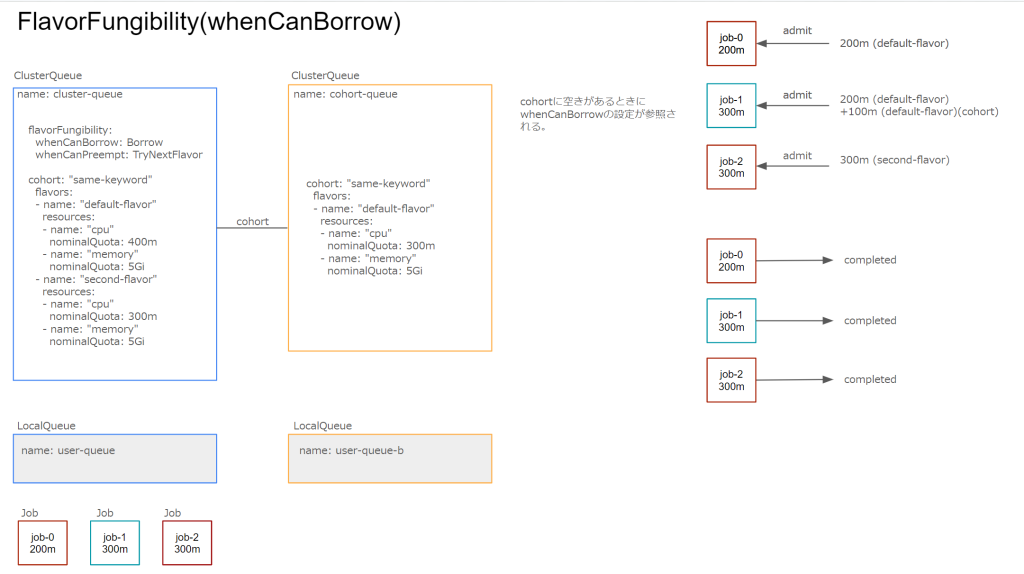
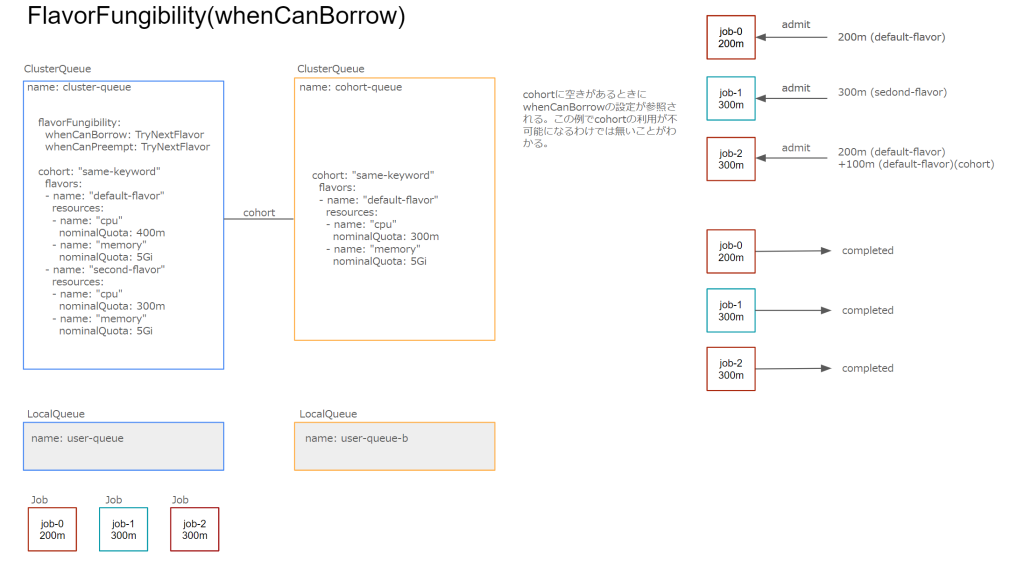
whenCanPreempt
デフォルトはTryNextFlavorになっており、Preemptを行わずClusterQueue内のResourceFlavorが利用可能か試します。Preemptを設定する場合は前述したwithinClusterQueueなどのPreemptの設定が既に行われている必要があります。

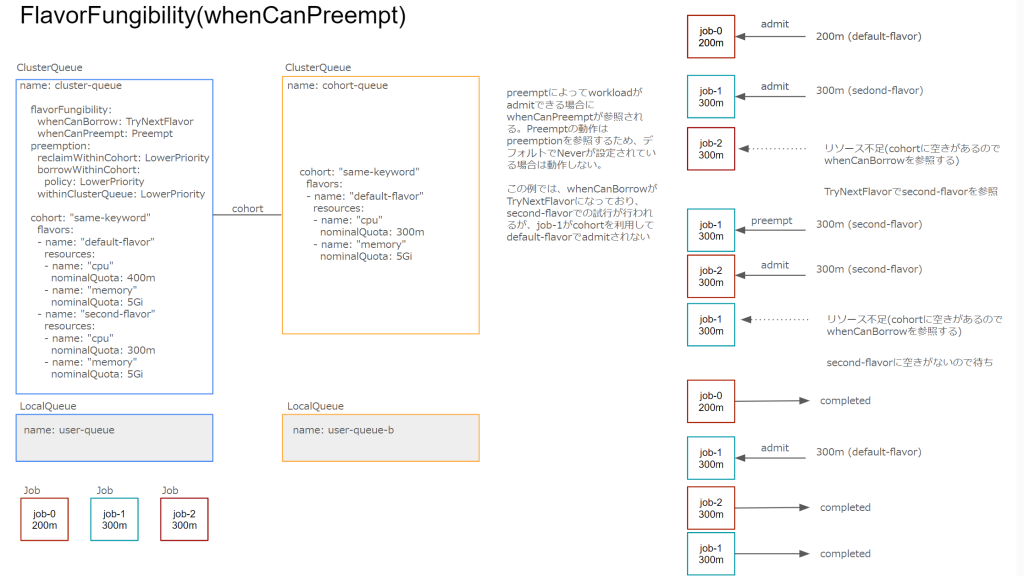
最後に
本記事ではKueueの概要と設定の大半を占めるClusterQueueについてまとめました。
CohortやPriorityClass、Preemptionの要素は設定が増えていくと複雑になってきます。特にPreemptionとFlavorFungibilityの組み合わせによってはワークロードが意図せずPreemptされたり、実行が保留になる場合があります。必要に応じてデフォルトの設定から追加していき、期待通りに動作する設定を作成しましょう。