
はじめに
はじめまして、Sreake事業部でインターンをしている村山です。
今回は、PR Guardianというツールの開発と検証をしました。PR GuardianはPull Requestの概要の作成、コードの改善提案をするツールです。
PR-Guardianについて
まずPR-Guardianについて説明します。PR-GuardianはPR-Agent(Qodo Merge)やCopilot for pull requestと同様にPull Requestのレビューを中心とした機能を提供するGo製のツールです。
前回の記事では概要作成と改善提案の機能についての解説を行いました。今回は作成した新たな機能とそれらのベース技術についての解説を行います。
新機能について
PR-Guardianは以下の機能を新たに追加しました。これらの機能はPR-Agentの機能を参考にし、作成したものです。各機能の中で紹介するシステムプロンプトは便宜上、日本語で記述していますが、実際には英語のプロンプトを与えています。また、主要な部分のみを抜粋しているため、例示などは省略されていることがあります。
レビュー機能
PRのレビューを行います。レビューするための材料として、PRのタイトルとPRでのdiffを与えます。レビューには、GitHubのスタッフエンジニアの方の哲学を取り入れ、以下のような指示を入れています。
あなたは熟練したエンジニアです。
あなたのタスクは、コードレビューアーとして著者と議論を行い、質問をしたり、仮定に異議を唱えたり、コードを改善するための第三者の視点を提供することです。
コードレビューでしっかりと自分の意見を伝えることは、製品の将来を導き、インシデントを防ぐだけでなく、コミュニケーションの明確さが重要です。
どのコメントが個人的な好みであり、どれが承認の障害となるのかを明確にすることが求められます。
コードレビューをより効果的にし、意図をさらに明確にするために、あなたが提案するアプローチの例を提供してください。
プロンプトには、PRの情報と上記のような指示の他に、入力情報の読み方、出力フォーマットなどが含まれています。そのプロンプトによる出力は以下のようになります。
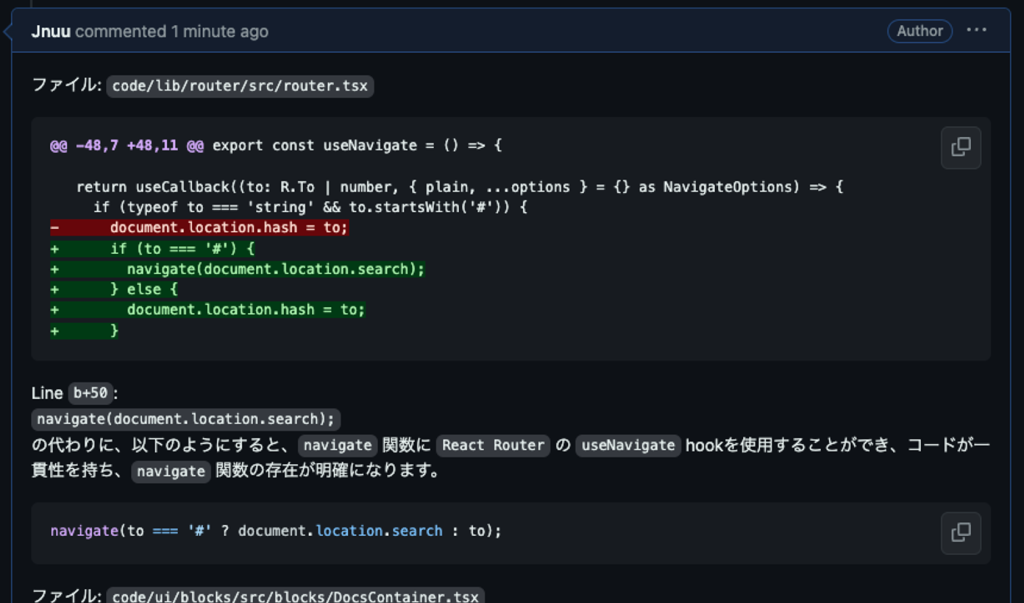
質問回答機能
ユーザからの質問に回答します。質問の回答には、PRのdiff、リポジトリのコード、機能の呼び出しがレビューコメントである場合は、そのコメントのレビュー内容を使用します。PRの内容について質問する場合は/ask {質問} のように呼び出すことで、PRの内容全体を対象に質問できます。レビューに対する質問は対象となるレビューコメントへの返信でこの機能を呼び出すことで、レビュー内容に対する回答を生成します。このレビューはPR-Guardianが生成したものでも、人によってレビューされたものでも構いません。レビューコメントに関する質問への回答をするためには、レビューされている箇所をLLMに渡す必要があります。基本的に、レビューコメントには変更を提案する行とその前後の1、2行しか含まれておらず、コードのコンテキストとして入力するには不十分です。また、PRのdiffもコンテキスト内の変更のないコードは省略されるため、入力には不十分な場合もあります。レビュワーと同様の視点を持たせるためにも、コンテキストのコードは入力しておくほうが良い結果が得られやすいです。コンテキストのコードを取得するために、レビューコメントのdiff hunk headerからコードのコンテキストを取得し、それを元に該当箇所のコードを取得します。該当箇所のコードの取得方法については、後述します。LLMに該当箇所のコードと質問を入力することで、diffの範囲外に及ぶ質問でも対応することができます。
一方でタスクとしては比較的定番のものであるため、以下のような指示をしています。
あなたは熟練したエンジニアです。
あなたのタスクは、Pull Request (PR) によって変更されたコードを理解し、ユーザーからの質問に適切に答えることです。
ユーザーからの質問は、PRにおけるコードの変更内容や、各ファイルのhunkに関するものです。
例えば、以下のようなDiffに対して、
@@ -56,7 +56,15 @@ export const DocsContainer: FC<PropsWithChildren<DocsContainerProps>> = ({
<SourceContainer channel={context.channel}>
<ThemeProvider theme={ensureTheme(theme)}>
<DocsPageWrapper
- toc={toc ? <TableOfContents className="sbdocs sbdocs-toc--custom" {...toc} /> : null}
+ toc={
+ toc ? (
+ <TableOfContents
+ className="sbdocs sbdocs-toc--custom"
+ channel={context.channel}
+ {...toc}
+ />
+ ) : null
+ } Diffの外にあるpropsについての質問を投げても、正しく回答が返ってきます。

コンポーネントの改善提案機能
コンポーネント単位の改善提案をします。前回紹介したコード改善機能との違いは、提案をする範囲がDiffの範囲ではなく、Diffの範囲外を含めて改善提案を行うことです。コンポーネントについては質問回答と同様です。機能の呼び出しと同時にコンポーネントの名前をコメントに含めることで、そのコンポーネントをコミットのリポジトリ全体から検索し、コンポーネントのコードを入力に含めます。
プロンプトはコード改善機能とほぼ同じです。
あなたは熟練したエンジニアです。
あなたのタスクは、Pull Request に関連するコンポーネントのコードをレビューし、そのコードの品質をどのように向上させるかを検討することです。
もしコンポーネントのコードの品質を向上させる余地がある場合は、改善されたコードの差分と変更理由を提案してください。
コンポーネントのコードがすでに高品質である場合は、提案を行う必要はありません。
ユーザーからは、Pull Request の概要とコンポーネントのコードが提供されます。
改善提案についてはレビューコメントではなく、通常のコメントとして投稿するようにしています。レビューコメントは、提案したコードがそのままコミットすることができますが、コンポーネントごと改善提案をした場合、提案されたコードをそのままコミットするには現段階では好ましくありません。提案がPRの趣旨と合致していないものであったり、PRを分ける方が適切であるような提案がされることが多くあるためです。
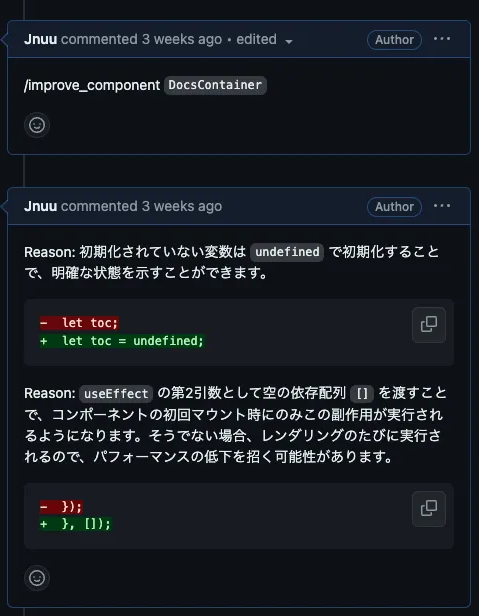
PRの内容とのズレがないよう、コンポーネントの提案に対してどのような提案を行うかを指定することもできます。
/improve_component <コンポーネント名> <追加のプロンプト>
類似のIssue(PR)検索機能
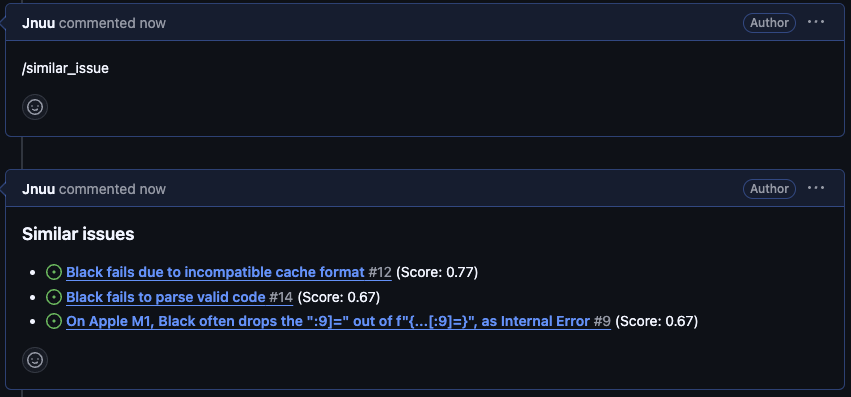
現在のPRに類似したIssue(PR)を探します。東京都知事選にて、安野たかひろさんのマニフェストのリポジトリで話題になっていた機能のようなものです。PRのタイトルとボディをEmbeddingし、Pineconeに蓄積します。機能が呼び出された際には、Pineconeでベクトル検索を行い類似のIssueを取得します。検索にはcos類似度を使用し、上位の類似度のIssueを類似度と共に返します。
正しく類似しているIssueが返されているのかの検証として、psf/blackのissueのうち、レビュワーによって似ているissueが提示されており、duplicateのラベルが付けられているissueを対象に正しいissueが提示できるかを検証しました。ラベルづけされたissue(類似issue)を5つ、その5つのラベルづけされたissueに関連づけられたissue(類似元issue)を8つ、全く関係のないissue(無関係issue)を5つをissueとして登録しました。その後、各類似元issueのPRでこの機能を呼び出します。
結果として、ラベルissueは0.7以上のスコアで1番、1番も正しい類似issueの場合は2番で正しく類似issueが検出できていました。ただ、無関係issueであるのに0.7に近いスコアで2,3番目に検出されるものもありました。下の画像は、1番目が正しい類似issueで2,3番目は無関係issueです。2,3番目を見ると、1番目と内容は無関係であるものの以下の点で類似していました。
- issueの書き方(フォーマット)
- 使用環境(OSなど)
以上の点に加えて、3つともボディの分量が少なく、相対的に類似している部分が多くなっていたため、類似度が高くなってしまったのだと考えられます。
最も類似度の高いものを検出するという点では良い結果が得られましたが、それ以下に関しては更なる検証と改善の余地があると思いました。今後は、issueのタイトルとボディに加えて、issue上でのコメントや、PRのコードなどとも上手く組み合わせていきたいと思います。
CHANGELOG.mdの更新機能
CHANGELOG.mdの更新を行います。基本的には概要作成機能と同じです。概要作成機能で作成された概要と相違の内容に概要作成機能と同じ情報を入力し、すでにあるCHANGELOG.mdのフォーマットとも相違がないようCHANGELOG.mdの内容も入力します。指示は以下のような形です。
あなたは熟練したエンジニアです。
あなたのタスクは、Pull Request (PR) によって変更されたコードをレビューし、CHANGELOG.md の内容を更新することです。
PRで行われた変更内容を、CHANGELOG.mdの内容に合わせて記述してください。
ユーザーからは、個々のファイルのhunkとしてPRのコード変更と、CHANGELOG.mdの内容が提供されます。
ここから得られた結果をコメントとして投稿します。追加する部分のみを出力するように指示していますが、これは改善提案機能など同様に人による確認のプロセスを挟むためです。
コメント、説明の追加機能
PRのコードの理解を助けるためのコメントを追加します。このコメントというのは、PRで変更のあったコンポーネントに対するもので、コードの内外のどちらにも対応しています。コード内のコメントでは、その言語のフォーマットに合わせたコメントを記述します。コード外を選択した場合は、変更のあった各コンポーネントの説明を、必要であれば図を含めてコメントとして投稿します。PRの概要説明機能との違いは、スコープの違いです。概要説明では変更のあったファイルごとの説明をしますが、この機能では変更のあったコンポーネント単位で説明を行います。
図を用いる場合はMermaidダイアグラムを使用します。Mermaidはフローチャートやシーケンス図、クラス図などを描画することができます。GitHubではMermaidのレンダリングに対応しているため、Mermaid用のコードブロック内にMermaidの構文に沿って記述したものをコメント内に追加するだけで下記の画像のようにレンダリングされます。画像を添付する場合は、情報量が増加すると共に読みづらくなってしまいますが、Mermaidによるレンダリングの場合は、コメント内で拡大や移動ができる上に修正も容易です。
LLMのモデルに関わらず、コードと共に「内容をMermaid形式で出力」のようなプロンプトを入力することで、基本的には修正を加えずにGitHub上で使用できるMermaid形式の出力が返されます。ただ、稀にMermaidのバージョンによってレンダリングできない出力がされることもあります。
あなたは熟練したエンジニアです。
あなたのタスクはPRのdiffからそのコード内での関係を図式化することです。
図式化にはmermaid形式を用いてください。使用する図は適宜選択してください。以下がPRのdiffです。
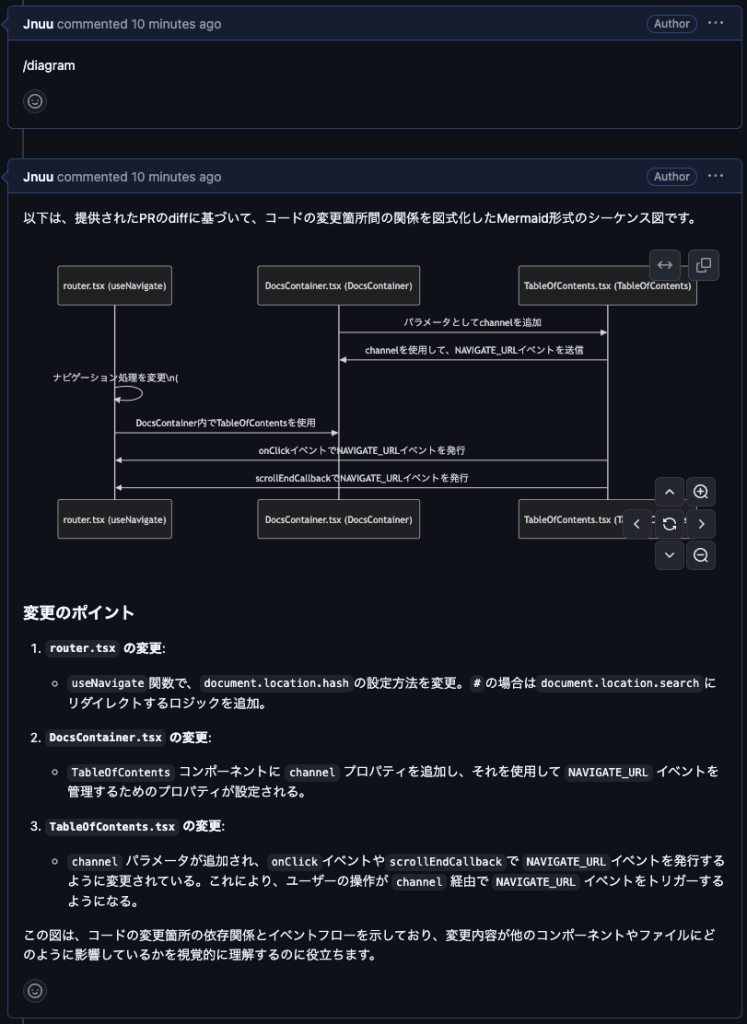
言語対応とパーサーについて
言語対応について
汎用的なツールにするためには、様々なプログラミング言語に対応することは重要です。LLMに任せてしまえば、プログラミング言語ごとの違いを意識せずに様々な機能を提供することができるように感じてしまいますが、なかなか難しい部分もあります。
概要作成や変更点全体の改善提案は、LLMに丸投げでもそれなりの回答が返ってきます。一方で、コンポーネントの名前とそのコンポーネントが含まれたコードを与えて、コード全体の何行から何行がコンポーネントのコードかを聞くとピッタリ正解というのはほとんどありません。どうにか工夫すれば正答率を上げられるのかも知れませんが、静的にコードを解析して構造から辿った方が確実です。ただ、PythonのパーサーでGoをパースできないように、言語ごとに対応を変える必要が出てきます。この対応にはコストもそれなりにかかります。これは推測ですが、PR-Agentの静的解析を使用しているであろう機能が有料かつ言語が限られているのも、こういう点が関係しているのだと思います。(静的解析以外のテストやコメントのフォーマットの部分もあるとは思いますが。)
PR-Guardianでは、PR-Agentが現段階で対応していないGoとRustに対応しています。また、後述するパーサーの運用によって、言語ごと一から対応する場合と比較して新たな言語への対応が容易になるような試みをしています。ただ、各言語での厳密性や網羅性に関しては劣る部分があるため、フォーマットやスタイルに沿ったドキュメントやテストの生成には対応できていないなどの問題もあります。フォーマットやスタイルに関しては、一つの言語の中でも複数存在する場合も多く、簡単な問題ではありません。PR-Guardianではそういった問題と向き合いつつ、手軽に触れられる機能、言語を増やしていく方針で開発しています。
パーサーについて
質問回答機能やコンポーネント改善機能のためにパーサーを導入しました。パーサーエンジンはtree-sitterを使用しています。tree-sitterはGitHubのコード検索にも使用されている、多言語対応可能なパーサーです。今まではコードの一致を確認するために、コードを文字列として単純に比較をしていました。しかしながら、質問回答機能、コンポーネント改善機能の実現はその方法では不可能でした。コンポーネント名だけが入力された場合、今までのロジックでは、コードの中からコンポーネントを検索した際に、それが宣言なのか呼び出しなのかの判定ができず、宣言、定義の部分のコードを取得することができませんでした。また、対応する言語を増やすたびに考慮しなければならない構文を網羅する必要があり、対応言語を増やすことは厳しい状況でした。
tree-sitterを導入することで宣言部のコードを取得することができるようになります。イメージとしては、GitHubのサイト上でできるコード検索のようなものになります。GitHubのコード検索はAPIが提供されていないため、APIが提供されている検索機能を利用して、コンポーネントの検索を実現しています。
手順としては以下の通りです。
- GitHubの検索APIに対し、リポジトリや検索対象のクエリと共にコンポーネント名で検索をリクエストする
- レスポンスのマッチの中に対象のコンポーネントがあるか判定する
- 存在したコンポーネントの宣言部を全て取得する
GitHubの検索APIからのレスポンスは、ベストマッチで取得します。この、ベストマッチというのは、基本的にはコンポーネントの呼び出しよりもコンポーネントの定義、宣言が関連度が高くなるようです。レスポンスの形式は以下のようになっています。フラグメントと、そのフラグメントの中でマッチした部分のテキストとそのインデックスが渡されます。フラグメント内のマッチ部分を判定し、コンポーネントがあるかどうかを判定します。
{
"text_matches": [
{
"object_url": "https://api.github.com/repositories/215335/issues/132",
"object_type": "Issue",
"property": "body",
"fragment": "comprehensive windows font I know of).\n\nIf we can find a commonly
distributed windows font that supports them then no problem (we can use html
font tags) but otherwise the '(21)' style is probably better.\n",
"matches": [
{
"text": "windows",
"indices": [
14,
21
]
},
{
"text": "windows",
"indices": [
78,
85
]
}
]
},ここから、パーサーでファイル全体から定義の全体を抽出します。フラグメントはその名の通り断片であるため、よほどシンプルなコンポーネントでない限りは、コンポーネント全体がフラグメント内に収まることはありません。そのため、ファイル全体から定義部分のみを取得する必要があります。まずフラグメントのマッチしている行をツリーに変換します。このツリーをルートとした際に、その子ノードのノードタイプを取得します。ツリーは例として以下のような形になります。
const sapmple = (a) => {};
program [0, 0] - [3, 0]
lexical_declaration [0, 0] - [2, 2]
variable_declarator [0, 6] - [2, 1]
name: identifier [0, 6] - [0, 13]
value: arrow_function [0, 16] - [2, 1]
parameters: formal_parameters [0, 16] - [0, 19]
identifier [0, 17] - [0, 18]
body: statement_block [0, 23] - [2, 1]
return_statement [1, 1] - [1, 10]
identifier [1, 8] - [1, 9]ルートはprogram、子ノードはlexical_declarationというタイプになります。この、子ノードのタイプでコード全体にクエリをかけます。tree-sitterでは関数名などのidentifierをキャプチャーし、それによってクエリを実行することもできます。しかしながら、ノードタイプによって構造は異なるため、正確にidentifierをキャプチャーするためには、対応する全てのタイプの構造を理解しておく必要があります。また、キーがidentifierとも限りません。例えばTypeScriptの場合、constやfunction であれば、name: identifier というような構造になりますが、classやtype などでは、name: type_identifier のようになり、identifierではキャプチャーすることができません。ただ、tree-sitterのクエリのAlternationsを使用すればidentifier であるかtype_identifier であるかの差であれば対応することができます。以下のように[] 内にidentifierとtype_identifier を記述することで一致したどちらかをキャプチャすることができます。
([
(identifier)
(type_identifier)
] @id
)一つの言語である場合はAlternationsを使用すれば、パターンをすべて列挙すれば対応することも容易です。しかしながら、様々な言語への対応という点となると少し難しい点もあります。先ほどはTypeScriptを例として挙げましたが、C++ではノードの名前もフィールド名も異なります。
void sample(x) {}
translation_unit [0, 0] - [1, 0]
function_definition [0, 0] - [0, 17]
type: primitive_type [0, 0] - [0, 4]
declarator: function_declarator [0, 5] - [0, 14]
declarator: identifier [0, 5] - [0, 11]
parameters: parameter_list [0, 11] - [0, 14]
parameter_declaration [0, 12] - [0, 13]
type: type_identifier [0, 12] - [0, 13]
body: compound_statement [0, 15] - [0, 17]関数名自体はdeclarator: identifier のidentifierの部分であるため、同じですがキーがdeclaratorというものになっています。そのため、ノードを辿って関数名を取得することはTypeScriptと同じままでは困難です。また、Alternationsでの対応はtype_identifier というがキーが存在しない場合はクエリ自体がエラーとなり実行することができません。そのため、今回はタイプでクエリをかけています。
少し荒削りではありますが、こういった方針をとることで言語対応にかかるコストの削減を試みています。
コストについて
PR-Guardianにおいて、入力トークンの多くを占めるのがファイルのdiffの部分です。そのため、PRの変更箇所が多ければ多いほどトークンとコストは増加します。概要を作成するdescribeのプロンプトでは、diffなどの実際のデータが入る部分を除くとトークン数は約450です。ここに2つのコミットで3つのファイルの約±50行が変更されたという情報を載せるとトークン数は約1420になります。単純に、50行あたり約1000トークンというような感じです。describeでは出力トークンは大体500前後に収まるため、gpt-4oを使用した場合トータルで約2円です。improveなどself-reflectionが含まれる機能は、describeよりはコストが掛かかりますが、それでも約5円に収まります。精度は多少落ちてしまいますが、より安価なモデルにすればコストを抑えることも可能です。例えば、improveは使わずにdescribeのような簡単なタスクをこなす機能だけを使うというような運用であれば、より安価なモデルを使っても問題はないでしょう。
以下の表に50行程度の変更があったPRで、各機能を実行した際のおおよそのトークン数を示します。improveやreviewなどは提案の数によってトークンはそれなりに変動します。update changelogもCHANGELOG.mdのボリュームによって入力トークンが大きく変動しますが、出力トークンは多くのケースで100以下に収まる上に、入力トークンは出力トークンと比較して半額程度に設定されていることが多いため、コストはそこまで増加しません。
| 機能 | 総トークン |
|---|---|
| describe | 1900 |
| improve | 4300 |
| improve component | 1300 |
| review | 2800 |
| ask | 2100 |
| update changelog | 3000 |
LLMによるコード生成とベンチマークについて
今日、LLMによるソフトウェアの自動開発の能力の向上は目を見張るものがあります。LLMの能力を測るベンチマークの一つとしてSWE-benchがあります。SWE-benchとはLLMのプログラミング、問題解決能力の評価のためのベンチマークです。SWE-benchでは、実世界のGitHub Issuesを言語モデルは解決できるかに焦点を当て、djangoなどのPythonの著名なリポジトリのIssuesから、コードベースとIssue、ユニットテストがデータセットとして提供されています。提供されるIssueとコードベースから、コードを修正し、そのコードがマージ後のテストを通過するかどうかを評価します。コードの修正時に言語モデルはテストの内容を参照することはできません。
データセットにはFull, Lite, Verifiedの三つの種類があります。12の著名なPythonのリポジトリから集められた、IssueとPRのペアが全て含まれているオリジナルのFull。評価時のコストの削減のためのLite。評価をより簡単で信頼性の高いものにしたVerifiedの三つです。このVerifiedはSWE-benchの作者とともにOpenAIがリリースしたもので、人間によってレビューされた500のデータセットです。オリジナルのデータセットは、ユニットテストの不確かさ、Issueの情報の不足、開発環境によるエージェント設定の困難さによって解決能力を正しく評価できていない可能性があるとOpenAIは指摘しています。これに対し、93人のプロのソフトウェアエンジニアによって各サンプルについて、Issueの記述、ユニットテスト、難易度などをスクリーニングし、適切なサンプルのみを抽出したデータセットがVerifiedです。Verifiedは他のデータセットよりも適切に評価ができ、GPT-4oでの結果がオリジナルでは16%だったものがVerifiedでは33.2%となるよう結果も得られています。正答率が1/6だったものが1/3となると、見え方も大きく変わり、ほとんどの問題は解けてしまうのではないかと感じます。
ただ、実際問題としてIssueやPRの記述が全てLLMフレンドリーな状態に整えられているとも限りません。著名なリポジトリの解決済みのIssue、PRでさえ、情報が不完全などとされてスクリーニングにかかっています。データセットになっているリポジトリは、どれも大きなコードベースで情報を完全に集めるのは難しいことかもしれません。ただ、必要な情報が揃っていなければ、現段階のLLMではコードを修正できない場合もあるわけです。
必要な情報を揃えるには手間もかかります。それは、リポジトリが大きくなればなるほど顕著です。その工程の一歩目に、LLMを用いたツールで情報をピックアップすれば、全て一から手作業で探し出すよりは効率的かもしれません。今後、PR-GuardianでIssueについてもPRと同様の機能を提供できるようになれば、コード生成のポテンシャルをより引き出すことができるようになるかもしれません。
ただ、SWE-benchで優秀な結果を残したモデルがあっても、修正したコードを最終的にマージするかの判断は、現段階では人間が行なうので、PRとその内容の理解は重要な位置を担っています。PR-Guardianは内容の理解とそこからの改善を助けることができます。PRの内容について議論が必要である場合も、PR-Guardianはコードに関する情報や第三者としての視点を与えることができるでしょう。
Copilot Chatについて
github.com上で使用できるCopilotがIndividualプランとBusinessプランで使用可能になりました。それに伴い、個人でも手軽にPR上でLLMの力を借りられるようになりました。
IssueやPRに関連する機能としては、コードについての質問、PRの要約の作成、スレッドの要約?が行えるようです。スレッドの要約については確認できていませんが、どれも手軽に使用でき、コードベースに直接アクセスできることもあって内容は正確であると感じました。特にコードについての質問については、PR内のFiles changedで変更に関する部分での質問や、PRのスコープ外のファイルやシンボルの添付ができ、精度の良い回答が得られました。一方で、現在はまだベータ段階ということもありますが、PRの要約についてはPRのdiffと「変更点を要約してください」というプロンプトを入力した際の出力そのままに近いという印象でした。
Copilotには膨大なコードベースを自由に参照できる強みがあるので、それを活かした今後も様々な機能がリリースされていくはずです。PR-Guardianはモデルやプロンプトを変更できる点やOSSである点で差別化を図っていければと思います。
終わりに
今回はPR-Guardianというツールの様々な機能開発、改善をしました。LLMによるコーディング能力、問題解決能力は日々向上していますが、人間による意思決定の場としてPRはある程度必要になるものだと感じています。PR-Guardianでは、PRでの変更の理解を助け、コードのさらなる改善に繋げるための機能を提供することを目指しています。また、PRでの議論を十分に行うことで、問題の発生時や開発者が新規に参加する際に、コードの理解に役立ちます。PR-Guardianに限らず、こういったツールを活用することで効率や品質の向上に繋げることができると感じているため、是非多くの方に触っていただければと思っています。
今後も既存の機能の改善、拡張とともに、LLMやコード生成ツールの進化を活用し、生産性の向上に貢献できるツールとして開発を続けていきたいと思います。