
1. はじめに
こんにちは、「信頼性は可用性ではない」を標語にしているnwiizoです。
近年、サービスの信頼性向上に向けた取り組みとして、SLI(Service Level Indicator)、SLO(Service Level Objective)、エラーバジェットという概念が注目を集めています。これらは、Google発祥のSRE(Site Reliability Engineering)プラクティスの中核をなす考え方であり、多くの組織がこのアプローチを採用し始めています。また、関連するツールも成熟し始めており、実践的な導入がより容易になってきています。
本ガイドでは、SLI、SLO、エラーバジェットを導入する前に知っておくべき重要なポイントについて詳細に解説します。各概念の定義から実践的な導入ステップ、さらには組織文化の変革まで、包括的な情報を提供します。
2. SREにおける基本概念
SRE(Site Reliability Engineering)では、サービスの信頼性を定量的に管理するために、以下の3つの重要な概念を用います。これらは「Reliability Stack」と呼ばれ、サービスの信頼性を体系的に管理するための基盤となります。
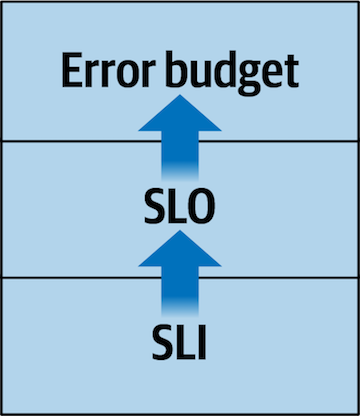
- SLI(Service Level Indicator)
- 定義:サービスの性能や信頼性を測定する具体的な指標
- 例:レイテンシ、エラー率、スループット
- 重要性:ユーザー体験に直接影響を与える要素を数値化し、客観的な評価を可能にする
- SLO(Service Level Objective)
- 定義:SLIに基づいて設定される目標値
- 例:「99.9%のリクエストが200ms以内に応答すること」
- 重要性:サービスの期待される品質レベルを定義し、チーム間の共通理解を形成する
- エラーバジェット
- 定義:SLOから逸脱することが許容される範囲
- 例:月間99.9%の可用性を目標とする場合、0.1%(43.2分)がエラーバジェット
- 重要性:信頼性と変更速度のバランスを取るためのツールとして機能する
これらの概念を適切に設計・運用することで、以下のような利点が得られます:
- サービスの信頼性に関する客観的な評価が可能になる
- 開発チームと運用チーム間のコミュニケーションが円滑になる
- リスクを定量化し、適切なトレードオフを行うことができる
SREチームは、これらの指標を常にモニタリングし、必要に応じて調整を行うことで、サービスの長期的な信頼性と進化を両立させることができます。
3. ユーザー視点の重要性
3.1 クリティカルユーザージャーニー(CUJ)の理解
CUJとは、ユーザーがサービスを利用する際の最も重要で頻繁に行われる一連の操作や体験を指します。SLOの効果的な実装の第一歩は、製品、開発、SREの各チームが連携し、対象のワークロードとそのCUJについて共通の理解を得ることです。
CUJを理解することの重要性:
- サービスの核心的な価値提案を反映し、ユーザー満足度と事業成功に直接影響を与える
- SLOの設定や最適化の焦点を絞り、最大の効果を得ることができる
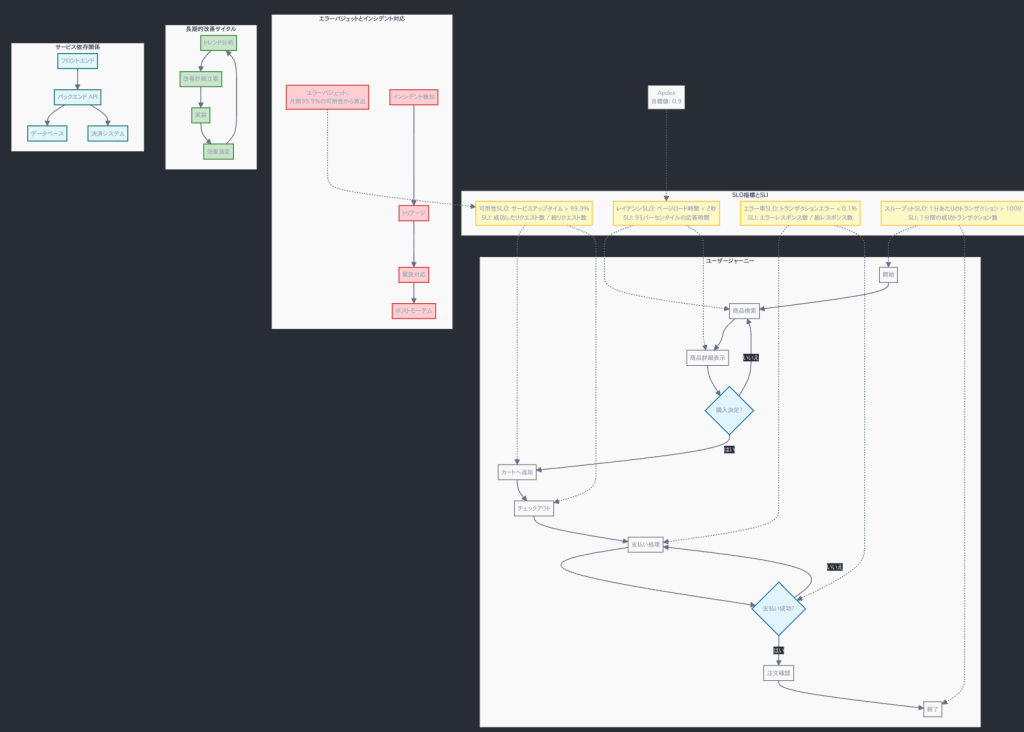
Eコマースサイトのクリティカルユーザージャーニーとして作成したMermaidを作成したのでこちらも表示しておきます(なぜなら、ちょっと頑張ったからです)
graph TD
subgraph ユーザージャーニー
A[開始] --> B[商品検索]
B --> C[商品詳細表示]
C --> D{購入決定?}
D -->|はい| E[カートへ追加]
D -->|いいえ| B
E --> F[チェックアウト]
F --> G[支払い処理]
G --> H{支払い成功?}
H -->|はい| I[注文確認]
H -->|いいえ| G
I --> J[終了]
end
subgraph SLO指標とSLI
K[レイテンシSLO: ページロード時間 < 2秒<br>SLI: 95パーセンタイルの応答時間]
L[可用性SLO: サービスアップタイム > 99.9%<br>SLI: 成功したリクエスト数 / 総リクエスト数]
M[エラー率SLO: トランザクションエラー < 0.1%<br>SLI: エラーレスポンス数 / 総レスポンス数]
N[スループットSLO: 1分あたりのトランザクション > 1000<br>SLI: 1分間の成功トランザクション数]
end
subgraph エラーバジェットとインシデント対応
O[エラーバジェット:<br>月間99.9%の可用性から算出]
P[インシデント検知]
Q[トリアージ]
R[緊急対応]
S[ポストモーテム]
end
subgraph 長期的改善サイクル
T[トレンド分析]
U[改善計画立案]
V[実装]
W[効果測定]
end
subgraph サービス依存関係
X[フロントエンド]
Y[バックエンド API]
Z[データベース]
AA[決済システム]
end
K -.-> B & C
L -.-> E & F
M -.-> G & H
N -.-> A & J
O -.-> L
P --> Q --> R --> S
T --> U --> V --> W --> T
X --> Y --> Z
Y --> AA
classDef default fill:#f9f9f9,stroke:#333,stroke-width:1px;
classDef decision fill:#e1f5fe,stroke:#01579b,stroke-width:2px;
classDef slo fill:#fff9c4,stroke:#fbc02d,stroke-width:2px;
classDef incident fill:#ffcdd2,stroke:#c62828,stroke-width:2px;
classDef improvement fill:#c8e6c9,stroke:#2e7d32,stroke-width:2px;
classDef dependency fill:#e0f7fa,stroke:#006064,stroke-width:2px;
class D,H decision;
class K,L,M,N slo;
class O,P,Q,R,S incident;
class T,U,V,W improvement;
class X,Y,Z,AA dependency;
AB[Apdex<br>目標値: 0.9]
AB -.-> K3.2 CUJ理解のための重要ポイント
- ユーザーの価値:各ステップがユーザーにもたらす具体的な価値を明確にする
- ブレークポイント:ユーザーがジャーニーを中断する可能性のある箇所を特定し、対策を立てる
- 測定可能性:各ステップで測定可能な具体的な指標(KPI)を特定する
- 共通点:異なるユーザージャーニー間の類似点や重複する要素を特定し、横断的な改善機会を探る
- 統合測定:エンドツーエンドのユーザー体験を反映する包括的なメトリクスを設計する
- 依存関係:ユーザージャーニーの各ステップ間の相互依存性を特定し、最適化の機会を見出す
3.3 ユーザー体験を反映したSLIの選択
SLIは、エンジニア側の測定しやすいCPU,メモリ使用率がユーザーが実際に体験する品質を直接反映する指標を選ぶべきです。例えば:
- ページロード時間:ユーザーの待ち時間を直接測定
- トランザクションの成功率:ユーザーの目的達成度を示す
- 検索結果の関連性:ユーザーの情報取得効率を反映
- ストリーミングの品質:動画や音声の再生品質を測定
これらのSLIを適切に選択し、モニタリングすることで、ユーザー体験の継続的な改善につながります。
4. SLOの導入と設定
4.1 SLO導入のタイミングと段階的アプローチ
SLO(Service Level Objective)は、サービスの信頼性と性能を測定・改善するための重要なツールです。多くの組織では、SLOの導入を躊躇したり、完璧な指標を求めて導入を遅らせたりする傾向がありますが、実際には早い段階からの導入が推奨されます。
「Implementing Service Level Objectives」の著者は、この点について次のように述べています:
さっそく今日から初めてのSLIに取り掛かり、時間をかけて改良していきましょう。SLOの目標値を選択し、それに対するパフォーマンスを確認します。開始するときには、全員の同意を得る必要はありません。
この助言は、SLO導入における重要な原則を示しています:
- 早期開始の重要性: 完璧を求めて導入を遅らせるよりも、まずは始めることが大切です。初期の指標や目標は完璧でなくても構いません。
- 段階的改善: SLOは一度設定したら終わりではなく、継続的に改善していくものです。時間をかけて、より適切で有意義な指標に洗練させていくことができます。
- フィードバックループの確立: 早期に導入することで、実際のパフォーマンスデータを基に改善を行うことができます。これにより、より現実的で効果的なSLOを設定できます。
- 柔軟性の維持: 全員の同意を得る必要がないという点は、迅速な導入と柔軟な調整を可能にします。
4.2 SLO設定の原則
- ユーザーの期待と技術的制約のバランスを取る
- ユーザーニーズと技術的実現可能性の両方を考慮
- 多角的なアプローチ(ユーザー調査、技術評価、ギャップ分析など)を採用
- 透明性とコミュニケーションを重視し、ステークホルダー間の理解と協力を促進
- 達成可能かつ挑戦的な目標を設定する
- 現状パフォーマンスの正確な把握に基づいて、実現可能な目標を設定
- ストレッチゴールを組み込み、チームの成長と継続的改善を促す
- リスク管理とモチベーション戦略を統合し、目標達成の可能性を高める
- 定期的に見直し、調整する
- 定期的なレビューにより、SLOの有効性と適切性を維持
- データ駆動型のアプローチにより、客観的な評価と調整を行う
- ビジネス目標との整合性を確認し、SLOの戦略的価値を保証
4.3 SLO設定のステップ
- 現在のパフォーマンスレベルの測定
- ユーザー期待度の調査(アンケート、フィードバック分析)
- 競合他社のベンチマーク調査
- 初期SLOの設定と試験運用
- フィードバックに基づく調整
各ステップを慎重に実行し、継続的に改善することで、効果的なSLOを設定・管理することができます。
5. SLO文化の構築
SLO(Service Level Objective)文化を組織に効果的に浸透させるには、計画的かつ段階的なアプローチが必要です。以下に、各ステップの詳細な実施方法とベストプラクティスを示します。
1. 同意を得る
目的: ユーザー体験の重要性について組織全体の合意を形成する。
実施方法:
- 経営陣向けプレゼンテーションの実施
- SLOがビジネス成果に与える影響を数値で示す
- 競合他社の成功事例を紹介
- 全社員向けSLO啓発セッションの開催
- SLOに関するFAQドキュメントの作成と配布
ベストプラクティス:
- 技術的な詳細よりも、ビジネス価値に焦点を当てる
- 具体的な成功指標(KPI)とSLOの関連性を明示する
潜在的課題と解決策:
- 課題: 経営陣の理解不足 解決策: 業界アナリストや外部専門家を招いてセミナーを開催
2. SLOの作業を最優先する
目的: ユーザー満足度向上を組織の最優先課題として位置づける。
実施方法:
- SLO関連タスクの優先度付けガイドラインの策定
- 個人およびチーム評価指標へのSLO達成度の組み込み
- SLO改善プロジェクトのための専門チームの設立
ベストプラクティス:
- SLO達成度を週次/月次レビューの定例議題にする
- SLO改善に貢献した個人やチームを表彰する制度を設ける
潜在的課題と解決策:
- 課題: 既存の優先度付けプロセスとの競合 解決策: プロダクトオーナーやプロジェクトマネージャーとの協力体制を構築
3. SLOを実装する
目的: ユーザー視点に基づいた適切なSLIとSLOを設定する。
実施方法:
- ユーザージャーニーマッピングワークショップの開催
- 各ユーザーインタラクションポイントでのSLI特定セッション
- SLO設定のためのクロスファンクショナルチーミング
ベストプラクティス:
- 実際のユーザーフィードバックを活用してSLIを選定
- 技術チームとビジネスチームの協働でSLOを設定
潜在的課題と解決策:
- 課題: 複雑すぎるSLIの設定 解決策: 「シンプルで測定可能」な原則を徹底し、段階的に改良
4. SLOを使用する
目的: 日々の意思決定プロセスにSLOを組み込む。
実施方法:
- リアルタイムSLOダッシュボードの開発と全社共有
- SLOベースのインシデント対応プロセスの確立
- SLOに基づくリリース判断クライテリアの策定
ベストプラクティス:
- SLOダッシュボードを大画面で常時表示
- 週次SLOレビューミーティングの実施
潜在的課題と解決策:
- 課題: SLOデータの信頼性への疑問 解決策: 定期的なデータ品質チェックと監査プロセスの導入
5. SLOに関する処理を反復する
目的: ユーザーフィードバックを基にSLOを継続的に改善する。
実施方法:
- ユーザーフィードバック収集システムの構築(例:アプリ内フィードバック機能)
- 四半期ごとのSLO見直しワークショップの開催
- A/Bテストを活用したSLO改善実験の実施
ベストプラクティス:
- ユーザーフィードバックとSLOパフォーマンスの相関分析
- SLO改善サイクルを可視化し、進捗を共有
潜在的課題と解決策:
- 課題: フィードバックの量が少ない 解決策: ユーザーインセンティブプログラムの導入(例:フィードバック提供者への特典付与)
6. SLOの活用を他の人々に提唱する
目的: 組織全体でユーザー中心のアプローチを広める。
実施方法:
- 社内SLOカンファレンスの開催(年1回)
- SLOチャンピオン制度の導入(各部門でSLO推進者を任命)
- SLO成功事例のケーススタディ作成と共有
ベストプラクティス:
- 経営陣によるSLO推進メッセージの定期的な発信
- 新入社員研修にSLO基礎講座を組み込む
潜在的課題と解決策:
- 課題: 一部部門でのSLO採用の遅れ 解決策: 段階的導入計画の策定と、先行部門からのメンター制度の確立
これらのステップを通じて、組織全体でSLO文化を醸成し、継続的な改善サイクルを確立することができます。重要なのは、各ステップを組織の状況に合わせて柔軟に適用し、常にユーザー価値の向上を中心に据えることです。SLO文化の構築は長期的なプロセスであり、忍耐強く、かつ積極的に推進していくことが成功の鍵となります。
6. SLOの設計と文書化
効果的なSLO(Service Level Objective)の設計と文書化は、サービスの品質管理と改善の基盤となります。以下に、重要なポイントと実践的なアプローチを詳細に解説します。
6.1 技術仕様の徹底的な検討
- システム分析:
- アーキテクチャ図を作成し、各コンポーネントの役割と相互作用を明確化
- パフォーマンステストを実施し、システムの限界値を把握
- スケーラビリティ考慮:
- 負荷テストを行い、システムのスケーリング特性を文書化
- 将来の成長を見据えたキャパシティプランニングを実施
6.2 設計プロセスの文書化
- 決定記録:
- 設計会議の議事録を作成し、主要な決定事項を記録
- 決定理由と考慮された選択肢を明記(例:「99.9%の可用性を選択。99.99%は現在のインフラでは非現実的と判断」)
- トレーサビリティ:
- 各SLOをビジネス要件や技術的制約に紐付け
6.3 測定可能性の確認
- メトリクス定義:
- 各SLOに対する具体的な測定方法を定義(例:「APIレスポンスタイムは、サーバーでのリクエスト受信からレスポンス送信までの時間」)
- データソース特定:
- 各メトリクスのデータソースを明確化(例:「Prometheusから収集されるHTTPレスポンスコード」)
6.4 レイテンシSLOの詳細分析
- パーセンタイル活用:
- 95パーセンタイル、99パーセンタイルなど、複数のパーセンタイルを使用
- 例:「95%のリクエストを200ms以内に処理」
- ユーザー体験マッピング:
- レイテンシとユーザー満足度の相関を分析し、重要な閾値を特定
6.5 コンプライアンス期間の統一
- 期間設定:
- 全SLOに対して統一された期間を設定(例:「28日間のローリングウィンドウ」)
- 理由説明:
- 選択した期間とビジネスサイクルの関連性を文書化
6.6 変更履歴の管理
- バージョン管理:
- GitなどのバージョンFT管理システムを使用してSLO定義を管理
- 変更ログ:
- 各変更に対して、変更内容、理由、影響、承認者を記録
## 変更履歴
- v1.2 (2024-03-15): APIレイテンシSLOを200msから180msに引き下げ
- 理由: インフラ改善により達成可能となったため
- 影響: ユーザー体験の向上が期待される
- 承認者: Jane Doe (CTO)
6.7 アクセシビリティの確保
- 中央リポジトリ:
- GitLabやConfluenceなどの中央管理システムにSLO文書を保存
- アクセス制御:
- 役割ベースのアクセス制御(RBAC)を実装し、適切な閲覧・編集権限を設定
6.8 コードとしてのSLO管理
- SLOコード化:
slo:
name: "API Latency"
target: 0.95
window: "28d"
metric:
name: "http_request_duration_seconds"
threshold: 0.2
このYAML形式は、SLOの主要な要素を明確に定義し、以下の利点があります。
- 可読性:人間が理解しやすい形式
- バージョン管理:Gitなどのバージョン管理システムで追跡可能
- 自動化:CI/CDパイプラインでの利用が容易
- 自動化: SLOをコード化することで、以下のような自動化が可能になります:
- CI/CDパイプラインへの統合:
- SLO定義の構文チェック
- 既存のSLOとの整合性確認
- Prometheusルールの自動生成と適用
- Grafanaダッシュボードの自動更新
- 自動テスト:
- SLOに対する負荷テストの自動実行
- テスト結果とSLO基準の自動比較
- 変更管理:
- SLO変更時の自動レビュー依頼
- 変更履歴の自動記録
- レポーティング:
- 定期的なSLO遵守状況レポートの自動生成
- SLO違反時の自動インシデント作成
- インテグレーション:
- チャットボット(Slack等)を介したSLO情報の照会と更新
- オンコール管理システムとの連携
- CI/CDパイプラインへの統合:
6.9 DRY原則の遵守
- ライブラリ活用:
- 社内共通のSLOライブラリを開発し、標準的な計算ロジックを提供
- テンプレート化:
- 再利用可能なSLOテンプレートを作成し、新規SLO定義の効率化を図る
これらのプラクティスを適用することで、SLOの設計と文書化プロセスをより体系的かつ効果的に管理できます。定期的な見直しと更新を行い、SLOがサービスの進化に合わせて最適化されるよう努めることが重要です。
7. SLOの観察と改善
SLOの継続的な観察と改善は、サービスの信頼性向上において重要な役割を果たします。
7.1 SLO観察の実践例
- 定期的なSLOレビュー会議の開催:
- 週次または月次でSLOの達成状況を確認
- 問題点や改善余地を議論
- ユーザーフィードバックとSLOの相関分析:
- ユーザーの満足度調査結果とSLO達成度の関係を分析
- ユーザーニーズとSLOの整合性を確認
- SLO違反の根本原因分析とユーザー影響の評価:
- SLO違反が発生した際の詳細な調査
- ユーザーへの影響度を定量的に評価
- 再発防止策の立案と実施
- ユーザー体験向上のための改善策の検討と実施:
- SLO達成状況に基づいた具体的な改善案の策定
- A/Bテストによる改善策の効果検証
- 成功した改善策の全面展開
7.2 観察から得られる効果
- ユーザー体験に関する共通言語の確立:
- チーム間でSLOを基準としたコミュニケーションが可能に
- ユーザー体験の改善に関する議論がより具体的かつ効果的に
- ユーザーニーズの変化への迅速な対応:
- SLO観察を通じてユーザーニーズの変化を早期に検知
- 迅速な対応によるユーザー満足度の維持・向上
- 技術的な改善とユーザー満足度の明確な関連付け:
- 技術的な改善がどのようにユーザー体験の向上につながるかを可視化
- 投資対効果(ROI)の明確化による意思決定の促進
- 継続的改善サイクルの確立:
- PDCAサイクルの実践によるサービス品質の段階的向上
- チーム全体の学習と成長の促進
SLOの観察と改善プロセスを通じて、組織はユーザー中心のサービス提供を実現し、長期的な競争力を維持することができます。
8. よくある失敗とその対策
SLOの導入と運用において、以下のような失敗がよく見られます。これらを認識し、適切な対策を講じることが重要です。
8.1 不適切なSLIの選択
- 失敗例:インフラの可用性のみに注目し、実際のユーザー体験を反映していないSLIを選択する。
- 対策:
- ユーザージャーニーマッピングを実施し、各ステップでの重要な指標を特定する。
- リアルユーザーモニタリング(RUM)を導入し、実際のユーザー体験データを収集する。
- A/Bテストを活用し、異なるSLIの効果を比較検証する。
8.2 過度に厳しいSLOの設定
- 失敗例:現実的でない高すぎる目標(例:100%の可用性)を設定し、チームに過度のストレスを与える。
- 対策:
- 過去のパフォーマンスデータを分析し、現実的な目標を設定する。
- 段階的にSLO目標を引き上げ、チームの成長に合わせて調整する。
- 競合他社のベンチマークを参考にしつつ、自社の状況に合わせた目標を設定する。
8.3 エラーバジェットの無視
- 失敗例:エラーバジェットを設定しても、それを考慮せずに新機能の開発やリリースを進める。
- 対策:
- エラーバジェット消費に連動した具体的なアクションプランを策定する。
- 新機能リリースの判断基準にエラーバジェットの状況を含める。
- エラーバジェットの状況を定期的に全チームで共有し、意識を高める。
8.4 組織全体の理解不足
- 失敗例:SREチームのみがSLO/SLIを理解し、他部門との連携が取れていない。
- 対策:
- 全社的なSLOトレーニングプログラムを実施する。
- SLO達成に貢献した個人やチームの表彰制度を導入する。
- 経営陣向けにSLO導入効果の可視化と定期的な報告を行う。
8.5 過度な手動プロセスへの依存
- 失敗例:SLI/SLOの測定や報告が手動プロセスに依存し、リアルタイムの状況把握ができない。
- 対策:
- 自動化されたモニタリングとアラートシステムを構築する。
- ダッシュボードを作成し、リアルタイムでSLO状況を可視化する。
- CI/CDパイプラインにSLO検証を組み込む。
これらの失敗を回避し、適切な対策を講じることで、SLOの効果的な運用と継続的な改善が可能になります。
9. 技術的な考慮事項
SLOの効果的な実装には、以下の技術的な側面を考慮することが重要です。
9.1 適切なSLIの選択
ユーザーの実際の体験を反映するSLIを選択します。例:
- ページロード時間(ユーザーの待ち時間)
- トランザクション成功率(ユーザーの目的達成率)
- 検索結果の関連性(ユーザーの情報取得効率)
- APIレスポンスタイム(サービスの応答性)
- エラー率(サービスの信頼性)
9.2 ユーザー中心のSLO設定
SLOは、ユーザーの期待と技術的な制約のバランスを取りながら設定します。例:
- 「95%のユーザーが3秒以内にページを閲覧できる」
- 「99%のユーザーが最初の検索結果から目的の情報を見つけられる」
- 「99.9%のAPIリクエストが500ms以内に応答する」
9.3 ユーザー体験を考慮したエラーバジェット管理
エラーバジェットの消費状況を常にユーザー体験と関連付けて評価します。
- エラーバジェットの消費率に応じた自動アラートの設定
- ユーザー影響度に基づいたエラーバジェットの重み付け
- エラーバジェット消費と新機能リリースのバランス管理
9.4 ユーザー中心のモニタリングとアラート
- リアルユーザーモニタリング(RUM)の導入
- ブラウザやモバイルアプリからの実際のユーザー体験データの収集
- 地理的分布やデバイスタイプに基づいたパフォーマンス分析
- ユーザージャーニーに基づいたエンドツーエンドモニタリング
- 主要なユーザーフローの自動テストと監視
- クリティカルパスにおけるパフォーマンスのボトルネック特定
- ユーザー影響度に応じたアラートの優先度設定
- SLO違反の深刻度に基づいたエスカレーションポリシーの策定
- ビジネスインパクトと連動したアラート設定
9.5 データ収集と分析基盤の整備
- 分散トレーシングシステムの導入
- マイクロサービス環境における問題箇所の特定
- サービス間の依存関係とパフォーマンスの可視化
- 大規模データ処理基盤の構築
- リアルタイムデータ処理と長期的なトレンド分析の両立
- 機械学習を活用した異常検知と予測分析
9.6 自動化とツール統合
- CI/CDパイプラインとの統合
- デプロイ前のSLO検証テストの自動化
- カナリアリリースとSLOモニタリングの連携
- インシデント管理システムとの連携
- SLO違反時の自動チケット作成
- インシデントの影響とSLO達成状況の相関分析
これらの技術的考慮事項を適切に実装することで、SLOをより効果的に運用し、継続的なサービス品質の向上を実現することができます。
10. 組織的な考慮事項
SLOの成功的な導入と運用には、技術面だけでなく組織的な取り組みも重要です。以下に、組織全体でSLOを推進するための主要な考慮事項を示します。
10.1 経営陣の理解と支持
- ユーザー体験の向上が収益にどうつながるかを具体的に説明
- SLO達成度と顧客満足度、リテンション率の相関を示す
- 競合他社とのユーザー満足度の比較データの提示
- SLOを通じた継続的な改善がブランド価値向上につながることの説明
- 長期的な競争力強化とSLOの関係性を明確化
- 成功事例や業界トレンドの共有
- 経営指標とSLOの連携
- 財務KPIとSLOの関連付け
- 四半期ごとの経営報告にSLO達成状況を組み込む
10.2 チーム間の協力体制
ユーザー中心のアプローチを組織全体で実践するための体制を整えます:
- 全チームでユーザーフィードバックを共有する仕組みの構築
- 定期的なクロスファンクショナルミーティングの開催
- 共通のフィードバックポータルの導入
- ユーザージャーニーマップの作成と共有
- 各部門の役割と貢献ポイントの可視化
- ユーザー体験向上のためのアイデアソン開催
- チーム横断的なユーザー体験改善プロジェクトの推進
- 部門を超えたタスクフォースの結成
- 成功事例の共有と横展開の促進
10.3 SRE文化の醸成
- SREの原則と実践に関する全社的なトレーニングプログラムの実施
- 基礎から応用までの段階的な学習カリキュラムの設計
- オンラインコースと実践的なワークショップの組み合わせ
- SREチームと開発チームの定期的な交流セッションの設定
- ペアプログラミングやジョブローテーションの導入
- 相互理解を深めるための技術共有会の開催
- インシデント対応とポストモーテムプロセスの標準化
- インシデント対応マニュアルの整備と定期的な訓練
- blame-freeな文化の醸成と学習機会としてのポストモーテムの位置づけ
10.4 継続的学習と改善
- SLO達成状況の定期的なレビューと振り返りセッションの実施
- 四半期ごとのSLOレビューミーティングの開催
- 成功事例と改善点の分析と共有
- 業界のベストプラクティスや最新トレンドに関する情報共有会の開催
- 外部講師を招いたセミナーの実施
- 技術ブログや専門誌の輪読会の組織化
- 外部カンファレンスやワークショップへの参加奨励
- 参加費用の補助や社内発表会の開催
- 学んだ知識の社内還元を促進するメンタリングプログラムの導入
10.5 インセンティブ構造の見直し
- SLO達成に貢献したチームや個人の表彰制度の導入
- 四半期ごとのSLO MVP(Most Valuable Player)の選出
- 年間のSLO改善大賞の設立
- パフォーマンス評価にSLO関連の指標を組み込む
- 個人およびチーム評価にSLO達成度を反映
- SLO改善活動への貢献度を昇進・昇給の判断材料に含める
- エラーバジェットの効果的な管理を評価項目に含める
- エラーバジェットの適切な使用と管理に対する評価
- イノベーションとリスク管理のバランスを考慮した評価基準の設定
10.6 具体的な技術について
SLOの実装と管理を効率化するために、以下のようなツールやプラットフォームを活用することができます:
- オープンソースツール:
- クラウドプロバイダーのサービス:
- Google Cloud Monitoring:ウェブUIでSLO設定とエラーバジェット自動計算を提供。GCPサービスとの緊密な統合。
- Amazon CloudWatch:AWSリソースとカスタムメトリクスに対してSLOを設定・追跡。AWSサービスとのネイティブ統合。
- Azure Monitor:Azureリソースに対するSLIとSLOの設定・モニタリングを提供。Application Insightsとの連携。
- SaaS型ソリューション:
- Datadog SLO:複数データソースからのメトリクス集約とカスタムダッシュボードを提供。AIによる異常検知機能も搭載。
- PagerDuty:インシデント管理とSLAモニタリングを統合。自動エスカレーションと柔軟な通知オプション。
- Grafana Cloud SLO:SLOの定義・追跡・可視化を一元化し複数データソースを統合。オープンソースGrafanaとの互換性。
- Mackerel:シンプルで使いやすいインターフェースでSLO管理を提供。カスタムメトリクスとの柔軟な連携が可能。
これらのツールは組織のニーズや既存のインフラストラクチャに応じて選択できます。導入に際しては各ツールの特性、スケーラビリティ、コスト、既存システムとの統合のしやすさ、およびチームのスキルセットを考慮し、慎重に比較検討することが重要です。また、段階的な導入アプローチを取り、継続的な評価と最適化を行うことで、SLO管理の効果を最大化することができます。
11. まとめ
SLI、SLO、エラーバジェットの導入は、組織全体でユーザー中心のアプローチを採用する大きな機会です。技術的な指標の向上だけでなく、常にユーザーの視点に立ち返ることで、真の意味でサービスの信頼性と価値を高めることができます。
11.1 主要なポイント
- ユーザー視点を常に中心に据える
- クリティカルユーザージャーニー(CUJ)の理解と分析
- ユーザー体験を直接反映するSLIの選択
- 適切なSLIの選択とSLOの設定が重要
- 測定可能で意味のあるSLIの特定
- 達成可能かつ挑戦的なSLO目標の設定
- エラーバジェットを効果的に活用し、イノベーションと信頼性のバランスを取る
- エラーバジェットの概念と重要性の理解
- エラーバジェットに基づいた意思決定プロセスの確立
- 組織全体の理解と協力が成功の鍵
- 経営陣からエンジニアまで、全レベルでのSLO文化の浸透
- クロスファンクショナルな協力体制の構築
- 継続的な観察と改善のサイクルを確立する
- 定期的なSLOレビューと調整プロセスの実施
- データ駆動型の意思決定と改善活動の推進
11.2 次のステップ
- 自組織のSLI/SLO成熟度評価の実施
- 現状分析と改善ポイントの特定
- ベンチマーキングと目標設定
- パイロットプロジェクトの計画立案
- 小規模なスコープでのSLO導入試行
- 学習と改善のサイクルの確立
- SREスキル開発プランの策定
- 組織全体のSRE/SLOリテラシー向上計画
- 専門家の育成と知識の展開戦略
- モニタリングとアラートシステムの見直しと改善
- 既存システムのSLO対応度評価
- 必要に応じた新ツールの導入検討
- エラーバジェットポリシーの策定と導入
- エラーバジェットの計算方法と使用ルールの定義
- エラーバジェットに基づく意思決定フローの確立
SLI、SLO、エラーバジェットの導入は、単なる技術的な取り組みではなく、組織文化の変革を伴う大きなチャレンジです。しかし、この取り組みを通じて、組織はより強固な信頼性エンジニアリング文化を構築し、ユーザー満足度の向上と持続的な成長を実現することができます。
本ガイドを参考に、各組織の特性や課題に合わせたSLO導入戦略を策定し、段階的かつ継続的な改善を進めていくことをお勧めします。SLOの導入は終わりのない旅ですが、その過程で得られる学びと成果は、組織とサービスの価値を大きく高めることでしょう。
希少なSRE人材が提供する高品質なSREサービス = Sreake
これはあくまでSLI、SLO、エラーバジェット導入の前に知っておきたいことです。実際の導入する際には更にいくつも考えること調整すべきことがあります。もし貴社が、社内のインフラエンジニアリソースを活用して、SLI/SLO/エラーバジェットの導入を検討しているのであれば、当社がご支援いたします。
当社のSREサービス「Sreake」は、SLI/SLO/エラーバジェットの導入と運用をサポートすることで、お客様企業が構築・運営するサービスの信頼性強化をご支援しています。 例えば、「今後、自社のエンジニアを核としてSLI/SLO/エラーバジェットを導入したいが、具体的な方法論や経験が不足している」といった場合に、Sreakeのメンバーが「効果的なSLI/SLO/エラーバジェット管理のための基盤づくり」を行うことで、導入の迅速化とコスト削減を実現するお手伝いをいたします。
具体的には、適切なSLIの選定、現実的なSLOの設定、エラーバジェットの効果的な管理方法、モニタリング・アラートシステムの構築など、SLI/SLO/エラーバジェット実践の要諦を、貴社の文脈に合わせて提供いたします。 また、データドリブンな意思決定文化の醸成、開発チームとの協働促進など、組織文化の変革もサポートいたします。 Sreakeのメンバーは、SLI/SLO/エラーバジェットの実践における第一人者として豊富な経験と知見を持ち合わせています。その専門性を活かして、貴社のインフラエンジニアの皆様がSLI/SLO/エラーバジェットを効果的に活用し、自立したSREチームとして機能できるようになるまで、伴走させていただきます。
ぜひお問い合わせをいただき、今後貴社が実現したい信頼性目標について共有くださいSLI/SLO/エラーバジェットの導入という旅路を、どこから、どのように歩んでいくべきか。 目標達成のために何を行うべきかについて、Sreakeのプロフェッショナルが、貴社の状況を踏まえて具体的にご提案差し上げます。
SLI/SLO/エラーバジェットの導入と運用の道のりは平坦ではありませんが、その先にあるのは、高い信頼性と俊敏性を兼ね備えた、まさに理想的なシステム運用の姿です。 インフラエンジニアの皆様のスキルと経験を活かしつつ、SLI/SLO/エラーバジェットという新たな領域にチャレンジする。その実現に向けて、Sreakeが貴社の挑戦を全力で支援させていただきます。