
1. はじめに
はじめまして、Sreake事業部の井上 秀一です。私はSreake事業部にて、SREや生成AIに関するResearch & Developmentに従事しています。
Google Cloudをはじめとするクラウド環境の運用において、gcloudコマンドや複雑なクエリ構文(MQLやLoggingのフィルタなど)を習熟する負荷は無視できません。特に新規参入者にとって、必要な情報を引き出すための「作法」を覚えることは大きな障壁となります。
この様な課題の中、クラウド運用の障壁を乗り越えるためのアプローチとして、本Blogでは、「対話型o11y AI Agent」を提唱します。
具体的には、Agent Development Kit(ADK)を使ったAIAgentと、observability-mcp の組み合わせです。AIAgentに「Google Cloudを観察する目と手」を与えることで、私たちは自然言語を通じて対話的にオブザーバビリティ(o11y)を実行できるようになります。
- ドキュメントがAgentの知恵に: トラブルシューティングの手順がプロンプトや内部ドキュメントとして整理されているほど、Agentは高度な自律性を発揮します。
- 横断的な調査の自動化: Agentがログ、メトリクス、トレースを自律的に横断して調査し、人間が理解しやすい形に要約します。
- 人間は「意思決定」に集中する: 複雑なデータ収集はAgentに任せ、人間は提示された要約に基づいた最終的なビジネスジャッジ(修正方針の決定など)に専念できる環境を構築できます。
2. 主要コンポーネントの紹介
今回のBlogで利用する主要な技術コンポーネントを紹介します。
Agent Development Kit(ADK)
ADKは、Googleが公開しているOSSで、高度なAIAgentを構築・評価・デプロイするためのフレームワークです。
- Agentを部品化して組み合わせ、開発・デプロイ・評価を効率化できるよう設計されています。
- MCPへの柔軟なツール接続:
MCPToolsetを備えており、MCPサーバーを介して外部の機能を簡単にツールとして取り込むことができます。
observability-mcp
observability-mcpは、Googleが提供する gcloud-mcp リポジトリに含まれる、Google Cloud Observability APIへのアクセスを提供するMCPサーバーです。observability-mcpにはログ、メトリクス、トレース、アラートポリシーなどを操作・取得するための多様なツールが提供されています。2026年1月時点で提供されているツールの一覧は以下の通りです。
| ツール名 | 説明 |
|---|---|
| list_log_entries | プロジェクトからログエントリをリスト表示する |
| list_log_names | プロジェクトからログ名をリスト表示する |
| list_buckets | プロジェクトからログバケットをリスト表示する |
| list_views | プロジェクトからログビューをリスト表示する |
| list_sinks | プロジェクトからログシンクをリスト表示する |
| list_log_scopes | プロジェクトからログスコープをリスト表示する |
| list_metric_descriptors | プロジェクトのメトリクス記述子をリスト表示する |
| list_time_series | 指定されたメトリクスの時系列データをリスト表示する |
| list_alert_policies | プロジェクト内のアラートポリシーをリスト表示する |
| list_traces | プロジェクト内のトレースを検索する |
| get_trace | プロジェクト内の特定のトレースをIDで取得する |
| list_group_stats | プロジェクトのエラーグループをリスト表示する |
observability-mcp をAI Agentに持たせる事で、Cloud Logging / Monitoring / Trace / Error Reporting といった情報を、AI Agentが直接操作・取得 できるようになります。
AI Agentは以下のような典型的なシナリオにおいて、人と協業しつつ、自然言語ベースで調査を進められると仮説を立てられます。
シナリオ: 障害発生時(エラー増加・サービス影響が疑われる)
ログ(Logging)でできること
- 障害発生時刻前後のエラーログを条件付きで横断検索できる
- 特定サービス・リビジョン・Pod などに絞ってログを抽出できる
- 直近で急増しているエラーメッセージや例外を特定できる
- ログの保存先や転送先を確認し、調査対象ログの所在を把握できる
メトリクス(Metrics)でできること
- エラー率・リクエスト数・レイテンシなど主要指標の変化を確認できる
- 障害発生前後でメトリクスを比較し、異常が出始めたタイミングを特定できる
- 複数サービスのメトリクスを並べ、影響範囲を把握できる
トレース(Tracing)でできること
- エラーを含むリクエストのトレースを検索できる
- 処理時間が急増しているスパンを特定できる
- アプリ・DB・外部 API のどこで詰まっているかを切り分けできる
エラー分析(Error Reporting)でできること
- 障害と関連するエラーグループを一覧化できる
- 影響の大きいエラーを優先度順に把握できる
シナリオ: パフォーマンス劣化の調査(遅い・重いと感じられている)
メトリクス(Metrics)でできること
- レイテンシ・CPU・メモリ使用量の長期推移を確認できる
- 徐々に悪化している指標を特定できる
トレース(Tracing)でできること
- 高レイテンシなリクエストトレースを抽出できる
- ボトルネックとなっている処理ステップを特定できる
ログ(Logging)でできること
- タイムアウトやリトライに関連するログを抽出できる
- パフォーマンス劣化に関連する警告ログを確認できる
シナリオ: リリース後の影響確認(デプロイ直後)
ログ(Logging)でできること
- 新リビジョン・新バージョンに紐づくログのみを抽出できる
- デプロイ後に新しく出始めたエラーを検知できる
メトリクス(Metrics)でできること
- デプロイ前後でエラー率・レイテンシを比較できる
- トラフィック増加やリソース使用量の変化を確認できる
トレース(Tracing)でできること
- 新コードパスを通るトレースを確認できる
- 新旧処理の実行時間差を把握できる
シナリオ: 日常運用・ヘルスチェック
メトリクス(Metrics)でできること
- サービスの平常時のベースラインを把握できる
- 異常検知の前兆となる指標変化を見つけられる
ログ(Logging)でできること
- 定常的に出ている警告・注意ログを把握できる
- ノイズとなっているログを洗い出せる
エラー分析(Error Reporting)でできること
- 未解消のエラーを継続的に把握できる
- 技術的負債となっているエラーを可視化できる
Vertex AI Agent Engine
Vertex AI Agent Engineは、AI Agentを本番環境で Deploy / 管理 / スケール するためのマネージド基盤であり、インフラ運用の多くをGoogle Cloud側に委譲できます。特に、Runtimeだけでなく、Sessions(会話コンテキスト管理)、Memory Bank、Code Execution、Observabilityまで含めて、運用を一気通貫で扱える点が特徴です(公式概要)。
フレームワーク連携ではADKがフル統合対象として位置づけられており、今回のようなADKベースAgentのデプロイ先として自然な選択肢です(対応フレームワーク)。
Gemini Enterprise
Gemini Enterprise は、企業内データを横断検索できるイントラネット検索、対話型AIアシスタント、そしてAgentプラットフォームを統合したサービスです。Confluence / Jira / SharePoint / ServiceNow など主要SaaSへのコネクタを備え、権限を考慮した回答生成や検索が可能です(What is Gemini Enterprise?)。
運用観点では、Gemini Enterpriseの管理者がAgent Galleryを通じて、Google提供Agentと組織独自Agent(ADK Agent、A2A Agentなど)を管理できます。特に本Blogに関連する点として、Vertex AI Agent EngineにデプロイしたADK AgentをGemini Enterpriseへ登録して利用可能です。登録時は reasoningEngines/{ADK_RESOURCE_ID} 形式のリソースパスを指定し、Agent側ロケーションとの整合も必要です(Agents overview, ADK Agent登録手順)。
3. ADKでの利用方法
ここではADKでの利用方法を説明します。本プロジェクトでは、ADK AgentがMCPを直接stdio起動するのではなく、Cloud Run上で動作する統合MCP Proxy(gcloud-mcp + observability-mcp)へ MCP_PROXY_URL 経由で接続します。フォルダ構成を以下に示します。この構成は公式の推奨構成を改変しています。
.
├── agents
│ └── o11y_agent
│ ├── agent.py # ADK Agent本体
│ └── prompts
│ └── o11y_analyzer.py # Prompt
└── gcloud_mcp
└── proxy_gcloud_mcp.py # Cloud Runにデプロイする統合MCP Proxy- agent.py: 以下のコードは、ADK Agentが
MCP_PROXY_URLで指定されたMCP Proxyへ接続して、Google Cloudの観測データを解析する構成例です。実データ取得や操作はMCP経由で行われます。
# agent.py
import os
import subprocess
import httpx
import vertexai
from dotenv import load_dotenv
from google.adk.agents.llm_agent import Agent
from google.adk.tools.mcp_tool import McpToolset
from google.adk.tools.mcp_tool.mcp_session_manager import StreamableHTTPConnectionParams
from .prompts import o11y_analyzer as o11y_analyzer_prompt
load_dotenv(".env")
MCP_PROXY_URL = os.environ.get("MCP_PROXY_URL", "<http://localhost:8080/mcp>")
TOOL_TIMEOUT = 300
def get_identity_token() -> str:
result = subprocess.run(
["gcloud", "auth", "print-identity-token"],
capture_output=True,
text=True,
check=True,
)
return result.stdout.strip()
def create_authenticated_httpx_client(
headers: dict[str, str] | None = None,
timeout: httpx.Timeout | None = None,
auth: httpx.Auth | None = None,
) -> httpx.AsyncClient:
token = get_identity_token()
merged_headers = {"Authorization": f"Bearer {token}"}
if headers:
merged_headers.update(headers)
return httpx.AsyncClient(
headers=merged_headers,
timeout=timeout or httpx.Timeout(TOOL_TIMEOUT),
auth=auth,
)
vertexai.init(
project=os.environ["GOOGLE_CLOUD_PROJECT"],
location=os.environ["GOOGLE_CLOUD_LOCATION"],
staging_bucket=f"gs://{os.environ['GOOGLE_CLOUD_PROJECT']}",
)
if MCP_PROXY_URL.startswith("https://"):
connection_params = StreamableHTTPConnectionParams(
url=MCP_PROXY_URL,
timeout=TOOL_TIMEOUT,
sse_read_timeout=TOOL_TIMEOUT,
httpx_client_factory=create_authenticated_httpx_client,
)
else:
connection_params = StreamableHTTPConnectionParams(
url=MCP_PROXY_URL,
timeout=TOOL_TIMEOUT,
sse_read_timeout=TOOL_TIMEOUT,
)
root_agent = Agent(
model="gemini-2.5-flash",
name="o11y_analyzer",
description="The Agent specialized in analyzing observability data from Google Cloud Trace.",
instruction=o11y_analyzer_prompt.instruction(),
tools=[
McpToolset(
errlog=None,
connection_params=connection_params,
)
],
)- proxy_gcloud_mcp.py: 以下のコードは、Cloud Runにデプロイする統合MCP Proxyです。
gcloud-mcpとobservability-mcpをFastMCPで束ね、ADK側からは単一の/mcpエンドポイントとして扱います。
from fastmcp import FastMCP
from fastmcp.client.transports import NpxStdioTransport
from fastmcp.server import create_proxy
gcloud_proxy = create_proxy(
NpxStdioTransport(package="@google-cloud/gcloud-mcp"),
name="gcloud-mcp",
)
observability_proxy = create_proxy(
NpxStdioTransport(package="@google-cloud/observability-mcp"),
name="observability-mcp",
)
proxy = FastMCP(name="gcp-mcp-proxy")
proxy.mount(gcloud_proxy, namespace="gcloud")
proxy.mount(observability_proxy, namespace="o11y")
if __name__ == "__main__":
proxy.run(
transport="streamable-http",
host="0.0.0.0",
port=8080,
stateless_http=True,
json_response=True,
)- Cloud Runに載せるMCP Proxy運用の要点
transport="streamable-http"+stateless_http=True+json_response=Trueを有効化し、サーバーレス環境でのSSEセッション切断影響を回避します。NpxStdioTransportでNode.jsプロセスを起動するため、Cloud Run側リソース(メモリ/CPU)は余裕を持って設定します。Cloud Runを認証付きで公開する場合、ADK側はMCP_PROXY_URLをhttps://...に設定し、IDトークン付きリクエストで接続します。ローカル検証時はmake mcp-serverで同じProxyを起動できます(http://localhost:8080/mcp)。Cloud Buildでのデプロイはcloudbuild.yaml(サービス名gcloud-mcp)で管理しています。例として、以下のようなCloud Run設定を適用すると安定しやすくなります。
gcloud run services update ${MCP_CLOUD_RUN_SERVICE} \
--region=${GOOGLE_CLOUD_REGION} \
--project=${GOOGLE_CLOUD_PROJECT} \
--ingress=all \
--timeout=3600 \
--min-instances=1 \
--memory=2Gi \
--cpu=1- o11y_analyzer.py: 以下のコードは、Agentへのプロンプトやツールの使い方を補足するものです。用途やニーズに合わせて改変することを推奨します。
import os
import time
CURRENT_TIME = time.strftime("%Y-%m-%dT%H:%M:%SZ", time.gmtime())
def instruction():
return f"""
## Your Role:
You are a Observability Analyzer. Your primary role is to assist users in analyzing and interpreting observability data (traces, spans, performance metrics, logs) from Google Cloud.
## Notes on Tool Usage
- list_traces:
- pagesize: set pagesize to retrieve 1000 items at a time.
- filter: You can filter traces by various attributes such as span names, latency thresholds, time ranges, and resource types to narrow down your analysis.
## Output Format
- Markdown
- Attach the reasons determined during analysis and the relevant logs
- Example
```
- Event: xxxx
- Reason: xxxx
- Log content: `xxxx`
```
## Information:
Current time: {CURRENT_TIME}
Google Cloud Project ID: {os.environ["GOOGLE_CLOUD_PROJECT"]}
"""Agent EngineへのDeploy時の注意事項
McpToolsetを含むAgentのデプロイ時にシリアライズ失敗となる既知問題があるため、本プロジェクトではワークアラウンドとして errlog=None を指定しています。
Agent Engine側では、MCP接続先を env_vars で注入します。
一部の構成では、Agent Engine側にも追加パッケージやインストールスクリプト(extra_packages / build_options)の準備が必要です。 https://docs.cloud.google.com/agent-builder/agent-engine/deploy#build-optionshttps://docs.cloud.google.com/agent-builder/agent-engine/deploy#extra-packages
from vertexai import agent_engines
...
env_vars = {
"MCP_PROXY_URL": "${MCP_PROXY_URL}",
"GOOGLE_CLOUD_PROJECT": "${GOOGLE_CLOUD_PROJECT}",
}
remote_app = agent_engines.create(
agent_engine=adk_app,
requirements=self.requirements,
display_name=self.name,
description=self.root_agent.description,
env_vars=env_vars,
extra_packages=["installation_scripts/install.sh"],
build_options={"installation_scripts": [
"installation_scripts/install.sh"]},
** kwargs,
)
...4. 実際動かしてみる
ここでは、adk_o11y/agents/sample_agent を「意図的に失敗するAgent」として使い、adk_o11y/agents/o11y_agent で簡単なトラブルシュートを行います。狙いは、壊れたAgentを別Agentで観測・診断する最小構成を確認することです。
sample_agent には以下のToolがあります。search_book が必ず ValueError を送出するため、Tool呼び出し時にエラーが発生します。
def search_book(query: str) -> str:
raise ValueError(" database connection error.")
全体像として次のようになります。
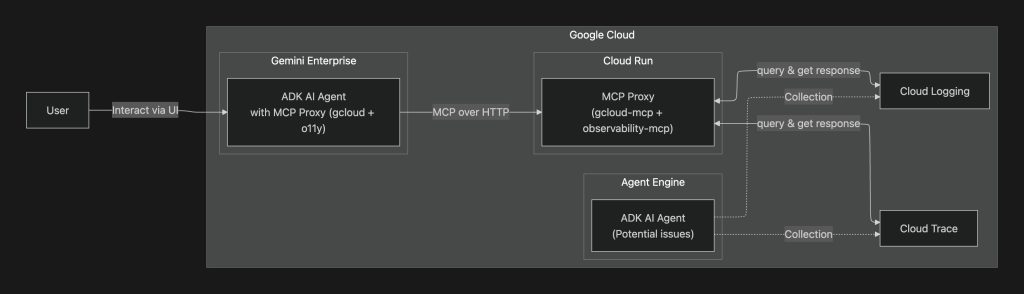
sample_agentの説明
sample_agent は、トラブル再現用の最小Agentです。search_book というToolを持っていますが、実装では意図的に例外を投げます。そのため、Toolが呼ばれると必ず失敗し、ログとトレースに異常系イベントが残ります。
def search_book(query: str) -> str:
"""Search for a book in the library database."""
raise ValueError(" database connection error.")
return f"Found book matching '{query}' in the library database."
root_agent = Agent(
model="gemini-2.5-flash",
name="sample_agent",
description="A sample agent that demonstrates error handling when a tool fails.",
instruction="Answer user questions to the best of your knowledge",
tools=[
search_book,
],
)
Demo
AgentをAgent EngineにDeployします。Vertex AI Agent Engine の Playground で sample_agent を開き、Toolが使われる質問を投げます。この時点で、Cloud Logging / Cloud Trace 側に失敗イベントが蓄積されます。
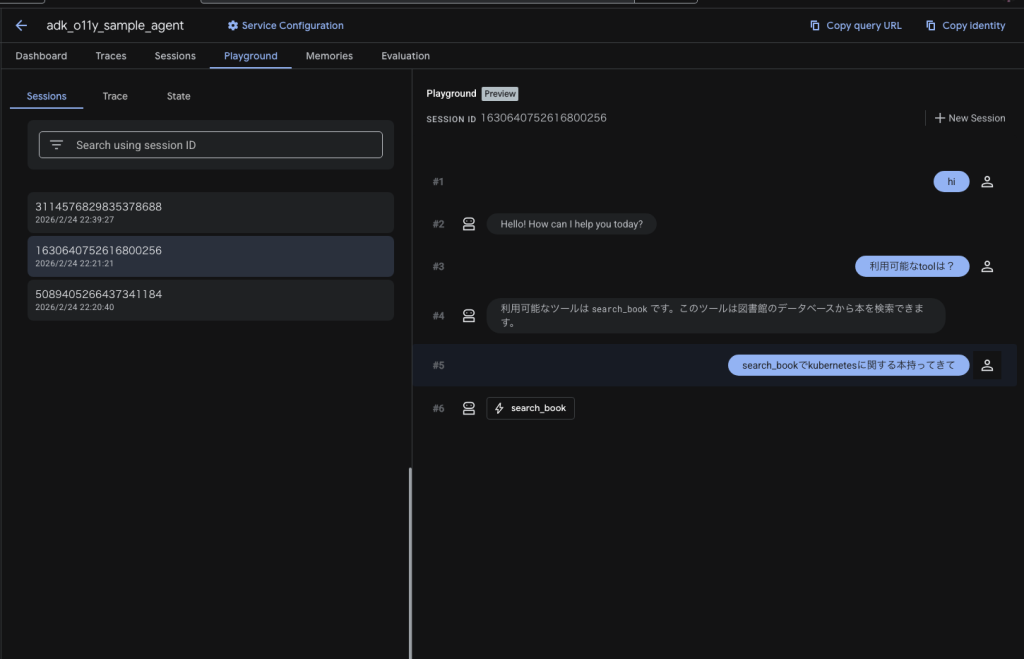
Tracesタブに移動してTrace IDを取得します。
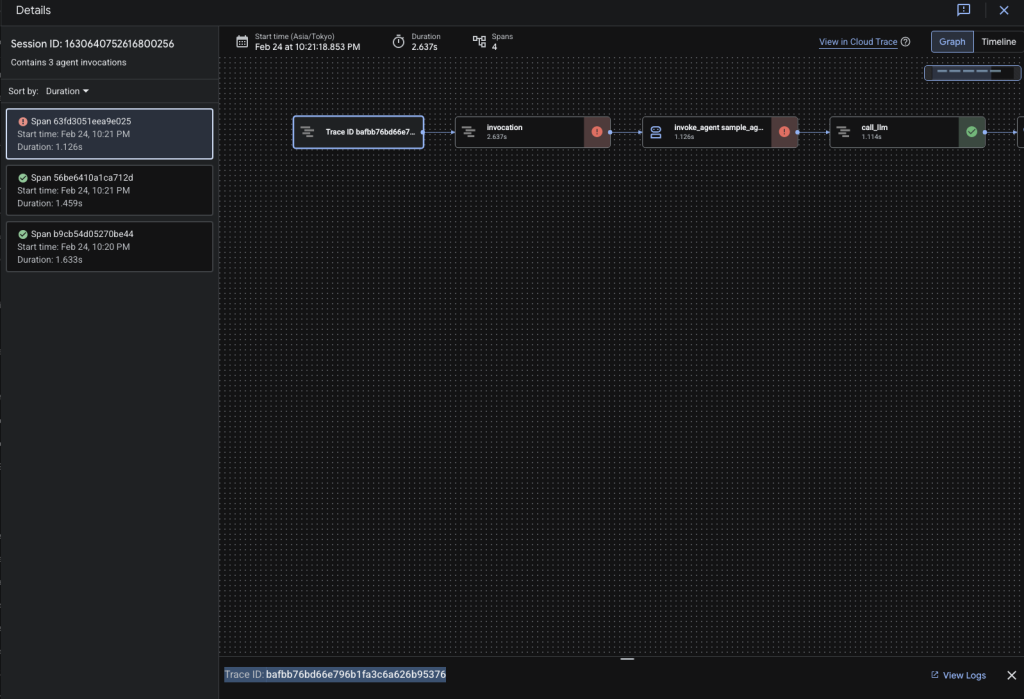
Gemini EnterpriseからAgent(o11y_agent)にQueryを投げます。
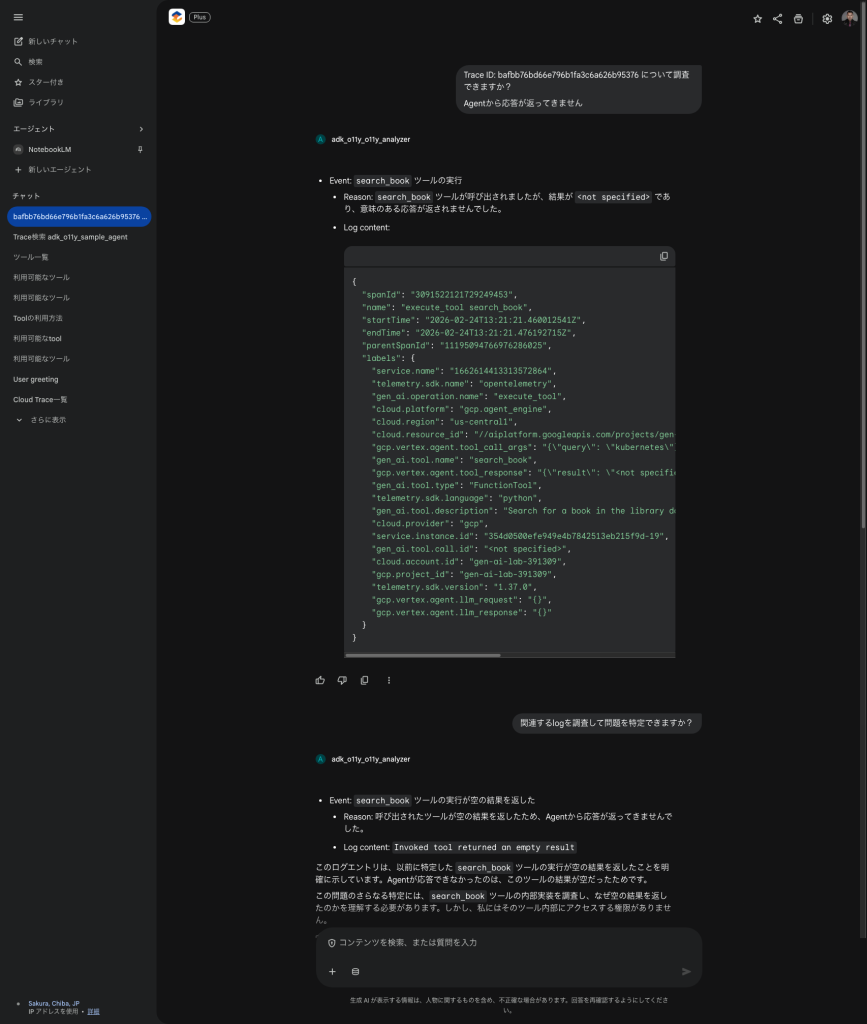
与えられているMCPツールの範囲で調査を行ってくれます。
Traceの言語化や関連するLogの調査を行い、人間側に噛み砕いて説明してくれるため、経験豊富なメンバーでなくても、生産性向上に寄与する事ができます。
5. 実運用観点で考慮するべきこと
observability-mcp を用いると、ログ・メトリクス・トレースといったデータ量の多い情報を直接扱えるようになります。その一方で、これらのデータを無造作にAgentへ渡すと、LLMのコンテキスト長を容易に超過し、分析精度の低下や意図しない要約・脱落が発生します。そのため、実運用ではコンテキストエンジニアリングがほぼ必須となります。
具体的には、以下の設計が重要になります。
- ダイレクトにLogに紐づくような情報(e.g. Trace ID)を渡す前提、もしくは、広い条件で傾向を把握し、その後に時間範囲・対象リソース・エラー種別などを段階的に絞り込む
- 生ログやトレース全文をそのまま渡すのではなく、代表例・要約・件数・発生傾向といった形に整理してから次の推論に進ませる
- 調査フェーズごとに「何を知るための情報か」を明示し、不要なデータをコンテキストに含めない
また、すべての用途を1つの汎用Agentで賄おうとすると、プロンプト、利用するツールや調査手順のコンテキストが増加する、といった問題が発生します。
そのため、ADKであれば、用途別にオプトインしたAgentを用意する構成が有効です。
例えば、
- 障害調査向け
- パフォーマンス分析向け
- リリース後影響確認向け
といった形で、目的・参照データ・調査手順を限定したAgentを用意することで、コンテキスト消費量を低減したり、Agentの精度向上につながります。
6. まとめ
本Blogでは、複雑化するクラウド環境のo11yにおける学習コストや属人化の課題に対し、ADKとobservability-mcpを組み合わせた「対話型o11y AI Agent」の構築アプローチをご紹介しました。
gcloudコマンドやMQLといった専門的なクエリの習熟という高いハードルをAI Agentが吸収することで、新規参入者であっても自然言語を通じて高度なトラブルシューティングやパフォーマンス分析が可能になります。これにより、私たちは「ログやメトリクスの検索・収集」といった作業から解放され、「提示された情報に基づく事象の判断とビジネス上の意思決定」という、人間本来が集中すべきタスクに専念できるようになります。
一方で、第5章で触れたように、実運用に向けてはLLMのコンテキスト長を考慮した「コンテキストエンジニアリング」や、用途に応じた「特化型Agentの分割設計」が成功の鍵を握ります。ただツールとAIを繋ぐだけでなく、「AIがいかに効率よく、正確にデータを解釈できるか」を設計することが、これからの新たなミッションになっていくでしょう。
生成AIとオブザーバビリティの融合は、まだ大きな可能性を秘めています。今回の構成例が、皆様の組織におけるクラウド運用の高度化や、開発者の認知負荷軽減の一助となれば幸いです。