
はじめに
2026年2月から3月末までの期限付きのインターンとして金古さんに参画いただきました。
インターン期間中に執筆いただいた記事をお届けします。
再起動したくない、でもリソースを変えたい
今回は EKS 1.35 + VPA 1.6.0 の環境で、In-Place Pod Resize を実際に試してみました。最近この機能が気になっていて、「本当に再起動なしでどこまで行けるのか」を自分で確かめてみたかった、というのがこの記事を書いた動機です。なので「機能紹介」よりも、「どこまで動いて、どこで詰まるのか」の記録に近いです。
数時間かかるジョブが動いている。前半の軽い処理が終わり、ここから本番の重い集計に入る。CPU をもっと使わせたい。しかし Pod を再作成すれば、また最初からやり直しになる。
ロードに数分かかるサービスがある。リクエスト量が増えてきて、memory が足りなくなりそうだ。でも Pod を作り直すたびにコールドスタートが発生し、その間のリクエストは詰まる。
こうした「再起動コストが高く、かつリソース需要が変動するワークロード」では、従来の Kubernetes のリソース変更は扱いづらい場面がありました。リソースを変えるには Pod を作り直すしかなく、それは再起動・再スケジュール・インメモリ状態の喪失を意味します。
In-Place Update of Pod Resources(KEP-1287) はこの制約を取り払い、稼働中の Pod を再起動・再スケジュールせずに CPU / memory を動的に変更できる機能です。v1.27 で Alpha、v1.33 で Beta、v1.35(2025年12月)で GA に到達しました。
実際に試してみると、単に「再起動なしで変えられる」だけではなく、アプリ側の制約やノード容量、VPA の反応速度、QoS の扱いなど、いくつか明確な壁も見えてきました。
先に結論を書くと、In-Place Pod Resize は「何でも無停止で変えられる」機能ではありません。
NotRequiredならかなり速く反映される一方、ノードの空き、メモリ削減時の OOM リスク、QoS、VPA の制御周期で普通に詰まります。
3行まとめ
| 見たいこと | 結論 |
|---|---|
| 手動 resize はどこまで無停止で動くか | 手動の CPU resize と、VPA 経由の memory 増加は、今回の環境では約 1 秒・再起動なしで反映されました |
| 何が詰まりどころか | Deferred/ Infeasible / VPA の制御ループ遅延(3〜4 分) / QoS 変更が主な壁。メモリ limit 削減時の OOM リスクにも注意が必要でした |
| どんな用途に向くか | 秒単位のスパイク対策より、再起動コストが高いワークロードのベースライン調整に向いていました |
この記事の前提
| 項目 | 内容 |
|---|---|
| 検証環境 | EKS 1.35.2-eks-f69f56f / VPA 1.6.0 / AL2023 / t3.medium × 2 |
| 想定読者 | Kubernetes と VPA の基本を知っていて、In-Place Resize の実運用感を知りたい人 |
| 今回確認した範囲 | Linux ノード上での手動 resize、VPA InPlaceOrRecreate、QoS / Deferred / Infeasible の挙動 |
| 今回は扱わない範囲 | Windows Pod、restartable init container / ephemeral container、swap 利用、Pod-level resources Alpha の実運用までは検証していません |
なぜ再起動なしでリソースを変えられるのか
cgroup は「外側」から制御する
根本的な理由は、cgroup のリソース制御がプロセスの「外側」でカーネルが行う仕組みだからです。
コンテナは VM ではなく、Linux の namespace + cgroup が適用されたプロセスです。cgroup v2 では cpu.max や memory.max のようなインターフェースファイルが公開されていて、これらへの write が controller の状態更新のトリガーになります。cgroup v2 のファイルインターフェース自体は Linux kernel の cgroup v2 documentation にまとまっています。
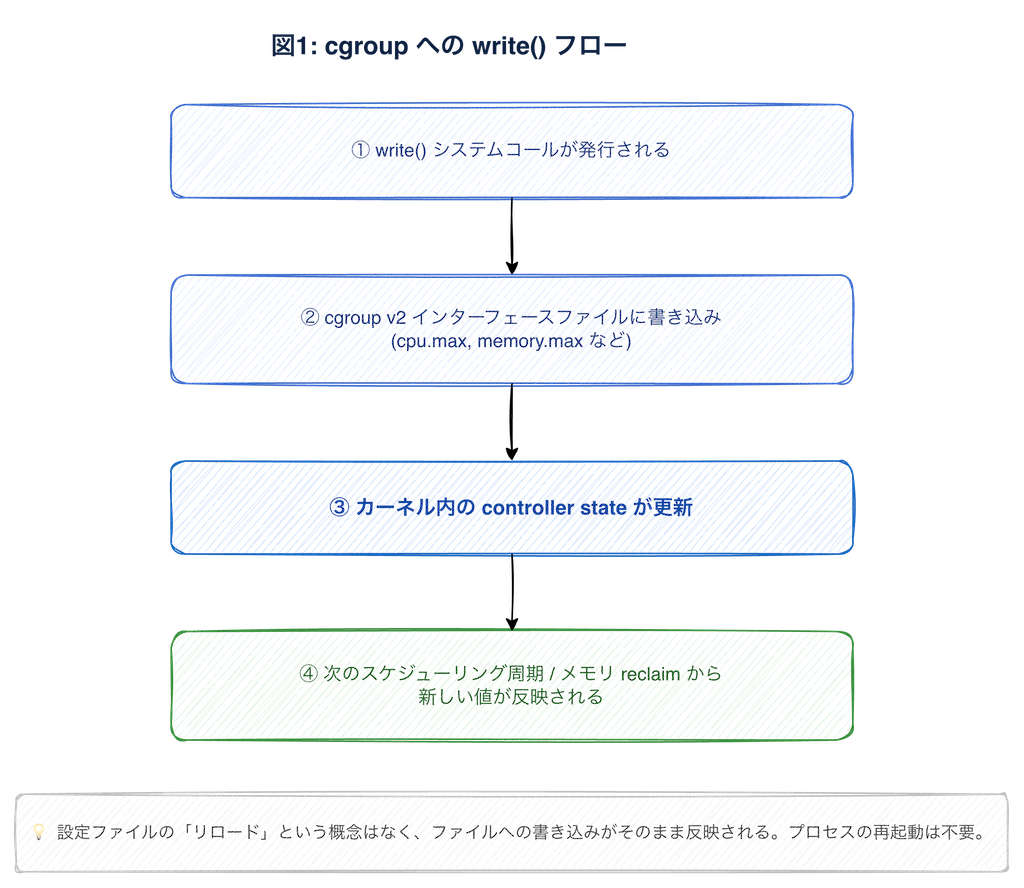
設定ファイルの「リロード」という概念はなく、書き込みがそのまま制御に反映されます。CPU 制限は次の quota period から効き始める一方、memory.max は hard limit なので、下げた瞬間に reclaim や OOM が起こりえます。
つまり cgroup はもともと動的変更を前提に作られていて、コンテナのリソース上限はプロセスの外から、プロセスを止めずに書き換えられます。In-Place Resize はこの能力を Kubernetes が安全に使えるようにしたもの、と捉えると分かりやすかったです。
CPU とメモリで非対称なリスク
CPU は圧縮可能リソース(compressible resource) なので、変更は比較的安全です。CPU クォータを減らすと次の周期からスロットルが早まるだけで、プロセスは TASK_RUNNING 状態のまま生き続けます。OOM killer に相当する機構もありません。
メモリは非圧縮リソース(incompressible resource) で、CPU とはかなり性格が違います。増やす分には安全ですが、memory.max を使用量以下に設定するとカーネルはリクレイムを試み、失敗すると OOM killer が発動します。
kubelet の内部処理フロー
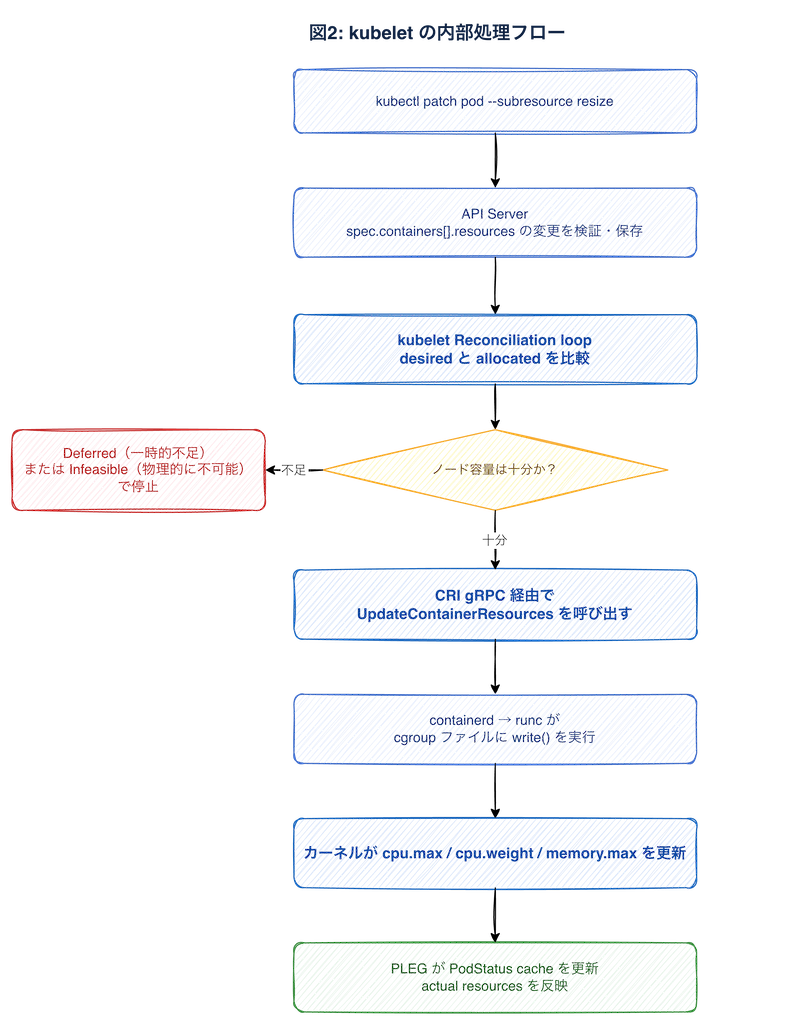
cgroup の更新順序は安全性のために厳密に制御されています。リソース増加時は Pod レベルの cgroup を先に拡大してからコンテナの制限を引き上げ、減少時は逆にコンテナの制限を先に縮小してから Pod レベルを縮小します。
resizePolicy: 再起動が必要かどうかを宣言する
resizePolicy:
- resourceName: cpu
restartPolicy: NotRequired # cgroup を直接更新(デフォルト)
- resourceName: memory
restartPolicy: RestartContainer # コンテナを再起動して反映RestartContainerが必要になるのは、JVM の-Xmx、Go のGOMEMLIMIT、Node.js の--max-old-space-size など、プロセス起動時にリソース上限を読み取ってキャッシュするアプリケーションです。こうしたアプリは cgroup の変更をその場では「感知」できないので、再起動しないと新しい値が反映されません。
まず試してみる: NotRequired での手動リサイズ
検証環境: EKS 1.35.2-eks-f69f56f / t3.medium × 2(AL2023)
resizePolicy: NotRequired の Pod で CPU request を変更します。
kubectl patch pod resize-cpu-test -n resize-test \
--subresource=resize --type=json \
-p '[{"op":"replace","path":"/spec/containers/0/resources/requests/cpu","value":"500m"}]'5s Normal ResizeStarted
5s Normal ResizeCompleted
✅ Restart count unchanged (0)
✅ Container ID unchanged
✅ Marker file preserved
✅ CPU request updatedrestartCount・containerID・マーカーファイルはすべて変化なしでした。約 1 秒で、再起動なしに完了したのを見て、cgroup への write() がかなり素直に反映されていることが分かりました。
正直、ここはもっと kubelet の再調停待ちで引っかかると思っていたので、拍子抜けするくらい素直でした。少なくとも今回の環境では、「手動 resize 自体はかなり速い」はかなり強く言えそうです。
⚠️ 注意:
--type=mergeを使うと未指定フィールドが削除されエラーになります。必ず--type=jsonで特定フィールドのみ変更してください
RestartContainer だとどうなるか
続けて、resizePolicy: RestartContainer を設定したコンテナでも試しました。CPU はNotRequired、memory はRestartContainer という組み合わせです。
| CPU リサイズ(NotRequired) | メモリリサイズ(RestartContainer) | |
|---|---|---|
| restartCount | 変化なし ✅ | +1 |
| containerID | 変化なし ✅ | 変化あり |
| ファイルシステム | 保持 ✅ | リセット |
| Pod UID | 変化なし ✅ | 変化なし ✅ |
RestartContainerの場合、Pod は作り直されない(Pod UID は保持、IP やボリュームは維持)が、コンテナは再起動します。In-Place Resize の恩恵は「同じノードに留まれること」にかなり限定される印象でした。
JVM や Go のような runtime を使うアプリが memory のRestartContainer を必要とする場合、コールドスタート自体は避けられません。ただ、「ノードに留まる」だけでも、IP やボリュームの維持、再スケジュールの回避といった部分的な恩恵はありそうです。
⚠️ メモリ limit 削減時の注意: kubelet はメモリ limit を下げる前に
memory.currentを読んで使用量が新しい limit 未満かチェックします。ただし、このチェックと実際の cgroup 書き込みの間には CRI 呼び出し等の手順が挟まるため、TOCTOU(Time-of-Check to Time-of-Use) の問題があります。チェック通過後にメモリ使用量がスパイクすると、memory.maxが書き込まれた時点で使用量が limit を超えており OOM Kill が発動します。この問題は kubernetes/kubernetes#135670 で追跡されており、ランタイム側でチェックと書き込みをほぼアトミックにする改善が提案されています。メモリ limit の削減方向は CPU とは違ってリスクがあるため、慎重に行う必要があります。
手動リサイズで見えた壁
壁 1: ノードに空きがない —Deferred
次の壁は、ノードのリソースが足りない場合です。
ノードのリソースを意図的に埋め、リサイズが通らない状態を作りました。
ノード Allocatable CPU: 1930m
Filler Pod で大半を埋める → 空き 200m 未満
リサイズ要求: 250m → 550m(+300m 必要)kubectl patch pod resize-cpu-test -n resize-test \
--subresource=resize --type=json \
-p '[{"op":"replace","path":"/spec/containers/0/resources/requests/cpu","value":"550m"}]'{
"type": "PodResizePending",
"status": "True",
"reason": "Deferred"
}Filler Pod を削除してリソースを解放すると:
[PASS] Resize completed automatically after resources were releasedDeferred は「今はできないが、空きができれば自動で完了する」状態でした。
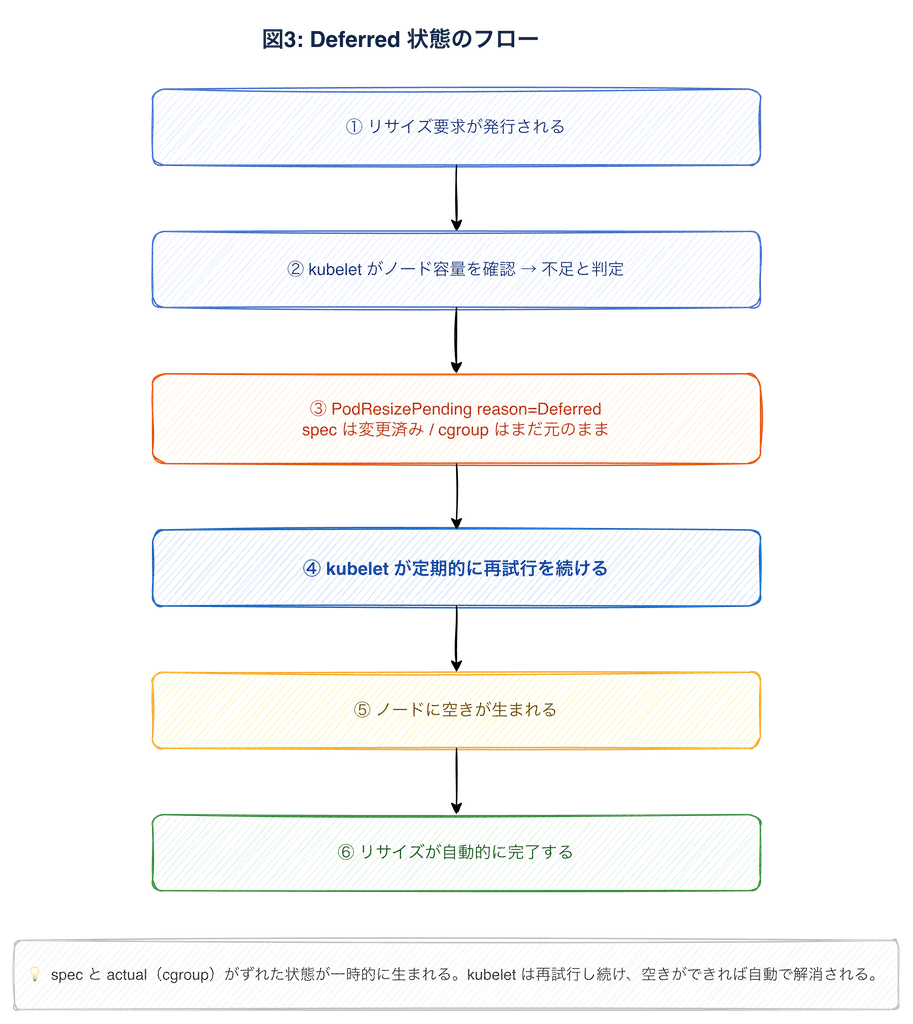
注意が必要なのは、spec はすでに変更済みなのに cgroup(actual)はまだ変わっていないという状態が生まれることです。kubectl get pod で見るとリソース値がずれたように見えますし、ノードが慢性的に逼迫している環境だと Deferred のまま長期間放置されるリスクもあります。
壁 2: そもそも無理なサイズ —Infeasible
Deferred よりも深刻だったのがInfeasible です。ノードの物理キャパシティ自体を超えるリソースを要求すると、この状態になります。
ノード Allocatable CPU: 1930m
要求した CPU: 2430m(500m オーバー){
"type": "PodResizePending",
"status": "True",
"reason": "Infeasible"
}# spec と status がずれたまま固定される
# 2430m (spec) vs 250m (actual)| Deferred | Infeasible | |
|---|---|---|
| 原因 | 一時的なリソース不足 | ノードキャパシティを超えている |
| 自動解決 | 空きができれば自動再試行 ✅ | 解決しない(値の修正が必要) |
| 対処 | 待つ・他 Pod を縮小する | リソース要求値を下げる |
Infeasible になると kubelet は再試行しません。誤った値を入れると spec と actual がずれたまま残るので、spec を正しい値に戻す patch を別途打つ必要があります。
たとえば今回の例なら、次の patch で 250m に戻せば復旧できます。
kubectl patch pod resize-cpu-test -n resize-test \
--subresource=resize --type=json \
-p '[{"op":"replace","path":"/spec/containers/0/resources/requests/cpu","value":"250m"}]'VPA と組み合わせて自動化する
手動パッチで動くことは確認できたので、次は VPA(Vertical Pod Autoscaler) と組み合わせて自動化を試してみます。
VPA とは
VPA は Pod の実際のリソース使用量を観測し、request / limit を自動調整してくれる Kubernetes のアドオンです。HPA が Pod の台数を水平に増減させるのに対し、VPA は個々の Pod のリソースサイズを垂直に調整します。主に 3 つのコンポーネントで構成されています。
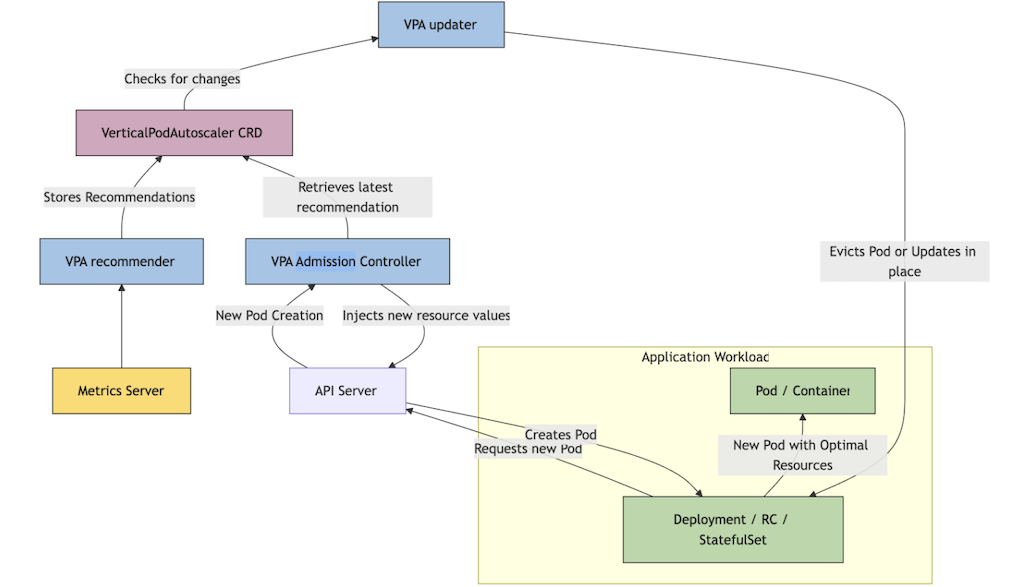
Ref: Vertical Pod Autoscaler | Kubernetes
- Recommender: metrics-server 等からメトリクスを収集し、推奨リソース量を算出する
- Updater: 現在の Pod のリソースと推奨値を比較し、乖離が大きければリサイズを実行する
- Admission Controller: Pod 作成時に MutatingWebhook で spec を推奨値に書き換える
VPA が解決する課題は「最初に設定した request / limit がずっと適切とは限らない」という点です。たとえば、最初は cpu: 100m で十分だったサービスが、機能追加やトラフィック増で慢性的にスロットリングするようになった場合、VPA がメトリクスに基づいて request を引き上げてくれます。
ひとつ注意点として、Recommender の推奨値は稼働中のリサイズだけでなく Pod 作成時にも適用されます。Admission Controller が Pod 起動前に spec を書き換えるため、マニフェストに cpu: 100m と書いても実際の Pod は推奨値の 25m で起動していました。VPA 有効環境では「マニフェストに書いた値」と「実際の Pod の値」がずれることがあるので、確認するときは kubectl get pod -o jsonpath='{.spec.containers[0].resources}' で実 Pod 側を見るのが安全です。
InPlaceOrRecreate モード
今回は VPA 1.6.0 の InPlaceOrRecreate モードを使いました。従来の VPA では updateMode: Recreate が主な選択肢で、リソースを変更するには Pod を evict して作り直す必要がありました。VPA がリソースを最適化してくれる代わりに、再起動コストは受け入れるしかなかったわけです。
InPlaceOrRecreate はこの制約を緩和するモードで、VPA 1.4.0 で Alpha、1.5.0 で Beta を経て、1.6.0 で GA になりました。Updater がまず in-place resize を試み、それが失敗した場合(QoS クラスの変更が必要な場合など)にのみ evict + recreate にフォールバックします。Kubernetes 側の In-Place Resize が GA になったことと合わせて、VPA 側にもこのモードが正式に入った形です。
インプレースリサイズは約 1 秒で完了した
RequestsAndLimits モードで memory リサイズを実行した結果:
# kubectl get events の出力(数値は age = 何秒前)
2m27s ResizeStarted memory: 128Mi → 250Mi
2m27s InPlaceResizedByVPA Pod was resized in place by VPA Updater.
2m26s ResizeCompleted ← age が 1s 減 = 1 秒後に完了
87s 2台目の Pod も順番に完了| Before | After | |
|---|---|---|
| Memory request | 128Mi | 250Mi |
| Memory limit | 128Mi | 250Mi |
| Pod UID | 変化なし ✅ | – |
| Restart count | 0 ✅ | – |
Pod の再起動なし・再作成なしでメモリ変更に成功しました。2 台の Pod は順番にリサイズされていて、Updater が一度に 1 台ずつ処理していることも分かります。
ここは想像以上に素直でした。recommendation が出てからの kubelet 側の反映自体は十分速く、ボトルネックは「in-place 更新そのもの」より前段の制御ループ側にありそうだと感じました。
RequestsOnly では limit が上限になる
controlledValues: RequestsOnlyを設定すると、VPA は requests のみを管理し、limits は変更しません。この状態で VPA が memory 250Mi を推奨しても既存の limit(128Mi)を超えて request を設定できないため、今回の検証では 128Mi に頭打ち になりました。
VPA 推奨: memory target = 250Mi
Pod の limit: 128Mi(変更されない)
→ request を limit 以上にできない
→ 実際に適用された request: 128Mimemory を大きく伸ばしたいなら、controlledValues: RequestsAndLimits + maxAllowed の組み合わせが必要そうでした。
VPA 連携で見えた壁
VPA で自動化できること自体は確認できましたが、手動 resize だけでは見えにくかった制約もありました。ここからは VPA と組み合わせたときに出てきた壁を見ます。
壁 3: リサイズまで 3〜4 分のラグがある — VPA のレイテンシ
次に気になったのは、負荷が始まってからリソースが実際に増えるまでの時間です。
CPU 負荷をかけた Pod(cpu request=50m)に対して、スロットリングの開始から実際のリサイズ完了までを 3 回計測しました。
| Run 1 | Run 2 | Run 3 | |
|---|---|---|---|
| recommendation 初回変化(T2) | t+56s | t+59s | t+59s |
| actual resize 完了(T3) | t+202s | t+230s | t+235s |
| recommendation →resize のラグ | 146s | 171s | 176s |
| ResizeStarted →Completed | 1s | 1s | 1s |
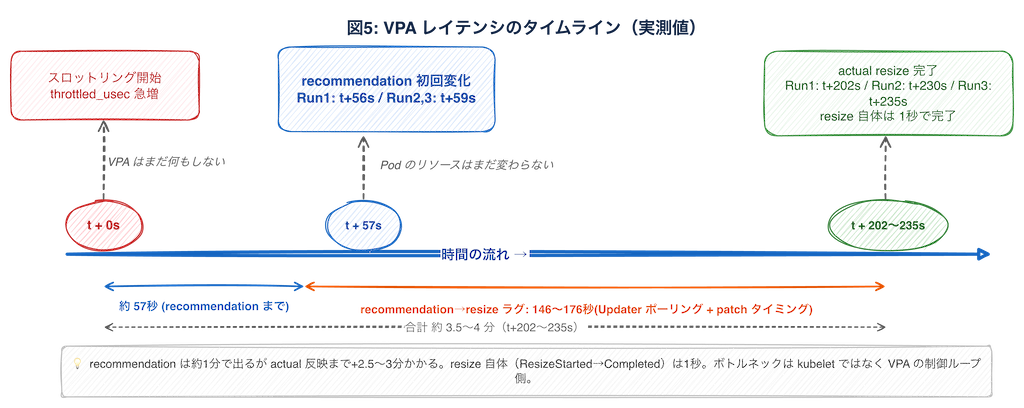
負荷開始から actual request の反映まで 約 3.5〜4 分。その間、スロットリングはずっと続いていました。recommendation 自体は約 1 分で出ていたので「お、意外と早い」と思ったのですが、Pod が実際に楽になるまではさらに 2.5〜3 分かかりました。3 回とも recommendation → actual resize のラグが最大の待ち時間で、この区間には Updater のポーリング間隔(デフォルト 1 分)と Pod eviction / patch の実行タイミングが重なっている可能性があります。一方で、kubelet が cgroup を書き換える resize 自体は 3 回とも 1 秒で完了しており、ボトルネックは kubelet ではなく VPA の制御ループ側にありそうです。
一方で、一定負荷が続いた場合の推奨値の収束は早めでした。30 分間の持続 CPU 負荷テストでは、t+5min の時点で 25m → 247m に収束し、その後は安定しました。「推奨値が際限なく増え続ける」挙動は今回の範囲では見えませんでした。
今回の検証を見る限り、VPA は秒単位のスパイクへの即応というより、継続する負荷のベースライン調整に向いていそうでした。急激なバーストへの即応が必要なら HPA(カスタムメトリクス)の方が合いそうですし、VPA と HPA を同じリソースメトリクス(CPU / memory)で同時に使うと競合します。VPA の使いどころについては Vertical Pod Autoscaler README の known limitations もあわせて見ると、判断しやすいです。
壁 4: QoS クラスが変わると Recreate になる
最後の壁は、QoS クラスの変更です。In-Place Resize では QoS クラスを変えることができません。
QoS クラスとは: requests == limits なら Guaranteed、requests < limits なら Burstable になります。RequestsOnly で request だけを下げると、limits はそのまま残るため Guaranteed → Burstable の変化が起きる場合があります。
今回の検証では、以下の VPA 設定で Guaranteed Pod に対して RequestsOnly を適用しました。
resourcePolicy:
containerPolicies:
- containerName: '*'
controlledValues: RequestsOnly # ← limits は変えない
controlledResources: ["cpu", "memory"]API server が拒否する:--dry-run=server で事前確認すると:
The Pod "fallback-test-app-..." is invalid:
spec: Invalid value: "Guaranteed": Pod QOS Class may not change as a result of resizingQoS クラス変更を伴う resize は、in-place では API server にはっきり拒否されました。
Updater が eviction + recreate にフォールバックした:
t+0s qos=Guaranteed recreated=false recommendation=false
t+60s qos=Guaranteed recreated=false recommendation=true
t+120s qos=Burstable,Guaranteed recreated=true evicted=truet+60s で VPA recommendation が出たあと、Updater は in-place resize を試みましたが API server に拒否されました。続いて EvictedByVPA が出て eviction + recreate にフォールバックしていて、Burstable,Guaranteed の混在は 2 台が順番に置き換えられている途中だと読めます。
"In-place resize failed, falling back to eviction"
error="Pod is invalid: spec: Invalid value: "Guaranteed":
Pod QOS Class may not change as a result of resizing"ただし、通常運用でこれが毎回発動するケースは多くなさそうです。
- Admission Controller が Pod 作成時に推奨値を書き込むため、requests が推奨値から大きく乖離しにくい
- フォールバックは eviction ベースなので、
replicas > minReplicasの余裕がないと動かない
この機能を使うべきワークロードの判断軸
今回の検証を通して、In-Place Resize + VPA が効くワークロードの輪郭はかなりはっきり見えてきました。
| ワークロードの特性 | In-Place Resize の適性 |
|---|---|
| 長時間バッチ(フェーズで CPU 要求が変わる) | ◎ NotRequired で再起動なしに変更できる |
| モデルロードに時間がかかる推論サーバー | ◎ Pod を温めたまま CPU/メモリを調整できる |
| 長期接続を持つサーバー(WebSocket / gRPC streaming) | ◎ 接続を維持したまま変更できる |
| JIT 暖機(JVM の JIT コンパイルや Node.js の初期化など、起動時に時間がかかる処理)が重い Runtime | △ memory は RestartContainer が必要。CPU のみ in-place の恩恵 |
| 秒単位のスパイクへの即応が必要 | ✗ 実リサイズまで 3〜4 分のラグがある。HPA の役割 |
| ステートレスで起動が速い Web API | ✗ HPA でスケールアウトする方が素直 |
| 静的 CPU manager を使うワークロード | ✗ 機能的に非対応 |
| Guaranteed QoS が必要で VPA と組み合わせたい | ⚠ RequestsOnlyは QoS 変更を起こしやすい。requests == limits を維持できる設計か要確認 |
VPA を使う場合の設定指針:
| やりたいこと | 設定 |
|---|---|
| まず様子を見たい | updateMode: Off で recommendation を観察 |
| memory を大きく伸ばしたい | controlledValues: RequestsAndLimits+ maxAllowed |
| CPU だけ自動調整したい | controlledResources: [cpu]を指定し、必要なら controlledValues を併用 |
| HPA と共存させたい | VPA は memory、HPA は CPU または外部メトリクスで役割分担 |
| replicas=1 で使いたい | minReplicas: 1 を設定。ただし Recreate フォールバックは発動しない |
今回の検証で使った構成
ここまでの内容を手元で追いやすいように、検証で使った構成を最小限まで削った YAML を置いておきます。細部は省いていますが、resizePolicy、VPA のupdateMode、controlledValuesをどう置くかを見るにはこれで十分です。
手動リサイズ用 Pod:
apiVersion: v1
kind: Pod
metadata:
name: resize-cpu-test
namespace: resize-test
spec:
restartPolicy: Never
containers:
- name: app
image: public.ecr.aws/docker/library/busybox:1.36
command: ["sh", "-c", "echo started >/tmp/marker && sleep 3600"]
resources:
requests:
cpu: 250m
memory: 128Mi
limits:
cpu: 250m
memory: 128Mi
resizePolicy:
- resourceName: cpu
restartPolicy: NotRequired
- resourceName: memory
restartPolicy: NotRequiredこの Pod は手動の NotRequired リサイズ確認用なので、restartPolicy: Never のままで問題ありません。
RestartContainer を試したい場合は、この manifest をそのまま流用せず、Pod 全体の restartPolicy を Always にした別 manifest を用意する必要があります。restartPolicy: Never の Pod では RestartContainer は使えません。
VPA 連携用 Deployment + VPA:
apiVersion: apps/v1
kind: Deployment
metadata:
name: resize-demo
namespace: resize-test
spec:
replicas: 2
selector:
matchLabels:
app: resize-demo
template:
metadata:
labels:
app: resize-demo
spec:
containers:
- name: app
image: public.ecr.aws/docker/library/busybox:1.36
command: ["sh", "-c", "while true; do sleep 3600; done"]
resources:
requests:
cpu: 50m
memory: 128Mi
limits:
cpu: 50m
memory: 128Mi
resizePolicy:
- resourceName: cpu
restartPolicy: NotRequired
- resourceName: memory
restartPolicy: NotRequired
---
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: resize-demo
namespace: resize-test
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: resize-demo
updatePolicy:
updateMode: InPlaceOrRecreate
minReplicas: 1
resourcePolicy:
containerPolicies:
- containerName: '*'
controlledResources: ["cpu", "memory"]
controlledValues: RequestsAndLimits
minAllowed:
cpu: 25m
memory: 128Mi
maxAllowed:
cpu: "1"
memory: 512Mi観測はkubectl describe pod に加えて、少なくとも次の 3 つを見ておくと追いやすかったです。
kubectl get pod resize-cpu-test -n resize-test \
-o jsonpath='{.spec.containers[0].resources}{"\n"}'
kubectl get pod resize-cpu-test -n resize-test \
-o jsonpath='{.status.containerStatuses[0].resources}{"\n"}'
kubectl get pod resize-cpu-test -n resize-test \
-o jsonpath='{.status.containerStatuses[0].restartCount}{"\n"}'spec とstatus.containerStatuses[].resources を並べて見ると、Deferred やInfeasible で「desired は変わったが actual はまだ変わっていない」状態を追いやすいです。
filler Pod(壁 1-2 再現用):
壁 1(Deferred)・壁 2(Infeasible)を再現するには、ノードのリソースを意図的に埋める filler Pod(ダミーの負荷用 Pod)が必要です。
apiVersion: v1
kind: Pod
metadata:
name: filler
namespace: resize-test
spec:
containers:
- name: filler
image: public.ecr.aws/docker/library/busybox:1.36
command: ["sleep", "3600"]
resources:
requests:
cpu: 1500m
memory: 128Mit3.medium(Allocatable CPU ≈ 1930m)の場合、この filler Pod を配置すると空きが約 200m 未満になり、+300m のリサイズ要求で Deferred を再現できます。
まとめ
In-Place Pod Resize は v1.35 で正式に GA になりました。少なくとも今回の EKS 1.35 + VPA 1.6.0 + Linux ノードの条件では、手動の CPU リサイズも、VPA InPlaceOrRecreate 経由の memory 128Mi → 250Mi の in-place resize も約 1 秒・再起動なしで完了しました。
ただし壁もかなりはっきりしています。ノードの空きが足りなければ Deferred、物理キャパシティを超えれば Infeasible になります。VPA は recommendation が約 1 分で出ても actual request の反映までは 3〜4 分かかり、QoS クラスが変わる resize は in-place では拒否されて eviction + recreate にフォールバックしました。また、メモリ limit の削減時は kubelet が使用量チェックを行うものの best-effort であり、TOCTOU のレースにより OOM Kill のリスクがあります。
まずは updateMode: Off で VPA の recommendation を観察し、ベースラインのサイズ感をつかむところから始めるのが現実的だと感じました。その上で、再起動コストが高く、負荷パターンが継続的に変動するワークロードから段階的に適用していくのがよさそうです。本番導入時は Deferred 状態の長期滞留を見逃さないよう、resize_state の Pod Condition を監視に組み込んでおくと安心です。
追記: Alpha → Beta → GA の変遷
今回の検証で一番大きかった壁は、壁 3 で見た VPA の制御ループ遅延(recommendation から actual resize まで 2.5〜3 分)でした。kubelet 側の cgroup 書き換えは 1 秒で終わるのに、そこに至るまでの Recommender → Updater のパイプラインで数分待たされる。ここを短縮できれば、In-Place Resize の適用範囲はかなり広がるはずです。
この点で気になっているのが ScaleOps です。公式記事では「real-time」「automatically utilizes In-Place Resizing when needed」「no configuration required」と、VPA よりかなり強い表現で即時性を主張しています(ScaleOps × InPlacePodResize)
ただし、現時点ではこれは vendor claim であり、今回の検証のように pod.spec.resources と pod.status.containerStatuses[].resources の差分を秒単位で追った第三者検証は見つかりませんでした。
追記: Alpha → Beta → GA の変遷
この機能がどう成熟してきたかを短く整理します。
Alpha(v1.27 〜 v1.32)
Alpha は v1.27 で InPlacePodVerticalScaling feature gate とともに導入されました。デフォルトでは無効で、チェックポイント管理やステート復元、kubelet とスケジューラの競合状態といった難所が多く、v1.32 まで 6 バージョン続く長い Alpha 期間になっています。
変遷を追ってみると、この機能が GA まで時間がかかったのもかなり納得感がありました。「cgroup に書けば終わり」ではなく、kubelet と scheduler、status 反映、既存ワークロードとの整合まで全部そろえて初めて安全に出せる機能だったからです。
導入された API フィールド:
| フィールド | 説明 |
|---|---|
spec.containers[*].resizePolicy | 再起動要否を制御(NotRequired / RestartContainer) |
status.containerStatuses[*].allocatedResources | kubelet がノード上で割り当てたリソース量 |
status.containerStatuses[*].resources | 実際にランタイムで適用されているリソース量 |
status.resize | リサイズ進行状態(Proposed / InProgress / Deferred / Infeasible) |
制限事項も多く、静的 CPU/メモリマネージャーとの併用不可、サイドカーリサイズ非対応、メモリ limit 引き下げ禁止、containerd v1.6.9 以上必須といった条件がありました。
Beta(v1.33)— 最も破壊的な API 変更
Beta の v1.33 では feature gate がデフォルト有効になり、API もかなり変わりました。/resize サブリソースが必須になって RBAC を分離しやすくなり、status.resize は廃止されてPodResizePending とPodResizeInProgress という Pod Condition に移行しています。さらにサイドカーコンテナのリサイズにも対応しました。
# Beta 以降の操作方法(kubectl v1.32+ 必要)
kubectl patch pod <name> --subresource resize --type=json -p '...'GA / Stable(v1.35)
GA となった v1.35 では feature gate は常時有効でロックされ、無効化できなくなりました。機能面ではメモリ limit の引き下げが許可され、Deferred 状態のリサイズは優先クラス、QoS クラス、待機時間の順で処理されるようになっています。加えて Pod レベルリソースのリサイズも Alpha として入っています。
参考資料
- KEP-1287: In-Place Update of Pod Resources
- Control Group v2(Linux kernel documentation)
- Kubernetes 1.35: In-Place Pod Resize Graduates to Stable
- Kubernetes v1.33: In-Place Pod Resize Beta
- Kubernetes 1.27: In-Place Resource Resize Alpha
- Resize CPU and Memory Resources(公式ドキュメント)
- VPA 公式ドキュメント
- Vertical Pod Autoscaler README
- VPA Features: In-Place Updates (
InPlaceOrRecreate) - Pod Resource動的リサイズの検証(Sreake)
- EKS 1.33 In-Place Pod Resource Resize 検証(DevelopersIO)
- In-place Pod resizing in Kubernetes(Palark)