
はじめに
はじめまして。Sreake 事業部にてインターンとして参加しました七海(ななうみ)です。大学では情報系を専攻しており、普段は Web アプリケーションのバックエンド開発を中心に学んでいます。
Sreake 事業部では SRE に関するコンサルティングやプラットフォーム開発を行っています。今回のインターンでは、社内向けの AI チャットツール「Geake」の開発チームに加わり、約 1 ヶ月間でいくつかの issue に取り組みました。
Geake は、お客様の Google Cloud 環境上に構築・提供する法人専用の生成 AI サービスです。すべてのデータがお客様の環境内に閉じるためセキュリティ面で安心でき、Gemini と Claude の両モデルを同一 UI で利用できるのが特徴です。機能追加や UI 変更などのカスタマイズにも対応しています。
本記事では、その中でも特にスレッド一覧取得 API のパフォーマンス改善と、その効果を定量的に示すために構築した負荷テスト基盤について書きます。
正直に言うと、クエリの改善そのものは半日で終わりました。しかし、「本当に速くなったのか?」を数字で証明するのに、その何倍もの時間がかかりました。この記事は、その試行錯誤の記録です。
Geake の技術スタック
| レイヤー | 技術 |
|---|---|
| フロントエンド | React / Vite / SWR |
| バックエンド | TypeScript / Hono |
| ORM | Prisma |
| データベース | PostgreSQL |
| インフラ | Google Cloud(Cloud Run) |
| AI | Gemini |
1. スレッド一覧 API のパフォーマンス改善
問題:一覧画面なのに全データを返していた
Geake のスレッド一覧画面は、ユーザーが過去に行った AI との会話をリストで一覧表示する画面です。画面に表示するのは「スレッドのタイトル」と「最新メッセージのプレビュー」くらいなのですが、内部のクエリを確認して驚きました。
全スレッドの全メッセージ・全添付ファイル・全生成ファイルを一括で取得する構造になっていたのです。
// 改善前: すべてのメッセージと関連ファイルを取得していた
const threads = await prisma.threads.findMany({
where: { userId: user.id },
include: {
messages: {
include: {
attachedFiles: true,
generatedFiles: true,
},
},
},
});開発初期でデータが少ない段階では、シンプルでわかりやすい実装です。ただ、これはいわゆる over-fetching(過剰取得)と呼ばれるパターンで、画面に表示しないデータまで取得してしまう問題です。プロトタイピングや初期開発では許容されることが多いですが、ユーザーの会話が蓄積されていくと、1 スレッドあたり数十メッセージ × 添付ファイル × 生成ファイルがすべてレスポンスに含まれることになります。一覧画面で使わないデータが大半を占める状態でした。
実装:取得するデータを絞り込む
やったことは大きく 3 つです。
① メッセージの取得を最新 1 件に限定する。 一覧画面で必要なのは直近のメッセージだけなので、take: 1 で最新 1 件だけを取得します。
② 添付ファイル・生成ファイルの取得をやめる。 一覧画面にはファイル情報を表示しないため、select で必要なカラムだけを指定し、attachedFiles / generatedFiles のリレーションを外しました。
// 改善後: 最新 1 メッセージの必要なフィールドだけを取得
const threads = await prisma.threads.findMany({
where: { userId: user.id },
orderBy: { updatedAt: "desc" },
include: {
messages: {
orderBy: { createdAt: "desc" },
take: 1,
select: {
id: true,
producer: true,
content: true,
createdAt: true,
updatedAt: true,
},
},
},
});
③ 一覧表示専用の軽量スキーマを domain 層に定義する。 レスポンスの型安全性を保つため、Zod スキーマを新設しました。
// domain/message.ts — 一覧表示用の軽量バージョン
export const MessagePreview = Message.omit({
attachedFiles: true,
generatedFiles: true,
});
// domain/thread.ts — 一覧表示専用スキーマ
export const ThreadListItem = Thread.omit({ messages: true }).extend({
messages: z.array(MessagePreview),
});
最初は MessagePreview を独立した型として定義していたのですが、レビューで「Message から omit で派生させた方が、Message の変更時に修正漏れが起きない」と指摘されました。言われてみれば当然ですが、自分だけでは気づけなかった点です。
差分は +114 行 / -330 行。コードが 200 行以上減って、レスポンスも軽くなる。気持ちのいい変更でした。
「before / after が見たい」
ここまでは順調でした。PR を出したところ、チームメンバーからこんなコメントがつきます。
ちなみにこれってどのくらいパフォーマンス上がったんでしょう(before / after が見たい)
「たしかに」と思いつつも、どう測ればいいのか見当がつきませんでした。ここから、実装の何倍もの時間をかけた計測の旅が始まります。
まずはブラウザの開発者ツール(ネットワークタブ)で手元の環境を確認しました。
| 指標 | Before | After | 改善率 |
|---|---|---|---|
| レスポンスサイズ | 39.7 KiB | 10.4 KiB | 74% 削減 |
| レスポンス時間 | 193 ms | 110 ms | 43% 短縮 |
手元では確かに改善が出ています。ただ、開発環境にはスレッドが数件しかありません。この程度のデータ量では「一覧に全メッセージを返すかどうか」の差はあまり出ないはずです。データが増えたときにどのくらい効くのか ── それを示すには、もっとちゃんとした計測環境が必要でした。
2. 負荷テスト v1:k6 ではじめての計測
なぜ負荷テストを作ることにしたか
ブラウザの開発者ツールでの計測には限界を感じていました。手動でリロードして測る方法では再現性がなく、ネットワークの揺らぎやブラウザのキャッシュに結果が左右されます。平均や中央値、パーセンタイル(上位 N% のリクエストが収まる値)といった統計量も得られません。
何より、データ量が少なすぎて差が見えないという根本的な問題がありました。本番に近い規模のデータを入れて、繰り返しリクエストを送って、統計的に比較する ── つまり負荷テストが必要だと考えました。
ツールには k6 を選びました。JavaScript でテストシナリオを書ける点と、Docker で手軽に実行できる点が決め手です。
k6 のセットアップ
k6 は Grafana Labs が開発しているオープンソースの負荷テストツールです。テストシナリオを JavaScript で記述でき、CLI から手軽に実行できます。
今回は Docker コンテナとして実行する方法を採用しました。Docker を使えばローカルに k6 をインストールする必要がなく、チームメンバーも同じ環境で実行できます。
# Docker で k6 を実行する例
docker run --rm -i \\
-v $(pwd)/load-test:/scripts \\
--add-host=host.docker.internal:host-gateway \\
grafana/k6 run /scripts/k6-threads.js
-rm -i: コンテナ終了後に自動削除し、標準入出力を接続- –
v $(pwd)/load-test:/scripts: テストスクリプトをコンテナ内にマウント -add-host=host.docker.internal:host-gateway: コンテナからホストマシン上のバックエンドに接続するための設定grafana/k6 run /scripts/k6-threads.js: k6 公式イメージでスクリプトを実行
k6 のテストスクリプトは通常の JavaScript(ES Modules)で書けます。export default function() が各 VU(仮想ユーザー)で繰り返し実行される関数です。
import http from "k6/http";
import { check, sleep } from "k6";
export const options = {
vus: 1, // 仮想ユーザー数
duration: "30s", // テスト実行時間
};
export default function () {
const res = http.get("http://host.docker.internal:3010/threads", {
headers: { Authorization: `Bearer ${__ENV.TOKEN}` },
});
check(res, { "status is 200": (r) => r.status === 200 });
sleep(0.5);
}
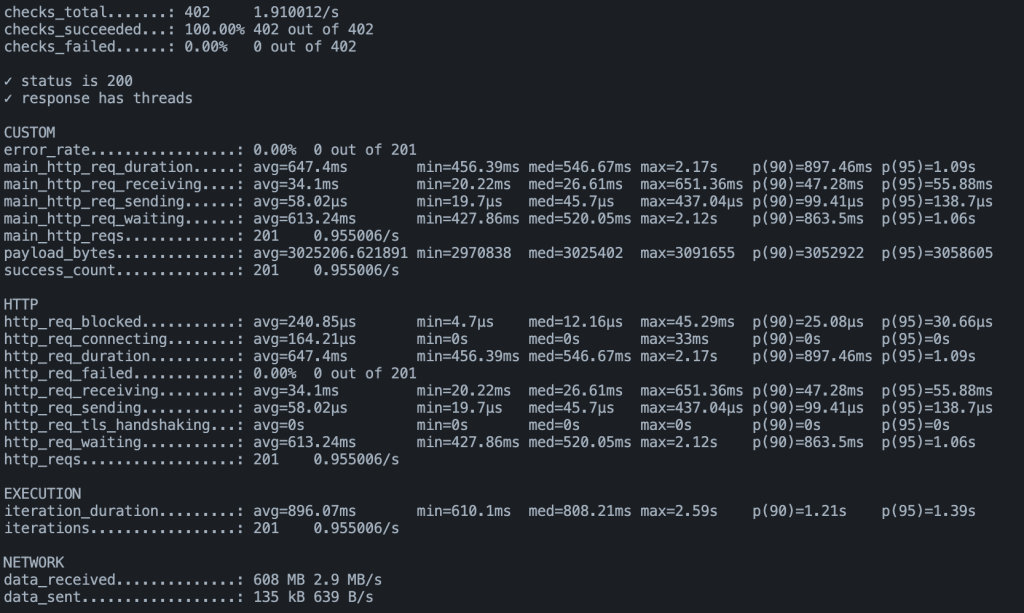
実行結果には平均レイテンシ、p50(med)/p90/p95 などのパーセンタイル、スループット(req/s)、エラー率などが自動的にレポートされます。
実行環境
負荷テストはすべてローカルの Docker Compose 環境で実行しています。実行環境によって結果は変わるため、参考値としてスペックを記載します。
| 項目 | 内容 |
|---|---|
| マシン | MacBook Air(Apple M1 / メモリ 16GB) |
| Docker | Docker Desktop for Mac |
| DB | PostgreSQL(Docker コンテナ) |
| Backend | TypeScript / Hono(Docker コンテナ) |
| k6 | grafana/k6(Docker コンテナ) |
| 認証 | Firebase Authentication エミュレータ |
テストデータを用意する
開発環境のデータでは差が見えないので、まずは大量のテストデータを作るところから始めました。シードスクリプト seed.loadtest.ts を書き、以下の規模のデータを投入します。
| データ | 件数 |
|---|---|
| スレッド | 1,000 |
| メッセージ(1 スレッドあたり 30 件) | 30,000 |
| 添付ファイル(1 メッセージあたり 2 件) | 60,000 |
| 生成ファイル(1 メッセージあたり 2 件) | 60,000 |
| 合計 | 約 121,000 レコード |
1,000 スレッドという数字は、Geake のユーザー数と利用頻度から「半年〜1 年後にヘビーユーザーが到達しうる規模」を想定して設定しました。各メッセージのコンテンツは 1〜4 KB のテキストです。
スレッドのタイトルには LoadTest-Thread-0001 のようなプレフィックスを付けました。これは後からテストデータだけを一括削除できるようにするためです。実行のたびに既存の LoadTest-* データを削除してから挿入する冪等設計にしたので、何度実行しても同じ状態になります。
k6 のシナリオ設計(v1)
最初の負荷テストでは、「負荷テスト」という言葉のイメージのまま、複数の仮想ユーザー(VU: Virtual User)で段階的に負荷を上げるシナリオを組みました。
// v1: 段階的に負荷を上げる構成
export const options = {
stages: [
{ duration: "30s", target: 2 }, // ウォームアップ
{ duration: "2m", target: 10 }, // ランプアップ
{ duration: "3m", target: 20 }, // 定常負荷(20 VU の同時アクセス)
],
};
Firebase エミュレータからトークンを取得し、認証ヘッダ付きで GET /threads を繰り返しリクエストする構成です。k6 は Docker コンテナとして実行し、host.docker.internal 経由でホスト上のバックエンドに接続しています。
before / after の切り替えに苦戦する
改善前後のコードを切り替えて比較するための compare.sh も作りました。ただ、ここで何度もつまずきました。
最初に思いついたのは、対象のルートファイル 1 つだけ git checkout で改善前に戻す方法です。しかしこれだと、domain 層のスキーマ(MessagePreview や ThreadListItem)が改善後のまま残り、型の不整合でビルドが通りません。関連ファイルが複数に散らばっていたので、ファイル単位の切り替えでは無理でした。
v1 の時点では git checkout + trap による復帰(スクリプトが異常終了しても元のブランチに戻る)という方法で一旦実装しました。根本的な問題が残っていることは自覚していましたが、まずは計測結果を出すことを優先しました。
v1 の計測結果
テストを回してみた結果がこちらです。
| 指標 | Before | After | 改善率 |
|---|---|---|---|
| 平均レイテンシ | 51,077 ms | 3,907 ms | 92% 短縮 |
| p50(中央値) | 60,004 ms | 4,071 ms | — |
| p90 | 60,304 ms | 6,447 ms | — |
| 平均ペイロード | 52 MB | 3 MB | 94% 削減 |
| スループット | 0.17 req/s | 2.40 req/s | 14 倍 |
| エラー率 | 73% | 0% | — |
Before の p50 と p90 が約 60,000 ms で揃っているのを見て最初は意味がわからなかったのですが、k6 のデフォルト HTTP タイムアウト(60 秒)に達してリクエストが打ち切られていたためでした。20 VU の同時アクセスで 1 リクエストあたり 52 MB のレスポンスを返そうとして、データベースがほぼ応答不能に陥っていたのです。
52 MB という数字には正直驚きました。一覧画面を開くたびに、50 MB 超のデータが流れていたことになります。ブラウザの開発者ツールでは 39.7 KiB と 10.4 KiB の差にしか見えなかったのに、データを 1,000 スレッド規模にするとここまで変わるのか、と。
v1 で突きつけられた課題
結果のインパクトは大きかったのですが、レビューでいくつかの根本的な問題を指摘されました。
「このテストで何を測りたいの?」 ── メンターさんからのこの問いかけが一番刺さりました。20 VU の同時アクセスでは Before が完全にタイムアウトしてしまい、「改善前の本来の処理時間」がわかりません。Before のエラー率 73% という数字は「改善効果」ではなく「DB が壊れるかどうかの差」を見ているだけではないか、と。
そのほかにも以下の問題がありました。
- データの非決定性:
Math.random()でメッセージ内容を生成していたため、before と after で微妙にデータが異なる可能性がある。比較実験なのに変数が制御できていない - compare.sh の安全性:
git checkout方式では、作業中の未コミット変更を壊すリスクがある - ウォームアップの混入: DB 接続プールの初期化など、ウォームアップ期間のリクエストが計測結果に混ざっていた
考えてみればもっともな指摘です。v1 は「とりあえず負荷テストを動かしてみた」段階であり、計測としての信頼性が足りていませんでした。
3. 負荷テスト v2:設計からやり直す
目的を再定義する
v1 のレビューを受けて、「このテストで何を証明したいのか」を改めて整理しました。
今回測りたいのは「同時接続が増えたときの耐久性」ではなく、「同一条件で before / after のレイテンシとペイロードサイズがどれだけ変わるか」です。であれば、VU を増やして DB を飽和させる必要はありません。VU=1 のシングルユーザーテストで逐次リクエストを送り、純粋な処理時間の差を見るのが適切です。
「負荷テスト」と聞くと「たくさんのユーザーを同時にぶつける」イメージがありましたが、目的が違えば設計も変わる。当たり前のことですが、実際にやってみるまで気づけませんでした。
k6 シナリオの再設計
v2 では、ウォームアップと本計測を独立したシナリオに分離しました。
// v2: VU=1 のシングルユーザーテスト
export const options = {
scenarios: {
warmup: {
executor: "constant-vus",
vus: 1,
duration: "30s",
exec: "warmup", // ウォームアップ専用の関数
},
main: {
executor: "constant-vus",
vus: 1,
duration: "3m",
startTime: "30s", // warmup 完了後に開始
exec: "main", // 本計測専用の関数
},
},
thresholds: {
"main_http_req_duration": ["p(95)<500", "p(99)<1000"],
"error_rate": ["rate<0.01"],
},
};
v1 からの主な変更点をまとめます。
| 項目 | v1 | v2 | 変更理由 |
|---|---|---|---|
| VU 数 | 最大 20(段階増加) | 1(固定) | 純粋な処理時間を測るため |
| シナリオ | 単一(stages) | warmup + main の分離 | ウォームアップの混入を防ぐ |
| 計測メトリクス | http_req_duration | main_http_req_duration | main シナリオだけを集計 |
| リクエスト間隔 | 0.5〜1.0s | 0.1〜0.3s | より多くのサンプルを取得 |
main_http_req_duration は k6 のカスタムメトリクスです。main シナリオの関数内で mainDuration.add(res.timings.duration) と明示的に記録することで、ウォームアップのリクエストが閾値判定やサマリーに含まれなくなりました。
決定論的なテストデータ
v1 の「before と after でデータが同一である保証がない」という問題に対応するため、シード付き疑似乱数生成器を導入しました。
// シード付き疑似乱数生成器 (mulberry32)
// 軽量かつ実装がシンプルなアルゴリズムを採用
function createSeededRng(seed: number): () => number {
let s = seed | 0;
return () => {
s = (s + 0x6d2b79f5) | 0;
let t = Math.imul(s ^ (s >>> 15), 1 | s);
t = (t + Math.imul(t ^ (t >>> 7), 61 | t)) ^ t;
return ((t ^ (t >>> 14)) >>> 0) / 4294967296;
};
}
const rng = createSeededRng(42); // seed=42 で固定
Math.random() を rng() に置き換えるだけの小さな変更ですが、これで seed=42 から常に同じ乱数列が生成されます。before の DB にも after の DB にも、まったく同じ 121,000 レコードが投入されることが保証されました。
比較実験では「変えたい変数以外をすべて固定する」のが原則です。頭ではわかっていても、v1 ではそこまで意識が回っていませんでした。
compare.sh の再設計:git worktree 方式
v1 では git checkout でブランチを切り替えていましたが、v2 では git worktree を使う方式に全面的に書き換えました。
# worktree を作成(元のリポジトリには一切影響しない)
git worktree add /tmp/geake-before ${BEFORE_COMMIT}
git worktree add /tmp/geake-after ${AFTER_COMMIT}
git worktree は、同一リポジトリの別コミットを独立したディレクトリに展開できる Git の機能です。メインの作業ディレクトリは一切変更されないため、未コミットの変更が消えるリスクがありません。
実はこの git worktree という機能の存在を、このタスクで初めて知りました。git checkout で苦労していた問題が一発で解決して、「もっと早く知りたかった……」と思ったのを覚えています。
比較の全体フローはこうなっています。
compare.sh 実行
│
├── worktree 作成 (/tmp/geake-before, /tmp/geake-after)
│
├── [BEFORE] テスト実行
│ ├── docker compose down -v(ボリュームごと削除してクリーン起動)
│ ├── postgres + firebase-emulator 起動
│ ├── mise install → pnpm install → prisma migrate → seed
│ ├── backend 起動 → /health でヘルスチェック待機
│ ├── k6 実行 → results/before.json に結果出力
│ └── docker compose down -v(環境を完全に破棄)
│
├── [AFTER] テスト実行(同じ手順)
│ └── k6 実行 → results/after.json に結果出力
│
├── 結果比較テーブルを表示
│
└── クリーンアップ(worktree 削除、Docker リソース削除)
※ trap EXIT で異常終了時も確実に実行
ポイントは、各テスト実行の前後で docker compose down -v を叩いていることです。-v オプションで Docker ボリュームごと削除するため、前回の DB 状態が残る心配がありません。seed スクリプトから毎回投入し直すので時間はかかりますが、完全にクリーンな状態から計測が始まることを保証しています。
また、trap cleanup EXIT を設定しているので、スクリプトが途中で Ctrl+C されたり、k6 がエラーで落ちたりしても、worktree と Docker コンテナが確実にクリーンアップされます。v1 で git checkout のまま中断して焦った経験があったので、ここは特に気を遣いました。
計測環境を先に検証する
余談ですが、v1 の初回実行で痛い目に遭った話をしておきます。
before と after のテストを回してみたら、レイテンシがほぼ同じ数値でした。「改善効果ゼロか……?」と一瞬焦りましたが、落ち着いてバックエンドのログを確認したところ、tsx watch がファイルの差し替えを検知しておらず、before でも改善後のコードが動いていたことがわかりました。
docker compose restart backend でプロセスを確実に再起動することで解決しましたが、この経験から「計測結果を見る前に、計測環境が正しく動いているかを確認する」という手順を意識するようになりました。v2 では worktree ごとにゼロからビルドする設計にしたので、この問題は構造的に起きなくなっています。
v2 の計測結果
すべての改善を反映した v2 の結果です。
| 指標 | Before | After | 改善率 |
|---|---|---|---|
| 平均レイテンシ | 6,669 ms | 647 ms | 10.3 倍高速化 |
| p50(中央値) | 6,320 ms | 547 ms | 11.6 倍高速化 |
| p90 | 8,336 ms | 897 ms | 9.3 倍高速化 |
| p95 | 8,899 ms | 1,095 ms | 8.1 倍高速化 |
| 平均ペイロード | 約 126 MB | 約 3 MB | 約 42 倍削減 |
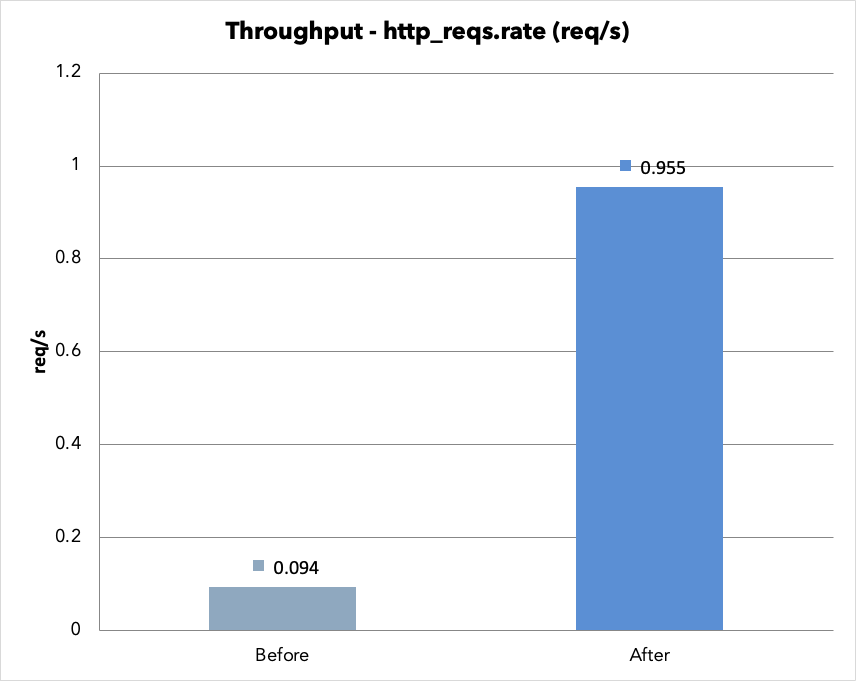
| スループット | 0.09 req/s | 0.96 req/s | 10.1 倍向上 |
| エラー率 | 0% | 0% | — |
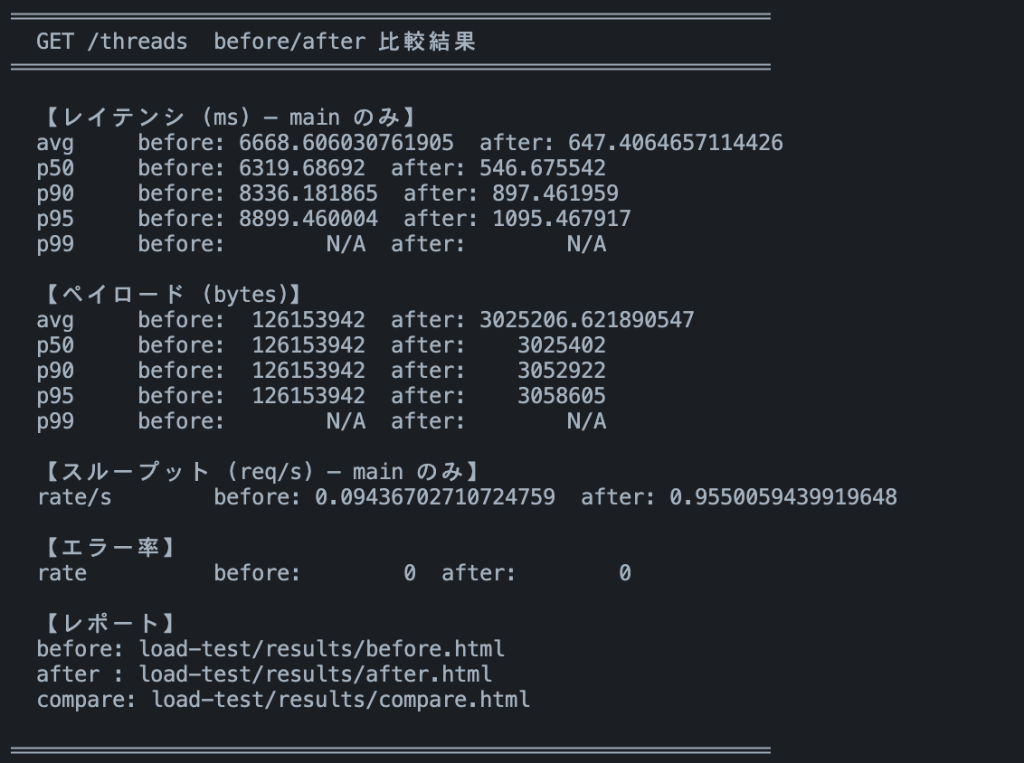
v1 と違い、VU=1 なので Before もタイムアウトせず完走しました。Before は 1 リクエストに平均 6.7 秒かかっていたのが、After では 647 ms に短縮されています。p50(中央値)で見ると 6.3 秒 → 547 ms で、約 11.6 倍の高速化です。
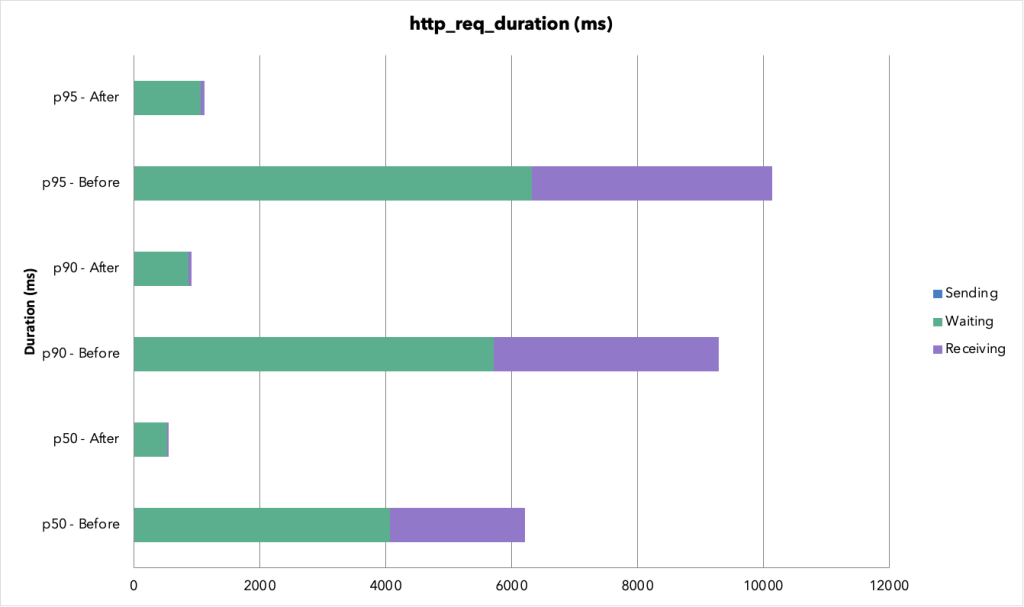
ペイロードサイズの差はさらに大きく、Before は 1 リクエストあたり約 126 MB のレスポンスを返していました。1,000 スレッド × 30 メッセージ × 各メッセージの添付ファイル・生成ファイルがすべて含まれていたためです。After ではこれが約 3 MB まで削減されました。
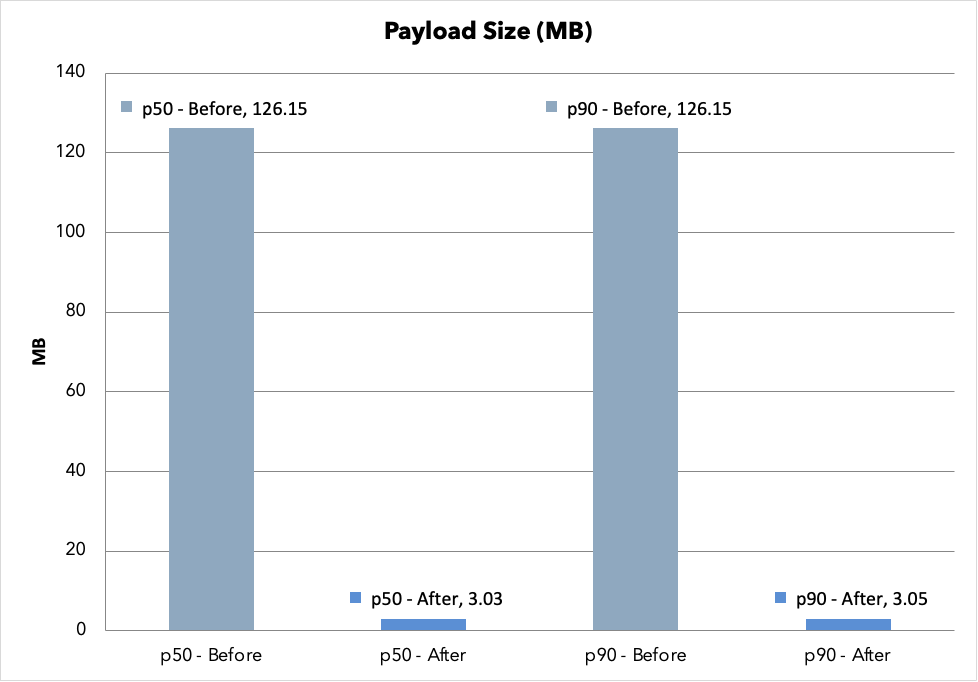
なお、この 126 MB / 3 MB という数字は 1,000 スレッドのテストデータでの値であり、現時点の本番環境のデータ量はこの規模ではありません。ただし、Geake の利用が広がった将来を想定すると、この改善がなければ一覧画面のレスポンスがユーザー体験を損なうレベルまで肥大化する可能性がありました。
v1 と v2 の結果を比べてみる
| 指標 | v1 Before | v2 Before | 違いの理由 |
|---|---|---|---|
| 平均レイテンシ | 51,077 ms | 6,669 ms | v1 は 20 VU で DB が飽和しタイムアウト多発 |
| エラー率 | 73% | 0% | v2 は VU=1 で DB が応答可能な負荷 |
| ペイロード | 52 MB | 126 MB | v1 はタイムアウトで完了しなかったリクエストが多いため、平均が低く出ている |
v2 で Before のペイロードが v1 より大きくなっているのは、v1 ではリクエストの大半がタイムアウトで打ち切られて不完全なレスポンスだったのに対し、v2 ではすべてのリクエストが正常完了して全データが返ってきたためです。
v1 の「92% 短縮」という数字のほうが v2 の「90% 短縮」よりインパクトがありますが、v1 は「DB が死ぬかどうかの差」を見ていただけで、改善効果の正確な測定とは言えませんでした。v2 によって、適切な負荷条件で純粋な処理時間の差を示せるようになったと思います。
計測結果の総まとめ
最終的に、3 つのアプローチで改善効果を検証しました。
| 計測方法 | サイズ改善 | レイテンシ改善 | データ量 | 特徴 |
|---|---|---|---|---|
| ブラウザ開発者ツール | 74% 削減 | 43% 短縮 | 数件 | 手軽だが差が小さい |
| k6 v1(20 VU) | 94% 削減 | 92% 短縮 | 1,000 スレッド | Before がタイムアウトで不正確 |
| k6 v2(1 VU) | 97% 削減 | 90% 短縮 | 1,000 スレッド | 適切な条件で純粋な処理時間を比較 |
3 つすべてで一貫してサイズ削減とレイテンシ短縮が確認できました。手法によって改善率の数字は異なりますが、方向性が一致していることで「改善されました」と自信を持って報告できるようになりました。
振り返り:一番の学びは何だったか
テストの目的を定義してから設計する
今回のインターンで最も大きな学びは、「何を測りたいのか」を明確にしてからテストを設計するということでした。
v1 では「負荷テストだから VU を増やす」「段階的に負荷を上げる」と、負荷テストの一般的なパターンをそのまま適用していました。しかし、今回の目的は「同時接続の耐久性テスト」ではなく「クエリ改善の効果測定」です。目的が違えば最適な設計も違います。
メンターに「そもそもこのテストで何を測りたいの?」と聞かれたとき、すぐに答えられませんでした。「速くなったことを示したい」──では、「速くなった」をどの指標で定義するのか? タイムアウトが減ることなのか、レイテンシが下がることなのか、スループットが上がることなのか。
この問いに向き合ったことで、v2 の設計が自然に決まりました。VU=1、ウォームアップ分離、決定論的データ、worktree による独立環境 ── すべて「同一条件で処理時間を比較する」という目的から導かれた設計判断です。
結果がおかしいときは、まず環境を疑う
「tsx watch がファイルの差し替えを検知しない」問題で、before と after がまったく同じ数値になったときは焦りました。「改善効果ゼロ……?」と。結局コードは正しくて、環境がおかしかった。計測結果を疑う前に、計測環境を疑え。地味だけど大事な教訓です。
比較条件を制御する
Math.random() をシード付き PRNG に置き換えるのは数行の変更ですが、「before と after で本当に同じデータなのか?」という疑問を構造的に排除できました。比較実験では、変えたい変数以外を固定する。これは頭では知っていたことですが、自分のコードで見落としていたことにレビューで気づかされました。
まだ残っている課題
v2 でテストの信頼性は大きく上がりましたが、完璧ではありません。
たとえば、今回の計測はすべてローカル Docker 環境で行っています。本番の Cloud Run 環境ではコールドスタートやネットワークレイテンシ、コネクションプーリングの挙動が異なるため、同じ数字が出るとは限りません。「ローカルで 7.5 倍速くなったから本番でも同じだけ速くなる」とは言い切れない。
また、GET /threads 単体の計測しかしていないので、他のエンドポイントや同時に走るバッチ処理との干渉は見えていません。次にやるなら、本番のログから実際のレイテンシ分布を取得して、ローカル計測との差分を確認したいと思っています。
スリーシェイクでの働き方
技術的な話が続いたので、最後にスリーシェイクでのインターン生活についても触れておきます。これからインターンを検討している方の参考になれば嬉しいです。
風通しがよくフラットなチーム
インターン中、一番ありがたかったのは「聞けば教えてもらえる」環境だったことです。
行き詰まったとき、メンターの方に Slack で相談すると、いつも丁寧に背景から説明してくれました。様々な問いかけも、答えを教えるのではなく自分で考えさせてくれるスタイルで、単に作業を終わらせるだけでなく「なぜそうするのか」を理解できたのは大きかったです。
メンター以外の社員の方も、PR レビューでは改善の理由を丁寧にコメントしてくれましたし、雑談ベースの技術的な会話も多く、チーム全体の人柄の良さを感じました。
さらに驚いたのは、社長との距離が近いことです。ミーティングで直接話を聞く機会があったり、関連技術についてエンジニアの方とやり取りをされていたり、役職に関係なくフラットにコミュニケーションが取られている印象を受けました。
インターン生だからといって遠慮する雰囲気はなく、「わからないことはわからない」と素直に言える空気がありました。これは自分にとって本当に助かりました。
柔軟な働き方
勤務はフルリモートで、作業時間もかなり柔軟性がありました。大学の授業との両立がしやすく、「この時間帯は授業があるので」と伝えれば調整してもらえました。
もちろん、柔軟だからこそ自分でスケジュールを管理する力が求められます。ただ、困ったときに相談すればサポートしてもらえるので、自律と支援のバランスが取れた環境だったと思います。
おわりに
1 ヶ月のインターンで、パフォーマンス改善の実装から負荷テスト基盤の構築まで、一連の流れを経験できました。
最も印象に残っているのは、ブラウザの開発者ツールで 39.7 KiB → 10.4 KiB だった差が、1,000 スレッド規模になると 126 MB → 3 MB に拡大した瞬間です。開発環境では見えなかった問題が、データ量を増やすと突然姿を現す。予防的なパフォーマンス改善の意義を、自分の手で測った数字を通じて実感しました。
振り返ると、「どのくらい速くなったの?」という一言のコメントから始まった計測の旅は、クエリの改善そのものより多くのことを教えてくれました。k6 の使い方、git worktree の存在、テスト設計の考え方、そして「目的を明確にしてから手を動かす」こと。
最後に、メンターの方をはじめチームの皆さまには、レビューや相談のたびに丁寧に対応していただき、ありがとうございました。「before / after が見たい」「何を測りたいの?」── これらの問いかけがなければ、今回の学びはなかったと思います。