
Sreake 事業部の芳賀雅樹 (@silasolla) です.
早速ですが,Cloud Dataflow のパイプラインは,実行のたびにデータの分割や到着順が変わるにもかかわらず,(一定の条件のもとで) 集約結果は同一になります.どうして,非決定的な環境から決定的な結果が得られるのでしょうか.
この記事では,Dataflow における順序の不確実性と,それを無害化するために Apache Beam の CombineFn が集約関数に課している代数的条件について見ていきます.
同じパイプラインを 2 回実行したら同じ結果が返る?
Cloud Dataflow でパイプラインを実行するとき,主に 3 つの不確実性が同時に働いています.
まず,データの分割と集約の構造は実行ごとに変わります.Dataflow の Dynamic Work Rebalancing [1] は,ワーカーの負荷に応じてバンドル (ワーカーに割り当てられる処理の単位) を実行中に再分割します.さらに Combine 操作では,ランタイムは入力を任意に分割して部分集約し,それらを任意の木構造でマージできます [2].どのデータがどのバンドルに入り,どのような木構造で集約されるかは,実行ごとに異なる可能性があります.
また,中間データの到着順は保証されません.Dataflow Shuffle [3] は,GroupByKey や Combine の中間データシャッフルをマネージドサービスとして処理しますが,どのワーカーからどの順序でデータが届くかは,ネットワーク状況やサービスの内部実装に依存します.
さらに,ストリーミングではウィンドウの発火タイミングが動的に変わります.Streaming Engine [4] は Watermark に基づいてウィンドウの発火やバンドルの境界を動的に制御するため,同じ時間のウィンドウに属するデータが,1 回の発火に全部入ることもあれば,2 回に分かれることもあります.
つまり Dataflow 上では,データがどう分割され,どの順序で届き,いつマージされるか,いずれもプログラマには制御できず,実行のたびに変わりうるわけです.普通に考えると,処理順序が毎回変わるなら結果も変わりそうに見えますが,それにもかかわらず,適切に設計された集約関数を使えば,集約結果は常に一致します.これは自明ではありません.
このように,非決定的な実行から決定的な結果が得られることの根拠は,Apache Beam の CombineFn が集約関数に課す代数的条件にあります.Beam のドキュメントはこの条件を “associative and commutative” と記述していますが,CombineFn の API 設計を含めて整理すると,代数学における「可換モノイド」とみなせる構造に対応します.
可換モノイドでないと困ること
可換モノイドの定義に入る前に,この条件を満たさない集約がどう壊れるかを見ておきましょう.
4 件のデータ [1, 2, 3, 4] の平均値を分散集約で求めるケースを考えます.正しい値は 2.5 ですね.
ランタイムがデータを 2 つのバンドルに分割したとします.バンドル A が [1, 2, 3] を受け取って平均 2 を計算し,バンドル B が [4] を受け取って平均 4 を計算したとき,この 部分結果を avg(2, 4) = 3 と素朴にマージしてしまうと,本当の平均値とは一致しません.
さらに,分割の仕方を変えると別の計算結果が出てきます.バンドル A に [1, 4],バンドル B に [2, 3] が入った場合は,それぞれの平均が 2.5 となり,マージ結果も 2.5 (たまたま正しい) です.
結果が分割に依存するということは,ランタイムがバンドルを組み替えるたびに異なる値が返るということです.Dataflow Shuffle でデータの到着順が変われば,さらに別のパターンが生じます.これでは,同じパイプラインを 2 回実行して同じ結果となることが保証できません.
根本的な問題は,平均値だけでは部分結果のマージに必要な情報 (要素数) が失われ,分割に依存しない二項演算を定義できないことにあります.
可換モノイドの定義
集合 S と二項演算 \circ: S^2 \to S の組 (S, \circ) が可換モノイドであるとは,次の 3 つの性質を満たすことをいいます.
結合律
(a \circ b) \circ c = a \circ (b \circ c) が任意の a, b, c \in S について成り立つことを要求します.これはグループ分けを変えても結果が変わらないことを意味します.ランタイムが集約の木構造をどう組んでも,計算結果が変わらないための条件です.
可換律
a \circ b = b \circ a が任意の a, b \in S について成り立つことを要求します.これは順序を入れ替えても結果が同じであることを意味します.Dataflow Shuffle でデータがどの順序で届いても,計算結果が変わらないための条件です.
単位元の存在
ある元 e \in S が存在して,任意の a \in S に対して e \circ a = a \circ e = a を満たすことを要求します.これは「何もないもの」との合成が元を変えないことを意味し,空のバンドルが生じたときに結果を歪めないための条件です.分散実行では「空の部分結果」が自然に発生するため,単位元が存在しない演算はその時点で破綻してしまいます.
Apache Beam の公式ドキュメント [2] では,結合律と可換律の 2 つが明示的に要求されています.
Combining functions used by Combine.Globally, Combine.PerKey, Combine.GroupedValues, and PTransforms derived from them should be associative and commutative. Associativity is required because input values are first broken up into subgroups before being combined, and their intermediate results further combined, in an arbitrary tree structure. Commutativity is required because any order of the input values is ignored when breaking up input values into groups.
結合律は「木構造の任意性」に,可換律は「入力順序の無視」にそれぞれ対応しています.一方で,単位元についてはドキュメントに明示的な記述はありません.しかしながら,CombineFn の API には create_accumulator() という「初期状態を返すメソッド」が存在し,その戻り値は他のアキュムレータとマージされても結果を変えません.これは単位元に相当します.
つまり,Beam は結合律と可換律をドキュメントで要求し,単位元を API 設計で暗黙に要求しているのです.この 3 条件を合わせたものこそが,代数学における可換モノイドに他なりません.
壊れない集約を設計するには
前述した平均値の計算は可換モノイドではありませんでした.では,どうすれば可換モノイドにできるでしょうか.
こういうときは,平均値を直接集約するのではなく,(sum, count) というタプルに変換してから集約するのが定石です.たとえば,バンドル A が [1, 2, 3] を受け取ると (6, 3) を返し,バンドル B が [4] を受け取ると (4, 1) を返すようにします.マージは要素ごとの和で (6 + 4, 3 + 1) = (10, 4) となり,最終的に 10 / 4 = 2.5 が得られます.分割を変えても,バンドル A が [1, 4] なら (5, 2),バンドル B が [2, 3] なら (5, 2) となり,マージ結果は同様に (10, 4) へ到達します.
この (sum, count) の演算が可換モノイドであることを示しましょう.集合 S = \mathbb{Z} \times \mathbb{N} の演算を (s_1, c_1) \circ (s_2, c_2) = (s_1 + s_2,\; c_1 + c_2) と定義します.
結合律
整数の和が結合的であることから直ちに従います.((s_1, c_1) \circ (s_2, c_2)) \circ (s_3, c_3) と (s_1, c_1) \circ ((s_2, c_2) \circ (s_3, c_3)) はどちらも (s_1 + s_2 + s_3,\; c_1 + c_2 + c_3) に帰着します.\square
可換律
同様に (s_1 + s_2,\; c_1 + c_2) = (s_2 + s_1,\; c_2 + c_1) から直ちに従います.\square
単位元の存在
e = (0, 0) であり (0, 0) \circ (s, c) = (s, c) \circ (0, 0) = (s, c) を満たします.\square
結合律が保証されていれば,分散実行時の木構造がどう変化しても最終結果は一致します.今回の 4 つの入力 [1, 2, 3 ,4] を集約する例を見てみましょう.
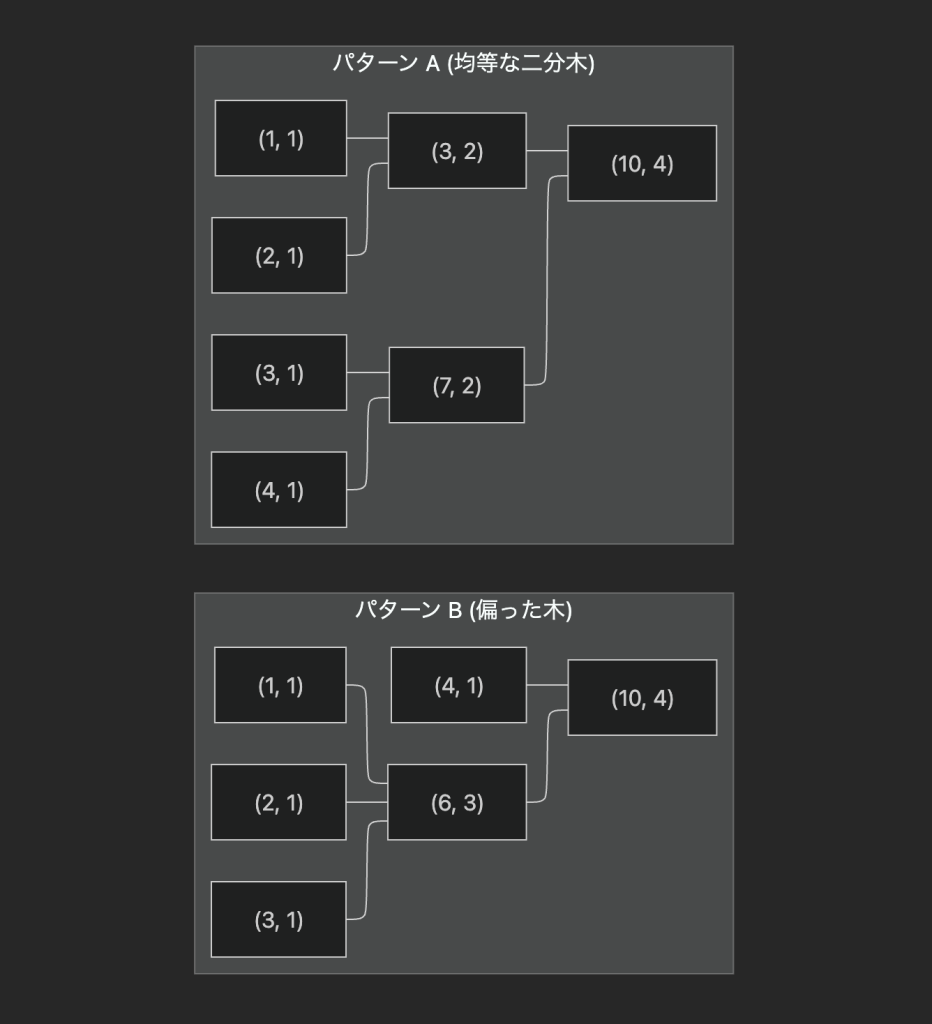
パターン A のような均等な二分木でも,パターン B のような偏った木でも,ランタイムが選択した集約の経路によらず,可換モノイドの性質から結果は (10, 4) となります.
CombineFn における可換モノイド
Beam のランタイムは,データの分割や到着順や発火タイミングを自由に制御します.その代わりに,プログラマには代数的性質を満たす集約の記述を要求します.CombineFn は,このトレードオフをインターフェースとして具体化したものです.
create_accumulator():単位元を返すadd_input(acc, input):入力をアキュムレータに変換して蓄積するmerge_accumulators([acc1, acc2, ...]):部分結果のリストをモノイド演算で畳み込むextract_output(acc):アキュムレータから最終結果を取り出す
先ほどの (sum, count) による平均値の集約を CombineFn として実装すると,次のようになります.
class AverageFn(beam.CombineFn):
def create_accumulator(self):
return (0, 0)
def add_input(self, acc, input):
return (acc[0] + input, acc[1] + 1)
def merge_accumulators(self, accs):
s = sum(a[0] for a in accs)
c = sum(a[1] for a in accs)
return (s, c)
def extract_output(self, acc):
return acc[0] / acc[1] if acc[1] else 0add_input と merge_accumulators が分離されていることで,アキュムレータの型を入力の型と異なるものにできます.平均の例では,入力は整数ですがアキュムレータは (sum, count) です.もし単一の reduce 関数しかなければ,入力型のまま集約する必要があり,この変換は表現できません.
extract_output が独立していることで,集約はアキュムレータ (可換モノイド) として完結し,出力の型への変換は最後に一度だけ行われます.sum / count のような分割に依存する操作を最後まで遅延できるのは,この分離のおかげです.
ドキュメントが明示的に要求するのは結合律と可換律の 2 つですが,create_accumulator() の戻り値が単位元として振る舞うため,このインターフェース全体が可換モノイドの構造を体現しています.こうしたメソッドの分離によって,Beam ランタイムはいつ,どこで,どの順序で集約するかを自由に決められます.プログラマが制御するのは計算の順序ではなく,どのように結合して も壊れないという性質です.
Dataflow における可換モノイド
ここまでの議論を整理します.Apache Beam は CombineFn を通じて,結合律や可換律をドキュメントで,単位元を API 設計で要求しています.この 3 条件が合わさった代数構造 (可換モノイド) は Beam のプログラミングモデルに属するものであり,Dataflow 固有の要件ではありません.ローカルのテスト用ランナーである DirectRunner も,要素を意図的に任意の順序で処理することで,順序に依存するコードをローカル開発の段階で検出できるように設計されています [5].
しかしながら,Beam のランナーの一つである Cloud Dataflow は,その条件を前提として実行時の最適化を行っています.Combine 操作では,ランタイムが入力を任意に分割・部分集約し,任意の木構造でマージしますが,結合律によってどのような木構造でも結果は一致します.Dynamic Work Rebalancing がバンドルを実行中に再分割しても,結合律と可換律によって結果は変わりません.Dataflow Shuffle はデータの到着順を保証しませんが,可換律によって順序非依存であることが保証されます.Streaming Engine はウィンドウの発火タイミングを動的に制御しますが,同一の要素集合が集約される限り,可換モノイドの性質からその結果は同一になります.(ただし,トリガーやアキュムレーションモードによって,出力列自体は実行ごとに異なる可能性があります)
Beam が代数的な条件を要求し,その条件を前提に Dataflow が実行時の最適化を行います.可換モノイドは Dataflow が「非決定的な実行から決定的な結果を得る」ための実行時の前提条件というわけです.データの分割,順序,発火タイミングといった不確実性は,いずれも可換モノイドの条件によって無害化されます.これが,非決定的な実行から決定的な結果が得られる所以です.
おわりに
本記事では,Cloud Dataflow の非決定的な実行において,結果が決定的に定まる根拠が CombineFn の要求する代数的条件 (可換モノイド) にあることを見てきました.
順序や分割の非決定性を,演算側の結合律や可換律によって吸収するアプローチは,Apache Beam に限ったものではありません.Apache Spark の aggregate [6] も結合関数に結合律を要求しており,同様の設計思想に基づいています.分散システムにおいて結果整合性を担保する CRDT (Conflict-free Replicated Data Type) [7] は,可換モノイドではなく join-semilattice (冪等律を加えた別の代数構造) に基づきますが,順序に依存しないマージを代数的性質で保証するという原理は共通しています.
参考文献
- Google Cloud. “Dynamic Work Rebalancing.” Google Cloud Documentation. https://cloud.google.com/dataflow/docs/dynamic-work-rebalancing
- Apache Software Foundation. “CombinePerKey.” Apache Beam Documentation. https://beam.apache.org/documentation/transforms/python/aggregation/combineperkey/
- Google Cloud. “Dataflow Shuffle.” Google Cloud Documentation. https://cloud.google.com/dataflow/docs/guides/deploying-a-pipeline#dataflow-shuffle
- Google Cloud. “Streaming Engine.” Google Cloud Documentation. https://cloud.google.com/dataflow/docs/guides/deploying-a-pipeline#streaming-engine
- Apache Software Foundation. “Direct Runner.” Apache Beam Documentation. https://beam.apache.org/documentation/runners/direct/
- Apache Software Foundation. “RDD (Scala API).” Apache Spark Documentation. https://spark.apache.org/docs/latest/api/scala/org/apache/spark/rdd/RDD.html
- Shapiro, M., Preguiça, N., Baquero, C., & Zawirski, M. (2011). “Conflict-free Replicated Data Types.” Stabilization, Safety, and Security of Distributed Systems (SSS 2011), Lecture Notes in Computer Science, vol 6976, pp. 386–400.
- Akidau, T. et al. (2015). “The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing.” Proceedings of the VLDB Endowment, 8(12), 1792–1803.