A2A protocol における Remote Agent 間の分散 tracing — OpenTelemetry + Cloud Trace で可視化する

はじめに
Sreake 事業部の井上 秀一です。私は Sreake 事業部にて、 SRE や生成 AI に関する Research & Development を行っています。
近年、 LLM を活用した AI Agent が注目される中、複数の Agent が協調して動作する multi-agent 構成が増えています。 Google が提唱する A2A (Agent-to-Agent) protocol は、異なる framework や vendor の Agent 同士が標準化された interface で通信するための open protocol です。
しかし、複数の Agent が独立した service として分散 deploy されると、observability が課題になります。障害発生時にどの Agent で問題が起きたのか、 latency の bottleneck がどこにあるのかを特定するには、 microservice と同様に 分散 tracing が必要です。
本記事では、 A2A protocol v1.0 を使って 3 つの Remote Agent (A→B→C)を chain 構成で実装し、OpenTelemetry による分散 tracing を導入して Google Cloud Trace で可視化する 方法を調査・実装しました。
A2A protocol と分散 tracing
A2A protocol の概要
A2A (Agent-to-Agent) は、 Agent 同士が互いの能力を発見し、 task を委譲するための open protocol です。 HTTP + JSON-RPC をベースとしており、 microservice における service 間通信と同じ通信 pattern を採用しています。
本記事では A2A Protocol v1.0 (alpha 版) を使用します。現時点での version 状況は以下の通りです。
| version | 状況 | SDK |
|---|---|---|
| v0.3.0 | 安定版 | a2a-sdk 0.3.25 |
| v1.0 | alpha 段階。1.0-dev branch で開発中 | a2a-sdk 1.0.0a0 |
v1.0 では v0.3 から以下の変更がありました。
| 項目 | v0.3 | v1.0 |
|---|---|---|
| method 名 | message/send | SendMessage(gRPC style) |
| 型 system | Pydantic | Protocol Buffers |
| Role | 文字列 ("user") | enum ("ROLE_USER") |
v1.0 を採用した理由として、 A2A の enterprise document にて分散 tracing への参加が推奨 (should) されている点があります。
“A2A Clients and Servers should participate in distributed tracing systems. For example, use OpenTelemetry to propagate trace context, including trace IDs and span IDs, through standard HTTP headers, such as W3C Trace Context headers.”
ただし、これは must ではなく should であり、 protocol 仕様として trace context 伝搬の具体的な仕組みは定義されていません。
A2A の通信モデル — HTTP + JSON-RPC
A2A の Agent 間通信は、基本的には HTTP の POST / で JSON を送受信している だけです(Agent Card の取得は GET /.well-known/agent-card.json、 streaming 応答には SSE を使いますが、通常の request/response はこの形です)。
この JSON のやりとりに使われているのが JSON-RPC 2.0 という軽量な protocol です。 JSON-RPC 自体はトランスポート非依存な仕様ですが、 A2A の JSON-RPC binding では POST / を endpoint として使います。 REST API では URL path と HTTP method の組み合わせ(GET /users/123、DELETE /orders/456)で「何をするか」を表現しますが、 JSON-RPC では同じ endpoint に送り、 JSON body 内の method field で操作を指定 します。
分散 tracing の観点で重要なのは、 A2A の通信が通常の HTTP request であるという点 です。 HTTP header にそのまま traceparent を載せられるため、 microservice で確立された分散 tracing の手法がそのまま適用できます。
なぜ分散 tracing が必要か
A2A protocol で複数の Agent が連携する構成を考えます。 Agent A がユーザーからの request を受け、 Agent B に委譲し、さらに Agent B が Agent C に委譲する — このとき、各 Agent は独立した service として動作しています。
tracing を導入していない状態では、各 Agent の request が別々の trace ID で記録されます。これでは、ある処理がどの Agent chain に属しているのかを紐づけることができません。
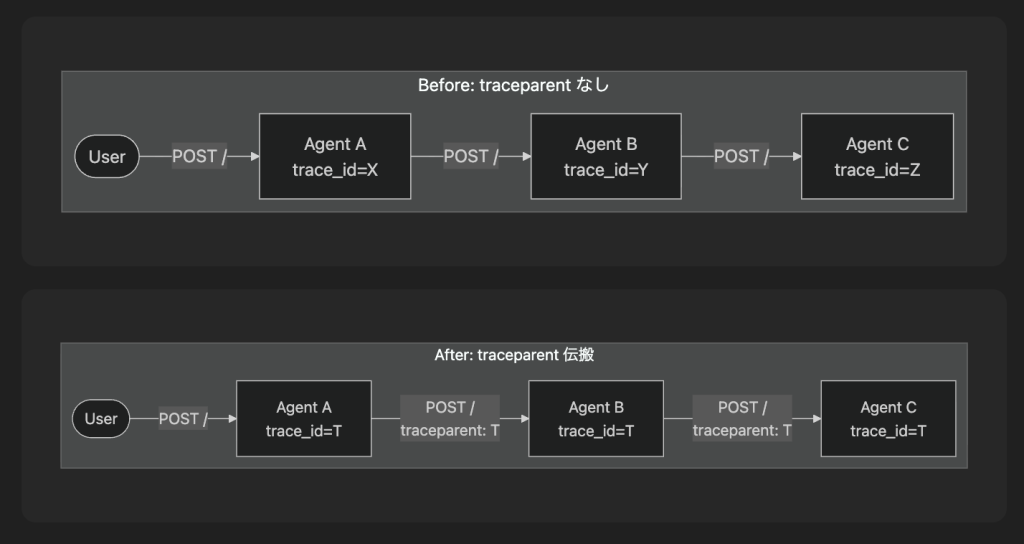
Before では 3 つの Agent が それぞれ別の trace ID (X, Y, Z) で記録され、因果関係が見えません。After では traceparent header の伝搬により 全 Agent が同じ trace ID (T) で記録され、1 つの trace として可視化できます。
これは microservice における分散 tracing と全く同じ課題です。
| microservice | A2A Agent |
|---|---|
| Service A → Service B → Service C | Agent A → Agent B → Agent C |
| HTTP/gRPC で通信 | A2A (HTTP + JSON-RPC) で通信 |
traceparent header で伝搬 | 同じ traceparent header で伝搬 |
| 各 service が独立 deploy | 各 Agent が独立 deploy (別 instance) |
| OTel SDK + HTTP 計装で自動化 | 同じ OTel SDK + HTTP 計装で自動化 |
A2A は HTTP ベースの protocol なので、 microservice で確立された分散 tracing の手法をそのまま適用できます。
architecture
scenario
社内の Agent 基盤を想定します。 A, B, C は全て独立した Remote Agent (例: 異なる Google Cloud instance 上に deploy)です。
- Agent A (窓口 Agent): ユーザーからの request を受け付け、社内総合 Agent (B)に A2A で委譲
- Agent B (社内総合 Agent): text を要約し、専門 Agent (C)に翻訳を A2A で委譲
- Agent C (翻訳 Agent): text を翻訳して返す
各 Agent 間の呼び出しは 固定 pipeline(LLM による routing 判断は行わない)です。 tracing の観点では、3 つの独立 service をまたぐ分散 trace が Cloud Trace 上で 1 つの trace として可視化されること が goal です。
全体構成図

技術 stack
a2a-sdk==1.0.0a0 # A2A protocol v1.0 (Client + Server)
google-genai # LLM 呼び出し (Gemini 2.5 Flash on Vertex AI)
uvicorn # ASGI server
ファイル構成
common/
server.py # create_a2a_app() — AgentExecutor → A2A v1.0 Starlette app
client.py # send_a2a() — A2A v1.0 client (ID token自動付与)
remote_agents/
agent_a/
agent.py # GatewayExecutor — B への A2A 委譲
__main__.py # create_a2a_app() + uvicorn
agent_b/
agent.py # SummaryExecutor — 要約 + C への A2A 委譲
__main__.py
agent_c/
agent.py # TranslationExecutor — 翻訳
__main__.py
main.py # thin client(local用)
docker-compose.yaml # local開発: agent-a(:8080), agent-b(:8001), agent-c(:8002)
makefile # deploy, test-remote, logs-{a,b,c}
Dockerfile # dev / prod のmulti-stage
実装
共通 module
A2A server (common/server.py)
create_a2a_app() は、AgentExecutor を受け取り、 A2A v1.0 準拠の Starlette application を返す helper です。
from a2a.server.apps import A2AStarletteApplication
from a2a.server.request_handlers import DefaultRequestHandler
from a2a.server.tasks import InMemoryTaskStore
from a2a.types import AgentCard
def create_a2a_app(
executor: AgentExecutor,
*,
name: str,
description: str = "",
host: str = "0.0.0.0",
port: int = 8000,
protocol: str = "http",
) -> Starlette:
card_url = os.environ.get("A2A_CARD_URL")
if not card_url:
card_host = os.environ.get("A2A_CARD_HOST", host)
card_url = f"{protocol}://{card_host}:{port}/"
# v1.0 は Protocol Buffers ベース — field の追加は .add() で行う
agent_card = AgentCard(name=name, description=description, version="1.0.0")
interface = agent_card.supported_interfaces.add()
interface.url = card_url
interface.protocol_binding = "JSONRPC"
skill = agent_card.skills.add()
skill.id = name
skill.name = name
skill.description = description
handler = DefaultRequestHandler(
agent_executor=executor,
task_store=InMemoryTaskStore(),
)
app = A2AStarletteApplication(agent_card=agent_card, http_handler=handler)
return app.build()
A2A v1.0 の server は以下の endpoint を提供します。
POST /— JSON-RPC request (SendMessage,GetTaskなど)GET /.well-known/agent-card.json— Agent の能力を記述した Agent Card
A2A client (common/client.py)
send_a2a() は、 remote Agent に A2A request を送信し、 response の text を返す helper です。
from a2a.client import ClientConfig, ClientFactory
from a2a.types import Message, Part, Role, SendMessageRequest
DEFAULT_TIMEOUT = 120 # Cold start + LLM + chain遅延を考慮
def _build_auth_headers(target_url: str) -> dict[str, str]:
"""Cloud Run サービス間認証用の ID トークンヘッダーを返す."""
if target_url.startswith("http://"):
return {} # local (HTTP) は認証不要
try:
import google.auth.transport.requests
import google.oauth2.id_token
token = google.oauth2.id_token.fetch_id_token(
google.auth.transport.requests.Request(), target_url
)
return {"Authorization": f"Bearer {token}"}
except Exception:
return {}
async def send_a2a(url: str, text: str) -> str:
"""remote Agent にtextを送信し、responseを返す."""
headers = _build_auth_headers(url)
async with httpx.AsyncClient(
timeout=httpx.Timeout(DEFAULT_TIMEOUT),
headers=headers,
) as http_client:
client = await ClientFactory.connect(
url,
client_config=ClientConfig(httpx_client=http_client),
)
message = Message(
message_id=str(uuid.uuid4()),
role=Role.ROLE_USER,
parts=[Part(text=text)],
)
request = SendMessageRequest(message=message)
response_text = ""
async for stream_resp, task in client.send_message(request):
# task, status_update, message から text を抽出
...
return response_text or "(no response)"
ポイント:
- Cloud Run service 間認証: HTTPS の場合のみ
google.oauth2.id_tokenで ID token を取得しAuthorization: Bearerheader に付与。 local (HTTP) では認証を skip - 120 秒 timeout: Cold Start + LLM 推論 + Agent chain の遅延を考慮
- streaming 対応:
client.send_message()は async generator で、 response を逐次受信
Agent 実装
Agent A: Gateway (remote_agents/agent_a/agent.py)
Agent A はユーザーからの request を受け取り、そのまま Agent B に A2A で委譲します。自身では LLM を呼び出しません。
AGENT_B_URL = os.environ.get("AGENT_B_URL", "<http://agent-b:8001>")
class GatewayExecutor(AgentExecutor):
"""全requestを Agent B に A2A で委譲する."""
async def execute(
self, context: RequestContext, event_queue: EventQueue
) -> None:
# requestからtextを抽出
user_text = ""
if context.message and context.message.parts:
for p in context.message.parts:
if p.text:
user_text = p.text
break
# Agent B に委譲
result = await send_a2a(AGENT_B_URL, user_text or "(empty)")
# 結果を返す
await event_queue.enqueue_event(
TaskStatusUpdateEvent(
task_id=context.task_id or str(uuid.uuid4()),
context_id=context.context_id or str(uuid.uuid4()),
status=TaskStatus(
state=TaskState.TASK_STATE_COMPLETED,
message=Message(
role=Role.ROLE_AGENT,
message_id=str(uuid.uuid4()),
parts=[Part(text=result)],
),
),
)
)
Agent B: Summary (remote_agents/agent_b/agent.py)
Agent B は text を要約した後、 Agent C に翻訳を委譲します。
from google import genai
from google.genai import types
AGENT_C_URL = os.environ.get("AGENT_C_URL", "<http://agent-c:8002>")
SUMMARY_PROMPT = """You are a summarization agent.
Summarize the given text in 2-3 sentences.
Always respond in the same language as the input."""
class SummaryExecutor(AgentExecutor):
def __init__(self):
self._client = genai.Client(vertexai=True)
async def execute(
self, context: RequestContext, event_queue: EventQueue
) -> None:
user_text = ... # text抽出(Agent A と同様)
# 1. Gemini 2.5 Flash で要約
response = await self._client.aio.models.generate_content(
model="gemini-2.5-flash",
contents=user_text or "(empty)",
config=types.GenerateContentConfig(system_instruction=SUMMARY_PROMPT),
)
summary_text = response.text
# 2. Agent C に翻訳を委譲
translated_text = await send_a2a(AGENT_C_URL, summary_text)
# 3. 翻訳結果を返す
await event_queue.enqueue_event(...)
Agent C: Translation (remote_agents/agent_c/agent.py)
Agent C は chain の終端で、 text を翻訳して返します。
SYSTEM_PROMPT = """You are a translation agent.
If the input is Japanese, translate it to English.
If the input is English, translate it to Japanese.
Output only the translation, nothing else."""
class TranslationExecutor(AgentExecutor):
def __init__(self):
self._client = genai.Client(vertexai=True)
async def execute(
self, context: RequestContext, event_queue: EventQueue
) -> None:
user_text = ... # text抽出
# Gemini 2.5 Flash で翻訳
response = await self._client.aio.models.generate_content(
model="gemini-2.5-flash",
contents=user_text or "(empty)",
config=types.GenerateContentConfig(system_instruction=SYSTEM_PROMPT),
)
await event_queue.enqueue_event(...) # 翻訳結果を返す
Cloud Run へのデプロイ
3 つの Agent をそれぞれ独立した Cloud Run service としてデプロイしています。各 Agent 間は A2A protocol (HTTP + JSON-RPC) で通信し、Cloud Run のサービス間認証 (ID token) で保護されています。

日本語テキストを Agent A に送信すると、Agent B で要約 → Agent C で英語翻訳され、英語の要約が返ります。
分散 tracing の実装
分散 tracing の導入にあたり、以下のファイルを追加・変更しました。
| ファイル | 操作 | 内容 |
|---|---|---|
common/otel_setup.py | 新規 | TracerProvider, Exporter, auto-instrumentation の初期化 |
common/tracing.py | 新規 | TracingExecutorWrapper — Agent レベルスパン生成 |
common/server.py | 変更 | TracingExecutorWrapper で executor をラップ + instrument_app() 適用 |
common/client.py | 変更 | send_a2a() に A2A client SendMessage スパン追加 |
各 __main__.py | 変更 | setup_tracing() の呼び出し追加 |
pyproject.toml | 変更 | OTel 関連 package 追加 |
Dockerfile | 変更 | OTEL_INSTRUMENTATION_A2A_SDK_ENABLED=false 追加 |
方針
A2A は HTTP ベースの protocol であり、 microservice と同じ pattern で trace context を伝搬できます。さらに、Agent Engine / ADK が自動生成する invoke_agent {name} 相当のスパンを手動計装で追加し、 Agent としての振る舞いを trace 上で可視化 します。
| レイヤー | 方法 |
|---|---|
| traceparent 伝搬 (Server) | opentelemetry-instrumentation-starlette で受信 request の traceparent を自動 extract |
| traceparent 伝搬 (Client) | opentelemetry-instrumentation-httpx で送信 request に traceparent を自動 inject |
| Agent スパン | TracingExecutorWrapper で invoke_agent {name} スパンを手動生成 |
| LLM スパン | opentelemetry-instrumentation-google-genai で generate_content gemini-2.5-flash スパンを自動生成 (トークン使用量含む) |
| A2A 委譲スパン | send_a2a() 内で A2A client SendMessage スパンを手動生成 |
| Exporter | opentelemetry-exporter-gcp-trace で Cloud Trace に送信 |
HTTP 計装による traceparent 伝搬で 1 つの分散 trace を構成し、手動 + 自動計装で Agent レベルの可読性 を追加するという 2 層構造です。
traceparent 伝搬の仕組み
分散 tracing を 1 つの trace にまとめる仕組みは、全ての HTTP request に付与される traceparent header の バケツリレー です。
traceparent: 00-<trace_id>-<parent_span_id>-01
^^^^^^^^ ^^^^^^^^^^^^^^
全Agent共通 呼び出し元のspan
具体的には、各 Agent プロセス内で以下の 2 つの auto-instrumentation が動作します。
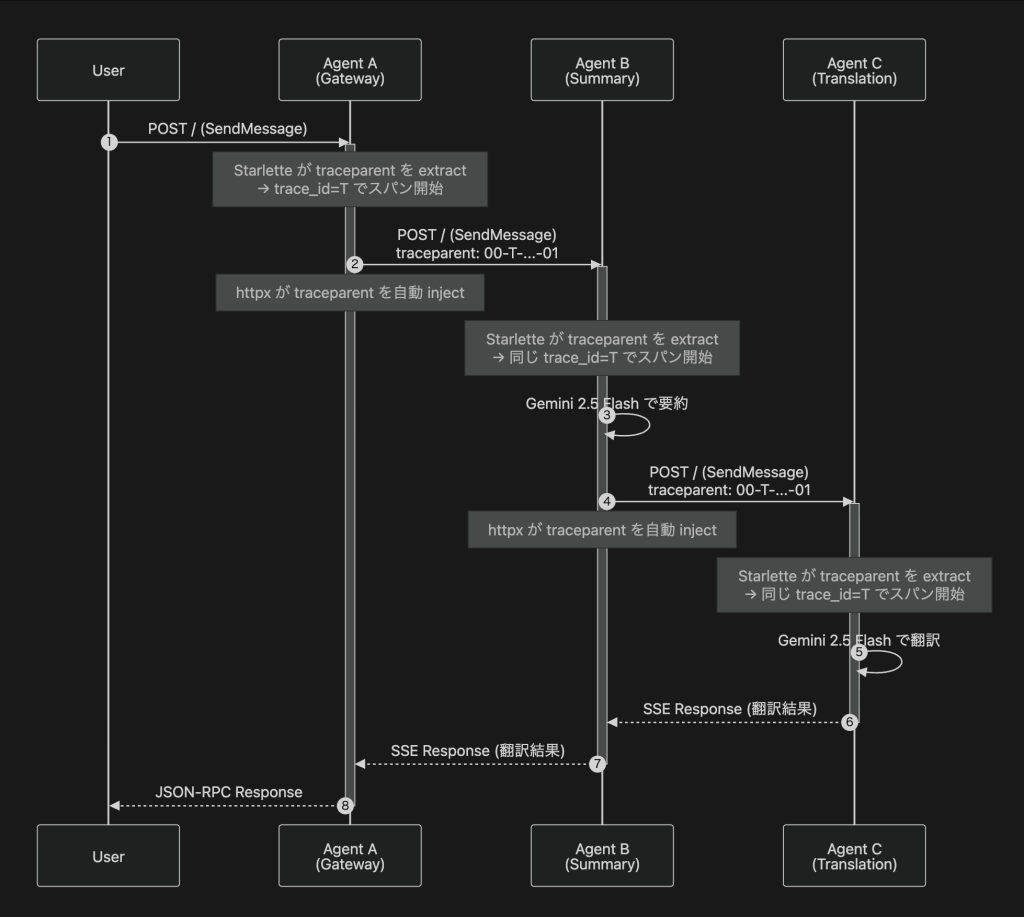
全 Agent で同じ trace_id=T が使われます。Starlette Instrumentor が受信時に traceparent header から trace_id を extract し、httpx Instrumentor が送信時に同じ trace_id を inject することで、Agent をまたいだ 1 つの trace が構成されます。
つまり、やっていることは HTTP client / server の計装だけです。 httpx の AsyncClient が request を送る際に traceparent header を 1 本追加し、Starlette が受信時にその header を読み取る — A2A protocol 固有の仕組みは一切不要で、microservice で確立された HTTP 計装をそのまま適用しているだけです。A2A が HTTP + JSON-RPC ベースの protocol であるからこそ、これが成り立ちます。
追加 package
# pyproject.toml
"opentelemetry-api",
"opentelemetry-sdk",
"opentelemetry-exporter-gcp-trace",
"opentelemetry-resourcedetector-gcp",
"opentelemetry-instrumentation-starlette",
"opentelemetry-instrumentation-httpx",
"opentelemetry-instrumentation-google-genai",
OTel setup (common/otel_setup.py)
setup_tracing() は各 Agent の process 起動時に一度だけ呼ばれ、OTel の基盤を初期化します。
import atexit
import os
import signal
from opentelemetry import trace
from opentelemetry.exporter.cloud_trace import CloudTraceSpanExporter
from opentelemetry.propagate import set_global_textmap
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.trace.propagation.tracecontext import TraceContextTextMapPropagator
def setup_tracing(service_name: str) -> None:
# 1. Resource(service.name + Cloud Run メタデータ)
resource = Resource.create({"service.name": service_name})
if os.environ.get("K_SERVICE"):
from opentelemetry.resourcedetector.gcp_resource_detector import (
GoogleCloudResourceDetector,
)
resource = resource.merge(GoogleCloudResourceDetector().detect())
# 2. TracerProvider + Exporter
provider = TracerProvider(resource=resource)
if os.environ.get("K_SERVICE"):
provider.add_span_processor(BatchSpanProcessor(CloudTraceSpanExporter()))
else:
from opentelemetry.sdk.trace.export import ConsoleSpanExporter, SimpleSpanProcessor
provider.add_span_processor(SimpleSpanProcessor(ConsoleSpanExporter()))
trace.set_tracer_provider(provider)
# 3. Shutdown ハンドラ(Cloud Run の SIGTERM 対応)
atexit.register(provider.shutdown)
def _handle_sigterm(signum, frame):
provider.force_flush(timeout_millis=5000)
raise SystemExit(0)
signal.signal(signal.SIGTERM, _handle_sigterm)
# 4. W3C Trace Context Propagator
set_global_textmap(TraceContextTextMapPropagator())
# 5. httpx auto-instrumentation(traceparent inject)
from opentelemetry.instrumentation.httpx import HTTPXClientInstrumentor
HTTPXClientInstrumentor().instrument()
# 6. google-genai auto-instrumentation(generate_content スパン + トークン使用量)
from opentelemetry.instrumentation.google_genai import GoogleGenAiSdkInstrumentor
GoogleGenAiSdkInstrumentor().instrument()
instrument_app() は Starlette app に受信側の計装と、FlushSpansMiddleware を適用します。
def instrument_app(app):
StarletteInstrumentor.instrument_app(app)
class FlushSpansMiddleware(BaseHTTPMiddleware):
"""BatchSpanProcessor のバッファを request 完了後に即時 flush."""
async def dispatch(self, request, call_next):
response = await call_next(request)
provider = trace.get_tracer_provider()
if hasattr(provider, "force_flush"):
provider.force_flush(timeout_millis=5000)
return response
app.add_middleware(FlushSpansMiddleware)
return app
FlushSpansMiddleware は BatchSpanProcessor のフラッシュタイミング問題を解決するためのものです。Cloud Run ではリクエスト完了後にインスタンスがアイドルに入り、デフォルト 5 秒のバッファ flush を待たずにスパンが欠落する場合があります。
Server 側: Starlette Instrumentor + Agent スパンの適用
create_a2a_app() (common/server.py) で TracingExecutorWrapper による Agent スパン生成と、instrument_app() による Starlette 計装を適用しています。
from common.tracing import TracingExecutorWrapper
def create_a2a_app(executor, *, name, description="", ...) -> Starlette:
# ... AgentCard 構築 ...
handler = DefaultRequestHandler(
agent_executor=TracingExecutorWrapper(executor, agent_name=name),
task_store=InMemoryTaskStore(),
)
app = A2AStarletteApplication(agent_card=agent_card, http_handler=handler)
return instrument_app(app.build())
TracingExecutorWrapper (common/tracing.py) は Agent Engine / ADK の invoke_agent {name} スパンと同名のスパンを手動生成します。
from a2a.server.agent_execution import AgentExecutor, RequestContext
from a2a.server.events import EventQueue
from opentelemetry import trace
_tracer = trace.get_tracer("a2a.agent")
class TracingExecutorWrapper(AgentExecutor):
def __init__(self, executor: AgentExecutor, agent_name: str) -> None:
self._executor = executor
self._agent_name = agent_name
async def execute(self, context: RequestContext, event_queue: EventQueue) -> None:
with _tracer.start_as_current_span(
f"invoke_agent {self._agent_name}",
attributes={"agent.name": self._agent_name},
):
await self._executor.execute(context, event_queue)
async def cancel(self, context: RequestContext, event_queue: EventQueue) -> None:
await self._executor.cancel(context, event_queue)
Client 側: A2A client SendMessage スパン + httpx 自動 inject
send_a2a() (common/client.py) に A2A client SendMessage スパンを手動追加し、httpx Instrumentor が traceparent を自動 inject します。
_tracer = trace.get_tracer("a2a.client")
async def send_a2a(url: str, text: str) -> str:
with _tracer.start_as_current_span(
"A2A client SendMessage",
kind=SpanKind.CLIENT,
attributes={"a2a.target_url": url, "a2a.method": "SendMessage"},
):
headers = _build_auth_headers(url)
async with httpx.AsyncClient(...) as http_client:
client = await ClientFactory.connect(url, ...)
# ... SendMessage request の送信 ...
A2A client SendMessage スパンの子として httpx Instrumentor がスパンを生成し、traceparent header が自動 inject されます。
entry point の変更
各 Agent の __main__.py に setup_tracing() の呼び出しを追加しました。Starlette app の生成 より前 に呼ぶ必要があります。
def main():
setup_tracing("agent-a") # ← 追加: app 生成より前に OTel を初期化
# ... argparse ...
app = create_a2a_app(
GatewayExecutor(),
name="gateway_agent",
description="Gateway agent that delegates to internal agents",
host=args.host,
port=args.port,
)
uvicorn.run(app, host=args.host, port=args.port)
a2a-sdk 組み込み OTel の無効化
a2a-sdk==1.0.0a0 は a2a.utils.telemetry module に OTel 計装を内蔵しています (@trace_class decorator で全 public method を自動計装)。しかし、SDK のスパンは独自の tracer で生成されるため、Starlette Instrumentor のスパンとの親子関係が適切に構成されません。
そのため、SDK の組み込み OTel を無効化し、代わりに TracingExecutorWrapper + GoogleGenAiSdkInstrumentor で Agent レベルのスパンを生成しています。
# Dockerfile (prod stage)
ENV OTEL_INSTRUMENTATION_A2A_SDK_ENABLED=false
Cloud Trace での確認
Before: tracing 導入前
Cloud Run は各 service への HTTP request に対して自動的に trace を生成しますが、traceparent header が Agent 間で伝搬されないため、 A, B, C でそれぞれ独立した trace が生成されます。
| # | Trace ID | Service | Request | Latency |
|---|---|---|---|---|
| 1 | 36a4da34... | Agent A | POST / (E2E 全体) | 92.5s |
| 2 | 64993360... | Agent B | GET /.well-known/agent-card.json | 33.5s (cold start) |
| 3 | 794eeff6... | Agent B | POST / (要約 + C への委譲) | 50.9s |
| 4 | 2f6a5dc7... | Agent C | GET /.well-known/agent-card.json | 49.2s (cold start) |
| 5 | 0409e9dd... | Agent C | POST / (翻訳) | 0.7s |
1 つの E2E request が 5 つの独立した Trace ID に分裂しています。Agent 間の因果関係が trace 上で全く紐づきません。
After: tracing 導入後
OTel + Agent レベルスパン導入後、1 つの Trace ID に全 Agent の 36 スパンが統合 されました。
Trace ID: 6884612c11e436d186e2157afb057641 (36 スパン)
/ (Cloud Run AppServer, Agent A)
└── POST / (Starlette, Agent A)
└── invoke_agent gateway_agent ← Agent 識別
└── A2A client SendMessage ← Agent 間委譲
├── GET (httpx, agent-card B)
│ └── ... (AppServer B + Starlette B)
└── POST (httpx, SendMessage B)
└── / (AppServer B)
└── POST / (Starlette B)
└── invoke_agent summary_agent
├── generate_content gemini-2.5-flash [in=58, out=32] ← LLM + トークン
│ └── POST (httpx → Vertex AI API)
└── A2A client SendMessage ← Agent 間委譲
├── GET (httpx, agent-card C)
│ └── ... (AppServer C + Starlette C)
└── POST (httpx, SendMessage C)
└── / (AppServer C)
└── POST / (Starlette C)
└── invoke_agent translation_agent
└── generate_content gemini-2.5-flash [in=71, out=25]
└── POST (httpx → Vertex AI API)
Before / After 比較
| 観点 | Before (OTel なし) | After (OTel 導入後) |
|---|---|---|
| Trace ID 数 | 5 つ (Agent × request 種別) | 1 つ |
| スパン数 (合計) | 7 (各 trace 1-2 スパン) | 36 (1 trace に集約) |
| Agent 間の因果関係 | なし (別 trace に分裂) | あり (親子スパンで接続) |
| Agent 識別 | ホスト名から推測 | invoke_agent {name} でスパン名に明示 |
| LLM 呼び出し | 記録なし | generate_content gemini-2.5-flash + トークン使用量自動付与 |
| Agent 間委譲 | 別 trace に分裂 | A2A client SendMessage → 子スパンで親子関係表現 |
| traceparent 伝搬 | なし | W3C Trace Context で自動伝搬 |
調査で判明した注意点
A2A v1.0 JSON-RPC の仕様
A2A v1.0 の JSON-RPC は v0.3 と method 名が異なります。message/send ではなく SendMessage のように gRPC style の method 名を使用します。 API document が追いついていない場合があるため、 SDK の source code を直接確認することをお勧めします。
Cloud Run と traceparent の互換性
Cloud Run の LB は独自の infra span を生成しますが、application level の traceparent header には干渉しません。Starlette/httpx Instrumentor level では traceparent が正しく伝搬されるため、custom header によるワークアラウンドは不要です。
BatchSpanProcessor のフラッシュと FlushSpansMiddleware
BatchSpanProcessor はスパンを buffer して定期的に flush します (default 5 秒)。Cloud Run ではリクエスト完了後にインスタンスがアイドルに入り、バッファがフラッシュされる前にスパンが欠落する場合があります。SIGTERM handler (provider.force_flush) はインスタンス停止時のみ発火するため、アイドル状態では効果がありません。
FlushSpansMiddleware をリクエスト完了後に force_flush() を呼ぶ Starlette middleware として追加することで、全スパンが確実に export されるようにしました。
asyncio.create_task() と OTel コンテキスト
a2a-sdk の DefaultRequestHandler は asyncio.create_task() で Agent の execute() を実行します。当初これが OTel コンテキスト切断の原因と疑いましたが、Python 3.7+ では asyncio.create_task() は contextvars を自動コピーする ため、OTel コンテキスト (= ContextVar) は正しく伝搬されます。スパンの欠落は前述の BatchSpanProcessor フラッシュタイミングが原因でした。
Agent Engine / ADK との比較
Vertex AI Agent Engine (ADK) は invoke_agent, call_llm, generate_content, execute_tool 等のスパンを自動生成し、Agent の振る舞いを Cloud Trace で可視化できます。本実装では A2A + Cloud Run 構成で ADK と同等の可読性を目指しました。
| 観点 | ADK (自動) | 本実装 (A2A) |
|---|---|---|
| Agent 呼び出し | invoke_agent {name} | invoke_agent {name} (手動: TracingExecutorWrapper) |
| LLM 呼び出し | call_llm + generate_content の 2 階層 | generate_content gemini-2.5-flash の 1 階層 (自動: GoogleGenAiSdkInstrumentor) |
| トークン使用量 | gen_ai.usage.* 自動付与 | gen_ai.usage.* 自動付与 |
| Agent 間委譲 | invoke_agent sub_agent (インプロセス) | A2A client SendMessage → httpx → 別 Agent (HTTP 越し) |
| 計装の手間 | ゼロ (全自動) | Agent + A2A 委譲は手動、LLM は自動 |
ADK はインプロセスで全て完結するため計装がゼロですが、A2A は HTTP で Agent を分離するため手動計装が一部必要になります。一方で、A2A 固有の A2A client SendMessage スパンにより、HTTP 越しの Agent 間委譲が trace 上で明示的に可視化される という利点があります。
所感
- A2A は HTTP ベースなので、microservice の分散 tracing がそのまま使える: Starlette + httpx の 2 つの auto-instrumentation で、application code に traceparent を意識した記述を一切書かずに伝搬を実現できた
- Agent Engine / ADK と同等の可読性を手動計装で実現できた:
TracingExecutorWrapperでinvoke_agent {name}、GoogleGenAiSdkInstrumentorでgenerate_content gemini-2.5-flash+ トークン使用量。ADK のgenerate_contentと同名のスパンで同等の情報が Cloud Trace で見られる opentelemetry-instrumentation-google-genaiが強力: LLM のモデル名、トークン使用量、finish reason、gen_ai.system(vertex_ai) まで自動付与される。手動でこれらを取得する必要がない- Cloud Run × BatchSpanProcessor の落とし穴: リクエスト完了後にスパンが欠落する問題は
FlushSpansMiddlewareで解決。Cloud Run 上で OTel を使う場合は注意が必要
おわりに
本記事では、 A2A protocol v1.0 を使った 3 つの Remote Agent の chain 構成に対し、 OpenTelemetry による分散 tracing を導入して Cloud Trace で可視化する方法を紹介しました。
実装のポイントは以下の通りです。
- Starlette / httpx Instrumentor で
traceparentの extract / inject を自動化 TracingExecutorWrapperでinvoke_agent {name}スパンを手動生成GoogleGenAiSdkInstrumentorでgenerate_content gemini-2.5-flashスパン + トークン使用量を自動生成FlushSpansMiddlewareで Cloud Run 上のスパン欠落を防止- a2a-sdk の組み込み OTel は無効化 (
OTEL_INSTRUMENTATION_A2A_SDK_ENABLED=false)
A2A protocol は HTTP + JSON-RPC ベースであるため、microservice で確立された分散 tracing の手法をそのまま適用できます。さらに Agent レベルのスパンを追加することで、Agent Engine / ADK と同等の可読性を実現できました。Agent 基盤が本番運用に向かう中で、こうした observability の確保は今後ますます重要になるでしょう。