
- 第一部:「監視からモダンなモニタリングへ、なぜユーザー企業こそDatadogを使うべきなのか?」Datadog Japan 青木氏
- 第二部:「JCBにおけるモニタリング監視について」株式会社ジェーシービー 笹野氏
- 第三部:「SREに基づいた監視運用の考え方」株式会社スリーシェイク 手塚
- Q&A
第一部:「監視からモダンなモニタリングへ、なぜユーザー企業こそDatadogを使うべきなのか?」Datadog Japan 青木氏

Datadogは、「インフラストラクチャモニタリング」「APM」「ログ」の3つを高水準で提供し、連携できるのが大きな強みです。IT運用、監視にかかわるところがプラットフォーム上でエンハンスされています。
最新の複雑化されたアプリケーション環境においては一元的な対処が難しくなり、対処が上手くできなければエンドユーザー様にも不利益を与えかねません。
Datadogを活用すれば膨大なデータをプラットフォーム上に集めて一元化できます。特異な言語が不要なので、ビジネスやサービスの向上へフォーカスでき、問題が発生した場合もいち早い解決が可能です。
今後もDatadogはIT運用やDXに伴う複雑な環境をDatadog上に集約し、オペレーションを改善できる取り組みを目指します。ユーザー様こそデータドッグを主要的に運用すべきという観点では、ベンダーがやりたがらない新しいことに対してユーザー様が問いかければ、新しい機能を活用して頂けるのではないかと思います。
第二部:「JCBにおけるモニタリング監視について」株式会社ジェーシービー 笹野氏
本日は現在JCBが持っている課題に対しての新規プロジェクトの発足と、プロジェクト内でJCBが行っているモニタリングとSREチームの取り組みの2点をセットでお話ししたいと思います。
JCBでは「ビジネス全体のスピード感の欠如」が課題として挙げられています。考えられる原因は「案件が承認されるまでの複雑なプロセス」や「スピードよりも品質重視の考え」などです。
新規プロジェクトでは以下のような対策を取っています。
- 出島戦略
- 既存の仕組みをスクラップ&ビルドしない
- ゼロベースでプラットフォームからデザイン
- 母体と異なるルールでプロセスを設計・実践
具体的には、以下のものをすべて独自で用意して対応しています。
- 開発のリスク管理
- チーム体制・組織
- サービスのアーキテクチャ
- プラットフォーム
- 開発使うツールや端末
JCBでは、プロジェクトによってできあがったプラットフォームのモニタリングにDatadogを使用しています。
Datadogを導入してよかった点は、以下の3つです。
- 平均検出時間(MTTD)の短縮
- リモート下でのオンコール対応の促進
- チーム間での共通認識化
Datadogでどのようにアラート検知しているかというと、アラートレベルに応じて通知設定を策定し、対応が必要な場合にはオンコール担当者に連絡が行くようにしています。運用していく中で、日々の改善としてレベル感の変更に取り組んでいるところです。
いくつかグループ分けしているチームの中でDatadogを実際に見ているのは、インフラレイヤーだけではありません。プラットフォームチーム、SREチーム、アプリケーションチームもDatadogを見ているのが現状です。
プラットフォームチームは、インフラリソースにインシデントが発生したときにどの対象か、どこに負荷がかかっているか調査する目的で見ます。アプリケーションチームは、自分たちが使っているリソースを見たりAPMを活用したりしています。Datadogを主管しているのが、SREチームです。各チームがつくっていくダッシュボードを一緒に設計し、各チームが触ったサービスレベルをダッシュボード化しています。
次は、Datadogをはじめとして様々なツールを入れた結果、オンコール対応がどれだけ変わったか、既存サービスの運用をしたメンバーにヒアリングして比較しました。結果として、早期検出と初動調査ができる量が増えています。
夜間を前提とした場合、既存のサービスでは夜間でも出社して詳細調査が必要になることがありました。Datadogを導入すると、初動調査の部分でモニタリングツールを手元で見られることが大きく、画面上で細かい調査が可能です。夜間出社すべきケースもありますが、結構な範囲でDatadogや他のサービスで取れる情報で対応できています。
実際にAPMで利用していますが、Datadog上でエラーが起きたが大丈夫かどうかの判断まで完結でき、極力どこでも調査できる仕組みとなっているのが現状です。
SLIとSLOも非常に重視していて、各自サービスで策定実施してモニタリングに落とし込む取り組みをしています。ここで大事なのが、SREも一緒に認識することです。インシデントが発生したときも、まず影響が出ていないか立ち返れるように、SLOのダッシュボードのテンプレートを使用しています。
目指しているのは、インシデントが発生したらDatadogを見ながら色々なリソースの状況を確認するという運用方法を取れる仕組み作りです。
最後にまとめですが、システム開発運用はどんどん変わっていくため、自動化やツール活用してインシデント対応の質、スピードを向上させる必要があると考えています。
第三部:「SREに基づいた監視運用の考え方」株式会社スリーシェイク 手塚

本日ご参加の中でSRE知らない方もいらっしゃるかと思いますが、SREはグーグルが提唱した運用チームの設計のあり方や組織です。グーグルでは「ソフトウェアエンジニアに運用チームの設計を依頼したときにできあがるものが最終的にはSREだ」と言っています。

Opsの現場では以下のような問題があるかと思います。
- 煩雑で繰り返しの多い手作業
- 障害対応のメンバーの過負荷
- システム改変の難しさでリリーススピードが遅い

グーグルが実践しているSREを取り入れると、以下のように問題が解決できます。
- 自動化の推進による煩雑な作業の削減
- オンコール対応の過負荷の軽減
- 信頼性を担保しつつ素早いリリースサイクルを実現

SREの中では、大きく3つの指標を用いてシステムを見ます。
SLI:サービスレベル指標(システムの良し悪しを判断する指標)
SLO:サービスレベル目標(チーム内組織内での目標値)
SLA:品質保証(対外的な保証値)
特にSLOの部分にフォーカスをおいて運用します。

SLO/SLIの運用はメリットが見えにくいので、簡単に図式化しました。天秤のような考え方で、注力ファクターを錘(おもり)と捉えます。
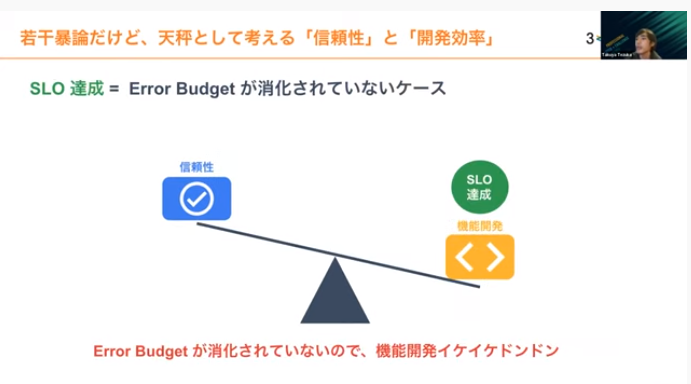
SLOを達成していればエラーバジェットが消化されていないので、どんどん機能開発しようという考え方になります。
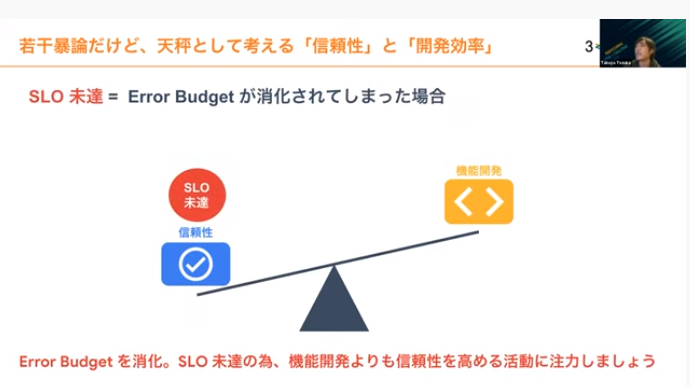
SLO未達の場合はエラーバジェットを消化しているため、機能開発よりも信頼性を高める活動に注力します。

絶対統一期間や開発優先など、ビジネスサイドで決め手となるロジックがなかったかと思います。SLOを導入し業務ハンドリングすると、開発と運用改善の優先順位をつけやすくなるのがメリットです。

上質なSLOを達成するには指標となるSLOを設定しなければならないので、メトリクス監視やいかにして可視化できるかが大事です。
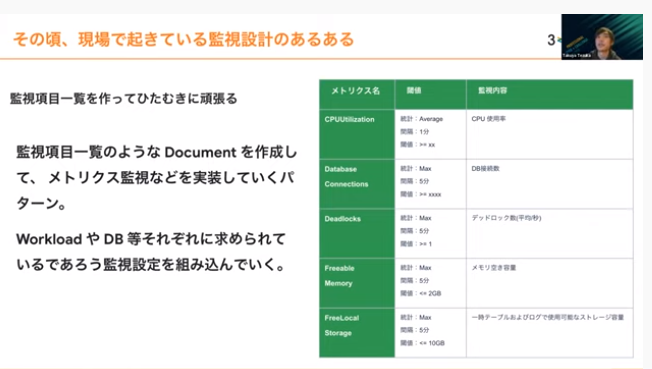
上記は実際に現場で監視運用・設計する際に、監視項目一覧のドキュメントをつくってメトリクス監視を実装していくパターンです。例としてAWSの監視項目一覧を挙げていますが、運用していく中でCPUが跳ね上がり、システム目線で見るとシステム異常が起きている場合もあるでしょう。
一方サービスレベル視点でユーザーに影響があるかを見るとリンクしておらず、システム的には異常が起きているはずなのにサービス上では異常なしといったケースがあります。または外から見ると異常があるのに中から見るとわからないような、つじつまが合わないという経験もあるかと思います。
つじつまが合わないときに、SREとして解決する方法を導いてくれるのがクリティカルユーザージャーニーです。ユーザーが自社サービスの上でどういった行動をしたいのか、一番大切な機能群をクリティカルユーザージャーニーと定義しています。
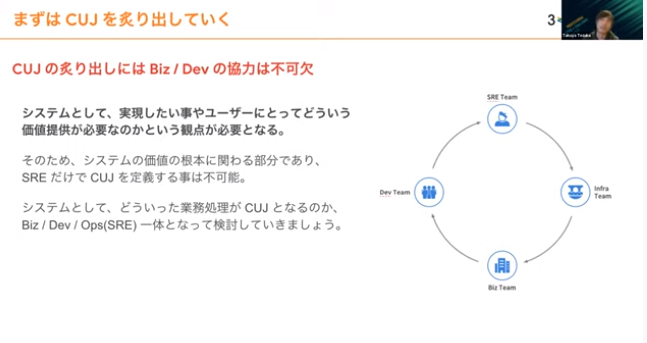
クリティカルユーザージャーニーのあぶり出しは、SREや運用チームだけでは難しい部分があり、Biz/Devとの協力が不可欠です。クリティカルユーザージャーニーという考え方をもとに監視運用、監視実装をすれば、ユーザー目線で具体的にどのような価値提供ができているのかを取り入れた監視が実装できます。
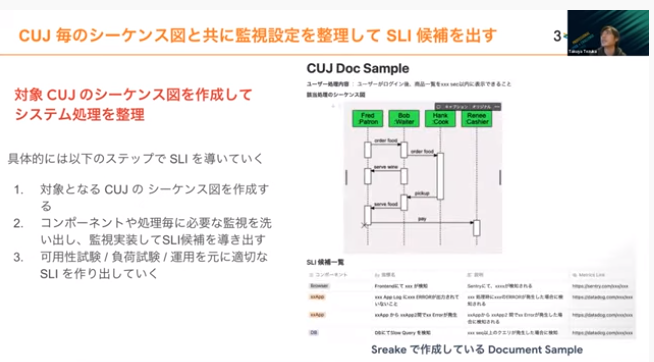
我々が支援する際には、クリティカルユーザージャーニーをもとにシーケンス図を書き出し、システム処理を整理するという観点で監視実装します。この後説明しますが、Datadogでいうとモニタリングローリング、APMなどの機能を使いながらどこが監視できているのか、できていないのかを整理するやり方です。重要と思われる指標を、SLI候補として運用します。

監視の考え方のステップ1として、監視項目一覧の中から監視実装し、CUJに基づいたユーザー目線でどういう監視をするべきか実装する流れが大事です。どういった価値をユーザーに与えていきたいのかは常に変わるので、継続的に運用の中で回しながらSLO/SLIの品質を高めます。システム目線よりもユーザー目線で常にシステム運用をしていく考え方が大事です。

実際Datadogで実装していく中で特にどのような機能を特に使うべきかお話させていただきます。

モニタリングやロギングはよく語られる部分なので、今回は特にSyntheticモニタリングとAPMに特化して紹介します。
SyntheticモニタリングはDatadogの中でも比較的新しめの、高度な外形監視ができる機能です。APMはアプリケーションパフォーマンスモニタリングのことで、アプリケーションレベルで異常調査しやすくなる監視方法になっています。
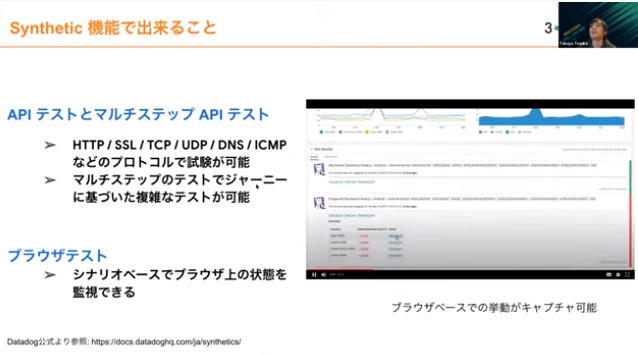
Datadog のSyntheticでできる1つめの機能が、APIテストとマルチステップAPIテストです。HTTPやICMPなど様々なプロトコルに対応しています。先ほどユーザージャーニーに基づいた監視が必要と話をしましたが、マルチステップでテストができるのがメリットです。ステップをくんだ監視実装がUI上でも比較的簡単にできます。
もう1つが実際のウェブブラウザの動きや状態を監視できるブラウザテストです。ブラウザの状態がどうなっているか見られる便利な機能なので、ぜひ使っていただければと思います。
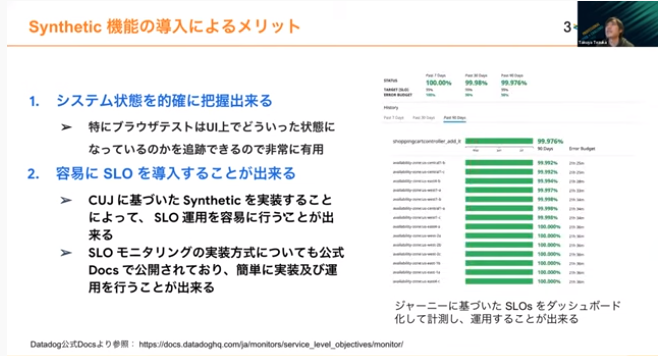
Syntheticを入れると、システムの状態を的確に把握できます。特にブラウザテストでブラウザの動きをキャプチャして追跡できると、どこに問題があるかわかりやすくなるのがメリットです。CUJに基づいたSyntheticを実装するだけで、SLO自体の運用が比較的簡単にできます。SLOの運用を最低限したい場合でも、導入のハードルが低い状態で実装が可能です。
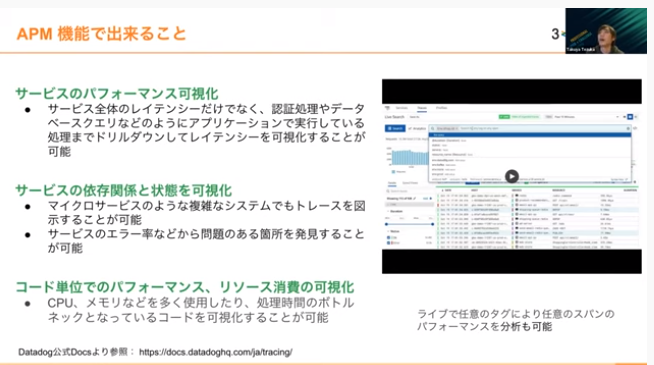
APM機能では、サービスのパフォーマンスを可視化できるのが大きなメリットです。サービス全体のレイテンシーだけではなく、認証処理やデータベースクエリなど深く入り込んだパフォーマンスモニタリングができます。
監視実装の考えかたの中で説明したように、APMを入れることでシーケンス図を基に考える際により鮮明にわかりやすくなるのがよい部分です。
マイクロサービスアーキテクチャのような複雑なシステムもトレースできるので、非常に便利です。サービスのエラー率の中から、問題のある個所も発見できます。ライブで任意のタグで検索できる機能も活用すると、実際障害が起きている現状の中でも追跡しながら解析できるのも大きなメリットです。

現場レベルで話をすると、実際にAPMを使う際に運用する部隊とアプリケーションの部隊が分かれてしまうケースも多いのではないでしょうか。部隊が分かれるとAPMを導入しようとしてもハードルが高いと感じがちですが、Datadogなら比較的簡単に導入できます。
Datadog AgentでAPM機能を有効化し、アプリケーションコードを見て改修が必要なだけで、大きな処理は発生しません。とはいえ、後回しになるケースも多く見られます。
システム開発をしながら開発の序盤からAPMを入れようと考えると、開発者にとってもためらわれるケースがあります。入れるタイミングとして我々がおすすめしているのは、負荷試験のときや、非機能関連の試験をするタイミングです。
負荷試験ではアプリケーションで実装し、負荷をかけて原因を特定しますが、APMの導入により、迅速に原因を特定しやすくなります。結果として、開発スピードを向上させられるのがメリットです。
アプリチームと連携は大事ですが、負荷試験のステップの中から部分的にでも導入していて、スピードの向上をアプリチームの方にも体験頂く方法もあります。
APMのメリットを理解してもらってから組織全体に広めるステップができると、品質の向上や開発効率の向上につながるでしょう。
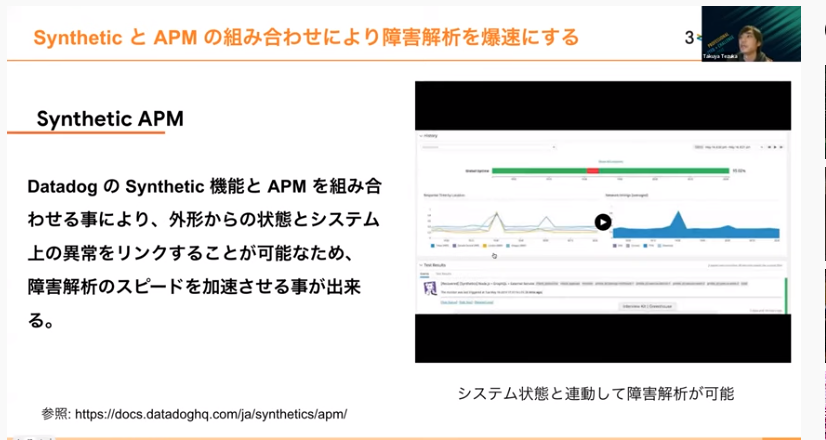
Datadogの公式にもあるように、SyntheticAPM Synthetic機能とAPM機能の組み合わせで外からのシステム状態と中がどうなっているかリンクしやすくする機能が便利です。
SyntheticモニタリングとAPMを導入すれば問題が起こったときの原因究明までが爆速になり、比較的簡単にSREにおけるSLO運用や監視の考え方を加速できます。
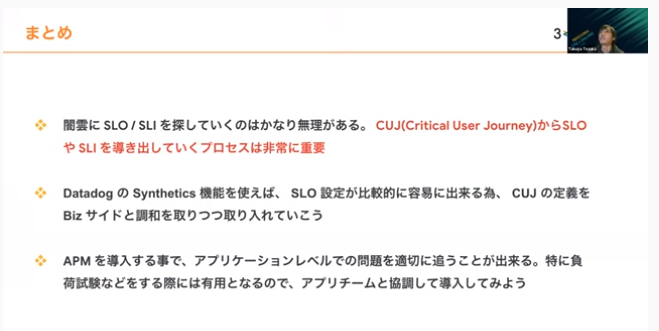
最後にまとめです。闇雲にSLOの考え方で監視実装すると本当の原因が何なのかが分かりにくくなりますが、CUJの中からSLO/SLIを導き出すと明確になります。SLO運用の中でSynthetic機能を使えば、容易に導入できておすすめです。APMの導入によってアプリケーションレベルでの問題のトリアージが使いやすくなるので、ぜひアプリチームの方と協調しながら導入をご検討ください。
Q&A
Q1. アラートを設定していくうえでどのように設定項目を決めるのがよいですか?
A1.アプリケーションに特化したSLOの考え方をとって、重要視する値を定義して優先度づけすることが大事です。問題が起きたときに細かくチューニングを継続して、SREなのか、運用していくメンバーがやり続けていく必要があります。
Q2.既存の設備をスクラップ&ビルドしないということはどういうことですか?
A2.既存の運用や基盤に我々が作りたいというサービスをのせるという考え方だと、既存のルールに乗っかる必要があり全部の課題を一気に解決するのは難しいと思います。基盤や設定運用、開発の方式もモーターフォール中心でやっていたのを、今はアジャイルの方式で進めています。
Q3. DataDog以外にもSaaS系監視製品は存在するかと思いますが、DataDogを選んだ決め手はありますか?
A3.インテグレーションの量や、我々が他で連携するようなSaaS系サービスも問題なくインテグレーションできるところです。実際にエージェントをいれてみてという設定も非常にスムーズにいきました。スモールスタートで取り組もうという考え方がある中で、コスト管理も見合いました。初期費用で大きなイニシャルがかかるのではなく、使うところでお値打ちに感じたのも選定の大きな点です。
今の質問に関して我々のお客様の事例でいうと、監視部分は統合した方が運用負荷が少ないというケースがあります。

東京在住のソフトウェア開発者、Motouchi Shuyaです。
システムの開発・運用・最適化が好きです。