この記事では、SRE提唱、SREサービス提供、SREの大組織での導入について語り尽くしたイベントを要約しお伝えします
2021/9/9 「SRE Gaps 理論と実践からSREを再考する」イベントリポート

先日、『SREの探求』刊行記念として実施されたオンラインイベント、「SRE Gaps 理論と実践からSREを再考する」についてのイベントリポートです。
講演は、『SREの探求』の監訳者であり、外資系ソフトウェア企業で開発者向けマーケティング(デベロッパーアドボケイト)として勤務する山口能迪さん(@ymotongpoo)、当社スリーシェイクでSREサービス事業部の部長である手塚卓也 (@tt0603)、そしてNTTデータでデジタルペイメント開発を行う矢口拓実さん (wantedly) がそれぞれ講演・パネルトークを行いました。
主催はForkwellの重本湧気さん (@xigemoto)、コンテンツスポンサーは当社スリーシェイク、モデレーターも当社エンジニア @nwiizoでお送りしました。
なお、イベントの動画はこちらからアーカイブ配信されていますので、ご興味ありましたらぜひお待ち下さい。
- 基調講演: 外資系ソフトウェア企業 デベロッパーアドボケイト 山口 能迪 氏
- 講演1「Sreake流 SREの始め方」株式会社スリーシェイク Sreake事業部 部長 手塚 卓也氏
- 講演2「大規模組織のSREが果たすべきミッション」株式会社エヌ・ティ・ティ・データ ITSP事業本部 カード&ペイメント事業部 デジタルペイメント開発室 主任 矢口 拓実氏
- パネルトーク / 事例講演への質疑応答
- SREセミナー案内
基調講演: 「SREの理念と原則」
外資系ソフトウェア企業 デベロッパーアドボケイト 山口 能迪さん
先日、『SREの探求』という本を監訳しました。

日本では、過去に翻訳刊行された『SRE サイトリライアビリティエンジニアリング』『サイトリライアビリティワークブック』を読んで、SREに取り組む企業が増加しました。しかし、これらの本で言及されている事例はほとんどがGoogleの事例であり、「Googleだからできたんでしょ」「我々の会社では無理」といった諦めに似た感想をよく伺いました。
日本のエンジニア組織に対して、どのように良い情報を提供するのがよいかと思っていたところ、この『SREの探求』という本に出会いました。この本は、Google以外の会社がSREを導入実践する内容がメインになっております。本の内容については本日詳しくは話しませんが、ぜひ手にとって見ていただければと思います。
本日は、SREの概念的な話を共有させていただきます。
まず、SREとは何をするものか、ですが、「SREとはシステムの信頼性を確保するためのシステム開発運用方法論」です。システムの信頼性は、不確実性や変化により低下します。この不確実性をもたらすのは、システムの開発者や運用者、ならび外からアクセスするユーザーといった人間です。本日は、極力人間に依存しないようにするために、SREは何をやっているかについてお話します。
SREのキャッチフレーズとして、「ヒロイズムを取り除く」というキーワードが当てはまります。これは、システムに携わる人は「障害などに対処して、システムを救う人」のような能力の使い方をするのではなく、「客観的なルールに基づいて判断させ、勝手に安定する状態を作る」ことが望ましいという意味です。
人に依存しないためには、ソフトウェアの問題として解決すべきだという点です。ソフトウェアの問題とは、再現性が高い、スケールする、自動化できる、抽象化できる、といった利点を指します。例えば、「人間がしなくても良い作業で、ビジネスインパクトがある手作業(トイル)」の削減をソフトウェアに任せるのは最も有効な手段です。
さらに、作業をソフトウェア化できれば、もう一歩進んだ自動化も可能です。例えば、ソフトウェアのビルドを行う際の継続的インテグレーションや継続的デプロイメントや、アラートの自動化、データパイプラインならびバッチ処理などがあります。こうした自動化により、人間に依存する部分が減ります。
次に、人間に依存しないためには数値化・文書化された共通ルールが必要です。これらは、客観性・再現性を高め、継続的な改善に寄与するというメリットがあります。
- SLIとSLO
- SLOの範囲内であれば新規開発やトイル削減に時間を割き、SLO違反の場合はシステム安定化に注力する。
- エラーバジェット
- 開発において予算という考えを取り入れて数値化し、他の部署にもわかってもらいやすくなる
- インシデント管理
- 一番エンジニアリング能力が高い人が徹夜で解決して「良かったね」という対処でなく、「誰がやっても80点取れる」プロセスとして確立する
- 運用手順書(プレイブック/ランブック)
- 誰が行っても対処できる手順書を準備することで、暗黙知を共有する。
しかし、これらの前提として大事なのは「人間が体力的・精神的なパフォーマンスを最大に発揮できる」ということです。
体力面ではアラート・オンコール戦略が重要です。「アラートが出た結果、特に問題なかった」ということが続いた結果起こる「オオカミ少年アラートの見直し」「アラートの適合率」「バーンレートの導入」「アラートの頻発を防ぐためのSLO見直し」などが重要です。また、「冗長構成のサーバーの1台が落ちた」場合に、本当にオンコール対応が必要なのか、通常業務時間で直せば良いのではないか、という判断も必要です。
次に精神面です。障害が発生した際に誰かを責めるのではなく、色々な人が意見を言って、その中で最善のものを出して直すという状況、環境作りが大切です。これをシステムの問題と考えて解決する上で、ポストモーテムの実施と共有は改善のチャンスとなります。
講演1「Sreake流 SREの始め方」 株式会社スリーシェイク Sreake事業部 部長 手塚 卓也さん
我々は、お客様のSRE組織の立ち上げや導入、コンサルティングを実施する際にロードマップを使っています。
- SREチームの定義
- SREの開始
- SRE実践
- SREの発展と継続
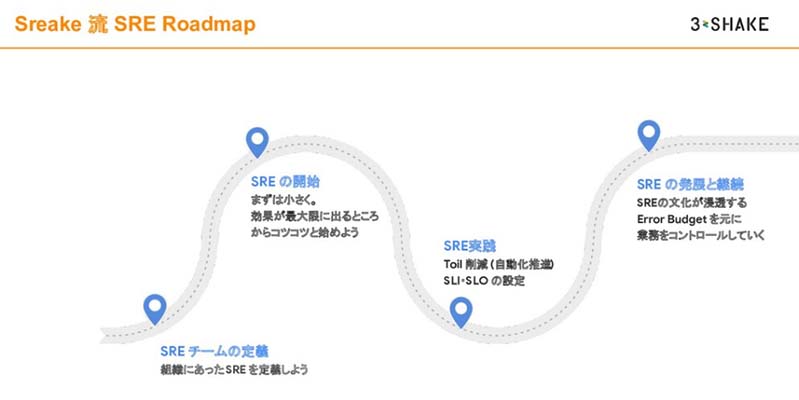
今回は、SREの始め方ということで、「SREチームの定義」と「SREの開始」にフォーカスを置いてお話しします。SREに関連する用語は「SLO/SLIの定義」「適切なオンコール」「自動化の促進」などたくさんありますが、結局「SREは何が美味しいのか」について触れていきます。
まず、既存の運用で抱えている問題を3つ抽出します。
- 煩雑で繰り返しの多い、愛のこもった手動の運用作業
- 日々追われる障害対応とメンバーへの過負荷
- 守りを重視するが故にリリーススピードが遅い
SREを実践するとこれらを解決できるのではないかと思います。トイルの削減、適切なオンコール、エラーバジェット、業務ハンドリングで過負荷軽減、信頼性を担保しつつ素早いリリースを実現するといった点です。これらをソフトウェア・エンジニアリングの手法で解決できることがSREの美味しさではないか、と個人的に思っています。
SREをはじめるにあたっての必要な要素は以下の3点です。

1つめの「システムの性質」ですが、信頼性をどこまで追求しなければならないシステムなのか、という点を指します。SREにおいてSLO 100%を目指すのはアンチパターンですので、これに労力を割きすぎるのは望ましくありません。言い換えると、「お客様が満足する程度の品質と効率性のバランスを満たす」、そのバランスを取ることがSREではないかと私は理解しています。
2つめは「組織文化」です。class SREは、DevOpsを実装するという表現がありますが、例えば、「組織のサイロ化をなくす」「失敗を当たり前のように受け入れる」といったものです。SREの実装にあたってはこういう手法を受け入れる土壌があるか、なければ作れるか、また他のチームからの理解を得て協業できるか、という点が非常に大事です。
3つめは「チームのスキル」です。インフラエンジニアが進化して、SREエンジニアが誕生すると理解している組織も多いようですが、本来はこうではありません。DevOpsロードマップでは「プログラム言語の習得」「異なるOSのコンセプトを理解する」といったポイントが9つ語られています。
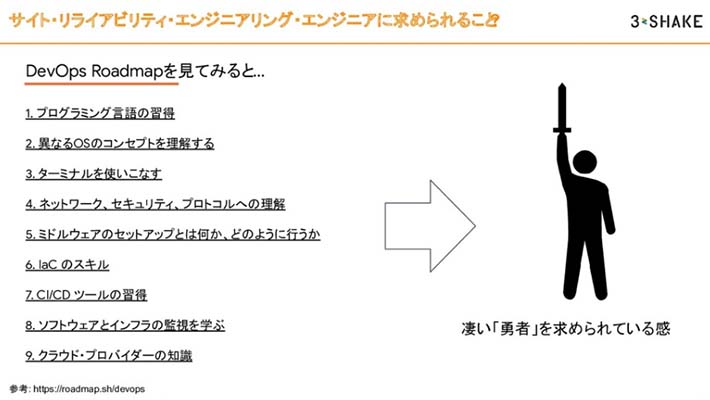
これは、すごい「勇者」を求められている感じがあります。これらを全てできる人は世の中にどの程度いるか疑問です。
SREチームに求められていることは、「勇者のパーティー」のイメージと思っています。例えばGoogleでは、ソフトウェアエンジニアリングが40-50%で、残りがUnixやネットワーク系の知識があるメンバーとされていますが、この構成もシステムによって変わると思います。「チームSRE」のイメージは、魔法使いがソフトウェアエンジニアで、戦士がインフラエンジニアで、僧侶がネットワークエンジニアで、勇者が何でもできる人、みたいな感じですね。
我々がお客様をご支援する中でよく言っているのが、「小さく始めましょう」ということです。やることは多いですし、スキルや文化を変えるのは労力がいる作業なので、小さく始めて、「SREチームとして僕らはできるぞ」という成功体験を得るのが非常に大事と思います。よって、新規のサービスとか、手が付きやすいサービスを対象に取り組みを始めると、SREを始めやすいのではないかと思っています。また、SRE チームの評価に役立つレベル別チェック リスト なども参考になるのではないかと思います。
次に、SREの実践内容です。いくつか簡単に見ていきましょう。

SLIとSLOについてですが、最終目標としては、SLOを定義して、それをもとに業務ハンドリング、エラーバジェット管理をしたいという話になります。「上質なSLO」を設定するためには、指標となるSLIを作ることが非常に大事です。つまり、あらゆるメトリクスをしっかり収集して可視化できるようにすることです。
運用体制整備・インシデント管理・効果的なアラートに関してですが、そもそも「障害解析に対してしっかり追跡できるシステムができている」ことが大事です。そして、特定個人を非難しない文化であることが、何より大切です。
次に、CI/CD(継続的インテグレーション・継続的デリバリー)を行う目的ですが、リリースサイクルの向上と信頼性の担保という異なる2つを両立させるためのアプローチです。資料をご覧いただければと思います。

最終的に大事なポイントとしては、情報収集して分析できることです。SREでは、データドリブンな世界にする必要があります。データが集まっていない状態では、闇雲にSLOの話が繰り広げられるような辛い世界になってしまいます。こうならないために、最初はデータ収集しながら、可視化を目指しつつ、乾式版の高陸、CI/CDの仕組み、トイルを特定するチケット管理などを実践する必要があります。
まとめは3点です。
- そもそも、SREでないとダメなのかを追求し、何を目的とするかを理解しましょう。
- 敵を知り己を知れば百戦殆うからず。組織文化、チームの性質、チームのスキルを理解したうえで、SREを始めましょう。
- SREを始めるときはなるべく小さく、手を付けやすいところから始めましょう。
講演2「大規模組織のSREが果たすべきミッション」
株式会社エヌ・ティ・ティ・データ
ITSP事業本部 カード&ペイメント事業部 デジタルペイメント開発室 主任 矢口 拓実氏
私のセッションは、我々のような会社が「SREをやってみた」系の事例紹介としてお話しいたします。
私の所属組織ですが、決済サービス、金融業界です。既に30年以上やってきた「CAFIS」(クレジットカードを中心とした決済システム)がありますが、この組織の中で我々がデジタル組織を発足させました。現在決済戦国時代で、◯◯ペイなどがたくさん登場していますが、これらに合わせてビジネスプロセスも変えなければと考えています。
我々は2018年から「SAFe」という、スクラム開発を拡張したような大規模Agileフレームワーク (500名) を活用しています。またSRE組織も発足させ、現在では30名に成長しています。

SREで目指すところですが、我々はGoogleを目指しているわけではありません。目下組織で進められているDX、クラウド化が、ビジネス的に失敗する状況を回避することを目的としています。
今回は、オンプレからの移行で想定される失敗パターンとして、特に重要な「信頼性(可用性)の低下」にフォーカスしてお話しします。我々はAWSをがっつり使っていますが、いわゆるweb三層みたいなモデルをそのまま持ってくると、基本的に可用性は低下する、と確信を持っています。
決済業界だと可用性は超重要なので、「落ちてしまうなら、クラウドは無理」という意見に対して、「クラウドの信頼性を高める(信頼性を高めてクラウド化を実現させる)」アプローチを取っています。
決済業界では、最新のクラウドサービスなどで用いられる技術と大きなギャップがあります。このため、いきなり多くの最新技術を導入するのはリスクが高すぎるという判断となります。こうなると、「オンプレ環境をそのままクラウドに持っていく(中途半端なクラウド化)」というケースが多いのですが、これは結構失敗するケースが多いと思っています。
我々の技術負債があまりに溜まっていたので、この解消ストレッチを行う上で、「スリーシェイク様と初期から協業」ならび「All Kubernetes化」が重要となってきます。

我々のSREに関する取り組みですが、はじめに手塚さんをはじめとするスリーシェイクの方にがっつり入っていただきました。そして、当社のSRE組織のメンバーに対して「SREを行う上で基盤となる技術」のキャッチアップを行って頂きました。これが大きかったかなと思っています。これに対応する形で、新しい拠点を渋谷に作り、全員にMacbook支給、IaC (Inftrastructure as a code) できなかったらデプロイしない、Excel禁止といった改革、対策を行いました。
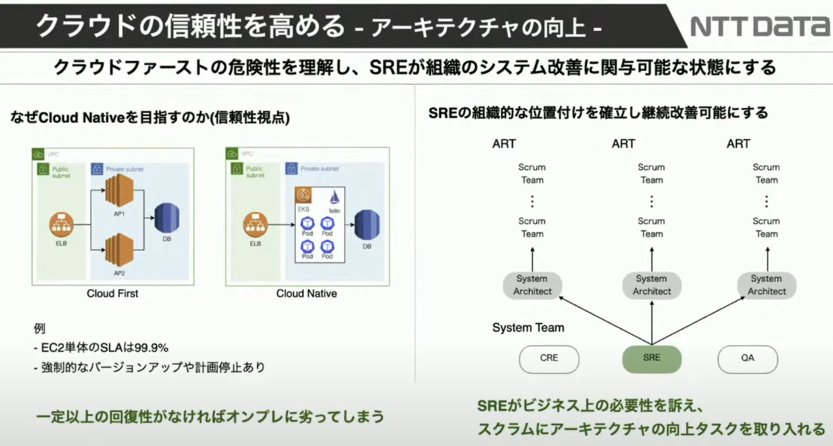
我々がクラウドネイティブを目指す理由としては、例えばEC2のSLAは99.90%です(注: 2021/9に99.99%に変更)。オンプレでホスティングしているサーバーと比べると、クラウドのほうが絶対によく止まります。しかし、そこを「オンプレで構成の凍結を是とする」のではなく、「落ちても大丈夫、回復するし、トラフィックも流れる」「一定以上の回復性を確保する」という点を目指すべきと思います。
次に、SREの立ち位置を組織内で明確にすべきという点です。マイクロサービスのメリットをスクラムチームのプロダクトオーナーに納得させる、スクラムにアーキテクチャ向上タスクを取り入れて組織のサイクルにする必要があります。我々のSREはこういった所に力を入れています。
エラーバジェットですが、「多少止まってもそれでもメリットがある」という考えがある一方、止められないシステムもあります。またAWSのようなクラウドベンダーでは、AWSが責任を持つ部分で障害が発生してシステムが止まっても、我々ができることは少ないのが一般的です。しかし、AWSが止まったからといって決済システムが止まっていいわけではないので、我々が戦える部分で、ある意味技術領域外でも戦っていくのが、当社のSREのミッションだと思っています。
まとめます。大規模組織のSREが果たすべきミッションですが、「一度DX/クラウド化でサービスを開始したら歩みを止めることができない」という理解のもとに、「常にToBeを描き直し、時には社内と戦いながらビジネスを成功に繋げる」ことがメインミッションではないかと思います。
パネルトーク / 事例講演への質疑応答
- 質問1
- Q: オンプレで作ったシステムをそのままクラウド化すると可用性が下がる事例を教えてほしい
- A: (矢口)具体的な事例はないが、Web三層のままやっていたらサービスが停止していたタイミングが多数ありました。東京リージョンで3AZ中に2AZ死んだりすることもありました。EC2をどこまで信頼せずにやれるかが戦いだと思います。ちなみに、Kubernetesは本当にすごいですね。おかげで助かった場面が多くあります。
- 質問2
- Q: SRE導入周りの悲喜こもごもな事例を教えてほしい
- A: (手塚)矢口様が勤務されるNTTデータさんを見ると、組織文化がすごい大事というのを感じます。新しいものを受け入れる文化、失敗を受け入れる文化をビジネスオーナーの方中心で作ってくださったのが、本当にありがたいことです。一方で、そこが壁になる会社さんもあり、苦闘していることもあります。
- 質問3
- Q: インフラ中心のSREチームが、アプリケーションチームを巻き込むためのおすすめの戦略はあるか
- A: (山口)いまTwitterで拝見したコメントが非常に良かったので共有します。ISUCON(LINEが運営する、決められたレギュレーションの中で高速化チューニングバトル)で、インフラチームがアプリチームに勝ったという「ショック療法」がありました。また、ユーザージャーニーを見る時に、結果としてアプリケーションのどこがクリティカルなのか、そこのデータは取れる状況になっているのかを客観的に見せたあとで、「(信頼性向上のための)クリティカルセクションがアプリケーションの中にある」ことをわかってもらうことは大事かなと思います。
- A: (手塚)ポストモーテムで振り返るのが王道という気がしますね。結局何がダメだったか、その中にアプリケーションマネジメントが入っていなかったのが原因と分かれば、(巻き込むための)契機になります。
- 質問4
- Q: インフラエンジニアリングチームがSREチームに移る場合に、組織として最初に着手すべき部分はなにか
- A: (矢口)マインド整備じゃないかと思います。SREはどういうマインドでやるべきか、なぜSREになったのかを各人が腹落ちしているとがんばれます。段階的なステップや目標を決めながら、求められている所に落とし込みながらやっていく。これを行うためにモチベーションを維持するハードルが高いので、マインド面が重要なのかなと思います。
- 質問5
- Q: 開発経験がないとSREにジョブチェンジするのは難しいか
- A: (矢口)実際開発をやったことがない人がSREになるのはかなりきついのが現実だと思います。SREは、総合的なトラブルシュートで最も経験値が上がると思っています。次いで開発や構築です。開発経験がない方は、トラブルシュートにいっぱい参加していれば、自ずとできるようになると信じます。ただ、辛いです。
- 質問6:
- Q: SREがあったほうがよい会社、なくてもいい会社はあるか
- A: (山口)パソコンがない企業であれば不要かもしれない。しかし、SREはユーザーの信頼性を獲得するためにあるので、エンジニアリングをやっている企業であれば、実践してみる価値はあると思います。
SRE関連セミナー紹介

なお当社では、SRE Tech Talkと題して、SREのより技術的な内容について当社エンジニアが語ります。
- 3-shake SRE Tech Talk #1
- Kubernetes と Toil の削減に立ち向かう 青山 真也
- SRE への第一歩、PagerDuty × DataDog を使用した品質管理 金子 雄
- 負荷試験ツール Vegeta をラップした 結合試験自動化ツール 「結合さん」を作ってみた 戸澤 涼
- 3-shake SRE Tech Talk #2
- Google Cloud で実践する SRE 篠原 一徳
- Docker と containerd の違い – コンテナログ編 寺岡 良矩
また、第三回目のSRE Tech Talkも準備中です。ぜひこちらのスリーシェイク公式YouTubeチャンネルに登録頂ければ幸いです。