SRE [サイト リライアビリティ エンジニアリング] の歴史と概要について、SREが用いる4つのアプローチについて解説します。SREとは何かを網羅していきます。
SREとはなにか [サイト リライアビリティ エンジニアリング]

ITサービスのインフラ運用・改善といった観点から「SRE」という言葉を耳にすることが増えてきました。以下では、SREとは何か、DevOpsやインフラエンジニアと何が違うか、どのような場面でSREが必要になるかといった点について解説いたします。また、「SREに関するTips」や「ITサービス企業の自社SRE事例」についても、あわせてご紹介します。
SREとはなにか

SREとは、ITサービスの信頼性を高めるために、ITエンジニア(開発者)が信頼性向上のために行う設計やアプローチ、またはこれらを行うチームを指します。
SREの発端は、グーグルが自社の検索エンジンサイトである「google.com」を安定稼働させるために、システムアドミニストレータ(運用者)ではなく、エンジニアを用いてサービス横断的なアプローチに実施したアプローチを指します。なお、サイトリライアビリティエンジニアリング(Site Reliability Engineering)の頭文字を取ってSREと呼ばれますが、この「サイト」とは、当時信頼性を向上させる対象が「google.com」のウェブサイトであったことの名残りです。

当時のグーグルは、「google.com」で検索サービスを提供すること(そして閲覧者が広告をクリックすること)がビジネスの柱でした。よって、「google.com」にダウンタイムが生じることは、訪問者の「google.com」に対する信頼性を損ね、かつ、訪問者に広告をクリックしてもらい売上を創出する機会が減ることを意味しました。つまりグーグルにとって、サイトが安定して稼働することは、「サービスに欠かせない基本機能」だったのです。
なお、SREは現在「ウェブサイト」だけでなく、分散コンピューティングシステム全般に対して用いられるアプローチとなっています。
SREはどのようなアプローチを用いるか

SREと一言でいっても、SREが具体的にどのようなアプローチを用いるのかは意外に知られていません。大まかな流れを以下で解説します。
なお、本記事では、グーグルのSREチームが執筆した「SRE サイトリライアビリティエンジニアリング Googleの信頼性を支えるエンジニアリングチーム」を参照、執筆しています。
1.SREチームを組織する

はじめに取り組むべきは、ソフトウェアエンジニアを中心とするSREチームを組織することです。グーグルでは、SREチームの50~60%は「グーグルの正規のソフトウェアエンジニア」で、残りの40~50%は「正規のエンジニア『予備軍』だが、他のメンバーには持っていないスキルを持っているエンジニア」を選定しています。
2.SLIを計測しSLOを設定する

ITサービスの運用に置いて、信頼性100%と、信頼性99.99%では大きな違いがあります。信頼性100%を実現するためには、99.99%とは異なり膨大な工数を投入する必要がありますが、ほとんどのユーザーにとっては「99.999%」が「100%」になったからといって、大きなメリットがあるわけではありません。つまり、100%を目指すことは効率的ではないため、各サービスごとに適切な可用性を設定する必要があります。
はじめに、SLIですが、これは「Service Level indicator」の略で、提供されているサービスのレベルの性質を定義した計測量です。一般的には以下をSLIとして用います。
- リクエストのレイテンシ(リクエストに対するレスポンスを返すまでにかかった時間)
- エラー率(受信したリクエストを正常に処理できなかった比率)
- システムスループット(単位時間あたりに処理できるリクエスト数)
- 可用性(サービスが利用できる時間の比率)
次に、SLOですが、これは「Service Level Objective」の略で、SLIで計測されるサービスレベルの目標値、または目標値の範囲を指します。例えば、SLOを「年99.99%」と設定すると、「1年のうち52分は稼働しなくてもよい」ということになります。例えば、「1年の間にサービスが30分停止する障害」が生じたとしても、SLOの範囲であればそれは想定の範囲であり、問題ではなくなります。
同様の用語で、SLA(Service Level Agreement)がありますが、こちらはITサービスの契約において「この稼働率を下回る場合、金銭的な保証を行う」ことを示す値です。SLIは測定値、SLOは補償を伴わない目標値である点で異なります。
3.自動化・省力化するためにプログラムを書く

SREが「システムアドミニストレーター」ではない最大の特徴は、システムの拡大に伴い、保守運用工数が正比例して増大することなないように、自分たちでプログラムを書いて積極的に自動化・省力化を行う点です。このため、SREという言葉には「エンジニアリング」という言葉が含まれています。
この「プログラムを書く」という意味は、「運用工数を減らすためのプログラムを書く」という意味と、「サービス自体のプログラムを書く」の2つの意味があります。運用工数を減らすために、サービスのプログラムの修正が必要な場合、SREチームがサービスのプログラムを開発チームに代わり書くことまで含まれます。
これができる理由は、製品サービスの開発チームと、SREチームとの壁を低くし、人材が相互に行き来させるためです。つまり、チーム全体を相互にトレーニングできているのです。
4.運用を改善する

SREが行う運用改善は詳細かつ広範囲なアプローチを含みます。ここで、その中から特に重要な点のみ紹介します。
(1)モニタリングの改善
かつてはグーグルでも、障害発生時の対応として、「何らかのシステム上のしきい値を超えた場合にメールが自動で担当者に送信され、担当者は『メールを見て、なにを行うべきかを考える』」という手法を用いていました。しかしこの方法は、人間の解釈に依存する属人的な対応を行うこととなるため、グーグルではモニタリングの出力を3つに分けています。
- アラート
- 即座のアクションが必要な事態が発生(また今後発生する見込み)
- チケット
- アクションが必要だが、即時でなくてもよい(数日間の猶予がある)
- ロギング
- アクション不要。今後の診断目的で記録・通知されるもの。
上記はあくまでグーグルの例です。SREを導入する企業は、各サービスごとに「どのようなモニタリング出力方法が最適か」を検討し、改善を加えて行く必要があります。
(2)緊急対応時の手順書作成
グーグルでは、サービスに緊急対応が発生した場合、「即興で対応する」のではなく、「あらかじめ作成された手順書通りに対応する」場合、平均修復時間に3倍の改善が見られました。
このため、SREチームは各サービスの綿密なトラブルシューティングならび手順書・ヒントの作成が求められます。
(3)変更管理
グーグルSREチームは、およそ70%のサービス障害は、稼働中のシステム変更が原因であることを突き止めました。これを防ぐためには、以下の3点が必要とされます。
・漸進的なロールアウトの実装
・高速かつ正確な問題の検出
・問題が生じた際の安全なロールバック
「SRE サイトリライアビリティエンジニアリング Googleの信頼性を支えるエンジニアリングチーム」1.3.5. 変更管理
この3つの取組みを一体として行うことで、リリース速度とリリースの安定性の両立が可能となります。
(4)需要予測/キャパシティプランニング/プロビジョニング/効率的なリソース活用
サービスの今後の成長を予測し、それに見合ったキャパシティを確保することは、サービスの信頼性確保にとって重要です。
サービスの成長は大きく分けて「自然な成長(ユーザー数や利用頻度の漸進的な増加)」と「突発的な成長(機能追加、キャンペーンなど)」があります。予測には、自然な成長だけでなく、突発的な成長も織り込む必要があります。
そして、プロビジョニングは「必要な分だけ」「正確に」「かつ迅速に」行われる必要があります。必要分以上のプロビジョニングはコストがかかり効率性が悪化すること、また不正確かつ迅速でないプロビジョニングはシステム稼働停止リスクがあるためです。リソース活用はあくまで「利用率」をもとに効率性の観点から判断されるべきです。
(5)ポストモーテム
ポストモーテム (post mortem) とは「検死」を意味する言葉です。
サービス運用において障害や失敗が発生した際、「障害や失敗をひとまず収束されたから、それでよし」とするのでなく、障害や失敗から学びを得るための定型化されたプロセスを設けること、そして再発を防止するための対策を確実に導入すること。これがSREにおけるポストモーテムです。
なお、ポストモーテムが「担当者やチームの吊し上げの場」となってはいけません。誰かを吊し上げたところで、サービスの信頼性は向上しないどころか、「吊るし上げられることを恐れて問題を隠蔽する」ようになりかねません。
ポストモーテムで必要なのは、問題につながったアクションを特定し、その問題が正しくドキュメント化され、影響を及ぶす全ての根本原因が理解されること、そして再発を防ぐための予防策が確実に導入されることです。
なお、上記はSREが行う基本的なアプローチを抽出したものです。組織やサービスによって、適用方法も異なってくると考えられますので、あくまで参考としてご理解ください。
SRE実施企業の事例紹介
以下では、「すでにSREを実施している企業の事例」について紹介いたします。
株式会社エウレカ

エウレカは、自社が運営するマッチングサービスである「pairs」の運用品質向上のためにSREチームを設け、「エウレカのSREとして何を行うか」を定義し、日々改善の取り組みを行っています。
エウレカSREチームのミッション定義と取り組み
エウレカでSREチームが発足した当時のチームのミッションは以下の通りです。
- 一言でいうと「会社の目指すビジネスの実現の阻害確立を上げる要因を全て排除すること」
- 可用性99.5%
- クリティカルなセキュリティリスクの撲滅
- 適切なキャパシティプランニング
- リリースエコシステムの改善と安定化
- 事業価値最大化のための技術サポート
そして、ミッション達成のために以下の取り組みを行っています。
- 技術的な取り組み(一例)
- SLO/SLIの定義
- 全サービスへのIaC (Infrastructure as Code) の適用
- VM→コンテナへの移行
- サブシステム・関連システムのサーバーレス化
- クエリ修正・コード修正(サーバー負荷軽減目的)
- トラフィックのスケーラビリティ確保
- Datadogによる監視・モニタリング、など
- 技術的以外の取り組み
- ポストモーテム文化の醸成
- 障害対応のフロー構築
- リード・テンプレートの作成
- 障害チケット発行からのスタッフ招集の仕組み
ミッションの再定義と新たな取り組み
エウレカのSREチームの取り組みは大きな成果を生んだ反面、「役割範囲が広すぎるため投資が広く薄くなってしまう」「SREチームに責任が集中した結果ボトルネックが発生」といった問題が発生しました。このため、エウレカSREチームは自身のミッションを以下のポイントで再定義しています。
- 会社に提供する価値
- SREという役割に囚われすぎないで価値を提供
- リソース配分
- リソースの50%を「外部依頼への対応(監査、インフラ構築など)」と「トイル(繰り返し発生する運用作業)」に割き、残り50%を「課題定義とロードマップ構築」に充てる
- やらないこと
- 別チームへ業務を移管し、SREチームの業務対象外とするなど
そして、SREチームとして大事な点として、「SREのエッセンスを大事にしつつ、常に変化・改善し続けること」としています。定義についても、半年や一年で見直して改善を繰り返すことが望ましいとしています。
まとめ
エウレカのSREチームの活動から得られる教訓は、3つです。
- グーグルが定義する『SRE』に囚われすぎないこと
- 技術的な取り組みと、技術的以外の取り組みを並行させる
- ミッションの定義は必要だが、ミッションは定期的に見直す
貴社のSREの取り組みにお役立ていただければ幸いです。
*本項は以下のページ記載内容を引用、再構成したうえで解説を行っています。
エウレカ SREチームの2021年までの取り組みとこれから
株式会社メルカリ

メルカリは、自社が運営するフリーマーケットアプリである「メルカリ」ならび金融サービス「メルペイ」の運用品質向上のためにSREチームを設け、システムの信頼性向上に取り組んでいます。
SREチーム立ち上げから現在
メルカリのSREチームの役割は、自社サービスである「メルカリ」を少ないダウンタイムで、かつ早いレスポンスで利用できるようにすることで、サービスの信頼性を高めることが目的とされています。
2015年に発足したメルカリのSREチームは、当初以下を業務範囲としていました。
- APIサーバ、ミドルウェアの可用性の維持・向上
- APIサーバ、ミドルウェアのパフォーマンスの向上
- ログ収集・分析基盤の構築、運用
- サーバプロビジョニング・デプロイの整備
- セキュリティの担保
- 開発環境などの整備
しかし、2018年頃からはじまった「メルカリ」のマイクロサービスへの移行ならび、高い信頼性を求められる金融サービス「メルペイ」の運用開始により、SREチームによる横断的な信頼性向上の取り組みが難しくなっていたとされます。結果、「メルカリ」と「メルペイ」を横断した今日着き版を開発・提供するチームが発足し、これに応じてSREチームでも新しいチームを立ち上げています。
マイクロサービスSREとエンベデッドSRE
メルカリでは、従来の「SREカスタマー」チームを改め、「マイクロサービスSRE (Microservices SRE)」チームを発足させました。マイクロサービスチームは各チームに運用上のオーナーシップが委ねられているが、チーム横断で信頼性向上を行うためのチームです。
そして、SREチームメンバーは「エンベデッドSRE (Embedded SRE)」という役割を担うこととなりました。Embedded SREとは、職能横断的な「プロダクトチームの一員」として割り当てられることが特徴で、それぞれ担当するマイクロサービスを持ち、その品質改善に努めます。
プロダクトチームから高い評価
マイクロサービスSRE、エンベデッドSREというアイデアは、プロダクトチームから高く評価されました。各マイクロサービスチームからの評価の平均は5点満点の4.63という高評価です。
今後は、複数のマイクロサービスに共通する課題の発掘と解決ならびツール整備に注力を行うとのことです。
まとめ
メルカリSREチームから学ぶことができるのは、「グーグルが開発したSREという方法論を正しく行う」「その後、SREをメルカリにあわせて進化させる」という点です。これはまさに「守破離」の考えそのものといってよいと思います。
貴社のSREの取り組みのお役に立てれば幸いです。
*本項は以下のページ記載内容を引用、再構成したうえで解説を行っています。
インフラチーム改め Site Reliability Engineering (SRE) チームになりました
開発チームとともに歩むSREチームが成し遂げたいこと mercari engineering
株式会社ヌーラボ

ヌーラボは、プロジェクト管理ツール「Backlog」や、ビジュアルコラボレーションツール「Cacoo」などを開発・販売するIT企業です。以下では、ヌーラボのSREチームの取り組みについて解説します。
ヌーラボSREの歴史
かつてヌーラボはエンジニア全員がサービス開発にあたっていましたが、2015年にインフラエンジニアが入社し、SREの取り組みが開始されています。
ヌーラボのSRE組織についてですが、「開発チームに含めたほうが良いか」「プロダクトチームに含めたほうが良いか」「独立した組織としたほうが良いか」といった議論を経て、現在では「各サービスを開発する課」とは独立した形で「SRE課」が発足しています。
これは、SREは担当プロダクトを持ちながらも、各開発チームに対して横断的に連携を進めることがミッションとされたためです。
なお、SREが各プロダクトの開発チームとは独立した組織になることのデメリット(例: プロダクト開発の細かな状況が分からなくなる)を回避するため、週に一度の会議を設けてリリース予定の共有や現在起こっている問題についての議論を行うようにしています。
ヌーラボSRE課の役割と取り組み
SRE課では以下のプロセスで、信頼性向上のための活動を行っています。
- SRE課のメンバーは改善のためのバックログを作成する。このバックログをもとに月に1度「棚卸し会議」を行い、「どの課題に優先的に取り組むか」を決定する。
- 1ヶ月以内の改善活動についてはSREのみで取り組み、1ヶ月を超える活動の場合はSREとプロダクト開発者の両方でチームを作りプロジェクト化する。
取り組みの例としては、以下の事例が紹介され、大きな成果を発揮しています。
「Backlog」画像検索機能のリプレイス
- プロジェクト期間: 5ヶ月間
- チーム: SRE 1名、開発者1-2名(時期により変動)
- 課題: スケーラビリティ、可用性、ハードウェアコスト、運用コスト、新サービス追加やマイクロサービス化の足かせとなっている
- 対策: 既存機能のリプレイス
- 結果: 当初の課題を全て解決。アプリケーション・サーバー上のインデックスファイルが不要となり、結果、アプリケーション・サーバーのコンテナ化・分割が可能に。
まとめ
SREが「タテ(プロダクトチーム寄り)」の役割を果たすのか、それとも「ヨコ(組織横断的)」の役割を果たすのかは、サービスの規模や数、組織の人材や文化などにより決定されるべきで「これが正解」といったものは存在しません。
貴社でSREを検討の際には、ぜひ上記内容をご参考いただき、また当社がお手伝いできる場面があればお気軽に問い合わせいただければ幸いです。
*本項は以下のページ記載内容を引用、再構成したうえで解説を行っています。
ヌーラボのSREは歴史の長いプロダクトをどのように改善しているか? #ヌーラボのアドベントカレンダー
ヤフー株式会社 (Private PaaS チーム)

ヤフーのPrivate PaaS(自社向けのPaaS環境)を構築するエンジニアは、サービス信頼性向上のためにSREを行っています。
ヤフー Private SaaSの概要と規模
ヤフーが自社のサービス構築のために準備しているPrivate PaaSは以下の環境で構築されています。
- クラウド基盤: VMware Tanzu Application Service (TAS)
- TASクラスタ数: 25 (本番) + 3 (開発環境) + 2 (性能試験)
- 本番アプリケーション数: 約17,000
- 本番稼働アプリケーションコンテナ数: 約80,000
- 処理リクエスト数 (平均リクエスト/秒): 約350,000
- 処理リクエストピーク数 (平均リクエスト/秒): 約600,000
アプリケーション数、コンテナ数、リクエスト数などはまさに膨大といってよく、世界でも有数なレベルのサービス規模です。なお、「TAS 25クラスタ」といってもピンと来ませんが、「1つのTASのクラスタでメモリ間さんで10TB以上のアプリケーションを稼働できる」というレベルの巨大さです。
SLO設定・SLI測定
はじめに、「ヤフーPrivate PaaSでSREを行うに際して、何を指標とするか」ですが、ヤフーでは「PaaS利用者から見える機能」に着目し、以下の2つを挙げています。
(1)アプリケーションデプロイジョブキューのエラー率
(2)アプリケーションのPaaSへのデプロイ成功率
まず、Private PaaS部門は「アプリケーション開発部門」ではありません。各アプリケーションを開発する部門、エンジニアに対して信頼できる開発実行環境を提供するのがその役割です。このため、指標は「アプリケーション」で設定されていません。
なおSLOですが、「SLO = PaaS利用者が不都合のないSLI値」として、90%~99.99%で設定されています。さらに「システム障害時の影響度」に応じて、4段階にレベル分けされています。
- レベル0: ヤフーのサービス利用者に直ちに悪影響がでるものもの
- レベル1: ヤフーのサービス利用者に悪影響がでる可能性がある
- レベル2: ヤフーのサービス利用者に影響はないが、社内の開発者に直ちに悪影響がでるもの
- レベル3: ヤフーのサービス利用者に影響はないが、社内の開発者に悪影響が出る可能性があるもの
事例内では明示されていませんが、重要度が最も高いレベル0は99.99%、最も低いレベル3は90%で設定されていると考えられます。
そして、各SLOレベルに応じて細かくSLIが設定されています。具体的には「HTTPSアクセス成功率」「コンテナ通信成功率」「アプリケーション正常動作率」などです。
SLIならびSLOの運用と改善
SLOレベルは、SLIがSLOを下回る(実際の測定値が目標値を下回る)場合の対応を定めています。ユーザーに影響が出ている(または出る可能性がある)場合は、24時間365日対応を行い、社内開発者飲みに影響が出ている(または出る可能性がある)場合は業務時間内での対応としています。
次に、SLO値の見直しについてですが、「SLOを満たしているが、社内エンジニアからエラーに関する問い合わせが来る」「障害対応を求められる」場合に、もともと設定されていたSLOが適切でない(低すぎる)と判断し、SLOの引き上げを行っています。
また、利用者が少ないのでSLIを計測していなかった値が、後に障害要因となったケースなどでは、この反省を踏まえてSLIの追加を行い、測定すべきSLIを増加させています。
さらに、設定されているSLIが適切でない場合(例: SLI計測に用いていたデプロ対象のサンプルアプリのメモリ設定値が小さすぎる)、計測基準を変更するなどして対応しています。
メリットと課題
メリットは、Private PaaSチーム全体で稼働状況を把握できるため、SLI/SLOを用いたリリース判断や障害対応判断を行えるようになったとしています。
課題としては、「SLI計測値としては正常だが、一部のPaaS利用者に重大な障害が発生するケース」を捉えきれていない点です。SLIは十分にSLOを満たすほど高く、全体としては正しく運用されているが、一部ユーザーは頻繁に障害が発生しているようなケースです。今後はこうしたケースに対する対応が課題となっています。
*本項は以下のページ記載内容を引用、再構成したうえで解説を行っています。
ヤフーのPrivate PaaSチームにおけるSREの取り組み 〜 サービス安定稼働に向けた指標計測
株式会社monotaRO (モノタロウ)

事業者向け工業用間接資材の販売会社であるモノタロウは、売上の90%以上をオンラインからの受注が占めるEC企業です。
SREチームを社内に設けて、日々「monotaro.com」の信頼性向上のための活動をおこなていますが、通常の手順では解決できないトラブルをどのように解決したかについて解説しています。
発生したトラブルとそれに対する対応
あるとき、モノタロウのWebサービス全体でレイテンシ悪化やバックエンドAPIへのタイムアウト増加が頻発しました。
レイテンシ悪化はよくある問題であるため、通常の手順で対応したところ、問題は即座に解決せず、アラートが鳴り止まない状態となりました。具体的には「ある短時間にエラーが増加している」というアラートと、「レイテンシ悪化」のアラートが両方飛んでいました。
通常の手順でははじめに、代表的な指標を掲載したダッシュボードを確認し、サイト全体の動向を把握します。その後、ダッシュボードから得た情報をもとに仮説を立て、その仮説に沿ってさらなる調査を行い対策を行います。具体的には「サーバーを特定してスケールアウトする」といったものです。今回の問題も、API処理サーバーのスケールアウトを行い、その直後はエラーが解消されたかに見えました。
しかし、翌週にも同様の問題が発生しました。ダッシュボードを見る限り、リソース利用状況は悪化しておらず、APIサーバーの処理サーバーには問題がないことが分かりました。このため、さらなる原因究明が必要となりました。
原因の確認
結論からいうと、前週に発生した問題と、翌週に発生した問題では原因が異なっていた(障害点が移動した)ために、原因究明が困難となっていました。前週に行ったスケールアウトは正しい対策でしたが、これにより後ろ側のコンポーネントに負荷が集中し、新たなボトルネックが発生していました。ただ、バックエンドのどこがボトルネックになっているかについての調査が難航しました。はじめは検索エンジンを疑い、スケールアウトを行いしたが、レイテンシの定期的な悪化は継続しました。そして、さらなる仮説検証を行うことで、最終的にはAPIサーバーとリバースプロキシ間のTCP接続およびパケットが溢れてしまったことが真の問題であることが判明しました。
対策
これに対する対策として、リバースプロキシのスケールアウトを行うことでトラブルは解消されました。そして、同様にトラブルを見過ごさないように監視項目が追加され、これらの指標がダッシュボードに追加されました。
ダッシュボードに全ての指標を掲載することは不可能です。よって、優先順位の高いものを選んで掲載します。しかし、ダッシュボードに掲載されていない指標に関連する障害が発生した場合、原因究明が困難となります。よって、ダッシュボードを適宜アップデートし、再発防止に努める必要があります。
*本項は以下のページ記載内容を引用、再構成したうえで解説を行っています。
スケールアウトの落とし穴から学ぶ、SREチームでのダッシュボードのアップデート術
フォルシア株式会社

フォルシア株式会社は「情報検索プラットフォーム Spook」を開発する企業で、高速検索ソリューションやダイナミックプライシングのソリューションなどを提供しています。フォルシアでは、サービスの信頼性向上のためにSREの活動を行っていますが、SRE専任の担当者はおらず、サービス開発エンジニアがSREを兼任しています。以下では、フォルシアSREの改善活動について2点解説します。
オンコール削減
かつてフォルシアでは、サーバー高負荷が発生している際にオンコール対応が必要となるケースが頻発していました。この「トイル」に対して、SREチームで高負荷の発生原因を特定・分類した結果、「ある事象が起こったら、この自動復旧スクリプトを実施する」という自動化を行い、本番環境に適用しました。
結果、オンコール対応回数を50%削減することができました。
新しいエラーの早期検知
どれだけサービスのテストを行っても、完全にエラーを無くすことは不可能です。しかし、エラーを早期に検知できれば、問題を短時間で収束させられます。このため、早期の検知が重要です。
フォルシアSREでは、過去1週間で初めて発生したエラーを検知した場合は、Slackに通知を送るbotを準備し、エラーの早期検知が行えるようにしています。
品質AWARDによる表彰
サービスのリリースや利益創出は高く評価を受けることはあっても、サービスの品質向上が特段に注目されることは少ないのが実情です。フォルシアでは、サービス品質の向上に寄与したチームを表彰するために「品質AWARD」を設けています。
活動を全員から称賛されることに加え、副賞として美味しいお菓子が贈られるということで、「普段注文を集めることが少ない品質向上活動を明らかにする」意味でも、「品質向上に携わるエンジニアの士気を高める」意味でも、非常に有益な活動といえます。SREを表彰する枠組みがない企業は、こうした品質向上に対する表彰制度の導入を検討してみてはいかがでしょうか。
*本項は以下のページ記載内容を引用、再構成したうえで解説を行っています。
社内の課題を着実に解決 フォルシアSREチームの取り組み
https://www.forcia.com/blog/001291.html
株式会社リクルート(Hot Pepper Beauty)

国内最大手の美容系検索・予約サイトである「Hot Pepper Beauty」を運営するリクルートでは、各サービスごとにSREチームが存在し、Hot Pepper Beautyの信頼性向上のために日々活動しています。以下で解説します。
美容クリニック開発内のSRE
Hot Pepper Beauty内の「美容クリニックサービス開発チーム」では、以下の組織体系で運用されています。
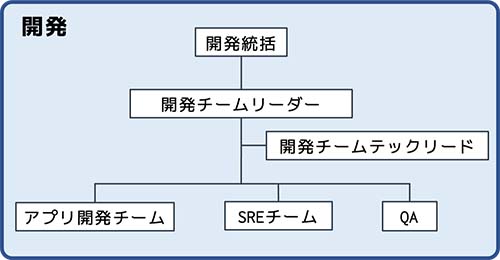
出典: https://engineer.recruit-lifestyle.co.jp/techblog/2021-06-24-hpbc-sre/
SREチームは「アプリ開発チーム」「QA」と並んで、開発チーム内の1チームという位置づけです。人員の7割がアプリ開発、QAが2割、SREは1割程度となっています。
美容クリニック開発内SREチームの主な責任範囲は、サービス立ち上げ時は「インフラ構築」ですが、立ち上げ後は「インフラの保守運営」がメインとなり、チームの変動などの影響で「SREが1人」という状態になってしまいました。ここで、新たにSREチーム自体の見直しを行い、以下のミッションと責務を定めました。ちなみに「開発チームに対する責務(左)」と、「システムに対する責務(右)」です。

そして、1年で以下の活動全てを実施し、多くで成果を得ました。
SRE活動事例
- DX (Developer eXperience) 改善
- DX改善とは、アプリ開発チームからSREチームに寄せられた、開発プロセスや開発環境に関する不満を改善するための活動を行った。
- 定性的なヒアリングを実施し、「CI (継続的インテグレーション) が遅い」「テストデータを手動で作成するのが辛い」といった回答を集めた後、根本原因を調査し、優先順位付けを行い、改善に取り組んだ。
- 結果、開発周りの改善が実現されると同時に、アプリ開発チームがSREチームの活動を理解し、より意見の共有が進んだ。
- プルリクエストの解析による開発プロセスの評価
- プルリクエスト(コードを修正追加した際に、他の開発者に本体への反映を依頼する機能)について、開発時間、開発粒度、品質などから外部的に評価を行った。
- 明確なボトルネックを発見するには至らなかったが、アプリ開発チームにたいする外形監視が機能することが分かった。
- 人員の中長期計画の策定
- アクションとして、「リスクマインドマップ」を作成し、「発生し得る事象」と、「発生し得るリスク」がひと目で分かるようにした。そして、リスクに対する対策に優先順位付けを行い、中長期的な人員計画を策定した。
- 開発KPI、モニタリング整備
- 以前から設定されていたサービス目標を計測可能なレベルで分解し、SLIとSLOを再定義した。
- メトリックスを集約しているDatadogから、Slackに対してダッシュボードのnginxメトリックスを自動でキャプチャして定期的に投稿するよう設定。レイテンシの確認機会が増えた。
- 月次の集計作業を持ち回りで実施することで、各人がレイテンシについて考える機会を増やすようにした。実際、ここから改善も生まれた。
- 本番障害一次受け体制構築
- メンバーにサービス運用経験を積ませた上で、「責務の定義」「オンコールローテーション作成」「インフラ障害がどのサービスに影響を与えるかひと目で分かる表作成」を行い、オンコールメンバーの負荷軽減と影響範囲の迅速な理解を促進。
*本項は以下のページ記載内容を引用、再構成したうえで解説を行っています。
「ホットペッパービューティー」美容クリニックでのSRE活動
Lowe’s

Lowe’s は、アメリカ・ノースカロライナ州に本社がある、ホームセンター事業を営む会社です。従業員数は3万人、店舗数は1,977店舗 (2019年) を有する巨大企業です。以下では、Lowe’sのSREチームの活動についてお伝えします。
Lowe’sのSREへの取り組み
2018年時点、Lowe’sはSREを導入していませんでした。このため、問題を先回りして解決するのではなく、問題が起こってから対処するアプローチを取っていました。オンコール体制、インシデント管理が適切でなく、大量のトイルが発生していました。
この状況を改善するために、オンプレミス環境をGoogle Cloudに移行するタイミングで、マイクロアーキテクチャの採用とSREの導入を決定しました。具体的には以下の活動を行いました。
- トイルの自動化
- Lowe’sの最大の課題はトイル対策でした。まず行ったのは、「アラートが上がっても、まっさきにエンジニアに連絡が入らないようにした」ことです。エンジニアで対応できるトリアージや修正は、トレーニングを受けたマシンでも対応できるという判断で「教師あり学習」と「教師なし学習」をマシンに対して行った結果、対処可能なレベルまでトイル削減に成功しています。
- ロードマップ全体に対するエンジニアの意識統一
- SREをドメインチームとプロダクトチームに配置し、SREイニシアティブに沿った開発をすすめることで、信頼性向上、パフォーマンス向上、スケーラビリティの確保、リリースまでの時間削減に貢献しています。
- ワンタッチリリースの導入
- ワンタッチリリースとは、pullリクエストが承認されると、承認された変更を本番環境に安全にデプロイする「DevSecOpsパイプライン」をトリガーします。これにより、安全で信頼性が高く、かつスピーディーなフィードバックループを構築しました。これにより、リリース1件につき30分もかからずにワンクリックでデリバリーが完了するようになりました。
- キャパシティプランニングの導入
- SREがキャパシティプランニングに注力することで、推奨されるキャパシティの変更を継続的デリバリー (CD) パイプラインとして実現しています。予想を超えたトラフィック急増の場合のみ、SREがオンデマンドでキャパシティ変更を行います。
*本項は以下のページ記載内容を引用、再構成したうえで解説を行っています。
Lowe’s が Google SRE プラクティスで顧客の要求に応えている方法
株式会社ミクシィ(モンスターストライク)

モンスターストライク(モンスト)は、株式会社ミクシィ内のゲームスタジオ「XFLAG」が提供するスマートフォンゲームで、2016年には世界で最も売上を上げたゲームと言われています (1,300億円)。
以下では、モンスト登場以前のミクシィの信頼性向上の活動と、モンスト以後のSREによる信頼性向上の活動についてお伝えします。
モンスト登場前
モンスト登場前のミクシィの主力事業は、SNS「mixi」でした。「インフラチーム」「アプリチーム」の他に、「刺身の上にたんぽぽを乗せるような単純作業から開発者を開放しよう」という目的で作られた「たんぽぽグループ」がありました。
たんぽぽグループは、全てのシステムに横断的に関わり、開発・運用がスムーズに進むための取り組みを継続的に行ってきました。当時のシステム面の課題と対策は以下の通りです。

モンスト登場後
モンスト登場以後、ミクシィのビジネスモデルは一変しました。モンストは、これまで主軸だったSNS事業を追い抜き、ビジネスの大黒柱に成長しました。モンストリリース後に実施した対策は以下の通りです。

モンストが急速に拡大する中で、モンストを運営する社内ゲームスタジオである「XFLAG」は、さらなる信頼性向上を目的として、SREグループを発足させました。SREの業務内容は以下のとおりです。
- モンストの負荷改善
- 可用性向上
- データのバックアップ
- リリースエンジニアリング
- 物理マシン、クラウドのリソース設計と最適化
- 自動化、ツール開発
- 監視、モニタリング改善
- 各種Webサイト構築
- 新規案件相談、モック開発
- セキュリティ対策
- 障害対応(オンコール。現在ではPagerDutyを活用)
- その他
SREグループに所属するメンバーは「今やるべき仕事は自分で見つける」「使いたい技術はメンバーの合意を得て積極的に導入する」といった、仕事の進め方の原則に従って業務を行います。
- また、SREメンバーの評価ポイントについても明文化されています。
- 何にどれくらい時間をかけて、何に対して貢献したのか
- 与えられた仕事だけしても評価はされない
- 技術によりどんな問題を解決したか。今その技術を選ぶ必要があったか
- 何を作ったのか。そのモノの価値はどうなのか。生産性は高かったのか
- 事業、プロダクト、サービスにどの程度貢献できたのか。なぜそれに貢献したか
- グループにどのような影響を与えたか。メンバーに対しどんな行動をして、何が変わったか
一般的にSREは、信頼性向上のためにあらゆる事を行う組織と認識されていますが、その評価ポイントについて明確になっていない組織も多いかと思います。ミクシィでは、上記のように、「SREに何を求めていて、行動や成果に対してどのような観点での説明責任が期待されているか」を分かりやすくまとめているおり、SREを導入している組織であれば大いに参考になるでしょう。
*本項は以下のページ記載内容を引用、再構成したうえで解説を行っています。
モンスターストライクの信頼性を支えるSREの組織化について
freee株式会社

freee株式会社は、法人や個人事業主に「会計」「人事」「申告」などの事務支援サービスを提供するSaaS企業です。
freeeは、「会社の財務情報」「従業員の給与情報」「マイナンバー」といった気密性の高い情報を多数取り扱うため、障害に対してシビアな対応が求められます。とはいえ、障害をゼロにする(可用性を100%にする)ことはできませんので、障害を受け入れながらも安定したプロダクトを目指す必要があります。
大規模障害前
2016年頃のfreeeは、明確な障害対応フローがなく、暗黙知に頼る開発・運用現場でした。機能開発を優先した結果、信頼性を高めるための活動は後回しにされました。ただ、これはスタートアップ企業であればある意味、当然の方針ともいえるため、この点だけを取り上げて「悪い」とは言えません。
2017年頃には、プロダクトの成長に伴ってポストモーテムを書く習慣が広がりを見せますが、特にルールもなくエンジニアが散発的に取り組む程度(属人的な学び)にとどまっていました。
2018年には、サービス運用の外部監査の国際規格である SOC1 (Service Organization Control 1) の取得に向けた障害対応フローが策定されると同時に、ポストモーテムも共通のフォーマットができたことで品質も改善していました。
大規模障害後
2018年10月の月末に、freeeは150分もの間、サービスが全て停止する大規模障害を発生させてしまいます。具体的な原因はオペレーションミスで、顧客のデータ保護を優先させるため全サービスを停止せざるを得なくなりました。月末は最もサービスが使用されるタイミングであったため、このタイミングでのサービス停止は利用者に大きな影響を与えました。しかし、freeeのエンジニア組織は、この障害から多くを学んでいます。
まず、SOC1取得にめけて整備した障害対応フローをブラッシュアップし、障害発生時の初動対応、役割、社内外コミュニケーションについて「誰が何をすべきか」を明確に取り決めました。これにより障害対応がスムーズに行われるようになりました。
次に、オフィス内に物理的な「障害対応エリア」を設けました。情報を一箇所に集約し復旧までの舵取りを行えるようにしました。これは、別々の場所で作業していると認識のズレが起こりやすいためです。
また、初動の省力化も行っています。例えばSlackで「障害対応するぞ」と投稿すると、障害対応マニュアルが表示されたり、「障害フォーム」と投稿すると、障害速報フォームが表示されると行ったSlackbotの活用もその一つです。また、ポストモーテムの自動作成、GASを用いた社内告知の自動化などもあります。
「失敗して攻めよう」
freeeは創業当時から「失敗して攻めよう」という言葉が共有されていました。学びのある失敗をすることで最速で成長するという意味です。逆に学びのある失敗していないのは、挑戦が足りないとされます。
具体的な活動としては、「失敗.js」という障害の学びを開発組織全体で共有する場を設けたり、小さな問題が大きくなるまでに改善するための「割れ窓を改善し隊」という活動を行うなどです。さらには、「alertを振り返り隊」という、直近1週間のアラートを振り返り、ノウハウを共有する活動も行っています。
freeeの、「失敗を共有し、そこから学んで攻める」という企業文化は、SREの取り組みとは親和性が高いといえます。それゆえ、本当に意味でSREが組織に根付き、それが開発組織ならびサービスにおける強みとなっています。
*本項は以下のページ記載内容を引用、再構成したうえで解説を行っています。
freee のエンジニアは障害から何を学び、どう改善しているのか?
https://speakerdeck.com/manabusakai/what-do-freee-engineers-learn-and-improve-from-failures
SREに関するTips紹介
人類最初のSRE: マーガレット・ハミルトン

グーグルが自社の取り組みである「SRE」を解説した本である「SRE サイトリライアビリティエンジニアリング」では、人類最初のSREとしてマーガレット・ハミルソンについて記載されています。
1936年に生まれたマーガレット・ハミルトンは、ミシガン大学を卒業後に純粋数学を学んだ後に「気象学用のソフトウェア開発」のためにマサチューセッツ工科大学(MIT)で職を得ています。ここからハミルトンのソフトウェア開発が始まり、国防目的の研究所であるリンカーン研究所を経て、アメリカ航空宇宙局(NASA)の一員として人類の月面着陸プロジェクトである「アポロ計画」に携わるようになりました。
ハミルトンがなぜ「人類最初のSRE」と呼ばれるに至ったかは、「アポロ計画のミッションの失敗をソフトウェアのアプローチで回避した」ためです。
シミュレーター上で行うアポロのミッションシナリオを「予想外のキー」を押すことでクラッシュさせたハミルトンは、「宇宙飛行士が予想外の操作を行った際に備えて、エラーチェックのプログラムを追加すべき」と主張しました。しかし、「宇宙飛行士はそんな予想外の間違いをしない」と主張した上層部により、追加リクエストは却下されました。
リクエスト却下により、ハミルトンはプログラム追加を行えませんでしたが、代わりに、「宇宙飛行士が万が一、予想外の間違いをした場合のためのドキュメント」を更新しました。
ドキュメントが更新された4日後、実際に宇宙飛行士が予想外の操作を行ったことで、「航行データが消失し、宇宙飛行士が無事に帰還できない」危機に直面しました。しかし、ハミルトンがあらかじめドキュメントを更新しておいたため、宇宙飛行士はドキュメントに記載された手順で航行データを復元することができました。なお、これは現在では「フェイルセーフ」と呼ばれる、「故障や人為的なミスがあった場合でも、安全な状態に復帰する」仕組みです。
SREの価値とは、企業や組織のシステムに対して「問題が起こってから対処を考える」ではなく、「問題を予期して対策を取ることで、『問題を発生させない』『問題が発生しても、少ない被害で問題を収束させ安全な状態にする』」ことです。
ハミルトンはいち早く「起こるかもしれない問題を発見し、対策を提案」するだけでなく、「提案が却下されても、取りうる最善の策を講じる」ことでミッションと人命を救いました。SREを志すエンジニアは、こうしたハミルトンの姿勢から多くを学べるのではないでしょうか。
エラーバジェットとその考え方について

エラーバジェットとは、「サービスの可用性目標値を100%から引いた値」です。例えば、サービスの可用性目標値が99.99%であれば「100% – 99.99% = 0.01%」がエラーバジェットとなります。エラーバジェットの設定により生じる時間は、サービスの改善やさらなる信頼性向上のために利用できます。
ちなみに、エラーバジェットを設定する前提は「100%の可用性を設定することは間違っている」ということです。
例えば、「核攻撃から国民を防御する、人命に直結するシステム」であれば、多大なコストと労力を払っても100%を確保すべきです。しかし、これほどの可用性を求められるITサービスは、民間のITサービス運用ではほぼありません。よって、一般のITサービス運用に携わる組織は「100%を求められてもいないし、目指す必要もない」と理解することが出発点です。
「100%を目指すべきでない理由」は「効率性」です。
年間の可用性が「99.99%」と「100%」では、年間のダウンタイムが「52.6分 (99.99%)」か「ゼロ (100%)」かという違いがあります。年間1時間弱というわずかなダウンタイムを許容せずに100%を目指すと、「膨大なコストと労力がかかる割に、ユーザーは特にメリットを感じられない」という結果となるためです。
これに対し、年間99.99%の可用性目標を設定し、0.01%をエラーバジェットとした場合、可用性に対する考え方が大きく変わります。
エラーバジェット設定前は、「今年は99.99%の可用性だった。つまり1年のうち0.01%稼働できない時間があったので問題だ。運用チームはもっと頑張って100%を目指すべき」という考えに至ります。結果、運用チームは「コスト効率の悪い信頼性向上のアプローチ」にコストと労力を費やしてしまいます。
エラーバジェット設定後は、「今年は99.99%の可用性で目標を達成した。0.01%の時間は自由に使えるので、どう使うべきか」という発想となります。障害によるサービス停止ですら、「恐れる」ものから、「エラーバジェットの範囲内で管理するもの」となります。
平均故障時間 (MTTF) と、平均修復時間 (MTTR) について

平均故障時間 (MTTF: mean time to failure) とは、「前回の障害が復旧してから、次の障害が発生するまでの時間」を指します。「問題なく安定稼働していた時間の長さ」と言い換えてもよいでしょう。
そして、平均修復時間(MTTR: mean time to repair) とは、「新たに障害が発生してから、障害が復旧するまでの時間」です。
- MTTFは「安定稼働している時間がどの程度の長さであったか」を示します。MTTFの数値は「長ければ長いほど安定稼働していてよい」です。
- MTTRは「障害が発生してから復旧までに、どの程度の時間がかかったか」を示します。MTTRの数値は「短ければ短いほど障害復旧が早くてよい」です。
MTTFを長くするには、当たり前ですが「MTTRをできるだけ短くする」ことが大切です。MTTRを短くするには、大きく分けて3つの取組みが必要です。
1つめは、「障害発生時の手順をドキュメント化しておくこと」です。ドキュメント化していない場合、ドキュメント化されていた場合と比べてMTTRは3倍の長さとなります。
2つめは、「よくある障害を自動で復旧させること(その仕組みを作ること)」です。手作業での復旧と比べ、自動化された復旧ではMTTRが削減できます。
3つめは、「障害自体を発生させなくすること(発生しにくくすること)」です。障害が発生した後のポストモーテムの機会を活用し、障害が発生しないための運用の改善やアプリケーションの改善、その他の改善を行うことでMTTRを削減できます。
トイル (Toil) について

グーグルは、SREの考え方をまとめた本である「Site Reliability Engineering」にて、トイルについて、行っている作業が以下のうち1つでも当てはまれば、それはトイルと呼べる可能性は高いとしています。
- 手作業であること
- 繰り返させること
- 自動化できること
- 戦術的であること
- 長期的な価値を持たないこと
- サービスの成長に対して O (n) であること(正比例すること)
グーグルのSRE組織では、運用業務(トイル)を50%以下に抑えることが目標となっています。つまり、トイルが多ければ多いほど、この運用業務時間が長時間となり目標達成が難しくなるのです。そして、トイルの確認を怠ると、トイルが急速に増大して100%の時間を埋め尽くすリスクもあります。
トイルを全て無くして0%にすることは現実的ではありません。そして、SREが処理する量が少量であれば概ね問題はありません(なお、グーグルSREの運用業務割合は33%です)。
しかし、トイルが増大すると、「(SREチームメンバーの)キャリアの停滞」「士気の低下」「混乱の発生」「生産性の低下」といった問題が生じ、SRE組織での仕事に疑問を投げかける事態となりかねません。
よって、SREチームはエンジニアリングのアプローチにより常にトイルをなくしていくアプローチを継続する必要があります。
モニタリングの種類

SREにおけるモニタリングと、モニタリングに関する用語は定義づけられており、問題発生時に担当者が迷いなく必要なアクションを取られるように分類されています。
モニタリングに関する定義
- モニタリング: システムに関するリアルタイムの定量データ収集、処理、集計、表示
- ホワイトボックスモニタリング: システム内部で公開されているメトリクスに基づくモニタリング
- ブラックボックスモニタリング: ユーザーが目にする挙動のテスト
- ダッシュボード: サービスの主要メトリクスをサマリ表示するアプリケーション
3種類のモニタリング出力
- アラート: 担当者が即座にアクションを取ることが求められる通知
- チケット: 担当者が後ほどアクションを取ることが求められる通知(即座ではない)
- ロギング: アクション不要の通知(ログ取得に関する通知)
リリースエンジニアリングとその哲学

SREにおけるリリースエンジニアリングとは、ソフトウェアをビルドし、リリースするプロセスの信頼性を高めるためのソフトウェアエンジニアリング手法です。定義されたポリシーや適切なツールと自動化が行われていれば、開発者やSREはソフトウェアのリリースを信頼できるで行うことができます。
グーグルでは、SREにおけるリリースエンジニアリングにおけるポイントを、以下の4点で整理しています。
- セルフサービスモデル
リリースエンジニアリングにより開発されたベストプラクティスやツールを用いることで、各開発チームの判断によりにリリースが行えるようになります。言い換えると、開発チームが望むタイミング、望む頻度でのリリースが可能です。 - 高速性
グーグルのリリースエンジニアリングにおいては、「ユーザーが利用できる機能をできる限り早くロールアウトするために、リリースを頻繁に行い、バージョン間の変更を少なくすること」が重要だという哲学が共有されています。リリースエンジニアリングは、短時間でのリリースを可能とする必要があります。 - 密封ビルド
「ビルドマシン上にインストールされているライブラリやその他のソフトウェアには影響されない」ようにするため、グーグルでは「密封ビルド」を用いています。別々のマシンでビルドを行っても、得られる結果が同じになるようにすべきです。 - ポリシーと手順の強制
リリースにおいて、意図しない変更が行われることを防ぐため、以下の処理は保護すべきとされています。
– ソースコードの変更承認
– リソースプロセス間に行われる各手順の指定
– 新しいリソースの作成
– 最初の結合ビルドの提案とチェリーピッキングの承認: チェリーピッキングとは「稼働中のソフトウェアのバグ修正などを目的として、オリジナルのビルドに変更を含めた修正版の再ビルドすること」を指します。
– 新しいリリースのデプロイ
– プロジェクトのビルド設定の変更
オンコール

オンコールとは、業務時間内または業務時間外に「即対応が必要な障害が発生した場合の通知、または通知を受けた後の対応(オンコール対応)」を指します。一般的には、24時間・365日の対応が求められるため、複数のチームメンバーによりシフト制でオンコールにあたっています。
本記事内の「SREにおけるモニタリングの種類」の中で、3種類のモニタリング出力について説明されていますが、ここでいう「アラート」がオンコール対応が必要な障害で、「チケット」「ロギング」はオンコール対応が必要ではありません
特に業務時間外のオンコール対応は、少人数で迅速な対応が求められます。グーグルでは、時間に対する要求が極めて厳しいシステムであれば5分、そうでなければ30分での復旧が一般的とされます。短時間で問題を解決するためには、どれほど経験豊富なエンジニアであっても、属人的に問題解決を行うのではなく、事前に準備されたドキュメントに従った対応が求められます。
なおSREでは、全労働時間に占める運用業務は50%以下にすることが規定されていますが、オンコール業務はこの運用業務時間に含まれます。オンコール業務が占める時間は最大でも25%以下とし、残った25%の時間は他の運用業務に費やすべきとされています。
トラブルシューティングの一般的な手法

トラブルシューティングに必要な2つの要素
SREかどうかに関わらず、サービス開発においてトラブルシューティングは欠かせないスキルです。「開発において多くの成功と失敗を繰り返してきた結果、適切なトラブルシューティングを実地で習得した」というエンジニアは多いですが、トラブルシューティングは学ぶことも教えることもできるものです。
トラブルシューティングを行う上で必要な2つの要素は以下のとおりです。
- 一般的なトラブルシューティングの手法
- 当該システムに対する深い知識
トラブルシューティングを行う上で、一般的な手法について精通しておくことはもちろん必要ですが、「問題が発生したから、トラブルシューティングの手法を1から試していく」のは効果的ではありません。当該システムが本来どのように動作しているかを理解した上で、トラブルシューティングを行うほうがはるかに効率的です。
トラブルシューティングの一般的なプロセス
上記を踏まえた上でトラブルシューティングの理論について解説します。
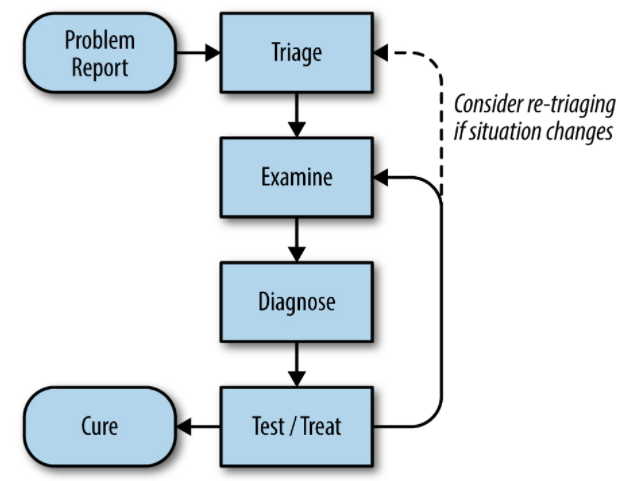
*画像引用元
Site Reliability Engineering – Chapter 12 – Effective Troubleshooting
上記画像はトラブルシューティングの一般的なプロセスです。
- 問題のレポート (Problem Report): 問題の報告がトラブルシューティングの起点です
- トリアージ (Triage): 問題の優先順位付けを行います
- 観察 (Examine): ログなどをもとに問題を調査
- 診断 (Diagnose): 問題がなぜ発生しているか、どうすれば解決できるかを判断
- テスト/対処 (Test/Treat): 問題の解決を行うための手法をテストし、その後実効します
- 回復 (Cure): 問題が解決済みとなりました
なお、テスト/対処の段階で状況が変化した場合は、再び「トリアージ」または「観察」からプロセスをやり直すことを検討します。
[意図的に障害を発生させる] 緊急対応を減らすためのSREアプローチ
プロダクトやサービスは必ず障害を引き起こすものです。壊れないものなどありません。SREの目的は「サービスの信頼性を向上させる」ことであるため、平均故障時間 (MTTF) の最大化と、平均修復時間 (MTTR) の最小化、そして平均故障間隔 (MTBF) の最大化に務めるべきです。
これらの数値を改善するためには、単に障害が起こるのを待って、それを迅速に解決し、再発防止策を施し、ドキュメント化を行うだけではありません。「意図的に障害を起こす」というアプローチもあります。
意図的に障害を発生させ、改善を行う
サービス担当者にとって最悪のケースは以下のようなものでしょう。
- これまで安定稼働していたシステムが突然障害を起こした
- 問題は全く未知で、どのように対処すればよいか検討がつかない
- 長らく安定稼働していたため、チームメンバーも問題の対処に関する知見がない
サービスが安定稼働することは当然、望ましいことではありますが、安定稼働すればするほど、チームメンバーが「障害を解決する経験」「障害から学ぶ経験」「障害から改善につなげるアクションを行う経験」を積むことが困難になります。
グーグルではこうした事態を避けるために、SREが意図的にサービスに障害を発生させています。具体的には「100個の分散MySQLデータベースのうち、1個に対するアクセスを全てブロックする」というものです。
意図的に障害を発生させることで、システムの弱点を発見し、システム相互の依存関係を見つけ、その障害を観察すると同時に、信頼性を向上できるようなアプローチの適用や改善、そしてドキュメント化を行っています。
意図的な障害テストが「テスト」で済まない可能性を考慮する
上記の「100個のMySQLのうち1個のアクセスをブロック」の例ですが、これはグーグルで行った実際の例です。結果、多数のサービスが1時間弱停止するという障害を引き起こしました。問題があったとしても数分でロールバックできるはずが、大規模なロールバックがうまくいかなかったためです。
この例では、ロールバックが機能しなかった時点で、あらかじめテスト済みの別なアプローチを複数行い、並行して主要な開発者からの支援を得ました。結果、1時間弱で復旧できました。
意図的な障害を発生させるという「テスト」は、サービスの長期的な信頼性向上のために効果的なアプローチではありますが、十分に準備していなかった場合、大規模な障害を引き起こす可能性があります。ぜひ、この点は留意していただければと思います。
失敗例から学ぶインシデント管理

インシデント管理とは、「障害発生時に起こる問題を限定的なものとし、できるだけ早く通常運用に復帰させるアプローチ」を指します。以下では、インシデント管理の失敗例から学んでみましょう。
管理されていないインシデント例
- オンコールエンジニアAは、「サービストラフィックのうち1つが、一つのデータセンターで処理できなくなった」障害通知を受けます。そして短時間で障害は拡大し、ついには過負荷からサービスが停止してしまいます。
- ロールバックを行ったが機能しなかったため、オンコールエンジニアAは、他の同僚エンジニアBとC、ならび当該サービスを開発したエンジニアDを呼びます。B、C、Dはそろって調査に入ります。
- 上層部はサービス停止に怒っており、技術担当重役であるEは過去の経験から「こうすればよい。早くアプローチを行え」と指示します。
- Eの指示を断りきれず、Aは試行しますが、効果は全くありませんでした。
- 困ったAは、別なエンジニアであるFを呼びました。Fは「こうしたアプローチが効果があるのではないか」とひらめき、独断で変更を適用しサービスを再起動しました。
- 結果、サービスは完全に停止してしまいました。
上記のようなインシデント管理の失敗例から学べることは、以下の3点です。
1.明文化された手順と役割の不在
理想的な問題解決は、オンコールエンジニアが問題解決できなかった時点で、「誰が何をどのように行うか」が明文化されたドキュメントに従い、インシデント対応を行うことです。しかし、上記ではドキュメントがないままオンコールエンジニアがバラバラに支援を要請しています。また、手順がないことから、問題解決の役割を直接的に負わない技術担当重役が口をはさむという事態も引き起こしています。
2.コミュニケーションの不在
オンコールエンジニアならび支援要請を受けたスタッフは、それぞれの所見を共有ならび、合意した上で判断することなく、バラバラに行動した結果、最終的に独断専行・システム停止を招いています。仮に明文化されたドキュメントがない場合でも、「関係するスタッフ全員が参加する会議」が設定され、共有や決定がされていれば、より効果的なアプローチが行えていたでしょう。
3.不適切なオンコールエンジニアの役割定義
オンコールエンジニアは「できるだけ独力で問題を解決する」ことよりも、「問題を短時間で解決するための環境を整える」ことのほうが重要です。独力での調査やログ確認は、結果、トラブルを深刻化させています。オンコールエンジニアの役割について、より問題解決志向で定義されていれば、対応の遅れと深刻化は避けられたかもしれません。
インシデントを管理するには
上記の失敗例を踏まえ、下では、インシデントを管理するための3つのポイントを紹介します。
1.役割分担
インシデントに関する役割を明確化し、各スタッフが自律的に動けるようにします。具体的には以下のような役割です。
- インシデント責任者: インシデントに関する高レベルの状況を把握し、インシデントレスポンスチームを構成し、各人の責任を割り当てます。そして、他のスタッフに対して、どこにいけば(またはどのような方法で)インシデント責任者に連絡が取れるかを周知することも必要です。
- 実行作業者: 問題調査やシステム修正など、具体的なインシデント対応を行います。実行作業者以外がインシデント対応の具体的なアクションを行うべきではありません。
- コミュニケーション担当者: インシデントレスポンスチームのメンバーと、チーム外に関係者に適切なコミュニケーションをメールなどで取り続けます。場合によっては、インシデントに関するドキュメント管理を行う場合もあります。
- 計画担当者: 実行チームを支援する役割です。バグの登録、夕食の発注、引き継ぎの調整などに加え、インシデント解決後にシステムを通常に戻すための記録の作成を行う場合もあります。
2.インシデントのドキュメントを最新の状況に保つ
インシデント責任者は、複数人で管理できるドキュメントツールを利用して、インシデントのドキュメントを常に更新し続ける必要があります。あらかじめインシデントドキュメントのテンプレートを作成しておき、最も重要な情報をドキュメントの先頭に持ってくるようにすべきです。
3.明確な引き継ぎ
インシデント責任者は、1日の勤務時間が終了したら、引き継ぎの責任者に状況の共有をお行い、引き継ぎの承認を得た上で、「いつ、誰にインシデント責任者権限を引き継いだ」かを、他のスタッフに宣言することが大切です。
まとめ
SREの役割はサービスの信頼性向上です。インシデント管理を適切に行うことは、平均修復時間 (MTTR) の最小化につながり、サービスの安定稼働に直結します。SREに関心がある組織にお役に立てれば幸いです。
ポストモーテムの確立

ポストモーテムの目的は、「根本原因の共有」「再発防止のためのアクション策定」です。しかし、ポストモーテムが機能するためには、組織において「正しいポストモーテム」が確立されている必要があります。
1.ポストモーテムを作成する条件をあらかじめ定義する
「ポストモーテムを作成すること自体が、批判や非難の対象となる」場合は、「できるだけ批判や非難を避けるために、『ポストモーテムを避ける』という事態」が起こりかねません。どのような状況の場合にポストモーテムが必要かについては、あらかじめ明確に定義しておき、無用な議論を避ける必要があります。
2.批判や非難を行わず、建設的であり続ける
ポストモーテムが批判や非難の場であってはいけません。何十年とポストモーテムを行っている業界に「航空業界」や「ヘルスケア業界」があります。いずれも、問題が人命に直結する業界であるため、「ミスがあっても、それを批判・非難せず、強化する機会とみなす」という文化が確立されています。ポストモーテムを作成するのであれば、人命に直結しているか否かは別に、建設的であり続ける必要があります。
3.ポストモーテムをレビューし共有する
ポストモーテムを作成するチームは、正しいステップに従って作成・共有を行うべきです。
チームはまず必要な情報を入手し、関係者からオープンにコメントを収集します。また、本件に関してフィードバックをくれる協力者に正式に依頼します。
次に、作成したポストモーテムをチーム内で、また上長からのレビューを行います。「データ収集」「インパクト分析」「根本原因」「アクションプラン」といった観点でレビューを受けた後に、ポストモーテムを広範囲に公開します。
4.ポストモーテム文化の確立
非難のないポストモーテム「文化」を確立するには、以下のような活動が効果的です。
(1)メールでの情報発信
月刊のニュースレターで、興味深いポストモーテムを共有します。
(2)ポストモーテムグループでの情報共有
社内ポータルや情報共有ツールを用いて、ポストモーテムに興味があるエンジニアが参加できる場を作り運営します。
(3)読書会
過去のポストモーテムを取り上げ、参加者で読み合わせながら「当時実際に参加したエンジニア」と「参加していないエンジニア」が対話することで、理解を深めます。
(4)不運の輪 (Wheel of Misfortune: 新人SRE向けトレーニング)
新人SREのトレーニング目的で、他のエンジニアの協力を得て、過去に作成されたポストモーテムを「リアルに再現」し、育成の場とします。
信頼性を高めるためのソフトウェアテストの種類

SREの観点から実施するソフトウェアテストの目的は、信頼性を向上させることです。これは、平均修復時間 (MTTF) を最小化し、平均故障間隔 (MTBF)* を最大化するとも言い換えられ、信頼性を測定する指標となります。
*MTBF: mean time between failure, 前回に障害が発生してから新たに障害が発生するまでの期間。長ければ長いほどよい。
以下では、ソフトウェアテストについて解説します。
ソフトウェアテストの種類: 一般的なテスト
過去から用いられる一般的なソフトウェアテストは、以下のようなものです。

*画像引用元
Site Reliability Engineering – Chapter 17 – Testing for Reliability
(1)ユニットテスト
分割可能なユニット(クラスや関数など)ごとのテストです。関数や挙動が正確に実行されることを確認します。
(2)結合テスト (Integration Test)
個々のユニットテストをパスしたソフトウェアコンポーネントは、より大きなコンポーネントに組み込まれます。この大きなコンポーネント単位でのテストが結合テストです。
(3)システムテスト
システムに含まれる全てのコンポーネントをテストする最大級のテストがシステムテストです。システムテストには複数のバリエーションがあります。
単純ながら重要な挙動を確認するためのテストで、追加テストを省くために行われます。 [B] パフォーマンステスト
スモークテスト後に実施します。システムのパフォーマンスが許容範囲内に収まることを保証するためのテストです。 [C] 回帰テスト
システム全体の一部分を修正した後に、修正箇所が他に悪影響を及ぼしていないかを確認するテストです。回帰テストの内容を記録しておくことで、今後のシステム修正時に「過去と同じ不適切な修正」を行ってしまうことを防げます。
ソフトウェアテストの種類: プロダクションテスト
(1)設定テスト
Webサービスの設定が正しく行われることを確認するためのテストです。記録されるファイルを確認し、特定のバイナリが実際にどのように設定されているかを確認し、テスト対象の設定ファイルにどのような差異があるかを確認します。
(2)ストレステスト
システムが「どのしきい値で過負荷になるか」を確認するためのテストです。多くのシステムでは、負荷の上昇により「徐々に性能が低下する」のではなく、「しきい値を超えたとたん、一気に致命的な障害が発生する」ため、ストレステストにより限界を認識することが重要です。
(3)カナリアテスト
例えば、利用しているサーバーに新バージョンが出た場合、「一部のサーバーのみ新しいバージョンに差し替えて、問題が発生するかどうかを確認する」ためのテストです。もし問題がなければ残りのサーバーも新バージョンへ移行、問題があれば新バージョンの一部のサーバーのバージョンを戻すことで問題を収束させます。
グーグルのポストモーテムから学ぶ「Google Music楽曲欠落」

Google Music(またはGoogle Play Music)は、グーグルが以前提供していた音楽ストリーミングサービスです(現在はYouTube Musicに統合)。2012年に、グーグルのSREチームが実際に対処した問題について解説します。
「楽曲がスキップされる」という報告から「削除の暴走」を確認
「これまで再生できていた楽曲が、スキップされて再生できない」というユーザーからの報告にうけて、Google Musicのユーザーサポートチームは問題の調査にあたっていました。
そして再生できなかった楽曲のメタデータが、本来の参照先(楽曲のファイル)を参照できなくなっているという事態を確認しました。その結果、プライバシー保護のためのデータ削除パイプラインが暴走し、大量の楽曲を自動的に削除していることが判明しました。
想定外の問題を確認したエンジニアは、即座にアラームを鳴らして、サポートケースの優先度を最大限に高めて、エンジニアリングチームとSREチームに問題を報告しました。
問題を解決するために行ったステップ
バグの特定とリカバリの並行処理
「問題を根本から早急に修復することが必要」と判断したエンジニアリングチームとSREは、チームを2つに分けて対処を介しました。1つめのチームは「楽曲のリカバリ」に当たり、2つめのチームは「データ損失のバグを根本からの改修」に当たりました。
幸いなことに、障害発生の1週間前にディザスタリカバリテストの演習が行われており、新しいツールを利用する準備が整っていました。リカバリチームは、新しいツールを利用して60万にも及ぶ楽曲をマッピングし直す作業を開始しました。
削除された60万の楽曲のうち、テープバックアップに保存されていたものは43万強で、17万弱の楽曲は消失していることが判明しました。しかし、テープバックアップのリカバリプロセスにより、17万弱の楽曲をリカバリする方法を見つけました。
その間、根本原因を究明するチームは様々な仮説検証を行いましたが、原因究明には至りませんでした。
リカバリ第一波
オフサイトでバックアップされたテープ (43万強の楽曲)から、1.5ペタバイトのデータを取り出し、そのテープからデータを取り出す作業が開始されました。データ量ならび楽曲数が多量であったため、テープバックアップシステムからのリストアを要求することだけでも、SRE的なアプローチが必要となりました。
チームの驚異的な活躍の結果、43万曲の楽曲は約2日間で99.95%の楽曲のリストア操作が完了するという結果となり、残りの楽曲のテープ回収も進行中で、ほぼ処理が完了している状態となりました。実際にユーザーが楽曲にアクセスするまでには追加で5日かかっていますが、ソフトウェアの処理的には2日で復旧を完了する結果となっています。
リカバリ第二波
テープバックアップ前に削除された17万弱の楽曲については、Googleストアで購入されたものがほとんどで、ストアのオリジナルの楽曲には影響はありませんでした。よって、比較的短期間で復旧が完了しています。残ったわずかな楽曲は「ユーザーが自身でアップロードした楽曲」で、こちらについてはユーザーに再アップロードを依頼し、リカバリ処理を終えました。
根本原因の追求
最終的に、Google Musicのチームは「データ削除パイプライン」の欠陥を特定しました。当初、エラーに備えた強調機能と大きなデータのマージンが有効に動作していましたが、サービスの成長に伴いパフォーマンスの最適化が行われ、結果、データが複数自動でバックアップされる処理が競合状態を定期的に発生させ、結果、意図しない削除が行われていました。
後にデータ削除パイプラインは再設計され、競合状態が発生されないように改善が加えられました。加えて、大規模な削除バグを検出できるようにモニタリングとアラートの再設定が行われています。
グーグルのポストモーテムから学ぶ「GTapeからのリストア」

グーグルには、GTapeというテープバックアップのシステムがあります。以下は、Gmailのデータをリストアするために、GTapeを用いた例となります。
Gmailのユーザーデータ消失
2011年2月、Gmailから大量のユーザーデータが消失していることが判明し、緊急の電話会議が設定されました。Gmailには多くの保護機構、内部チェックならび冗長性があるにも関わらず、データの消失が確認されました。とはいえ、こうした事態は何度もシミュレーションされていたため、何を行うべきかは明らかにされていました。
- リストアにかかる時間をアカウントごとに算出し通知すること
- (初期推定値である)数時間以内に全アカウントをリストアすること
- (推定されていた完了時間内に)99%以上のデータを回復
データ消失の原因は、Gmaiの内部的な冗長性やバックアップのサブシステムの障害であることが判明しました。この障害は内部的にリカバリできる範囲を超えていたため、大きな障害となりました。
この大規模なデータ消失事故は、結果として30時間で復旧されました。事前のシミュレーションに加え、グーグル社内の多くのチームが支援に参加したことも、短時間で障害を復旧できた原因となりました。
まとめ
サービスの信頼性を高めるために、「最悪の事態に備えておく」ことはSREとして極めて重要な姿勢です。上記のGmailのデータ消失からは、常に最悪を想定し、必要な備えを「机上の計画」としてだけでなく「実地のシミュレーション・訓練」として行っておく重要性を伝えてくれます。
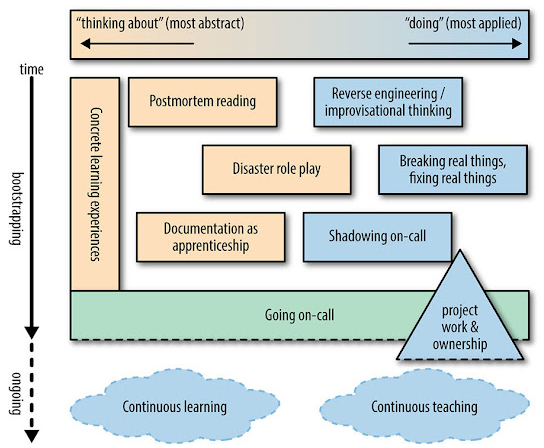
新人SREの教育に関する8つの指針

新人SREを雇用した後に行うことは何でしょうか。技術的なオリエンテーションに加えて、どのような教育を行うべきかの8つの指針についてお伝えします。
SRE新人教育の8つの指針
- 具体的で順序立てられた学習体験を設計する
- リバースエンジニアリング、統計的な志向、基本原則に基づく作業
- ポストモーテルを読み、障害の分析を推奨する
- リアルな障害を人工的に発生させ、本物のモニタリングやツールを用いて修復させる
- 障害のロールプレイングをグループで行う(不運の輪)
- オンコールローテーションにシャドウとして参加し、自分のノートをメインのオンコール担当のノートと比較する
- エキスパートのSREとペアを組み、オンコールトレーニング計画の目的セッションを見直す
- 単純ではないプロジェクト作業を切り出して渡し、サービススタック中の一部を受け持つ機会を与える
新人SREを「下働き」させるのでは成長しない
新人SREは将来的には、エキスパートのSREに成長し、SRE組織をリードすることが期待されています。よって、「シニアなSREの下働きをさせ、突然本番のオンコール担当をさせる」「ポストモーテムを隠す」といった育成は望ましくありません。
*画像引用元
Site Reliability Engineering – Chapter 28 – Accelerating SREs to On-Call and Beyond
https://sre.google/sre-book/accelerating-sre-on-call/
上記の表を参考に、綿密な学習計画を立てて「新人SREメンバーの立ち上げ」を支援しましょう。
データの完全性を考えるヒント(データアクセス)

サービスを運用する上で、データの完全性を考えるにあたり重要な点は、「データが正しく保管されている」ではなく、「サービス上のデータにユーザーが利用可能であり続ける」ことです。
ユーザーは「データが正しく保管されているがアクセスできない」と、「データが破損して消失した」を明確に区別しません。使いたい時に使えなかった、そしてそのダウンタイムが長く続くことは、データ破損と消失と同様の悪いインパクトをユーザーに与えます。
また、アクセスできない期間の長さも重要です。
2011年にグーグルは、一部のユーザーがGmailにアクセスできないという障害を起こしました。この時は最長で4日間もGmailにアクセスできないユーザーが発生しました。メールを日々利用するユーザーからすると、4日間は「あまりに長い」、それどころか、24時間アクセスできなかったとしても「あまりに長い」と判断されました。
Gmailだけでなく、Google Photo、Google Drive、Cloud Storage、Cloud Datastoreなども同様です。いずれも「グーグルのサービス」であり、いずれかが障害を起こすことでグーグルのブランドイメージ全体を毀損しかねません(競合製品への乗り換えも起こります)。
サービスの開発、またはSREとして信頼性向上に努める際は、「ダウンタイムの長さがどの程度以上になると『あまりに長い』と判断されるか」を考慮した上で、適切な信頼性を担保すべきでしょう。
DevOpsとSREの違い
SREのキャリアを目指す方の多くが、DevOpsとSREの違いについて戸惑うようです。詳細は、当サイトに掲載している「SREとDevOpsの違いはなにか」をご覧いただければと思いますが、以下ではそのエッセンスだけお伝えします。
「SREはDevOpsというインターフェイスの実装である」
違いについて端的に解説すると、「DevOpsは思想であり、それを具現化させたのがSREである」といえます。まず、DevOpsについてですが、以下の5ポイントでカバーされます。
- 組織のサイロの削減(風通しのよい組織の実現)
- エラー発生を前提とする(100%を目指さない)
- 段階的に変更を行う(一気にすべてを変更しない)
- ツールと自動化を活用する(サービス成長と正比例で運用工数を増やさない)
- 全てを計測する(モニタリングに基づく数値設定が重要)
ただ、上記はあくまで思想、概念でしかなく、具体的な方法論ではありません。これを具体的にどのように行うかを「トイルの削減・自動化」「SLI/SLOの設定による目標定量化」といった形で、誰でも用いられるように体系化させたものがSREといえます。
変更管理とその重要性

グーグルでは、サービス障害の70%は「稼働中のシステムに対して変更を行った際に発生している」ことを明らかにしました。つまり、変更管理を正しく行うことでサービス障害を未然に防ぐことができたり、万が一障害が発生しても短時間で収束できることを意味します。
では、具体的に何を実現すべきか、ですが、以下の3点とされています。
(1)漸進的なロールアウトの実装
これは、「変更を行う際に、一度にすべてのユーザーに対して変更を適用せずに、少しずつ変更適用を行い、その反応を見ながら適用範囲を拡大する」ことを意味します。万が一問題が発生しても影響範囲は限定的になり、対処も容易となります。
(2)高速かつ正確な問題の検出
これは、トラブルシューティングを適切に行うことを意味し、具体的には直感や経験に頼らずに、理性とデータに基づいた問題への対処を意味します。
(3)安全なロールバック
問題が発生した際に、一つ前のバージョンに安全にロールバックできる仕組みを構築すべきという内容です。
上記3点を正しく行うことで、問題発生範囲の最小化、理性的な問題解決、ユーザーへの影響の最小化が実現されます。
キャパシティプランニング

グーグルでは、SREの責任範囲にキャパシティプランニングを含めています。キャパシティプランニングにおいては、サービスの成長に対して必要な可用性を提供できるキャパシティと冗長性を確保することが重要です。しかし、キャパシティプランニングが正しく行われないケースが多いのもまた実情です。
以下は、適切なキャパシティプランニングを行うための基礎となります。
(1)自然な需要増加の正確な予測
現在のサービス利用状況の増加率のみでなく、サービス開発やマーケティング計画といった複数の観点から予測を作成する必要があるといえます。
(2)突発的な需要増加の発生源を予測に含める
過去に同様のサービスを提供した際の経験を活かし、突発的なニーズの高まりが起こる発生源と、どの程度の伸びが起こり得るかを予測します。
(3)ハードウェアリソースとサービスリソースのキャパシティの関連を把握するため定期的なテスト実施
リソースを正しく把握できていなければ、正しい予測を行っても無意味です。定期的にテストを行い、そのデータを予測にフィードバックします。
プロビジョニング

プロビジョニングは、「需要予測とキャパシティプランニングの結果に従い、キャパシティを確保する」ことです。つまり、プロビジョニングを実施した時点で費用が発生します。小規模のサービスであれば、プロビジョニングの費用はさほど高額ではありませんが、大規模のサービスとなれば、プロビジョニング一回で巨額の費用が動きます。
また、プロビジョニングは正確に行わなければ、確保したキャパシティが正しく利用可能となりません。サービス側に変更を行い、確保したキャパシティが正しく機能するかどうかのテストも必要です。
このため、プロビジョニングの実施は「素早く」「必要なタイミング」でのみ実施すべきとされます。
リソースの効率的な活用

ビジネスとしてサービスを成立させるためには、リソースの効率的な活用を必ず考慮する必要があります(SREの多くもこの点に関わる活動を行います)。
リソースの利用は、「需要(負荷)」「キャパシティ」「ソフトウェアの効率性」を関数で表されます。
- 需要が増加すると、ソフトウェアの速度が低下します。
- ソフトウェアの速度低下は、キャパシティ不足に起因します。
- キャパシティが極端に不足すると、ソフトウェアは反応を返さなくなります。
- キャパシティを追加すると、ソフトウェアの速度が加速され、より多い需要を満たすことができます(しかり多額に費用もかかります)。
これが一般的なリソース不足に対するキャパシティ追加ですが、SREは「ソフトウェアを改修する(コーディングする)」ことで、ソフトウェアの効率性を高めるというアプローチを行えます。これにより、従来であればキャパシティ不足が発生した状況であっても、効率性が高まったソフトウェアにより、速度が低下せずに動作させられる場合があります。
常にモニタリングを怠らず、そしてリソース不足に対してキャパシティを追加するだけでなく、SREがソフトウェア自体に手を入れることで、コストを押さえたリソースの効率的な活用が実現します。
サービスのリスク許容度(コンシューマーサービス)

SREでは、100%の可用性を目指していません。このため、「どの程度の可用性を目指すべきか」を各サービスごとに判断する必要があります。また、「障害発生時のリスクをどの程度許容できるか」についても判断が必要です。
以下では、コンシューマーサービス(個人ユーザーが利用するサービス)におけるサービスのリスク許容度について解説します。
可用性
- どの程度の可用性を提供するかは、以下から判断できます。
- ユーザーが期待するサービスレベルサービスが売上を生んでいるか
- サービスは無料か、有料か
- 競合のサービスレベルはどの程度か
- コンシューマ向けか、企業向けか
グーグルのサービスを例に説明すると、Google Workspace (旧称 G Suite)は企業向けの有料サービスであることから、対外的には99.9%に設定すると同時に、内部的にはより高い可用性を目標としていました。その理由は、99.9%がSLAであり、これを下回ると返金が必要となるためです。
Youtubeは、個人向けの無料サービス(現在は有料プランもあり)です。2006年の買収当時はまだ急速な成長フェーズにいたこと、また当時は有料プランがなかったこともあり、安定稼働よりも機能追加を重視し、かなり低い可用性目標が設定されていました。
障害
障害をいくつかのカテゴリに分類する、以下となります。
- 一時的なアクセス障害
- 完全なデータ消失、データの漏えい
結論からいうと、一時的なアクセス障害はSLOのエラーバジェットの範囲内に収まっている限りは問題はないが、完全なデータ消失やデータ漏えいはサービスの信頼性を大きく損ねる事態となります。
このため、データ消失やデータ漏えいを防ぐためには、システムを全て停止させる(=一時的なアクセス障害が発生する)という判断も必要となります。
コスト
コストを考える上で重要な視点は以下の2点です。
- 1ケタ高い可用性を実現した場合、収入はどう変化するか
- 収入増加は、それを実現するために費やしたコストと見合うか
信頼性は高まったが。それにより収入が増える見込みがない場合は、可用性を高めることはコスト的に見合わないといえます。
エラーバジェットの活用

SREが提唱する概念で最も有名なものの1つが、エラーバジェットです。「開発チームはサービスの開発速度で評価される」「SREはサービスの信頼性で評価される」という異なる評価軸を持つチームが、エラーバジェットをどう活用すればよいか解説します。
エラーバジェットをリリースの指標とする
開発チームとSREの間で、エラーバジェットについて合意ができた場合、開発チームはエラーバジェットの範囲内でリリースを行うことになります。そして、エラーバジェットを使い切りそうになる(例: 想定外の障害が頻発する)場合は、リリースを一時的に停止し、パフォーマンス改善やシステムテストなどにリソースを投下します。なお、サービス開発側の責任でない障害(例: ネットワークやデータセンター障害)の場合でも、エラーバジェットは消費されます。
エラーバジェットを緩めることも選択肢のひとつ
ただ、上記が全てのケースでうまく機能するわけではありません。本ページでも紹介した「dely株式会社(クラシル運営元)」は、サービスの迅速な開発とリリースを重視してエラーバジェットを採用していません。
厳しい競争環境があり、可用性向上よりも迅速な機能追加が求められる場合、エラーバジェットも採用しつつ、迅速な開発とリリースを両立させたい場合は、「エラーバジェットを緩める (SLOを下げる)」ことも選択肢となります。
Google Chubbyから学ぶ意図的なSLOの引き下げ

Google Chubbyは、疎結合の分散システム向けの(ファイル)ロックサービスです。グローバルなサービス運用のために、Chubbyインスタンスを、レプリカが異なる地理的リージョンに分散配置しています。
しかし、Chubbyインスタンスが障害を発生させ、ユーザーに影響が出ていることが判明しました。障害頻度は高くありませんでしたが、それが故に「Chubbyの信頼性は高い」と判断したエンジニアが、Chubby依存のサービスを多数開発した結果、ChubbyがダウンするとChubbyに依存するサービスが立ち上がらない問題が多数生じていました。
これに対してSREチームが行った対策は、「ChubbyはSLOを満たすが、SLOを大幅に超えない(可用性を高めすぎない)」という運用を行いました。Chubbyの信頼性が高すぎなければ、Chubbyに完全に依存するサービスが開発せず、Chubby停止を考慮に入れた設計を行わざるを得ないためです。
一般的には、「Chubbyの可用性をほぼ100%に高める」というアプローチが取られそうなものですが、「Chubbyに依存しすぎて、サービス停止になる設計が悪い」ということで、あえて信頼性を下げるアプローチは、非常に興味深いものがあります。
正しいSLAの理解

SLAとは、「サービス事業者とサービス利用者間で行われる、金銭的な補償を伴うサービスレベルの合意」です。例えば、可用性SLAが99.99%の場合、実際の可用性がこれを下回る場合、サービス事業者はサービス利用者に対して違約金を支払わねばありません。
なお、SLOは「社内的な目標値で、その値を満たさなかったとしても、金銭的な支払いは発生しない」点が最大の違いです。
では、どのサービスにSLAを設定し、どののサービスにSLAを設定しないかですが、これは「グーグル検索」と「Google Workspace (旧称 G Suite)」で説明できます。
グーグル検索はSLAが設定されていません。グーグル検索は無料のサービスであり、利用者は費用支払いが不要です。その代わりに、検索連動型広告の出稿者が「広告料」という名の費用を支払っています。検索連動型広告はクリックごとの課金なので、例えば「ある時間帯に広告が表示さなかった」としても、グーグルは広告主に対して違約金を支払う根拠がないのです。
しかし、SLAがないからといって内部的な運用目標値がないわけではありません。内部的にはSLOが設けられ、その目標を満たすべくSREが行われています。
逆に、Google WorkspaceではSLAが設定されています。Google Workspaceは利用者がその利用費用を支払うサービスであり、例えば「今週まるまる1週間サービスを利用できなかった」という場合は、業務に大幅な支障をきたします。このため、グーグルは利用者または見込客に対して「Google Workspaceを安定的に運用させます」というコミットが必要となります。その、コミットの証がSLAです。
なお、Google WorkspaceのようなSLAが設定されているサービスでは、「適切なレベルのSLA設定が必要」です。ユーザーに失望されるほど低すぎてもいけませんし、すぐに違約金が発生するほど高くてもいけません。サービスを多く利用してもらい、十分な利益を生むためには、SLA設定は慎重に行う必要があります。
SLI定義の標準化

サービスごとに「SLIの定義を何にするか」をバラバラに考えていては、各サービス間でSLIを比較することが難しくなるだけでなく、測定の設定などに都度工数がかかります。よって、標準的なSLIの定義はテンプレート化しておくべきです。以下はその例です。
- 集計のインターバル「集計期間は1分とする」
- 集計の対象領域「クラスタ内の全てのタスク」
- 計測の頻度「10秒ごと」
- 対象となるリクエスト「ブラックボックモニタリングジョブからのHTTP GET」
- データの取得方法「モニタリングシステムを通じてサーバーで計測」
- データアクセスのレイテンシ「最後のバイトまでの時間」
上記はあくまで例ですが、自社の複数のサービスでSLIを定義する際は、できるだけ標準テンプレート化された定義を用いて、定義の設定に工数をかけすぎないように注意してください。
SLOの正しい定義

SLIの定義で重要なのは「望ましい目標から特定の指標にさかのぼる」ことです。
この逆の「特定の指標から望ましい目標を設定する」場合は、単純に測定しやすい指標が設定されることが多く、ユーザーの期待するものに近づかない可能性があるためです。
次に、SLOの明確な定義についてですが、「計測方法と、計測値が適正である条件を指定する」ことが重要となります。以下例となります。
- Get RPCの呼び出しの99%(1分間での平均)が100ミリ秒以下で完了すること(計測の対象は全てのバックエンドサーバー)
- スループットタイプのクライアントのSet RPC呼び出しの95%が、1秒以下で完了すること。
- レイテンシタイプのクライアントの、1KB以下のペイロードを持つSet RPC呼び出しの99%が、10ミリ秒以下で完了すること。
上記を参考に、解釈を間違えることがない明確な定義づくりを行ってください。
SLOの選択と設定における注意点

SLOはあくまで社内的な目標値ですが、これをSREのみで設定することは適切ではありません。当該サービスのSLO設定は、純粋に技術面からのみ設定されるべきではないためです。技術面に加えて、ビジネス面、コスト面、人員などの面を総合的に考慮して設定されるべきです。
その理由は、特に重要なSLOを設定した時点で「どのような陣容でサービスを運営するか」の構造がほぼ定まってしまうこと、また、顧客向けの指標でもあるSLAにも影響するためです。
SLOの選択と設定においては、以下の議論を踏まえるべきです。
- 現在のパフォーマンスに基づいてターゲットを選択しない。これは、サービスが拡大するにつれ「高すぎるSLO」「低すぎるSLO」となる可能性があるためです。
- シンプルさを保つ。SLIを出すのに複雑な計算が必要となる場合は、システムのパフォーマンスの把握しにくくなるためです。
- 「絶対」は避ける。例えば「絶対に落ちないシステム」を目指すべきではありません。ユーザーの必要性を超えたSLO設計は効率的でありません。
- SLOは最小限に留める。SLOは業務の優先順位を決定づけるために設けるもので、そうでないSLOに十分な価値はありません。
- 最初から完璧でなくてもよい。緩めのターゲットから開始し、徐々に厳しくしていくのが現実的です。
よく考えられていないSLO設定により、SREに過度な負荷が集中したり、サービスの品質が低下するといったリスクがあります。開発チームにとって有益で、理にかなった強制力を持つように設定しましょう。
自動化がもたらす3つの価値

SREがサービスの運用を正しく自動化することで、以下の5つの価値を得ることができます。
(1)マニュアルエラーの削減
手作業をどれだけ丁寧に実施したとしても、その正確性は「自動化された処理」ほど高まることはありません。自動化されていれば、マニュアルで作業を実施する担当者により、処理の出来不出来が左右されることもありません。膨大な処理を正しく実施し続けるためには、処理をできる限り自動化する必要があります。
(2)効率的な運用基盤の構築
仮に、1万回の処理に対して、新たな処理を追加したい場合、これを手作業で直すのは大変です。しかし、処理が自動化されていれば、コードを修正するだけで、1万件の処理すべての追加対応を短時間で実施できます。そして、その効率化した処理を別なサービス上で同様に実施でき、処理全体の効率化を実現できます。
(3)高速な修復による時間の節約
自動化により、サービス上で起こった障害などの問題に素早く対応できます。対策が自動化されていなければ、エンジニアが「アラートを見たエンジニアが端末からログインして、問題を確認して、対策を検討して実施する」といった手順が必要です。もし自動化されていれば、エンジニアは自身の手を動かすことなく、極めて短時間で問題は解決されます。
グーグル社内におけるDiskerase障害から学ぶ

グーグルは自社データセンター以外にも、多くのサードパーティのデータセンター(コロケーション設備)を利用しています。コロケーション設備から不要になった機器を撤去する際には、ディスクの内容全体を上書きして、その後にこの消去が成功したかどうかを確認する作業(Diskerase作業)を行っています。
このDiskerase作業が正しく行われなくなったことがありました。CDNのロケーションに設置された消去すべきマシン群をDiskeraseで消去しようとした際に、Diskerase済でないにもかかわらず「Diskerase済」と判断されてしまったのです。さらには、Diskeraseが必要でないマシンに対しても自動化されたワークフローによりDiskeraseが実施され、当該CDNの全てのデータが消失するという事態が発生しました。
ただ、自社のデータセンターのみでユーザーのリクエストを処理できていたため、わずかにレイテンシが増加している以外の影響は起こりませんでした。その後2日間で問題は復旧され、自動化のさらなるチェックとワークフロー変更を行うことで、このような問題は発生しなくなりました。
ここから学べることは、マシンのデータが全て消失するという「最悪の事態」は起こり得るということ、そして「最悪の事態」が起こってもサービス全体には特段の問題は発生しなかったということです。複数拠点を利用して、大規模なサービスを運用するにあたっては、このような最悪の事態を回避するため、自動化が正しく機能するかをテストすべきでしょう。
システムの安定性とアジリティ

サービスの安定性とアジリティは常にバランスを取る必要があります。安定性を重視しすぎると、迅速なリリースや野心的な機能追加が行えなくなります、逆にアジリティを重視しすぎると、サービスは不安定なものになりかねません。このバランスを取ることこそが、SREの役割といってよいかもしれません。
SREにより信頼性を高めることは、開発者のアジリティ高めることにつながります。例えば、本番環境のロールアウトを高い信頼性のもとに実施できるのであれば、本番環境の変更が容易になります。結果、問題が生じたときの修復までの時間が短くなり、利用者への影響を限定的なものとできます。結果、エンジニアはより頻繁に新機能のリリースなどを実施できるようになります。
プロダクションミーティング

グーグルでは毎週、30分から60分程度、SREチームと他の関連する参加者により「プロダクションミーティング」を実施しています。
プロダクションミーティングの目的は、「SREチームが担当するサービス状況について明確に説明し、すべての関係者の認識を高め、サービス運用を改善するため」です。ミーティングが終了した時点で、「参加者全員のサービスの現状に関して同じ認識を持ち、地を持ち寄って話し合うことで、結果としてサービスの改善が促進」されることです。
なお、サービスと生じた問題を「他人事」ではなく「自分ごと」とするために、SREチームメンバーが持ち回りで議長を務めます。この経験は、各SREがインシデント対応中にチーム間で調整を行うときに役立ちます。
プロダクションミーティングでは、サービス運用のパフォーマンスの詳細について話し合い、これを設計や設定、実装と関連づけて考ける形で問題解決を行います。定期的なミーティングにおいて設計上の判断を、サービスのパフォーマンスと合わせて考えることは、協力なフィードバックループとなります。
正しいポストモーテムの書き方

インシデントを振り返り、再発防止のための掘り下げを行い共有するうえで、「どのようにポストモーテムを書くか」は非常に重要です。以下では、含むべき内容を分かりやすくお伝えします。
- 題名
- どのサービスでインシデントが発生したかがわかるような題名にする。なお、ツールが発行したインシデント番号も入れておくと、後の調査の際に役立つ。
- 作成日
- ポストモーテムの作成日
- 作者
- ポストモーテムの執筆者。複数人で執筆する場合は全員を記載
- ステータス
- インシデントの現在のステータス。インシデントが現在も継続しているか否か、アクションアイテムの対応が完了したか否か。
- サマリ
- インシデントを1行でまとめる
- インパクト
- システム面(データへの影響、可用性など)とビジネス面(損失、顧客離反など)の両面を記載
- 根本原因
- インシデントの根本原因を具体的に記載する。何が生じた結果、どのような障害が発生したか。頻度はどの程度か、など
- 発生要因
- 根本原因を端的にまとめる
- 対応
- インシデントを解決するために行ったアクションについて記載
- 検出
- どのような指標で確認を行ったかを記載
- アクションアイテム(再発防止策)
- 4つの項目を記載する
- アクションアイテム: 具体的な再発防止策を記載
- 種類: 再発防止策の種類を記入。例えば、「問題の回避」「問題の緩和」「新しいプロセス追加」「その他」から選択
- 担当者名: アクションの担当者名を記載
- バグの種類: どのようなバグに対応するアクション化を記載。バグとは関係ない場合は「該当しない」と記載
- 4つの項目を記載する
- 教訓
- 3つのポイントで箇条書きで記載
- うまくいったこと: インシデントの検知、自動対応、手動対応、共有などでうまく行ったことを記載
- うまくいかなかったこと: 上記と逆に、うまくいかなかったことを記載
- 幸運だったこと: 事前に行われていたモニタリング、自動化や再発防止策が機能し、状況が改善された点を記載
- 3つのポイントで箇条書きで記載
- タイムライン
- 分刻みで、「いつ、何が起こったか、誰が何を行ったか、その結果どうなかったか、どのような打合せを持ったか、決定事項は何だったか、インシデントはいつ収束したか」を箇条書きでまとめる
- 参考情報
- 参考となる情報(例:ダッシュボードのURLなど)を記載
インシデント管理におけるベストプラクティス

インシデント対応は常に負荷がかかるものですが、ベストプラクティスに従い管理することで、迅速で正しい解決に導くことが可能です。7つのポイントに絞ってお伝えします。
- 1.優先順位
- まず被害の拡大を食い止め、次にサービスを回復し、その後根本原因の証拠を保存します
- 2.準備
- あらかじめインシデント管理手順をドキュメント化します
- 3.信頼
- インシデント解決に当たるメンバー全員が、割り当てられた役割内で完全な自律性を持ってもらうようにします
- 4.自己観察
- インシデント対応中に自分の感情の状態に注意を払います。自分がパニック担っていると感じたり、問題に圧倒されていると感じた場合は、より多くの支援を求めます
- 5.対案の検討
- インシデントレスポンスとして、現在行っているアクションを継続するか、それとも別なアクションを新たに行うかを、常に検討・評価します
- 6.訓練
- インシデントレスポンスのプロセスを定期的に用いた練習を行い、身につけます(「不運の輪」トレーニングの実施など)
- 7.持ち回り
- 前回インシデント担当をリードした人は、次には別な役割を担う、といった具合に役割を交代し、全てのチームメンバーが、すべての役割を果たせるようにします
将来の発火点を予測する

SREチームは、日々信頼性向上のためのアクションや、インシデント対応を行っていますが、「単に発生したインシデントを解決し、対策のためのアクションを取る」だけでなく、「インシデント発生を未然に防ぐ」ためのアクションも必要です。
以下では、「インシデントを未然に防ぐ」「インシデント解決を妨げる問題発生を防ぐか」の観点で、どのような兆候に特に注意を払うべきかを解説します。
- SREチーム内の知識ギャップ
- チーム内のAさんはABCシステム担当、BさんはDEFシステム担当といった具合に担当が明確に別れた場合、相互に必要な知識が共有されておらず、インシデント対応に支障をきたす場合があります
- SREが開発したサービスの重要性増加
- 1人のSREが開発した信頼性向上のためのサービスが、気づかないうちに重要性を増しているが、それに誰も気づいていない場合があります
- 次のアップデートへの過度な依存
- 「次のアップデートに修正をすべて盛り込むので、当座のアクションは行わない」として、問題へのアクションが何ヶ月も先送りにされる場合があります
- 「よくあるアラート」の見落とし
- 一般的なアラートすぎて、特に対応する必要がないとみな判断している場合です。実は重要な問題が背後に隠れていないか調査を行うか、アラートを上げるルール変更を行うべきです
- 正式なSLI/SLO/SLAが設定されていないが、クライアントから不満が上がっているサービス
- システム的な観点、ならびビジネス的な観点で、SLI/SLO/SLAの設定についての議論が必要です
- 短絡的なキャパシティプランニング
- 「メモリ消費が著しいのでメモリを追加しましょう」といった、十分なテストや予測を伴わないキャパシティプランニングを指します。多角的な観点からテストならびモニタリングを行い、本当にキャパシティ追加が今必要かについて再考すべきです。
- アクションアイテムが「ロールバック」のみのポストモーテム
- 根本原因の解決につながらないポストモーテムは、問題の再発の原因となります。
プロダクトローンチを成功させるには

グーグルでは、プロダクトローンチを成功させるために、以下の5つを満たすローンチプロセスを重視しています。
- 軽量であること
- 頑健であること
- 綿密であること
- スケーラブルであること
- 適応性があること
上記は、「軽量でありながら綿密」というように矛盾する内容も含まれます。こうした内容のバランスを取るために、以下の3点に留意しています。
- 単純さ
- 基本を正しく理解し、あらゆる不測の事態に備えようとしない
- 個別対応のアプローチ
- 経験豊富なエンジニアが、個々のローンチに合わせてプロセスをカスタマイズする
- 高速な共通パス
- 常に共通のパターンをたどるローンチを特定し、そのローンチに対するシンプルなプロセスを作成する(例えば「新しい国でのプロダクトローンチ」などが該当する)。
SLO設定において期待値を管理する

SLOの設定は、ユーザーがサービスに対してどの程度の期待をしているかにより判断できます。例えば、写真共有サービスであれば「低い可用性」は避けるべきですが、アーカイブの管理システムであれば「低い可用性」でも問題ないと判断できます。
期待値を適切に管理するため、以下の2点を活用できます。
- 安全マージンを確保する
- ユーザーに公開するSLO値より、内部的なSLO値を高くすることで、この差分を安全マージンとして確保できます。仮に内部的なSLOを下回ったとしても、ユーザー向けSLOを上回っていれば、ユーザーを失望させずに余裕あるサービス運用ができます。
- 過剰達成を避ける
- SLOよりもはるかに高い可用性が維持されている場合、ユーザーはSLOではなく、現実に達成されている可用性を当然と考え、それに依存します。これを避けるためには、意図的に可用性を低下させて、高すぎる依存を減らすことも有用です。
日本では、「過剰達成を避けるために、意図的に可用性を低下させる」のは難しいかもしれませんが、「計画的なサービス停止時間」を設けることで、同様の効果が得られます。このサービス停止時間はエラーバジェットとなりますので、開発などの用途で利用できます。
オンコールにおける直感 vs. 理性

近年の研究によると、人は困難に直面したときに取る行動は、「直感的・反射的に行動しようとする」か、「理性的かつ慎重に行動しようとする」かの2つに分かれます。
例えば、「同じアラートが過去に3回飛んできて、同様の処理を行った」後に、「4回目の同じアラートが飛んできた」場合、過去の経験に頼った直感的な対応を行いたくなります。しかし、明確なデータの裏付けなく行動してしまう直感的な行動は間違いであることも多いのが実情です。
よって、インシデント対応においては理性的かつ慎重に対応することが望ましいといえます。このためには、オンコール担当者のストレスを減らすことが重要です。具体的には、以下の3つを満たすべきでしょう。
- 明確なエスカレーションパス
- しっかりと規定されたインシデント管理手順(ドキュメント)
- 非難を伴わないポストモーテム文化
産業エンジニアリングから学ぶSRE

SREはソフトウェアエンジニアリングの概念ですが、他のエンジニアリング領域から学ぶこともできます。
例えば、製造業においては「予想外の事態に備えるために、組織のどのレベルであっても厳密に守るべきプロセスを細部に渡って確立する」ことが重視されています。これは、「従業員野安全を真剣に捉える」ことを意味し、何かおかしいと思ったらすぐに手を挙げることが推奨されています。日本では、トヨタ自動車が「異常が起きたらすぐにラインを止める」という教育が浸透していることでも有名です。
この安全に対する姿勢は製造業だけでなく、「原子力」「軍隊」「信号システム」といった業界でも同様です。これらの業界では、安全性に関する信頼性レベルが国により明確に定められています。
アメリカ海軍から学ぶSRE

ソフトウェアエンジニアリング以外の業界から、SREに関するヒントを学ぶことができます。
アメリカ海軍では、「小さなタスクを行う際の注意不足が、大きな障害につながる」ことを繰り返し認識させています。例えば、潤滑油のメンテナンスを手順通りに行わないことで、潜水艦に甚大な被害が処うる可能性がある、といった内容です。
このため、原子力海軍では、定期的なメンテナンスで小さな問題が雪だるま式に拡大しないように心がけています。
ソフトウェアエンジニアリングも同様です。システムは複雑に相互接続されているため、1つの領域の小さなアクシデントが複数のコンポーネントに影響を及ぼします。システム全体の信頼性を高めるために「タスクを正しく行う」、そして「タスクを自動化して正確に行わせる」ことが重要となります。
通信業界から学ぶSRE

「通信インフラ」という言葉があることから分かる通り、通信業界はサービスの高い可用性を当然のように求められる業界です。
予測を超えた通信利用により、キャパシティが逼迫した際、通信業界では余剰キャパシティを投入して、キャパシティ逼迫の継続を防いでいます。 この余剰キャパシティは、緊急時や、システムを過負荷とする既知のイベントに対して前もって投入することもできます。
これは、Webサービスでも同様です。例えば、「テレビTVを大量に投下する」タイミングで、サイトへの訪問者急増を見越して、キャパシティを増加させるのは一般的です。こうしたSREの考え方は、通信業界を参考に設計されたと言えるかもしれません。
ディザスタリカバリテスト (DiRT)

サービスの信頼性を確保するためには、最悪の事態が発生したことを想定した備えが重要となります。ディザスタリカバリテスト (DiRT) では、本番環境に対して障害を意図的に起こすことで、以下を確認・発見します。
- システムが予想通りに反応するかどうかの確認
- 予想外の弱点がないかどうか確認
- 制御不能なサービス障害が怒らないように、システムを頑健にする方法の発見
そして、DiRTを実施する戦略として以下が重要であることもわかりました。
- 安全への徹底した組織的集中
- 細部への注意
- 余剰キャパシティ
- シミュレーションと実地訓練
- トレーニングと認定
- 詳細な要求の収集と設計への強い集中
- 多層防御
DiRT実施に当たっては、上記を考慮したうえで実施することで、より多くの成果が得られます。
プロダクションレビュープロセス (PRR)

PRRとは、「Production Readiness Review」の略で、サービスの詳細に基づいて、プロダクション環境における信頼性を保証するために、自分たちが学んだことや経験を適用するレビュープロセスです。
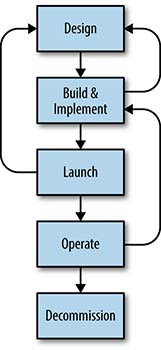
画像引用元: The Evolving SRE Engagement Model
https://sre.google/sre-book/evolving-sre-engagement-model/
上図は一般的なサービスのライフサイクル図です。PRRはサイクルのどの部分からでも開始できますが、SREが関わるステージは時間とともに拡大していきます。
なお、上記のような単純なPRRモデルは徐々に進化します。具体的には以下の通りです。
- 単純PRRモデル
- 拡張エンゲージメントモデル
- フレームワークとSREプラットフォーム
航空業界から学ぶSRE

航空業界でパイロットを目指す人は、いきなり飛行機を操縦しません。パイロットになるための教育課程を経た後に、極めてリアルなシミュレータを利用して、実際のデータを流して操縦の訓練を行います。
トレーニング中に本番で飛行機を操作した結果、大きな事故を招くことは許されません。このため、お客様やパイロットを危険にさらすことなく、本番と同等の経験が得られるような、可能な限り細かいレベルまで再現されたシミュレータが必要となっています。ただ、ある時点まで経験を積んだパイロット候補生は、実際に飛行機を操作する訓練に移行し、実地でさらなる経験を積みます。
これはSREでも同じと言えるかもしれません。お客様が現在利用中の本番環境のサービスを利用して、実験的な操作を繰り返し行うことはリスクが高すぎます。もちろん、プロダクション環境を利用したディザスタリカバリテストは非常に有用で、想定していない依存関係を明らかにするなどの価値はありますが、頻繁に行えるようなものではありません。このため、テスト環境でのトレーニングと、本番環境でのテストをうまく組み合わせることで、SREの成長を促進できるのです。
トラブルシューティングの落とし穴

トラブルシューティングを行う上で、一般的に注意すべき落とし穴4つが指摘されています。
- (1)関係ない症状を見たり、メトリクスの意味を取り違える
- (2)システムへの入力や環境の変更方法を正しく理解していない
- (3)仮説構築力が不足、ならび過去の問題に固執する
- (4)事象を間違った関係性で理解する
上記(1), (2)は正しい問題への学習や経験の蓄積により解消できます。(3)については、障害の発生確率を考えれば避けられる論理的な間違いです。そして(4)は、相関関係は因果関係ではないことを忘れてはなりません。
原因解明のプロセスにおいて障害を理解することは、問題解決の第一歩です。分かっていること、分かっていないこと、分からなければならないことをはっきりさせるためのアプローチを行うことで、「何が問題なのか」「どのように修正すべきなのか」をシンプルに把握できるようになります。
ライフセーバーから学ぶSRE

ライフセーバーとSREは全く違うカテゴリのものですが、SREがライフセーバーから学ぶことができる点もあります。それは、人命に関わる領域においてはトレーニングと認定(資格)が非常に大切であるということです。
ライフセーバーは、厳格なトレーニングに基づく認定を取得し、かつ定期的に再度認定を受ける必要があります。認定には、運動能力に関するものだけでなく、救急救命のような技術的なもの、さらには運用に関するものもあります(例: チームで救急救命を行う際の役割分担の取り決めなど)。さらに施設固有の事項についての学習も必要です。
SREも同様と言えるかもしれません。技術的な要素の獲得、技術に関する認定資格の獲得・更新、規則に沿ったSREチームの運用と文化の確立、担当するサービス固有の知識習得、などの要素により「SRE」が構成されていると言えます。
医療デバイス業界から学ぶSRE

操作ミスやメンテナンスミスにより、人の生命や身体に大きな影響を及ぼしかねないのが、医療デバイス業界です。SREは、医療デバイス業界からも学ぶことができます。重要な考えは「フェイルセーフ」です。
例えば、レーシック手術を行うための機器は、できるだけフェイルセーフであるように設計されています。このため、機器を利用する医師や、メンテナンスを行う技術者からの要求を集めた上での設計が極めて重要となります。
こうした機器の設計により、「1つボタンを押し間違えた結果、患者に回復不能な損傷を負わせてしまう」ような機器の挙動を防ぐことができます。
SREにおいても、「人間が単純な操作ミスを行った結果、後戻りできないほど甚大な損害が生じる」ような設定・設計を用いるべきではありません。フェイルセーフを考慮した設計を取り入れるべきでしょう。

東京在住のソフトウェア開発者、Motouchi Shuyaです。
システムの開発・運用・最適化が好きです。

