
NIMとは
NVIDIA Inference Microservicesの頭文字をとってNIMです。迅速なエンタープライズ対応デプロイメントのためのマイクロサービスを提供してくれます。NVIDIAのGPUで動かすことに最適化されたモデルをすぐにデプロイできるほか、対応タスクもReasoningからSpeech to Textなど多岐にわたります。学習済みモデルを利用してプロダクト開発を加速させたい方にとっては第一候補とすることができるものだと思います!
NVIDIAインテリジェント AIエージェント| NVIDIA
ちなみにNeMoというものを使うと独自に生成AIの構築もすることができるため、学習済みモデルでは少し物足りないなといった方に対しても改善するためのプラットフォームが提供されていますので、併せてご確認ください。
NIMの使い方
NIMの使い方はいくつかあり、例えばGoogle Cloud上ではMarketplaceで展開されており、Kubernetesクラスタとして展開できるようです。今回はNVIDIAさんが提供しているプラットフォームを利用し、デモを実施してみました。
以下のページに行くと利用できるサービスが多数展開されており、試してみたいモデルを選択するとデモを実施することができます。今回は提供されているAPIの中からいくつかピックアップして使ってみたいと思います。なお、今回はデモ用途として利用しているため、商用利用としてサービスの一部に組み込む場合は利用方法が変化する可能性があります。その点については別の記事で取り扱う予定です。
llama-4を用いた画像の説明
こちらのllama-4-maverick-17b-128e-instructを用いて、指定した画像の説明をさせてみようと思います。利用する画像は以下の画像になります(GTC2025の宿泊先で筆者が初日に食べた朝ご飯になります)。

画像を入力するときにサイズ制限がかかりますので、制限内に収まるように画像を修正してください。
まずはAPIキーの作成をする方法について説明します。なおこのAPIキーは開発検証用として提供されているものであり、本番環境などで利用することは避けてください。画面上右側にGet API Keyという緑色のボタンがありますのでそちらをクリックしてください。
すると以下のような画面が表示されますのでGenerate Keyを選択してください(こちらの説明にも再度キックスタート用の開発として使ってくださいと明示されていますので遵守をお願いします)。
キーが生成されると以下のような表示がされます。制せ営されたキーをコピーして控えておいてください。
ソースコードは基本的にサンプルと同じですが以下のようになります。変更点としては、出力テキストを日本語になるように指定しました。
from pprint import pprint
import json
import requests, base64
from dotenv import load_dotenv
load_dotenv()
API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC = os.environ.get("API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC")
invoke_url = "https://integrate.api.nvidia.com/v1/chat/completions"
stream = False
with open("image.jpg", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
assert len(image_b64) < 180_000, \
"To upload larger images, use the assets API (see docs)"
headers = {
"Authorization": f"Bearer {API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC}",
"Accept": "text/event-stream" if stream else "application/json"
}
payload = {
"model": 'meta/llama-4-maverick-17b-128e-instruct',
"messages": [
{
"role": "user",
"content": f'What is in this image? Please answer in Japanese. <img src="data:image/png;base64,{image_b64}" />'
}
],
"max_tokens": 512,
"temperature": 1.00,
"top_p": 1.00,
"stream": stream
}
response = requests.post(invoke_url, headers=headers, json=payload)
if stream:
for line in response.iter_lines():
if line:
print(line.decode("utf-8"))
else:
pprint(response.json())
APIキーは事前に作成したAPIキーを利用するようにしてください。これを実行すると以下のようなテキストを取得できました。特に違和感なく、画像の描写を語っていると思います。
API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC=<API_KEY> python llama_4_test.py
この写真には、皿の上の朝食のプレートが写っています。プレートには、目玉焼き、ソーセージ、ジャガイモ、トーストが載っています。2つの小さな容器に入った調味料が添えられています。一つは赤みのあるソースで、もう一つは黄色いソースです。背景には黒い急須と塩と思われる瓶があります。机は大理石のような模様の灰色です。試しに別の画像でも検証してみましょう。次は以下のような画像を対象に同じコードで実験してみました。

この画像を入力した結果が以下になります。
この画像には、歩道と道路が写っています。歩道には黄色の椅子とテーブルが置かれていて、人が座っています。道路の向こう側には、いくつかの建物が見えます。空は青く晴れています。こちらの画像でも、内容として適切に描写できているのではないでしょうか。
ocrdnetを用いた文字認識
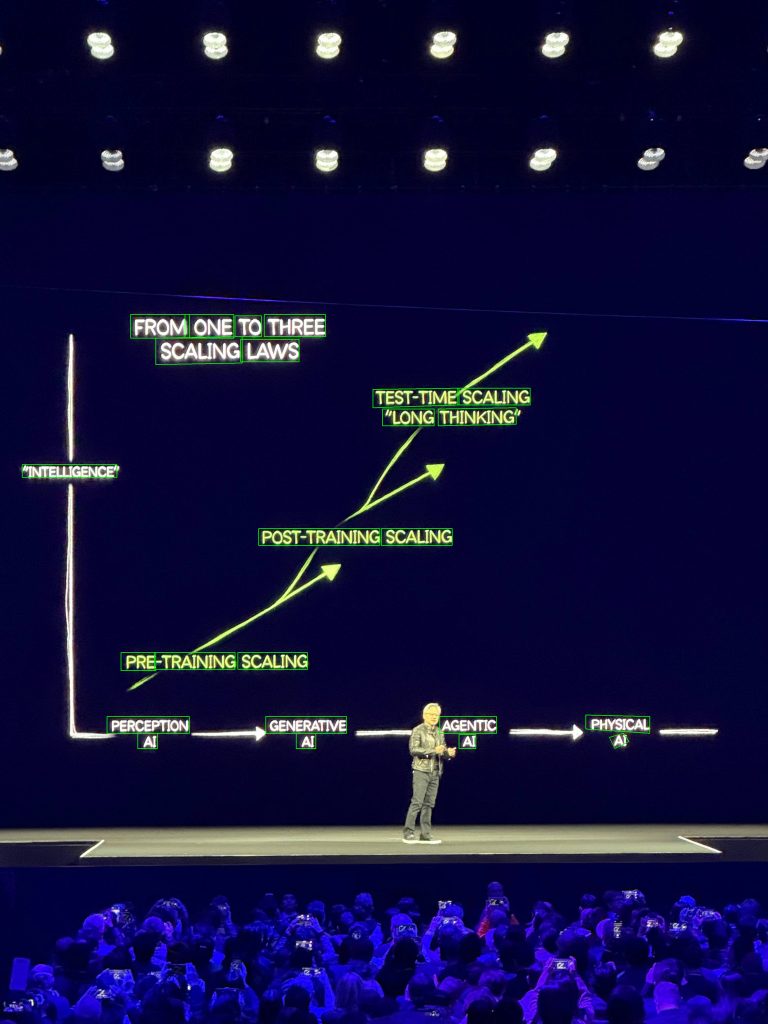
次に、こちらのocrdnetを使ってみます。ocrdnetは学習済みのOCRモデルとなります。今回はサンプル画像としてGTC2025のKeynoteで撮影した以下の画像を入力してみたいと思います。
APIキーについては先ほどの方法と同様にして発行してください。また、ソースコードについては公式で提供されている以下のコードをご利用ください。
import os
import sys
import uuid
import zipfile
import requests
# NVAI endpoint for the ocdrnet NIM
nvai_url="https://ai.api.nvidia.com/v1/cv/nvidia/ocdrnet"
from dotenv import load_dotenv
load_dotenv()
API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC = os.environ.get("API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC")
header_auth = f"Bearer {API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC}"
def _upload_asset(input, description):
"""
Uploads an asset to the NVCF API.
:param input: The binary asset to upload
:param description: A description of the asset
"""
assets_url = "https://api.nvcf.nvidia.com/v2/nvcf/assets"
headers = {
"Authorization": header_auth,
"Content-Type": "application/json",
"accept": "application/json",
}
s3_headers = {
"x-amz-meta-nvcf-asset-description": description,
"content-type": "image/jpeg",
}
payload = {"contentType": "image/jpeg", "description": description}
response = requests.post(assets_url, headers=headers, json=payload, timeout=30)
response.raise_for_status()
asset_url = response.json()["uploadUrl"]
asset_id = response.json()["assetId"]
response = requests.put(
asset_url,
data=input,
headers=s3_headers,
timeout=300,
)
response.raise_for_status()
return uuid.UUID(asset_id)
if __name__ == "__main__":
"""Uploads an image of your choosing to the NVCF API and sends a
request to the Optical character detection and recognition model.
The response is saved to a local directory.
Note: You must set up an environment variable, NGC_PERSONAL_API_KEY.
"""
if len(sys.argv) != 3:
print("Usage: python test.py <image> <output_dir>")
sys.exit(1)
asset_id = _upload_asset(open(sys.argv[1], "rb"), "Input Image")
inputs = {"image": f"{asset_id}", "render_label": False}
asset_list = f"{asset_id}"
headers = {
"Content-Type": "application/json",
"NVCF-INPUT-ASSET-REFERENCES": asset_list,
"NVCF-FUNCTION-ASSET-IDS": asset_list,
"Authorization": header_auth,
}
response = requests.post(nvai_url, headers=headers, json=inputs)
with open(f"{sys.argv[2]}.zip", "wb") as out:
out.write(response.content)
with zipfile.ZipFile(f"{sys.argv[2]}.zip", "r") as z:
z.extractall(sys.argv[2])
print(f"Output saved to {sys.argv[2]}")
print(os.listdir(sys.argv[2]))API_KEY_REQUIRED_IF_EXECUTING_OUTSIDE_NGC=<API_KEY> python ocrdnet_test.py上記のコードを実行すると、指定した出力フォルダに二つのファイルが生成されます。一つはOCRで検出されたテキスト位置にバウンディングボックスが描かれた画像が保存されており、今回の例では以下のようなファイルが保存されました。結果を見ると画像のテキスト位置にボックスが全てついておりとても精度が高いことが伺えます。また、ボックスは水平のものだけでなく回転も認識しているようで、より難易度の高いOCRを実行できていると言えます。
もう一つのファイルはバウンディングボックスとそこに書かれているテキストを保存したファイルになっており、今回の例では以下のような内容となっていました。出力の結果の座標を用いたい場合はこちらのファイルの内容をJSON形式で読み込んであげれば自由に利用ができます。
{
"inference_time": 0.3264620304107666,
"metadata": [
{
"label": "la",
"polygon": {
"x1": 1807,
"y1": 2892,
"x2": 1873,
"y2": 2892,
"x3": 1873,
"y3": 2947,
"x4": 1807,
"y4": 2947
},
"confidence": 0.9892578125
},
{
"label": "a",
"polygon": {
"x1": 2399,
"y1": 2903,
"x2": 2454,
"y2": 2887,
"x3": 2476,
"y3": 2919,
"x4": 2421,
"y4": 2947
},
"confidence": 0.95361328125
},
{
"label": "ai",
"polygon": {
"x1": 1166,
"y1": 2887,
"x2": 1243,
"y2": 2887,
"x3": 1243,
"y3": 2947,
"x4": 1166,
"y4": 2947
},
"confidence": 0.998046875
},
/*以下省略 */
...
]
}
他の画像についても少し試してみました。データセットとしてはTextOCRからデータを参照しました
※ライセンスについてはこちらを参照ください:https://creativecommons.org/licenses/by/4.0/
いくつか試してみまして、やはりはっきりと見えやすいものは認識率がとても高い傾向にあると思います。一方少しぼやけていたり角度がついているなど少しイレギュラーな状態に近づくにつれて認識漏れなどが発生しているようです。ただしこれは他のOCRモデルについても同様の傾向があると思いますし、他のモデルと比べても推論速度は早く精度も悪化しているわけではないと感じます。また、斜めの文字に対しても適切に識別している点はとても評価できるポイントです。というのも、文字が傾いている場合、バウンディングボックスを構成する点群が3つ以上、または角度を指定するパラメータの最低3つが必要になり、その分学習が難しくなるためです。




まとめ
今回は、NVIDIAが提供しているNIMというサービス群の中から、いくつかモデルを試してみました。学習済みモデル自体はhuggingfaceなど利用できる環境はいくつかありますが、サービスとしてローンチすることが容易である点、NVIDIAのGPUに最適化されたモデルを即時に利用できる点などメリットが多いことが特徴だと感じました。どのようなモデルが利用可能かは公式ページをぜひご参照ください。