
はじめに
こんにちは。Sreake事業部DBREチームのsenoです。
10月に入り、暦の上では秋となりました。とはいえ夏の暑さはまだまだ続いておりますね。
最近は、気持ちだけでも秋を感じるために「〇〇の秋」と称して色々やってみています。
読書・行楽・スポーツ…。
Sreakeといえば「技術」ということで、「技術の秋」と題して、今回はBigQueryデータキャンバスという機能について書いていこうと思います。
機能発表から時間は経ってしまっていますが、「どういう機能なのか」知らない方もいると思います。
この機会に、基本を一緒に学んでいきましょう。
BigQuery データキャンバスとは
データ キャンバスで分析する | BigQuery | Google Cloud
BigQueryデータキャンバスを仕様すると、自然言語を使用してデータの検出、クエリ、可視化を行うことができます。BigQueryデータキャンバスは有向非巡回グラフ(DAG)でデータソース、クエリ、可視化を操作できる、分析用のグラフィックインターフェイスを提供します。
これにより、メンタルモデルに対応した分析ワークフローを視覚的に確認できます。
(Google公式より引用)
BigQueryデータキャンバスとは、Google Cloud Next’24で発表されたBigQueryの新機能です。
2024年9月の時点ではプレビュー機能となっていますが、すべてのユーザーが利用できます。
BigQueryデータに対して、自然言語を利用してデータ分析を行うことができる革新的な機能です。
現時点でできる操作一覧は以下の通りです。
【できる操作一覧】
- 自然言語を解釈し、
SELECT FROMで表されるSQLを生成する - 棒グラフや折れ線グラフ、散布図等のグラフを生成する
- グラフをカスタマイズする
- クエリ結果に対する簡単なサマリーを生成する
- テーブルやクエリ結果の関係性をDAGとして表現する
- 作成したグラフをJupyter Notebookとしてエクスポートする
自然言語を利用してクエリの生成やデータ分析ができるため、データアナリストはもちろんのこと、データエンジニアにとっても、日々の業務を効率化する強力なツールとなる可能性を秘めています。
触ってみる
今回は、BigQueryの一般公開データセット内にある「natality(1969~2008 年に全米 50 州、コロンビア特別区、ニューヨーク市で登録された、米国のすべての出生数のデータ)」データセットを使い、データキャンバスでデータの分析やグラフ化を実際にやってみたいと思います。
データキャンバスを開く
BigQuery Studioのコンソール画面からからクエリタブ→「データキャンバス」を選択します。
すると、以下のような画面に移動します。
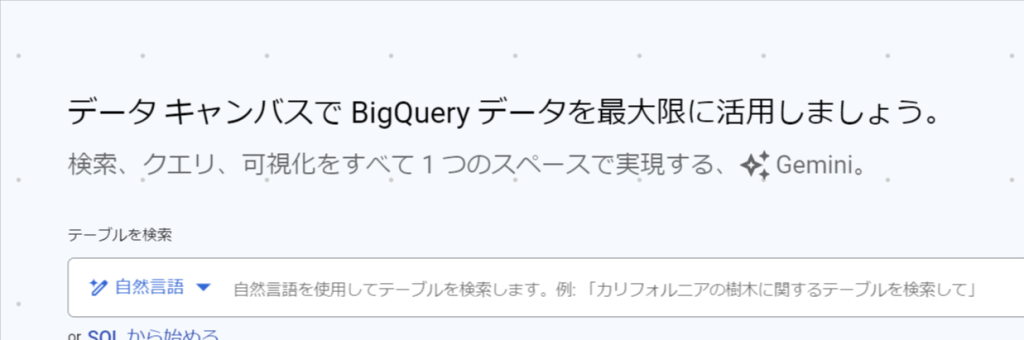
「テーブルを検索」のボックスに「natality」と入力し検索をかけると、このプロジェクト内において今回の検索に該当するデータセットとテーブル一覧が出てきます。
今回は「natality」テーブルを選択し「Add to Canvas」を押します。
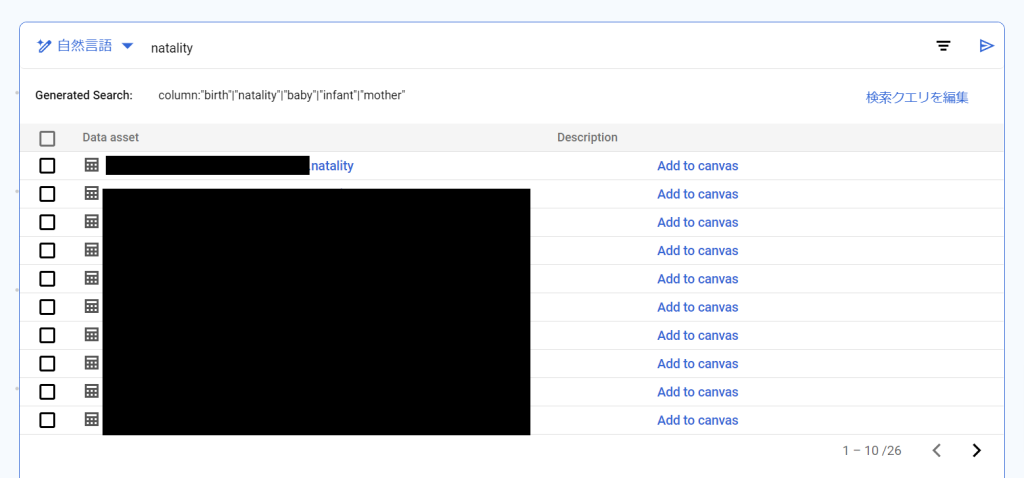
テーブルの詳細情報やデータの内容を見ることができます。
内容が分析したいものと合致していれば画面下の「クエリ」を押します。
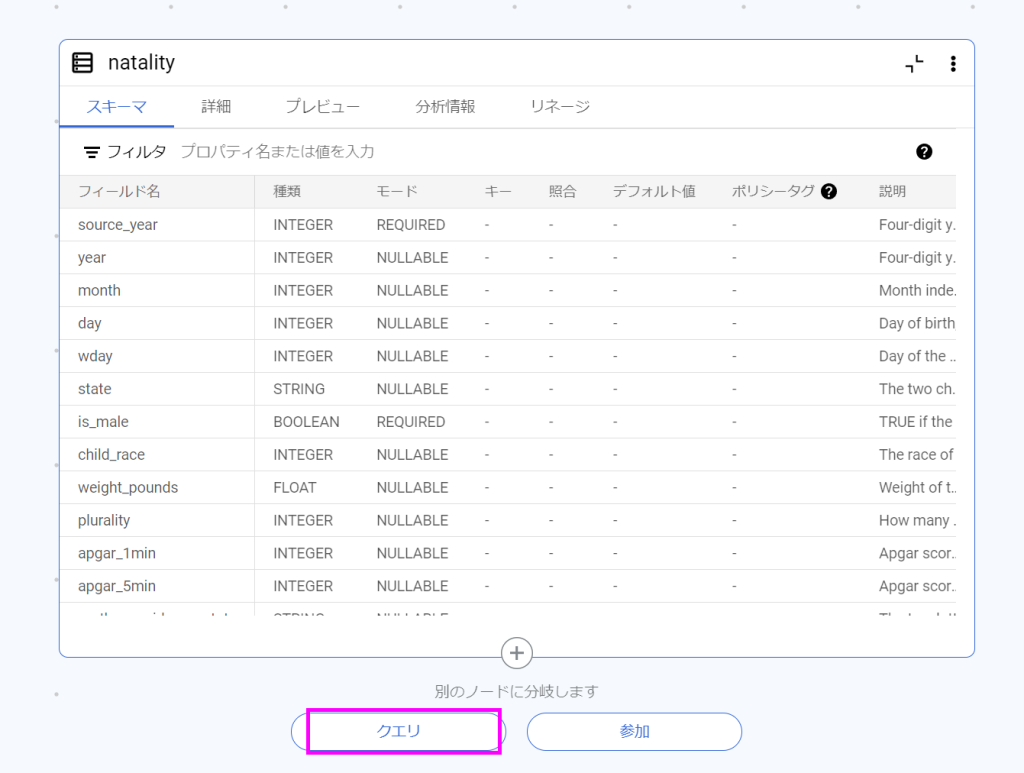
クエリ編集画面が出てくるので、ここにクエリを入力、もしくはGeminiでクエリを生成することができます。
今回はGeminiでクエリを生成する方法を利用してみようと思います。
算出データは「ニューヨークにおける年別の出生数」と「出生数が多かった年別に並べ替える」の2つとします。
プロンプト入力欄に「ニューヨーク市における出生数を年別にカウントして、出生数の多い順に並べてください」と指定します。
すると、以下のクエリが生成されました。
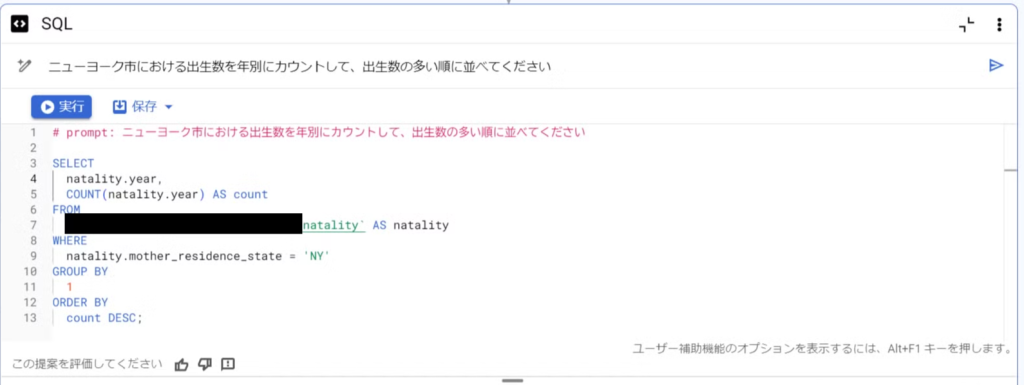
クエリの内容とスキャン量を確認し、問題がなければ「実行」。
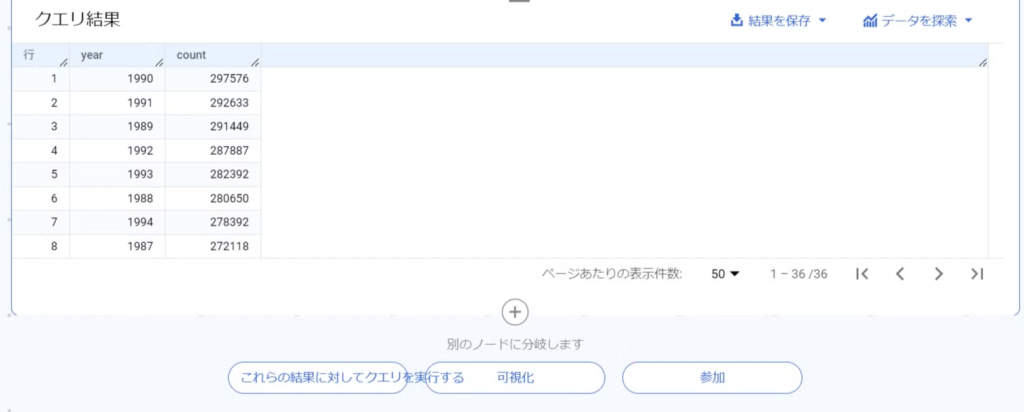
次にデータの可視化をやってみます。
実行結果の下に「可視化」ボタンがあるので選択。グラフの種類が選べるので「棒グラフの作成」を選びます。
年別の出生数の棒グラフを表示できました。
なお、クエリ内では「出生数が多かった年別に並べ替える」をしていますが、棒グラフでは年順に並んでいます。
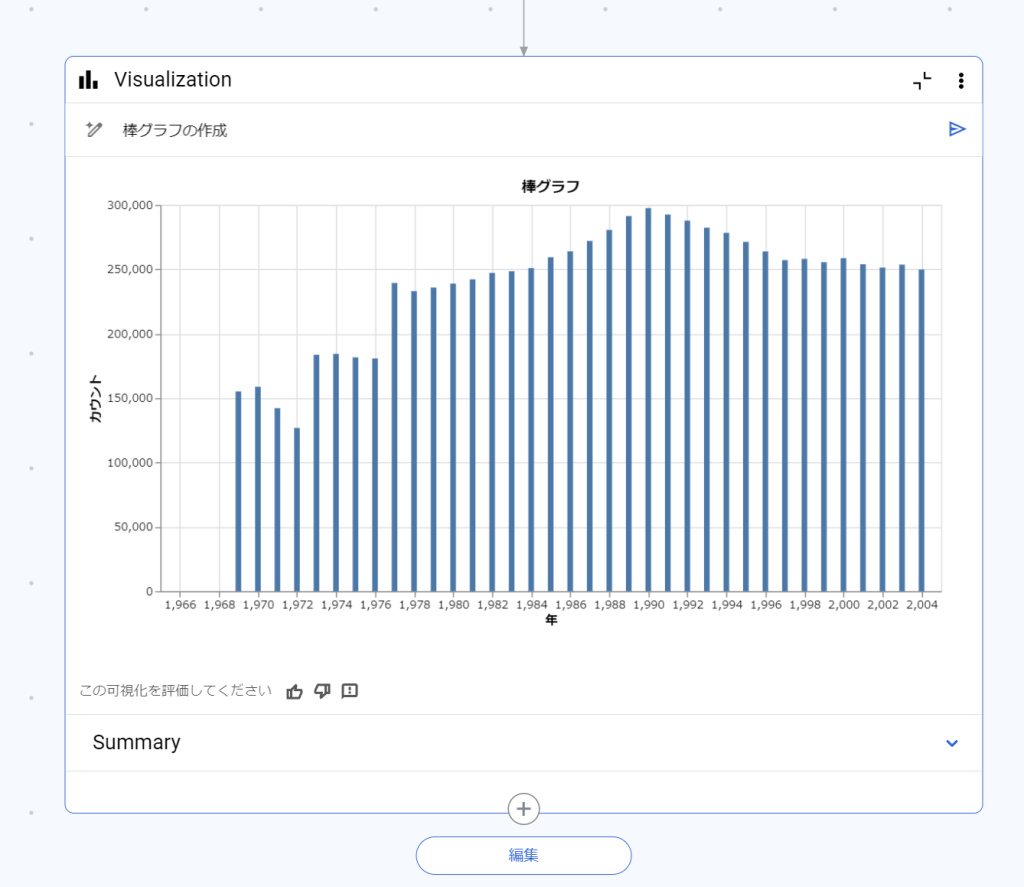
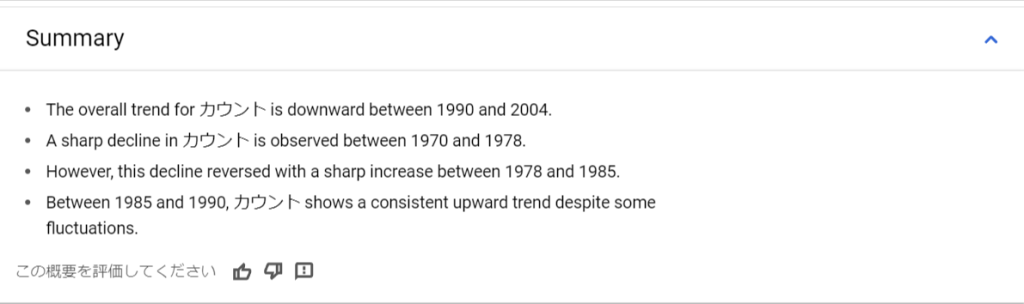
「Summary」を開くと、出力された結果に対してGeminiが考察した内容が記載されます。
(英語のみの提供となっていますが、今後の日本語対応にも期待したいところです)
これで基本的な操作は終了です。
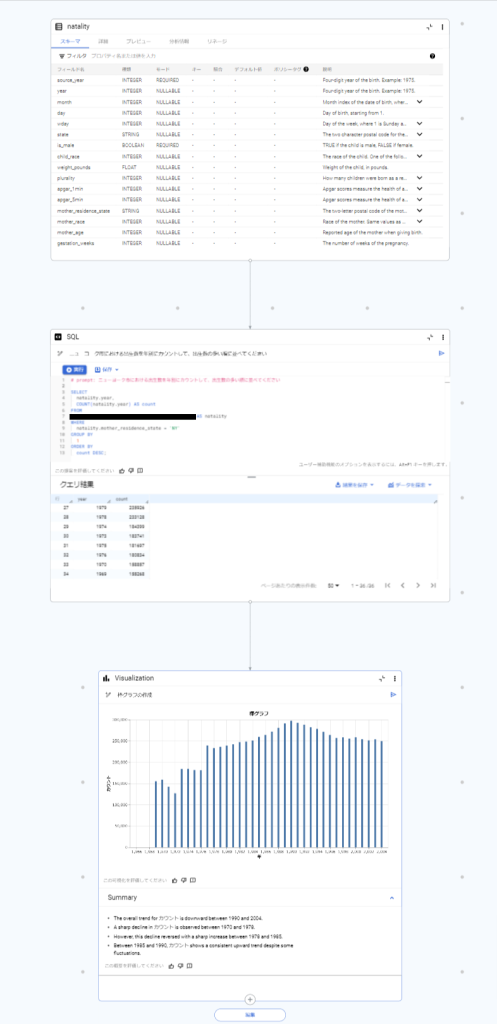
今回実行した内容はDAG形式で表示されるようになっており、全体像は以下のようになります。
データキャンバスの仕様について
どうやってSQL生成をしているのか?
BigQueryのGeminiは、アクセス権限のあるテーブルのメタデータにアクセスできます。これには、テーブル名、列名、データ型、列の説明などが含まれます。BigQueryのGeminiは、テーブル、ビュー、モデルのデータにアクセスできません。
(Google公式ドキュメントより)
Googleの公式ドキュメントによると、Geminiはテーブルのメタデータを元にSQLを生成しています。
テーブルのメタデータとは、主に以下を指します。
- テーブル名
- カラム名
- データ型
- カラムの説明文
逆を言えば「データの中身は見ずにSQLを生成している」という仕様になっています。
このような仕様のため、カラム説明文やクエリの指示文章の表現が曖昧になっている場合、期待したクエリが返ってこない(精度が悪い結果で返ってくる)という可能性もあります。
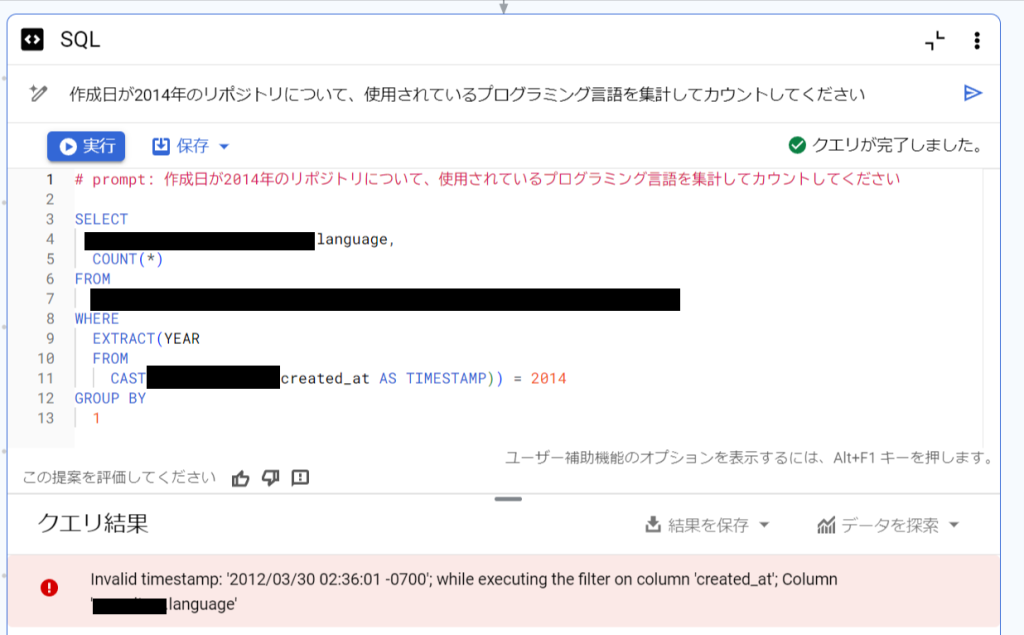
以下は、「natality」とは別のテーブルを利用した際のデータキャンバスのクエリ生成の結果の1例です。
該当テーブルにはカラムの説明文などは記載されていませんでした。
この状態で簡単な内容のプロンプトを入力して生成した結果、テーブルにはないカラム名を指定したり、データ型も意図しない型で変換しようとしているクエリが生成されてしまうことがありました。
精度を上げて利用するには
テーブルやカラムに説明文を設定する
Geminiはテーブルのメタデータを参照してSQLを生成します。
分析したいテーブルにどんなデータが入っているのかを、説明文に具体的に記載してあげることが重要になります。
【例】
性別を「1・2・0」で分類しているカラムがある場合、
「1は男、2は女、0は不明と分類」というように説明文に記載する。
プロンプト(指示文章)の文章をわかりやすいものにする
データキャンバスはSQLに近い文章であるほど、SQLの生成精度が向上する傾向があります。
SQLに近い文章というものについて「これ!」という程明確な内容はまだありませんが、以下のような観点で書いていくと良いでしょう。
【例】
- テーブル名・カラム名・説明文に出てこないワードは使わないようにする
- ドメイン特有の用語はGeminiがわからない場合もあります
- 処理内容が明確になるように書く
- 「カウント」をしたい際に、「集計」といった「意味を広く持つ言葉」で指定しないこと
まとめ・感想
今回はBigQueryデータキャンバスについての基本概要と、簡単に触ってみた内容をまとめてみました。
「自然言語を利用してデータ分析ができる」という点において、非常に画期的な機能であり、基本的な操作方法を理解すれば、多くのユーザーにとって強力なツールになり得ると感じました。
クエリだけでなくデータから考察もできるという点は、「おおまかにデータを見たい」といった時に役立つでしょう。
SQLの生成精度に関しては、データの管理方法やプロンプトの文章によって大きく変わる印象があります。
しっかりと活用するにはメタデータの整備は必須となりますし、必ずしも「期待通りのSQL」が出てくるわけではないため、「これは期待したSQLではない」と判断できる知識も現時点では必要です。
しかしながら、データキャンバスはまだまだ開発段階の機能であるため、今後のアップデートでどのように進化していくのか楽しみな機能です!