
自己紹介
高橋 楓
公立千歳科学技術大学理工学部2年の高橋楓です。普段は趣味や他社の長期インターンにてソフトウェア開発を行っており、インフラ基盤にはDockerを利用しています。しかし、KubernetesやGoogle Cloudをソフトウェア開発に組み込んだ経験はなく、それらの技術をソフトウェア開発のプロセスにどのように組み込めるのかを知りたいと考え、今回のインターンに参加しました。
竜 鶴吉
早稲田大学 基幹理工学部 情報通信学科 学部4年の竜 鶴吉です。大学では、コンテンツ指向ネットワークと呼ばれる技術を活用し、使いやすい分散型のIoT連携システムを構築するというテーマで研究を行っています。興味のあるSRE関連の技術を追求できる良い機会と思い、本インターンに参加しました。
はじめに
研究テーマの概要と選定背景
今回は、Kubernetesのセキュリティについて調査しました。
前半では、高橋がKubernetesを用いた開発においてCI / CDパイプラインにどのような保護を適用できるかを調査しました。
現代のソフトウェア開発では、CI / CDの重要性が増しています。CD FoundationとSlash Dataが発表した「State of CI/CD Report 2024」においては、CI / CDパイプラインの構築などのDevOpsプラクティスを実践する開発者の割合が増加していることが示されました。 (1-1)
しかし、CI / CDを開発プロセスに組み込むことには、一定の注意を要します。OWASP Top 10 CI/CD Security Risksにあるように、CI / CDパイプラインの設定上の欠陥が原因で、悪意あるコードの混入などの脆弱性が生じることがあります。 (1-2)
したがって、CI / CDへのセキュリティ対策手法を概観することが必要であると考え、それを今回の調査テーマに選定しました。
後半は、竜がeBPFを用いたコンテナランタイムセキュリティルールについて調査を行いました。
eBPFを用いたツールを触ってみたいという思いがあったのとセキュリティ周りは自分自身あまり触れたことのない分野だったので、この機会に気になった技術について調査してみようと思いました。今回は、eBPFを使用したコンテナランタイムセキュリティツールであるTetragonとFalcoについて比較をするような形で、アーキテクチャや具体的なポリシーの記述および動作確認、具体的なユースケースなどを調査しました。
想定読者
- CI / CDを開発に組み込もうとしている、あるいはすでに組み込んでいる方
- CI / CDのセキュリティに関心のある方
- eBPFがどのように活用されているか知りたい方
- コンテナランタイムセキュリティ技術に興味のある方
Kubernetesシステムのセキュリティ対策について
近年サイバーセキュリティの脅威が増している中、Kubernetes等のクラウドネイティブ技術において、多層防御のアプローチが重要になっています。
まず、Kubernetesシステムでは、ソースコードをビルドしてコンテナイメージを作成し、KubernetesクラスタにPodとしてイメージをデプロイすることで、アプリケーションを動作させます。その過程の概要を下図に示します。
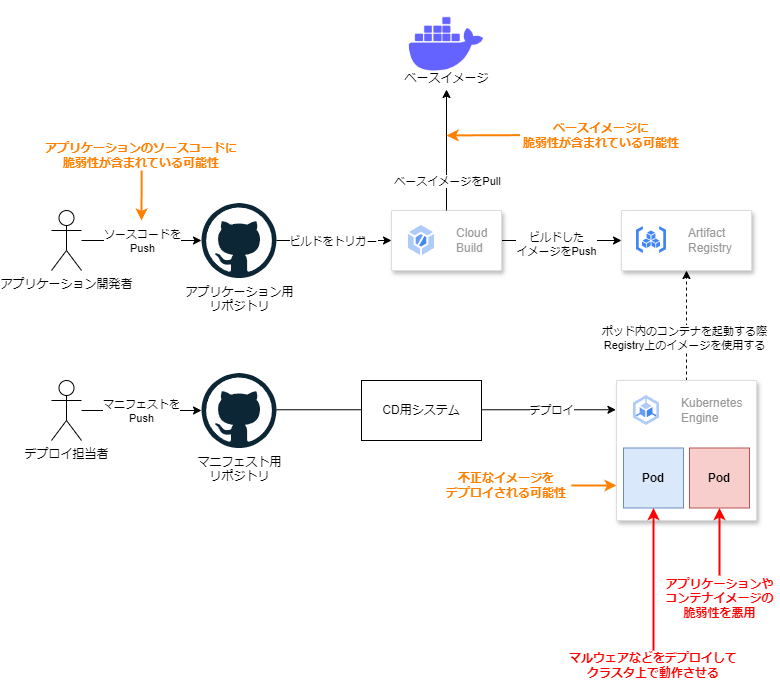
図の右下には、Kubernetesクラスタに対して発生しうる被害を2例挙げました。
まず重要なのは、これらの被害を未然に防ぐことです。これらの被害は、橙色で示したような脆弱性やKubernetesクラスタの設定不備に起因します。したがって、脆弱性による被害を未然に防ぐには、各種の脆弱性の有無を事前に検査し、検査を通過したものだけがKubernetesクラスタにデプロイされるようにしなければなりません。
また、被害を未然に防ぐだけでなく、被害の発生をいち早く検知できるようにしたり、被害の発生が疑わしいときに被害の拡大を抑えたりすることも重要です。
CI / CDにおいてセキュリティが必要になる理由
CI / CDは、CI(継続的インテグレーション)とCD(継続的デリバリー)のことを指す言葉です。(1-4)
開発者は「CI / CDパイプライン」と呼ばれる処理のフローを定義し、GitHub ActionsやCloud Buildといったツール上でそれを実行します。これを利用することで、ソースコードがGitHubリポジトリなどにコミットされたとき、自動テストやイメージのビルドが自動的に実行されるようにフローを構築できます。 (1-5)
テストやビルドは、開発プロセスの中で何度も繰り返し行われる行為です。CI / CDを用いてそれを自動化することで、開発速度を向上させることができます。
現代のソフトウェア開発において、CI / CDパイプラインはその心臓部といえる存在です。実装されたコードをデプロイされるまでに、CI / CDパイプラインは機密情報を含む数多くのリソースにアクセスします。また、その性質上、本番環境に対して変更を行う権限も持ちます。このように多くの権限を持つCI / CDパイプラインは、攻撃者にとっては有益な攻撃対象となります。(1-2) (1-3)
したがって、CI / CDパイプラインに適切な保護を行うことは、重要なリソースを攻撃から守るうえで重要といえます。
ランタイムセキュリティが必要になる理由
効果的なサイバーセキュリティの実践のために、クラウドネイティブな環境ではセキュリティ的脅威を検知することが防御策の一つとして不可欠です。サイバー攻撃が増加する中、クラウド上のアクティビティを可視化する必要があり、セキュリティ上の脅威を効果的に検知するためには、疑わしい挙動をリアルタイムで検知できるランタイムセキュリティシステムの導入が重要です。(2-1)
CI / CDにおけるセキュリティ技術の検証方法
本記事前半ではCI / CDパイプラインにセキュリティ技術を実際に組み込み、効果を検証しました。本項では、検証用の環境構築や、パイプラインの実行方法について説明します。
CI / CDツールについて
CI / CDツールには様々な種類があり、この記事でそれらすべてを扱うことはできません。
そこで本記事では、CIツールとしてGoogle Cloud Buildを取り扱います。Cloud Buildでは、Google Kubernetes Engineへデプロイを行うこともできるため、CDツールを取り扱うことはしません。 (1-6)
Google Cloud Buildとは
Google Cloud Buildは、Googleが提供するクラウドサービスであるGoogle Cloudの機能の一つです。GitHubリポジトリなどと連携することができ、特定のブランチにコードがpushされたときにフローを実行するような設定ができます。 (1-7)
Cloud Buildに行わせたいフローは、cloudbuild.yamlという名前のYAMLファイルに定義します。
検証環境
本記事での検証は、GitHubリポジトリ上にサンプルコードやcloudbuild.yamlを配置して行いました。下記に構成を示します。
サンプルGitHubリポジトリ
GitHubリポジトリは、アプリケーションコードなどを配置するappリポジトリと、Kubernetesマニフェストを配置するmanifestリポジトリの2つを用意しました。
また、それぞれのリポジトリにcloudbuild.yamlも配置することで、CI / CDパイプラインを構成しました。
- gcloud-build-sample-app(以下、appリポジトリ)
- https://github.com/coolwind0202/gcloud-build-sample-app
- アプリケーションの実装に用いるリポジトリを想定したものです。
- 内容
- Flaskアプリ用のソースコード
- Dockerfile
- Flaskアプリを5000番ポートで動作させるために使用します。 (1-8)
- cloudbuild.yaml
- CIでのセキュリティ対策の紹介に利用するファイルです。
- gcloud-build-sample-manifest(以下、manifestリポジトリ)
- https://github.com/coolwind0202/gcloud-build-sample-manifest
- Kubernetesのマニフェストを配置するリポジトリです。
- 内容
- manifest.yaml
- 指定したimageを1個のReplicasで起動し、LoadBalancerタイプのServiceを用いてアプリケーションにアクセスできるようにします。 (1-9) (1-10)
- cloudbuild.yaml
manifest.yamlに記述したマニフェストをGKEクラスタにapplyします。
- manifest.yaml
Google Cloudの設定
- Cloud BuildとGitHubリポジトリの接続
- appリポジトリとmanifestリポジトリの両方をそれぞれ接続しました。
- それぞれのリポジトリのmainブランチにpushすると、対応するリポジトリの
cloudbuild.yamlの実行がトリガーされます。(1-11)
初回のビルド
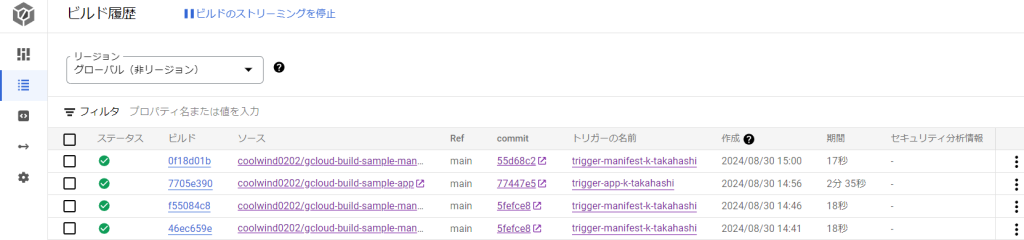
ビルド履歴画面について
Cloud Buildのビルド履歴画面は下の画像のようになっています。
- 「ステータス」の列が「!」となっている場合は、ビルドが失敗しています。
- 「ビルド」の列のリンクをクリックすると、ビルド時のログや、どの段階でビルドが失敗したのかを確認することができます。
手動でのビルド
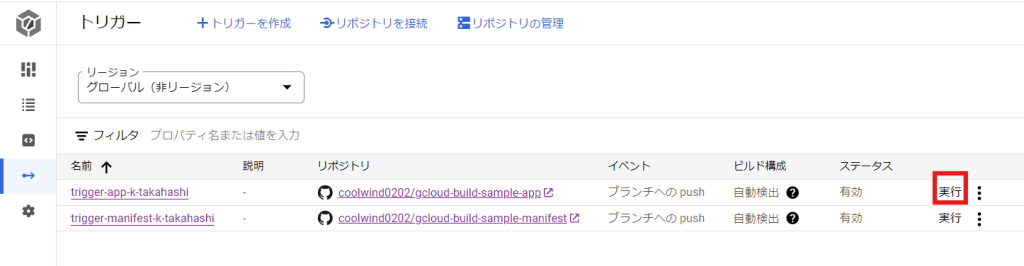
まだappリポジトリに関連づけたトリガーが一度も実行されていない場合は、手動でトリガーを実行し、イメージのビルドを行う必要があります。
Cloud Buildのトリガー画面を下に示します。この画面で、appリポジトリに関連づけたトリガーの実行ボタンを押します。
appリポジトリ用のcloudbuild.yamlは、何らかのGitコミットと関連付けられてトリガーされることを想定しています。
そのため、本記事の執筆時点でのappリポジトリの最新コミットのハッシュである77447e5f1d03524711bbbc241616de548c0b55ee を「commitハッシュ」に入力します。
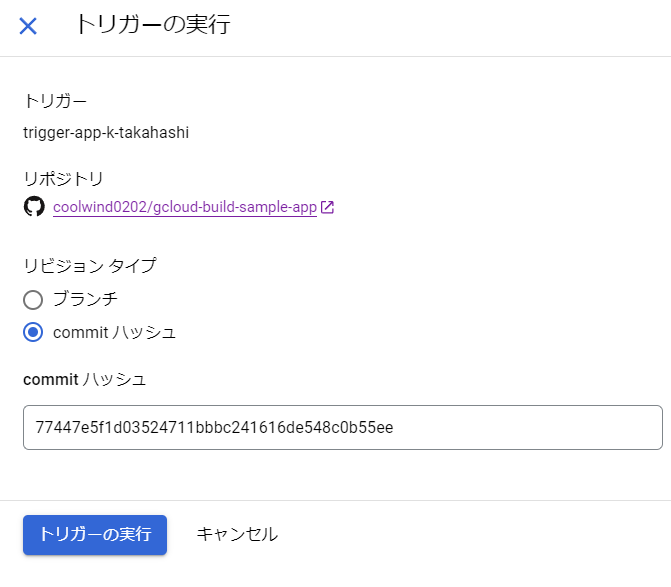
「トリガーの実行」ボタンを押すと、ビルドが開始され、Cloud Buildの履歴画面のビルド履歴に追加されます。
Trivyで既知の脆弱性を検査する
本項では、Trivyを用い、コンテナイメージに含まれるOSパッケージに既知の脆弱性が存在するかどうかを検査します。
既知の脆弱性について
コンテナイメージに関する脆弱性について説明する前に、既知の脆弱性に関する一般的な説明を述べます。
プロダクトは様々なコンポーネントに依存しています。そのため、コンポーネントに存在する脆弱性が原因で、プロダクトまでもが脆弱性を抱える危険性があります。プロダクトをセキュアに保つには、コンポーネントに脆弱性が見つかったとき、その脆弱性情報を速やかに検知して対処する必要があります。
幸いなことに、過去にコンポーネントに見つかった脆弱性はデータベースにまとめられ、CVE識別番号と呼ばれる番号を振られ管理されています。 (1-12)
Trivyとは
本項で紹介するTrivyは、既知の脆弱性情報を収集し、プロダクトが依存するコンポーネントに既知の脆弱性が存在しないかを洗い出すのに有用なスキャナーツールです。 (1-13)
Trivyはさまざまなファイルやビルドアーティファクトを対象に検査を実施することができます。しかし、本記事ではKubernetesを用いた開発プロセスを想定しているため、コンテナイメージに含まれるOSパッケージの脆弱性を検査する機能のみを紹介します。
なお、ここでのOSパッケージとは、dpkgやaptといったパッケージマネージャで管理されるパッケージのことをいいます。 (1-14)
なぜOSパッケージに検査を行うのか
通常、コンテナイメージには大量のOSパッケージが含まれています。しかし、それらのOSパッケージに含まれる脆弱性が原因で、Kubernetesクラスタやポッドに何らかの攻撃を行える可能性が生じることがあります。そのため、OSパッケージに含まれる脆弱性を効率的に検査できる方法が必要なのです。
ローカル環境で実行する
Trivyは、Dockerをインストールしているシステム上であれば容易に試すことができます。 (1-15)
たとえば、Dockerイメージの一つであるpython:3.7 をTrivyで検査するには、次のようなコマンドを実行します。
docker run --rm image aquasec/trivy python:3.7
コマンドを実行すると、脆弱性データベースの取得などが行われたのち、下の画像のような表が表示されます。
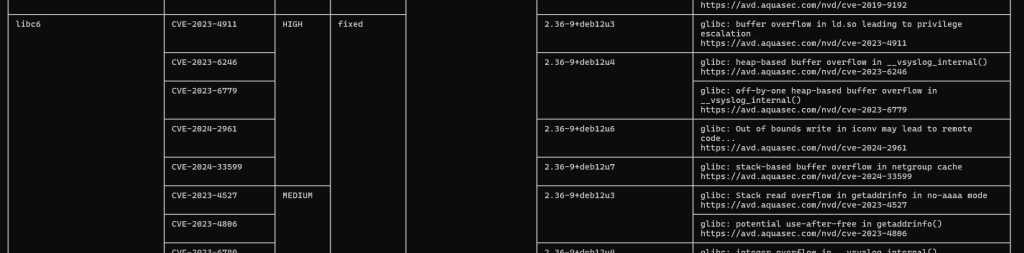
各列の意味は次の通りです。
- 1列目: 脆弱性が検出されたライブラリやミドルウェアの名前
- 2列目: CVE識別番号
- 3列目: 脆弱性の重大度(Severity) (1-16)
- 4列目: 脆弱性に対する修正パッチが提供されている(Fixed)かどうか
コミュニティ提供ビルダーのセットアップ
ここからは、Trivyによる脆弱性検査をGoogle Cloud Buildに組み込みます。
Trivyは、数行の記述で簡単にビルドステップに組み込めるようになっていますが、そのためには、事前に「ビルダー」と呼ばれるイメージをビルドし、レジストリにpushする必要があります。ビルダーとは、各ビルドステップを実行する際に使用される特別なイメージです。
Trivy用のビルダーをセットアップするには、下記ドキュメントの手順を実行します。ドキュメント内のbuilder-nameの値はtrivyとします。
基本的な脆弱性検査
appリポジトリのcloudbuild.yamlのstepsには、次のようなビルドステップが含まれています。
このビルドステップでは、Trivyの出力をtrivy-all-(ビルドID).jsonという名前のJSONファイルに保存します。 (1-17)
# 検知できるすべてのコンテナイメージ脆弱性を JSON でファイルに保存する
- name: 'gcr.io/$PROJECT_ID/trivy'
args: [
'image',
'-f', 'json',
'-o', 'trivy-all-$COMMIT_SHA.json',
'asia-northeast1-docker.pkg.dev/$PROJECT_ID/$_REGISTRY_REPOSITORY/app:$COMMIT_SHA'
]しかしこの設定だけでは、ビルドステップがすべて完了したあとにJSONファイルの内容を確認することができません。ビルドステップ完了時にCloud Storageのバケット内にJSONファイルが保存されるようにするために、cloudbuild.yaml のルートには次の設定も記述しています。 (1-18)
なお、artifacts.objects.locationには、Cloud Storageのバケット名を指定します。
artifacts:
objects:
location: 'gs://$_BUCKET/'
paths: ['trivy-all-$COMMIT_SHA.json']以上のビルドステップが完了すると、Cloud Storageの指定したバケット内には次のようなファイルが作成されます。

クリティカルでfixedな脆弱性が見つかったときにパイプラインを異常終了する
本項では、以下の2つの条件を満たす脆弱性が見つかったときにパイプラインを異常終了させる方法を考えます。
- 重大である
- 脆弱性に対する修正パッチが提供されている
Trivyでは、脆弱性の重大度(Severity)や、修正済(Fixed)かどうかの状態を元に、検出した脆弱性リストにフィルターをかけることができます。(1-19) フィルターをかけるには、次のオプションを渡してTrivyを実行します。
--severity HIGH,CRITICAL- 重大度がHIGH以上である(HIGHまたはCRITICAL)の脆弱性のみに絞り込む
--ignore-unfixed- 修正パッチが提供されている脆弱性のみに絞り込む
条件を満たす脆弱性が見つかったときにパイプラインを終了させるには、どのようにすれば良いでしょうか?
そのためには、--exit-code 1 オプションを渡してTrivyを実行します。このオプションは、条件を満たす脆弱性が見つかったとき、Trivyの終了時のステータスコードを1にします。 (1-20)
Cloud Buildは、ビルドステップが0以外のステータスコードで終了した場合にパイプラインを終了します(デフォルト設定の場合)。
以上のことから、次のようなビルドステップを追加すると、今回の目的を達成できます。
# 重大かつ修正パッチが存在する脆弱性を検出した場合はパイプラインを終了する
- name: 'gcr.io/$PROJECT_ID/trivy'
args: [
'image',
'--severity', 'HIGH,CRITICAL',
'--ignore-unfixed',
'--exit-code', '1',
'asia-northeast1-docker.pkg.dev/$PROJECT_ID/$_REGISTRY_REPOSITORY/app:$COMMIT_SHA'
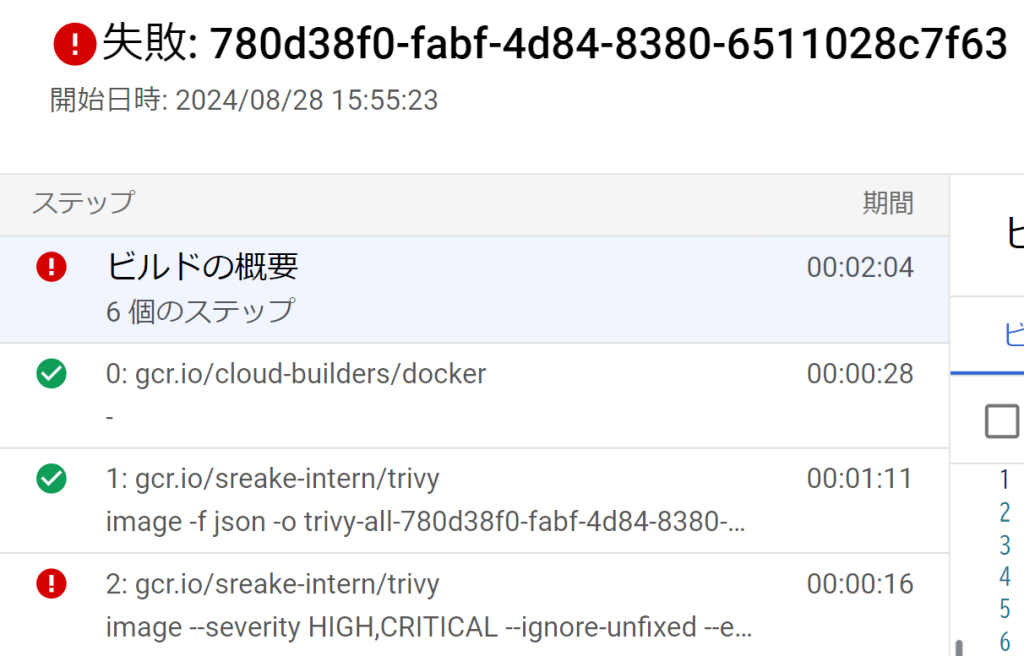
]Trivyでビルドが失敗しているかを確認する
appリポジトリに関連づけたトリガーを実行した際、ビルドステップのステータスが次のように表示されている場合は、前述の条件を満たす脆弱性が検出されたために失敗しています。
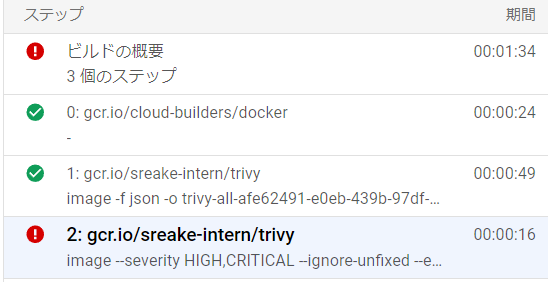
ビルドログを確認すると、どのような脆弱性が検出されたのかを確認することができます。
たとえば下図では、CVE-2024-5171 が検出されたことが原因でパイプラインが異常終了したと考えられます。

検査結果に含めてほしくない脆弱性を指定する
脆弱性が検出された際にパイプラインを異常終了することは、コンテナイメージを脆弱なままリリースしないために重要なことです。しかし、現時点で対応する必要のない脆弱性や、対応する手段に乏しい脆弱性が検出されたときには、パイプラインの実行をそのまま継続したいことがあります。
.trivyignore ファイルに、改行区切りでCVE識別番号を記載することで、指定したCVE識別番号をもつ脆弱性がコンテナイメージに存在しても、無視させることが可能です。
また、現時点では対応できないが将来的に対応する必要がある脆弱性に対しては、expキーワードを用いて無視する期間を指定することが有効です。(1-21)
# 基本的な形式
CVE-2024-5171
# 特定の日になるまで脆弱性を無視させることもできる
CVE-2024-5171 exp:2024-09-10
実運用に組み込む際に考えること
CIに組み込むことで検査を強制する
ここまで、Cloud Buildなどで構築したCIに対してTrivyを組み込む方法を解説しました。しかし、CIにTrivyを組み込むことには、どのようなメリットが考えられるでしょうか。
仮にCIにTrivyを組み込まず、Trivyの実行を開発メンバー自身に委ねるとします。この場合、次のような可能性が存在します。
- Trivyのエラーの解消に時間がかかることを理由に、Trivyの指摘を無視したままリリースを行う。
- Trivyを実行する必要があるということを、開発メンバーが忘れたままコードをコミットする。
プロダクトをセキュアに保つという観点からは、このような可能性が存在することは望ましくありません。
Trivyの実行をCIに組み込み、チーム内で定めた基準を超過する脆弱性が見つかった場合にはパイプラインを異常終了させることで、これらの可能性を低減することができます。
ただし、検査を実施したイメージだけをデプロイできるようにするには、別の設定が必要です。その詳細は後述します。
開発スピードとのトレードオフ
コンテナイメージに含まれるミドルウェアなどがもつあらゆる脆弱性に対して、何らかの対策を実施するのが理想です。しかし現実には、そのような全面的な対応を取ることにより、開発からリリースまでの時間が大きく延びる可能性もあります。
この問題への対応策として、Trivyで表示される脆弱性の重大度やCVSSなどの尺度を用い、脆弱性への対応基準を定めることが考えられます。具体的には「重大度がCRITICAL の場合は、その脆弱性による影響を即時調査する」といった基準です。
対応基準を定めたあとは、Trivyのフラグや.trivyignore を用いて、対応基準に従った脆弱性対応が容易になるようTrivyを設定する必要があります。
検知された脆弱性がプロダクトに影響を与えるかを調査する
検出されたすべての脆弱性がプロダクトのセキュリティに影響を及ぼすとは限りません。たとえば、コンポーネントの機能のうち特定の機能のみに脆弱性が存在する場合、プロダクトがその機能を利用していなければ、実質的に脆弱性の影響を受けない可能性もあります。
したがって、開発スピードを損なわないためには、検出された脆弱性に対応しないという選択肢も検討する必要があります。この選択肢の妥当性を説明するには、Trivyがそれぞれの脆弱性に対して表示している参考リンクや備考を確認することが有効です。脆弱性がプロダクトに影響を及ぼさないことが確認できれば、脆弱性に対応しないという選択肢が妥当であるという根拠になります。
SASTで脆弱なアプリケーションコードを検出する
SASTとは何か
SAST(静的アプリケーションセキュリティテスト)は、ソースコードに含まれる脆弱性や、ベストプラクティスに従っていない実装を、ソースコードを解析することにより検出する手法です。(1-22) アプリケーションを実行することなく検査を実施できるため、小さいコストで実施できる手法といえます。
Banditについて
本記事では、GitHubで公開されているオープンソースなSASTツールであるBanditを検証します。Banditは、Pythonで記述されたソースコードに対してのみ実行することができます。 (1-23)
SASTで検出できるもの
SASTツールは、機密情報のハードコーディングやSQLインジェクションといった脆弱性を検出することができます。たとえばBanditでは、検出できる脆弱性の一覧がWikiにまとめられています。 (1-24)
また、Lintツールのようにコーディングルールへの違反を検出する用途にも使用できます。
ローカル環境で実行する
Trivyと同様に、BanditをDockerイメージとして利用することが可能です。
appのローカルリポジトリ内に含まれているPythonコードにBanditを適用するには、次のようなコマンドを実行します。
docker run --rm -v appローカルリポジトリのパス:/app/ ghcr.io/pycqa/bandit/bandit -r /app
実行結果には、次のような指摘が含まれていました。
今回は、secret_key(セッション情報の暗号化に用いられる秘密鍵)がハードコードされているのではないか、という指摘です。
Test results:
>> Issue: [B105:hardcoded_password_string] Possible hardcoded password: 'dev key'
Severity: Low Confidence: Medium
CWE: CWE-259 (https://cwe.mitre.org/data/definitions/259.html)
More Info: https://bandit.readthedocs.io/en/1.7.9/plugins/b105_hardcoded_password_string.html
Location: /app/assets/app.py:14:17
13 app = Flask(__name__)
14 app.secret_key = 'dev key'
15単純なビルドステップ
Cloud BuildでBanditを使用する場合、Trivyと同様、コミュニティ提供のビルダーを利用するのが簡単です。
そのため下記ドキュメントの手順を実行しますが、今回はbuilder-name をbanditとします。
ビルダーをビルドしたあと、appリポジトリのcloudbuild.yaml に、次のビルドステップを追加します。
# Banditによる検査
- name: 'gcr.io/$PROJECT_ID/bandit'
args: ['-r', '.']特定の行の検査をスキップする
後述するように、本来適切であるコードに対してもBanditが指摘を行うことがあります。そのような場合、特定の行の検査をBanditにスキップさせる方法が必要になることがあります。
Banditは、# nosec というコメントが記載された行の検査は行いません。この性質を利用すれば、明らかに適切と思われる行の検査はスキップできます。(1-25)
たとえば、先の例で指摘があった、assets/app.py の14行目をスキップさせるとします。この場合、次のように変更する必要があります。
- app.secret_key = 'dev key'
+ app.secret_key = 'dev key' # nosec
より堅牢な方法として、特定の種別の脆弱性検査のみをスキップさせることもできます。
今回指摘された脆弱性の種類は、「B105:hardcoded_password_string」でした。この種別名のうち「B105」という文字列を次のようにコメントに記載します。このようにすると、B105の指摘は行わずに、それ以外の脆弱性検査は通常通り実施するようBanditに指示することができます。
- app.secret_key = 'dev key'
+ app.secret_key = 'dev key' # nosec B105
検査をスキップする際には、必ずその意図をコメントすることが推奨されます。nosec で検査をスキップする場合、そのコードが安全であることの保証はコードのレビュアーが行うことになります。nosec を記載した意図もコメントすることで、レビューをスムーズに進めることができます。
- app.secret_key = 'dev key' # nosec B105
+ # (コードが安全である理由)のため無視する
+ app.secret_key = 'dev key' # nosec B105
実運用に組み込む際に考えること
適切なソースコードに対してもSASTツールが問題を指摘する可能性
ここまで、ソースコードに含まれる脆弱性を検出するツールとしてSASTツールを紹介しました。しかし実際には、SASTツールは「脆弱性が存在する可能性」のある箇所を指摘しているに過ぎません。したがって、SASTツールが指摘する箇所の中には、本来問題がないのに誤検知されている箇所が存在することもあります。
確実に誤検知であるといえる場合には、先に紹介したように、特定の行の検査をスキップするようSASTツールに指示することができます。
Binary Authorizationで検査済のイメージのみをデプロイさせる
Binary Authorizationとは何か
Binary Authorizationは、GKE(Google Kuberenetes Engine)やCloud Runに対して、信頼できるコンテナイメージのみをデプロイできるように制限するためのGoogle Cloudの機能です。 (1-26)
後述しますが、イメージの正当性の検証は、2024年8月時点ではイメージ署名を用いて行われています。
今回のサンプルでは、manifestリポジトリに記載されたDeploymentのimageを書き換えることでデプロイを行うことを想定しています。しかし、Binary Authorizationなどの制限を設けない場合、プロダクトに無関係なイメージや、CIでの検査を通過していないイメージをimageとして指定することも可能です。
さらに、悪意を持った内部者がkubectl コマンドなどを使って、直接任意のイメージをデプロイする可能性も考えられます。
本項では、Binary Authorizationの機能を用い、CIでの検査を通過したイメージのみがデプロイされるように設定を行います。
Binary Authorizationでのイメージ検証
Attestorが証明書を確認する
Binary Authorizationでは、デプロイされるイメージの正当性を検証する際、イメージに関連付けられた証明書を確認します。イメージに関連付けられた証明書を取得し、その内容を検証する役割を持つリソースは、認証者(Attestor)と呼ばれます。(1-27)
ビルド時に証明書を作成する
証明書はデフォルトで作成されるものではありません。たとえば、Cloud Buildのビルドステップなどを用いて明示的に作成する必要があります。 (1-28)
Cloud Buildで証明書を作成する
コミュニティー提供ビルダーのセットアップ
Cloud Build上で証明書作成を行うには、binauthz-attestation というコミュニティ提供ビルダーが必要です。
TrivyやBanditのときと同様に、https://cloud.google.com/build/docs/configuring-builds/use-community-and-custom-builders?hl=jaの方法でコミュニティ提供ビルダーをセットアップします。
builder-name はbinauthz-attestation とします。
ビルドステップの追加
Cloud Build上での証明書作成は、下記のように必要なリソースを指定するだけで実行できます。 (1-28)
# 証明書の作成
- id: 'create-attestation'
name: 'gcr.io/$PROJECT_ID/binauthz-attestation:latest'
args: [
'--artifact-url',
'asia-northeast1-docker.pkg.dev/$PROJECT_ID/$_REGISTRY_REPOSITORY/app:$COMMIT_SHA',
'--attestor',
'projects/$PROJECT_ID/attestors/$_ATTESTOR',
'--keyversion',
'projects/sreake-intern/locations/asia-northeast1/keyRings/$_KEY_RING/cryptoKeys/$_KEY/cryptoKeyVersions/$_KEY_VERSION'
]具体的な設定については、権限設定の手順などが複雑なため本記事では割愛します。
イメージの検証を有効にする
デプロイ時にイメージの検証を行うようにするには、次の設定を行う必要があります。
- GKEクラスタのBinary Authorization機能を有効にする (1-29)
- ポリシーを設定する(認証者によって検証されたイメージのみを許可することを推奨)
ポリシーについて
通常は、認証者が署名検証に成功した場合のみデプロイを許可するように設定することが多いのではないでしょうか。
このようなルールは、ポリシーと呼ばれる設定によって定義されます。ポリシーは、Google CloudコンソールのBinary Authorization画面から変更することができます。
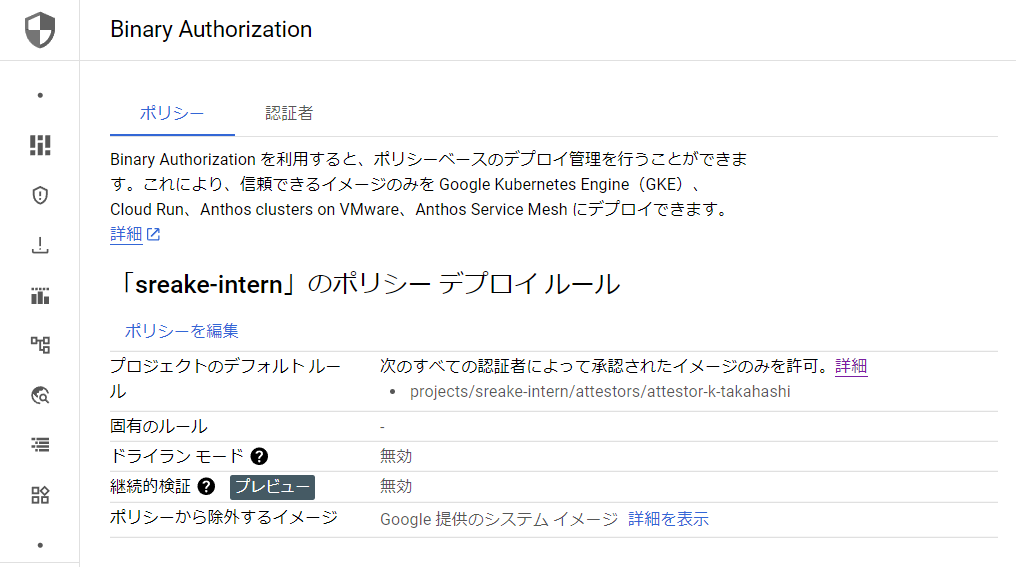
上記画像における「ポリシーを編集」ボタンを押すと、次のような画面が開きます。この画面で「証明書を要求」を選択した場合、特定の認証者が検証したイメージのみデプロイできるようになります。
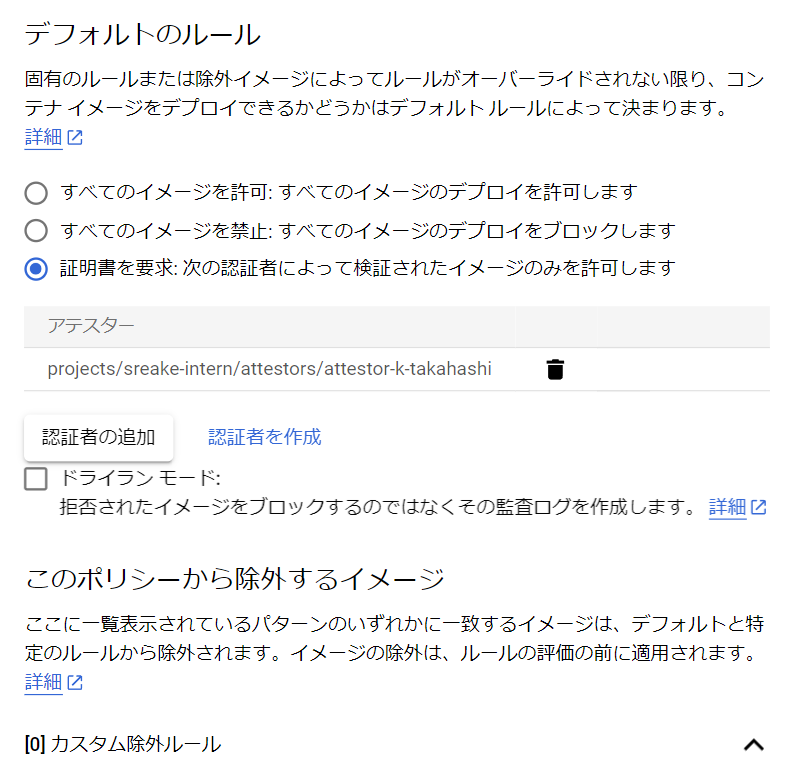
現在設定できるルールは、すべてのイメージを許可するか、禁止するか、証明書を用いた検証を行うのかという3つの選択肢に限られているため、実運用上は、証明書を用いた検証を設定することが多いと考えられます。
カスタム除外ルールを定義すると、特定のイメージや、Googleが提供するイメージに対する検査をスキップすることが可能です。
実際の動作例
本項では、デプロイ時に認証者によるイメージ検証が失敗したかどうかを確認する方法を説明します。
Google Cloudの「ログエクスプローラー」で次のクエリを実行すると、ポッドに対する操作ログのうち、ポリシー違反によって拒否されたものを抽出することができます。 (1-30)
resource.type="k8s_cluster"
logName:"cloudaudit.googleapis.com%2Factivity"
(protoPayload.methodName="io.k8s.core.v1.pods.create" OR
protoPayload.methodName="io.k8s.core.v1.pods.update")
protoPayload.response.status="Failure"
(protoPayload.response.reason="VIOLATES_POLICY" OR
protoPayload.response.reason="Forbidden")
NOT "istio-system"出力されたログのresponse.message を確認すると、次のようなログが表示されます。この内容を読むことで、どの認証者がどのイメージのデプロイを拒否したのかを確認することができます。なお、一部の値は便宜上マスクしています。
admission webhook "imagepolicywebhook.image-policy.k8s.io" denied the request: Image asia-northeast1-docker.pkg.dev/PROJECT_ID/REGISTRY_REPOSITORY/app@sha256:d8ad87faa988799f927cf39d3ded8de77226a9d62e7e5295ff41c54cc53c4706 denied by Binary Authorization cluster admission rule for asia-northeast1-a.summer-2024-k-takahashi-sample. Image asia-northeast1-docker.pkg.dev/PROJECT_ID/REGISTRY_REPOSITORY/app@sha256:d8ad87faa988799f927cf39d3ded8de77226a9d62e7e5295ff41c54cc53c4706 denied by attestor projects/PROJECT_ID/attestors/ATTESTOR: No attestations found that were valid and signed by a key trusted by the attestorCI / CDにおけるセキュリティ技術のまとめ
本記事では、CI / CDに実施できるセキュリティ対策を3つ紹介しました。
紹介したセキュリティ対策をまとめると、次のようになります。
- CI
- イメージのビルド前
BanditなどのSASTツールを利用することで、ソースコードの中から、脆弱性が存在する可能性のある箇所や、コーディングルールに違反している箇所などを検出することができます。
SASTツールは小さいコストで検査を実施できますが、誤検知が起こる可能性もあります。誤検知に対してはnosecコメントを付けることが有効な対策といえます。 - イメージのビルド後
ビルドしたイメージに含まれるミドルウェアなどに存在する既知脆弱性は、Trivyなどのスキャナツールを用いて検出することができます。
すべての既知脆弱性に今すぐ対応を行うのは現実的でない場合があります。また、検出された脆弱性が影響を及ぼさない場合もあります。脆弱性への対応基準をチーム内で策定し、.trivyignoreを設定することが有効です。 - SASTツールがソースコードを、Trivyがコンテナイメージを解析するように、解析ツールはそれぞれ解析する対象・範囲が異なります。
プロダクト全体の安全性を高めるには、解析範囲の異なるツールを組み合わせ、脆弱性検査を広い範囲に実施することが必要です。
- イメージのビルド前
- CD
- イメージのデプロイ
デプロイ時にイメージの正当性を検証しなければ、CIでの検査を通過していないイメージや任意の悪意あるイメージがデプロイされる可能性があります。そのため、検証済のイメージのみをデプロイできるよう制限するための仕組みが必要です。
Binary Authorizationなどのツールを用いると、検査完了時にイメージ署名を行うことで、署名の検証に成功したイメージ、すなわち検査済のイメージのみデプロイを許可することができます。
- イメージのデプロイ
ここまで、デプロイ以前の段階に適用できるセキュリティ施策を紹介しました。ここからは、実行中のコンテナに対して適用できる施策であるランタイムセキュリティ技術を紹介します。
ランタイムセキュリティについて
ランタイムセキュリティとは、カスタムのルールセットに基づいてコンテナの実行環境を監視し、ルールに違反するコンテナアクティビティを可視化および制御することで、セキュリティ上の脅威から保護するセキュリティ対策のことを指します。
ここからは、インターン生の竜が既存のアプリケーションの変更を加えずに、疑わしい挙動をリアルタイムで検知できるコンテナランタイムセキュリティツールについて紹介します。具体的には、後述するeBPFと呼ばれる技術を用いたツールであるTetragonとFalcoになります。
ランタイムセキュリティを支えるeBPFについて
eBPFとは、カーネルのソースコードを変更したりカーネルモジュールを開発せずとも、安全にカーネル内でプログラムを実行できる仕組みで、新しいカーネルの機能を素早く開発することができます。これにより、既存のアプリケーションを変更せずに以下のようなことが可能になります。
- ネットワークトラフィックの監視
- システムコールの追跡
- プロセスの監視
eBPFプログラムはカーネルにロードされ観測したいイベントにアタッチしたらすぐに、リアルタイムで監視を行うことができます。(2-2)
ここで、eBPFのコード例を見てみます。このサンプルには2つのコードが含まれています。
- カーネル空間で実行されるeBPFプログラム本体のコード(C言語)
- eBPFをカーネルにロードし、トレース結果を読み出すユーザ空間のコード(Python)
処理の流れとしては、まずeBPFプログラムをコンパイルしカーネルにロードします。そして、execveシステムコールをアタッチします。execveシステムコールが呼び出されたとき、つまりプロセスが新しいプログラムを起動するたびにhello関数が実行されます。
#! /usr/bin/python
from bcc import BPF
program = r"""
int hello(void *ctx) {
bpf_trace_printk("Hello, World!");
return 0;
}
"""
b = BPF(text=program)
syscall = b.get_syscall_fnname("execve")
b.attach_kprobe(event=syscall, fn_name="hello")
b.trace_print()以下はUbuntuのVM上で実行を行った結果を示します。2つのターミナルを用意し、1つのターミナルで上記のコードを実行します。そして、2つ目のターミナルで任意のLinuxコマンドを実行すると、同じタイミングで以下のようなトレース結果が出力されます。
(myenv) ubuntu@ubuntu2204:~/HelloWorld$ sudo /home/ubuntu/HelloWorld/myenv/bin/python3 hello.py
b' <...>-3561 [006] d...1 78598.967546: bpf_trace_printk: Hello, World!'
b' <...>-3563 [002] d...1 78599.053511: bpf_trace_printk: Hello, World!'
b' <...>-3564 [000] d...1 78599.054601: bpf_trace_printk: Hello, World!'
b' <...>-3564 [000] d...1 78599.058202: bpf_trace_printk: Hello, World!'
別ターミナルにおいてVM内で何かしらの操作を行ったタイミングでHello Worldが表示されているため、その操作を検知していることが確認できました。
今回紹介するTetragonやFalcoは、このようなeBPFの技術を用いてイベントを観測するコンテナランタイムセキュリティツールになります。
Tetragonについて
Tetragonとは?
Tetragonはカーネル内でeBPFプログラムを実行し、プロセスのイベントやシステムコール、ネットワークやファイルI/Oといったセキュリティ上重要な幅広いイベントを検知します。また、このようなイベントをポリシーに基づきフィルタリングする処理をユーザ空間に渡さずにカーネル空間内で行うため、イベントの検出だけでなくそのイベントを遮断するといったアクションを取ることができます。(2-3)
ここでは、Tetragonのアーキテクチャを確認し、疑わしいアクティビティを強制終了する仕組みを考察します。そして、実際にポリシーを適用し動作確認を行います。
アーキテクチャ
Tetragonは、Linuxのカーネル空間で動作します。カーネル空間にeBPFプログラムをロードすることで、様々なアクティビティをリアルタイムかつ低オーバーヘッドで監視することができます。カーネル内でポリシーに基づいたフィルタリングを行い、異常なセキュリティイベントを検出した際にユーザ空間のTetragonエージェントに処理を渡します。Tetragonエージェントはカーネル空間から送られたイベントデータを受信・解析し、必要に応じてGrafana等の外部のダッシュボードにデータを提供します。(2-4)
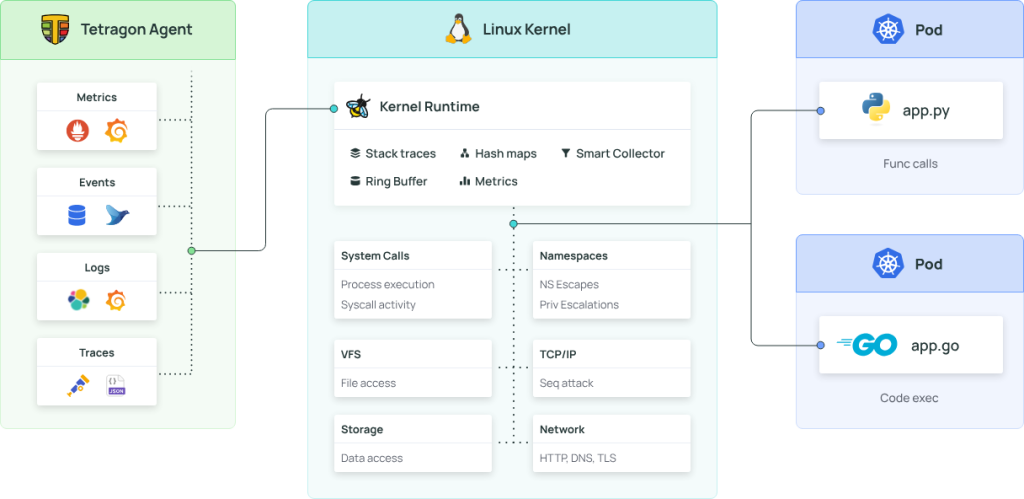
異常な挙動を強制終了する仕組み
先ほど、Tetragonがイベントの検出だけでなく遮断するといったアクションを取ることができる、と述べました。その仕組みについて簡単に説明しようと思います。
Tetragonは、2通りの方法でポリシーに対し異常と判定した挙動を強制終了させることができます。
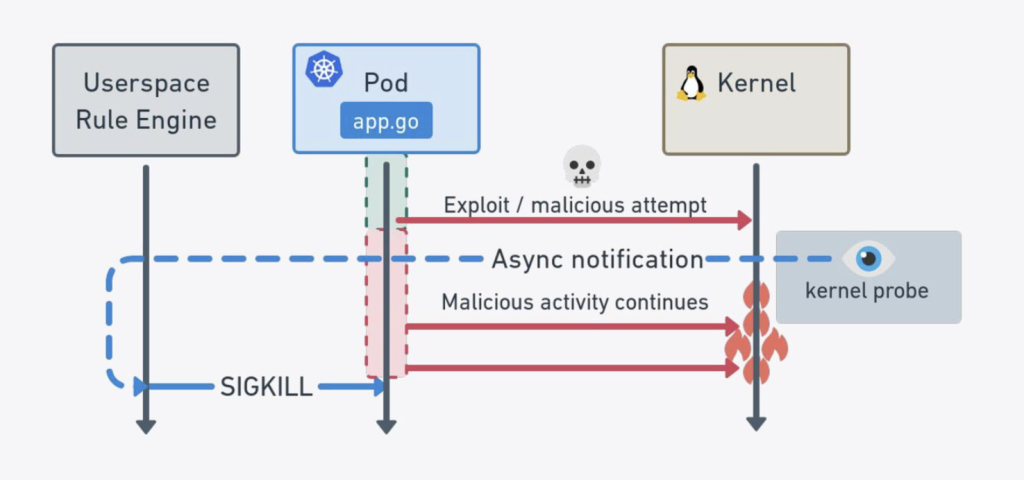
1つ目は、SIGKILLシグナルによるプロセスの強制終了です。
Tetragonはカーネル空間で動作するため、ポリシー外のイベントを検知した場合にカーネルからSIGKILLシグナルを送ることができます。以下の図が示すようにこの処理は同期的に発生していると言えるため、eBPFのコードがポリシー外と判定した動作が引き起こす攻撃を未然に防ぐことができます。
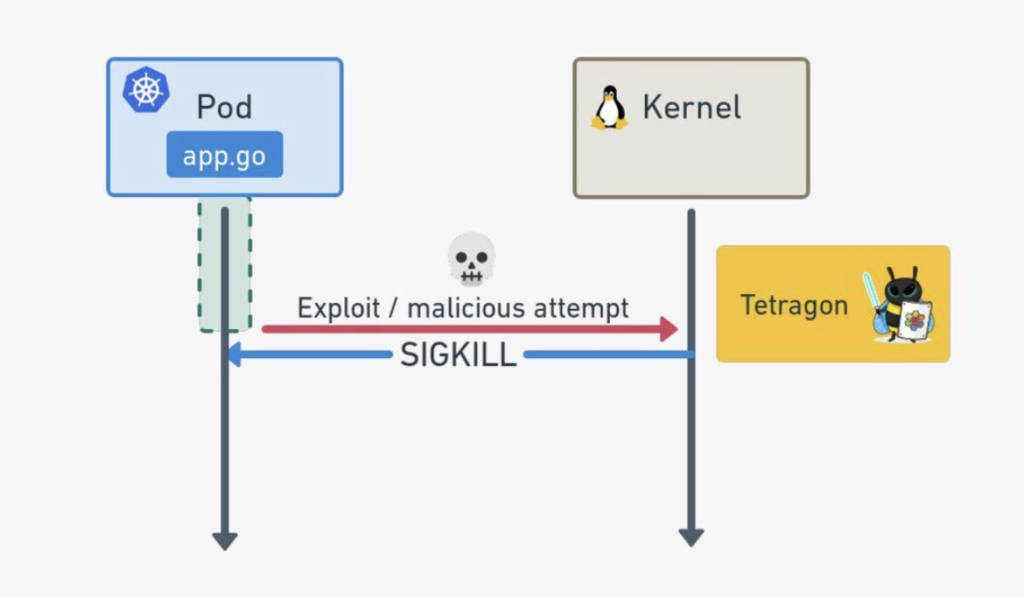
また、2つ目の方法としてはポリシー外のイベントの実行を防ぐために、特定の関数の戻り値をエラーコードに上書きすることでその関数の実行を防ぐという手法があります。これにより、システムコールがポリシーに違反する操作を試みた場合、その操作自体が行われずにエラーとして処理されます。
例えば、「本来は許可されていないファイルへの書き込み」を試みた場合、ファイルへの書き込み権限を確認するカーネル関数が呼び出されます。この関数の戻り値をエラーコードにすることで「ファイルアクセスを許可しない」という設定にできるため、書き込み操作が拒否されます。
このように、Tetragonは2通りの方法によりポリシーに対し異常な操作の強制終了を実現します。しかし、注意すべき点が一つ存在します。
例えば、write()システムコールに対しSIGKILLシグナルを送りプロセスを強制終了する場合、このシグナルが送られる前にデータの一部が書き込まれてしまっている可能性があり、書き込みが行われていないことを保証できません。したがって、実運用時にポリシー外のアクティビティを即時停止したい場合はシグナルを送るだけでなく戻り値の上書きを併用することが重要になります。(2-5)
Tetragonのインストール
実際にTetragonの動作確認を行うため、https://tetragon.io/docs/getting-started/install-k8s/ にしたがってインストールを進めます。
なお、Kubernetesの環境はGKEを利用しました。後述するFalcoの動作確認を行った環境も同様です。
TetragonはKubernetes環境ではDaemonSetとしてデプロイされ、クラスタ内の全てのノードにTetragonエージェントを展開し、イベントをリアルタイムで監視します。
helm repo add cilium https://helm.cilium.io
helm repo update
helm install tetragon ${EXTRA_HELM_FLAGS[@]} cilium/tetragon -n kube-system
kubectl rollout status -n kube-system ds/tetragon -wkube-system namespaceにおいてTetragonのDaemonsetができていることを確認します:
kubectl get ds -n kube-system tetragon
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
tetragon 1 1 1 1 1 <none> 10mここまでできれば準備は完了です。あとは、ポリシーを記述し反映すればTetragonがイベントの検出を行います。
Tetragonのポリシーについて
Tetragonでは、TracingPolicyを用いてKubernetesクラスタ内のLinuxカーネルで発生する任意のイベントをトレースします。
その際、kprobes, tracepoints, uprobesの3つのフックポイントがあります。フックポイントとはカーネル上でイベントが発生した際それを検知するトリガーです。トレースされたイベントは、ポリシー内のSelectorsフィールドに定義したルールと照合され、指定した条件と一致するか否かが判定されます。そして、条件と一致した場合にはログを残しアラートを出す、という流れになります。(2-6)
3つのフックポイントについて整理します。(2-7)
- kprobes: 任意のカーネル関数やシステムコールを動的にフックしてeBPFコードを実行し検知を行います。ただし、カーネル関数がバージョン間で変更される可能性があるため、カーネルのバージョンに依存する場合があります。
- tracepoints: Linux カーネルに予め定義された静的なフックポイントで、検知を行うための設定です。異なるバージョンのカーネル間でも安定しているという特徴があります。
- uprobes: ユーザ空間の関数を動的にフックします。
なお、今回反映を行って動作検証を行うポリシー例はkprobesを使用したものになります。
Tetragonでポリシーを適用する例
Tetragonでポリシーを適用する例として、以下の検証を行います。
- クラスタ外へのHTTPリクエストの検知および遮断
- 特定のディレクトリ配下のファイルへの書き込みの検知および遮断
外部ネットワーク接続の検知および遮断
クラスタ外部への接続のみを検知するため、クラスタ内部のPodとServiceのCIDR範囲内へのアクセスは除外するようにします。まず、それぞれのCIDRブロックを取得します。
なお、実行時はシングルノードの環境で動作確認を行いましたが、マルチノードの場合は複数のCIDRブロックを取得するため下記コマンドをそのまま実行してもポリシーに反映されない可能性があります。
export PODCIDR=`kubectl get nodes -o jsonpath='{.items[*].spec.podCIDR}'`
export SERVICECIDR=$(gcloud container clusters describe ${NAME} --zone ${ZONE} | awk '/servicesIpv4CidrBlock/ { print $2; }')ここでは、以下のようなポリシーとします。各フィールドについて説明します。(2-8)
kprobesフィールドによりTCP接続が確立される際に呼び出されるカーネル関数であるtcp_connectを監視対象としてフックしています。
syscall: false の部分でtcp_connectがシステムコールではなくカーネル関数であることが示されます。
argsフィールドで関数の引数が指定されます。
selectorsフィールドでは検知したいイベント(ここでは、宛先アドレスがローカルループバックアドレスやクラスタ内のCIDR範囲内ではないということ)のルールを記述します。
apiVersion: cilium.io/v1alpha1
kind: TracingPolicy
metadata:
name: "monitor-network-activity-outside-cluster-cidr-range"
spec:
kprobes:
- call: "tcp_connect"
syscall: false
args:
- index: 0
type: "sock"
selectors:
- matchArgs:
- index: 0
operator: "NotDAddr"
values:
- 127.0.0.1
- ${PODCIDR}
- ${SERVICECIDR}上記のポリシーを、tetragon_network.yamlとしてapplyします:
kubectl apply -f tetragon_network.yaml
そして、テスト用のPod上で様々なIPアドレスに対しwgetコマンドを実行し実験を行い、コマンドの実行と同時に別ターミナルでログを確認します。
除外対象のIPアドレスである127.0.0.1に対してはconnectイベントが表示されませんが、クラスタ外部のIPアドレスである8.8.8.8に対してはconnectイベントが表示されていることが確認できます。よって、反映したポリシーが機能しクラスタ外部への接続を検知できていることがわかります。
kubectl logs -n kube-system -l app.kubernetes.io/name=tetragon -c export-stdout -f | tetra getevents --namespace default -o compact
🚀 process default/test /bin/wget 127.0.0.1
💥 exit default/test /bin/wget 127.0.0.1
🚀 process default/test /bin/wget 8.8.8.8
🔌 connect default/test /bin/wget tcp 172.17.0.17:34814 ->8.8.8.8:80
💥 exit default/test /bin/wget 8.8.8.8 SIGINT なお、条件と一致するイベントを検知した際にそのイベントをトリガーしたプロセスを強制終了させることができます。そのためには、selectorsの最後に以下の設定を追加します。(2-9)
matchActions:
- action: Sigkill
このポリシーを反映し、再度同じようにして実験を行いログを確認します。
すると、先ほどのログとは異なり8.8.8.8に対してwgetコマンドを実行すると即座にSIGKILLシグナルがプロセスを強制終了していることがわかります
kubectl logs -n kube-system -l app.kubernetes.io/name=tetragon -c export-stdout -f | tetra getevents --namespace default -o compact
🚀 process default/test /bin/wget 127.0.0.1
💥 exit default/test /bin/wget 127.0.0.1 1
🚀 process default/test /bin/wget 8.8.8.8
🔌 connect default/test /bin/wget tcp 172.17.0.17:40866 -> 8.8.8.8:80
💥 exit default/test /bin/wget 8.8.8.8 SIGKILL
なお、イベントを遮断するもう一つの方法である、関数の戻り値をエラーコードに上書きする場合、selectorsの末尾に以下の設定を追加します。(2-10)
matchActions:
- action: Override
argError: -1
なお、カーネル関数の戻り値を上書きするにはカーネルが CONFIG_BPF_KPROBE_OVERRIDE オプションでコンパイルされていることが前提となるので注意が必要です。
ファイルアクセスの検知および遮断
次に、/etc/配下の任意のファイルに対する書き込みを検知するポリシーを反映して動作確認を行います。
前提として、外部からファイルの変更を検知する方法は複数考えられます。ここでは3つのカーネル関数を用いた方法に焦点を当てています。(2-11)
まず、security_file_permissionというカーネル関数を用いて/etc/配下にあるファイルに対して書き込み権限が与えられたか否かを判定します。戻り値が0であれば書き込みが許可されています。
また、security_mmap_file関数を用いて、メモリマッピングを通じてファイルに書き込みが行われたか否かを判定します。
最後に、security_path_truncate関数を用いて、ファイルサイズを変更することで間接的にファイルの内容を変更するtruncateシステムコールによるアクティビティをキャッチします。
これらのカーネル関数を組み合わせる形でファイルへの書き込みを検知するポリシーを作成します。ここでのポリシーはTetragon公式が用意しているものを使用します:
https://github.com/cilium/tetragon/blob/main/examples/quickstart/file_monitoring.yaml
このポリシーを、tetragon_fileaccess.yamlとしてapplyします。
kubectl apply -f tetragon_fileaccess.yaml
テスト用のPodの中で/etc/配下のファイルに対し書き込み操作を行います。そして、Tetragonがそれを検知しログを表示させるか実験してみます。
実験のため、以下のように/etc/配下での書き込みと/tmp/配下での書き込みを行います。
kubectl exec -it test -- /bin/sh
/ # ls
bin etc lib proc sys usr
dev home lib64 root tmp var
/ # cd etc
/etc # vi a < 書き込みを行う(aaa)
/etc # cat a
aaa
/etc # cd ../tmp
/tmp # vi b < 書き込みを行う(bbb)
/tmp # cat b
bbb
同時に新たなターミナルを開いて書き込み時のログを確認します。(一部省略しています)
その結果、/etc/配下への書き込みではwriteイベントが表示されていますが/tmp/配下への書き込みにはそのようなイベントが検出されていません。
このことから、Tetragonを用いることで特定のファイルやディレクトリへの書き込みを検知できることが確認できます。
kubectl logs -n kube-system -l app.kubernetes.io/name=tetragon -c export-stdout -f | tetra getevents --namespace default -o compact
🚀 process default/test /bin/sh
🚀 process default/test /bin/vi a
📝 write default/test /bin/vi /etc/a
📝 write default/test /bin/vi /etc/a
📝 truncate default/test /bin/vi /etc/a
💥 exit default/test /bin/vi a 0
🚀 process default/test /bin/vi b
💥 exit default/test /bin/vi b 0
なお、ポリシー外のアクティビティをトリガーするプロセスを終了させる設定を追加したポリシー: https://raw.githubusercontent.com/cilium/tetragon/main/examples/quickstart/file_monitoring_enforce.yaml
を反映した際、以下のようにviエディタで書き込みを行おうとした瞬間に強制終了されることが確認できました。
/ # cd etc
< aに書き込みを行おうとviエディタを立ち上げた
~
:wqKilled
このように、Tetragonを用いることで特定のディレクトリ配下への書き込みの検知と遮断を行うことができました。
Falcoについて
Falcoとは?
Falcoはクラウドネイティブなランタイムセキュリティツールです。カーネル空間で動作するeBPFプログラムによりリアルタイムでシステムコールイベントを収集し、設定したカスタムルールに基づいて異常なアクティビティを検知します。元々はSysdigによって作られ、現在はCNCFのプロジェクトとして様々な組織で実運用されています。
具体的には、特権コンテナの使用や重要なディレクトリへの読み取り/書き込み操作、sshバイナリの実行など、多岐にわたるアクティビティをシステムコールを通じて監視することができます。(2-12)
また、後述するFalcosideKickという機能を使うことでイベントのログを外部のアプリケーション(slack等)に簡単に転送することができます。
このように、Falcoを用いることでTetragonと同様にランタイムセキュリティを強化することができ、コンテナ内の活動を可視化し異常な動作を検出することができます。
ここでは、Falcoのアーキテクチャの概要を説明しつつTetragonとは異なる点としてプロセスの強制終了ができない理由を考察します。そして、ルールを実際に適用して動作確認を行いたいと思います。
アーキテクチャ
Falcoは、Tetragonとは異なり、カーネル空間ではなくユーザ空間でイベントの解析を行います。また、Falcoは主にシステムコールをベースとした監視を行い、カーネル空間で収集したシステムコールイベントと設定されたルールに基づいて異常な挙動を検出する機能を提供します。なお、Tetragonのように異常なプロセスを停止することはできません。この理由は後述します。
以下に、具体的なアーキテクチャを示します。
カーネル空間ではカーネルモジュールまたはeBPFモジュールがドライバとして動作し、システムコールのデータを収集します。カーネルモジュールはわずかにパフォーマンスが良く、eBPFモジュールはより安全性が高いですが、機能としては同じです。収集されたシステムコールのデータはFalcoライブラリのコンポーネントであるlibscapに渡され、コンテキスト情報の付加等が行われます。
次に、そのデータをlibsinspというコンポーネントに渡し、イベントの解析と検査を行います。そして、ルールエンジンにおいて、処理されたイベントとFalcoの利用者が作成したルールとの照合を行い、発生したイベントが異常か否かを判定します。異常であると判定された場合、Falcoを通じてアラートを出します。(2-13,2-14)
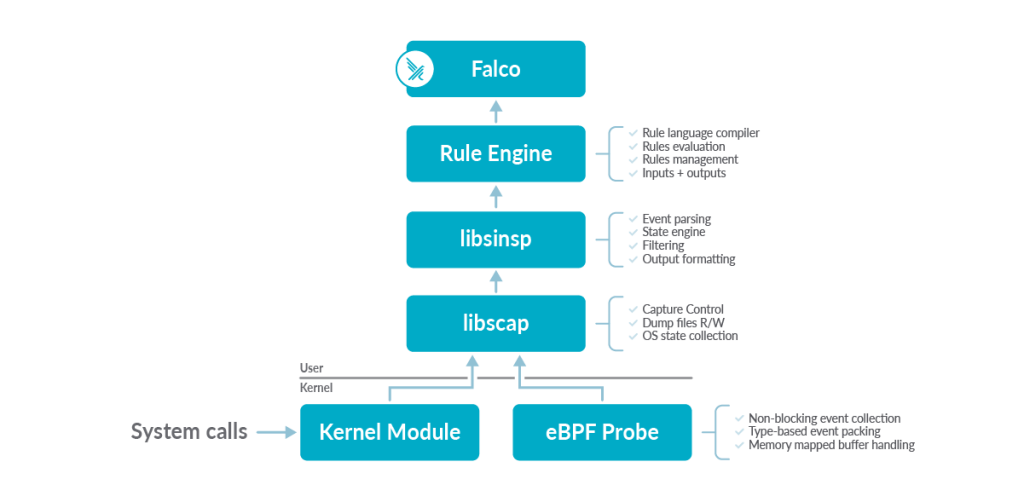
異常な挙動を強制終了ができない理由
「アーキテクチャ」の部分でも説明しましたが、Falcoはカーネル空間で収集したsyscallデータをユーザ空間に渡して処理します。従って、悪意のあるプロセスの強制終了を行うにはユーザ空間で動いているアプリケーションがアクションを取る必要がありますが、カーネル空間からユーザ空間への通知は非同期処理です。したがって、この場合プロセスの強制終了を実行したタイミングは、既に悪意のあるユーザがデータを抜き取り終わった後となってしまう可能性があります。(2-15)
そのため、カーネル空間で動作しているTetragonのeBPFコードは同期的にSIGKILLシグナルを送ってプロセスを強制終了できるのに対しFalcoにはそのような機能がないのです。
FalcoのインストールとFalcosideKickの有効化
Falcoでは、FalcosideKickという機能を用いることでログを簡単にslack等の外部アプリケーションに転送することができます。(2-16)ここでは、slackに転送する準備を行います。
後ほどネットワーク外部接続の検知とファイルアクセスの検知を行うので、その時のログをslackで確認するための準備を行いたいと思います。
その際、slack appにて設定を行いwebhookのURLを取得する必要がありますが、そのやり方については本ブログの趣旨から外れるので割愛します。
helmを用いてFalcoをクラスタにインストールし、オプションのFalcosideKickを有効にします。
https://falco.org/blog/extend-falco-outputs-with-falcosidekick/ を参考にして進めます。
helm repo add falcosecurity https://falcosecurity.github.io/charts
helm repo update
kubectl create namespace falco
helm repo add falcosecurity https://falcosecurity.github.io/charts
helm install falco falcosecurity/falco \
--set falcosidekick.enabled=true \
--set falcosidekick.webui.enabled=true \
--set falcosidekick.config.slack.webhookurl="https://hooks.slack.com/services/XXX" \
-n falco FalcosideKickとFalcoのpodが動いているかどうか確認します。
kubectl get pods -n falco
NAME READY STATUS RESTARTS AGE
falco-falcosidekick-849d56cd67-nx9ns 1/1 Running 0 97s
falco-falcosidekick-849d56cd67-p5zkd 1/1 Running 0 97s
falco-falcosidekick-ui-649dcd86bc-5fwkt 1/1 Running 0 97s
falco-falcosidekick-ui-649dcd86bc-prfvv 1/1 Running 0 97s
falco-falcosidekick-ui-redis-0 1/1 Running 0 97s
falco-sg9gd 2/2 Running 0 84sこれで準備ができました。
Falcoのルールについて
Falcoが受け取ったシステムコールイベントは、後ほど詳しく確認しますが、condition というフィールドにおいて記述したルールと適合しているかチェックされ、適合していればそのルールを検出するという流れになります。なお、厳密にはシステムコールイベントだけでなく、トレースポイントイベントやメタイベント、プラグインイベントもサポートしています。(2-17)
Falcoでルールを適用する例
以下に、Falcoでルールを適用する例として、Tetragonの項目でも行ったように以下の検証を行います。
- クラスタ外へのHTTPリクエストの検知に関する検証
- 特定のディレクトリ配下のファイルへの書き込みの検知に関する検証
その際に、アラートはslackに転送し確認します。
外部ネットワーク接続の検知
外部ネットワーク接続を検知するカスタムルールの記述について確認する前に、Falcoにおいてルールを記述する上で必須となるキーについて簡単に紹介したいと思います。
Falcoのルールは複数のキーから構成され、以下が必須要素になります。(2-18)
rule: ルール名condition: システムコールをベースとして、受け取ったイベントがルールにマッチするかどうかを複数のboolean演算を組み合わせることで判定する条件式です。この部分の記述により検知したいアクティビティが決定します。サポートされている記述は以下のドキュメントの通りです: https://falco.org/docs/reference/rules/supported-fields/desc: ルールに関するより詳細な説明output:conditionで指定したイベントを検知した場合に出力するメッセージを指定します。priority: イベントの重要度を表現します。以下のうちのどれかである必要があります: (emergency, alert, critical, error, warning, notice, informational, debug)
また、condition キーにおけるルールの記述をシンプルにするためにmacroを使うことができます。(2-19)
ここでは、2つのマクロを組み合わせる形でconditionを作成します。
- outboundというマクロにより、システム上でconnectシステムコールを使用しIPv4またはIPv6によりリモートホストへの接続が確立されようとしている瞬間のイベントをキャプチャします。
- allowed_outbound_destination_networksというマクロにより、クラスタ外部への接続のみ追跡するようにします。その際、クラスタ外部への接続のみを監視対象としたいため、Tetragonで外部への接続検知時に取得したPodとServiceのCIDRを使用します。
他にも必須のキーを記述し、出来上がったルールの例は以下のようになります。
customRules:
custom-rules.yaml: |-
- macro: outbound
condition: syscall.type=connect and evt.dir=< and (fd.typechar=4 or fd.typechar=6)
- macro: allowed_outbound_destination_networks
condition: ((fd.net=127.0.0.0/8) or (fd.net=172.17.1.0/24) or (fd.net=172.16.0.0/16))
- rule: Detect outbound connections outside allowed networks
condition: outbound and not allowed_outbound_destination_networks
output: Outbound connection to a disallowed network (command=%proc.cmdline, connection=%fd.name)
priority: WARNING
desc: >
This rule detects outbound connections that are not in the allowed networks上記で定義したルールをfalco_network.yamlとして反映します。
helm upgrade falco falcosecurity/falco \
--namespace falco \
--set falcosidekick.enabled=true \
--set falcosidekick.webui.enabled=true \
--set falcosidekick.config.slack.webhookurl="https://hooks.slack.com/services/XXX" \
-f falco_network.yamlテスト用のPodを作成し、実際に外部へとネットワーク接続を行いログをアラートとして検出できるかを試してみます。ここでは、クラスタ外部のIPアドレス1.1.1.1に対しHTTPリクエストを送ってみます。
kubectl run test --image=busybox -- sleep 3600
kubectl exec -it test -- /bin/sh
/ #
/ # wget 1.1.1.1上記コマンドを実行した直後、slackを確認すると以下のようにアラートが出ていることが確認できました。つまり、Falcoがクラスタ外部への接続を検知し、かつログの転送ができていることになります。
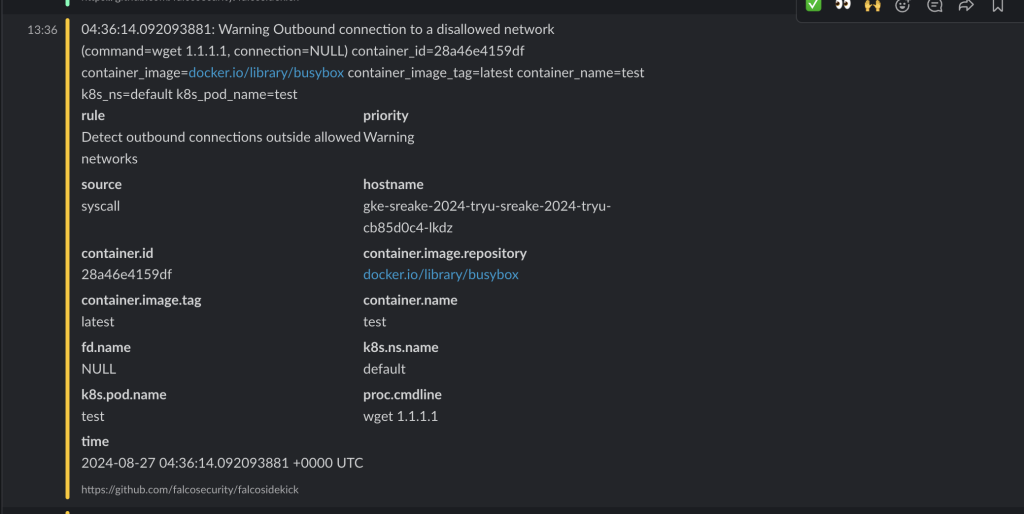
補足:
ここで、helm upgradeにより独自のルールを反映しましたが、内部で何が起きているかを簡単に確認してみます。
まず、先ほど実行したhelm upgradeにより独自ルールのyamlをもとにConfigMapが生成されます。
kubectl get configmap -n falco
NAME DATA AGE
falco 1 2m13s
falco-custom-rules 1 2d20h
falco-falcoctl 1 2m13s
falco-rules 1 31s
kube-root-ca.crt 1 7d20h
このConfigMapの中身を確認してみます。helm upgradeにより反映した外部ネットワークへの接続を検出するカスタムルールの内容が格納されていることがわかります。
kubectl get configmap falco-rules -n falco -o yaml
apiVersion: v1
data:
custom-rules.yaml: "- macro: outbound\n condition: syscall.type=connect and evt.dir=<
and (fd.typechar=4 or fd.typechar=6)\n \n- macro: allowed_outbound_destination_networks\n
\ condition: ((fd.net=127.0.0.0/8) or (fd.net=172.17.1.0/24) or (fd.net=172.16.0.0/16))\n\n-
rule: Detect outbound connections outside allowed networks\n condition: outbound
and not allowed_outbound_destination_networks\n output: Outbound connection to
a disallowed network (command=%proc.cmdline, connection=%fd.name)\n priority:
WARNING\n desc: >\n This rule detects outbound connections that are not in
the allowed networks"
kind: ConfigMap
metadata:
annotations:
meta.helm.sh/release-name: falco
meta.helm.sh/release-namespace: falco
creationTimestamp: "2024-08-28T06:25:29Z"
labels:
app.kubernetes.io/instance: falco
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: falco
app.kubernetes.io/version: 0.38.2
helm.sh/chart: falco-4.8.0
name: falco-rules
namespace: falco
resourceVersion: "7057073"
uid: 445c7dbf-2e63-4e1a-ac1b-ea80855c1f34生成されたConfigMapはFalcoのPodにマウントされますが、以下のように、実際にルールがマウントされていることが確認できます。このPodがイベントとルールの照合を行い、定義されたルール外のイベントを検知します。
kubectl exec -it falco-mg8mv -n falco -- /bin/sh
Defaulted container "falco" out of: falco, falcoctl-artifact-follow, falco-driver-loader (init), falcoctl-artifact-install (init)
# cd etc/falco
# ls
falco.yaml falco_rules.yaml rules.d
# cd rules.d
# ls
custom-rules.yaml
# cat custom-rules.yaml
- macro: outbound
condition: syscall.type=connect and evt.dir=< and (fd.typechar=4 or fd.typechar=6)
- macro: allowed_outbound_destination_networks
condition: ((fd.net=127.0.0.0/8) or (fd.net=172.17.1.0/24) or (fd.net=172.16.0.0/16))
- rule: Detect outbound connections outside allowed networks
condition: outbound and not allowed_outbound_destination_networks
output: Outbound connection to a disallowed network (command=%proc.cmdline, connection=%fd.name)
priority: WARNING
desc: >
This rule detects outbound connections that are not in the allowed networks# ファイルアクセスの検知
ファイルが書き込みモードで開かれ、そのファイルが/etc/ディレクトリ配下にある場合、警告を発するような条件を作成します。(2-20)
customRules:
custom-rules.yaml: |-
- rule: Write below etc
desc: An attempt to write to /etc directory
condition: >
(evt.type in (open,openat,openat2) and evt.is_open_write=true and fd.typechar='f' and fd.num>=0)
and fd.name startswith /etc
output: "File below /etc opened for writing (file=%fd.name pcmdline=%proc.pcmdline gparent=%proc.aname[2] ggparent=%proc.aname[3] gggparent=%proc.aname[4] evt_type=%evt.type user=%user.name user_uid=%user.uid user_loginuid=%user.loginuid process=%proc.name proc_exepath=%proc.exepath parent=%proc.pname command=%proc.cmdline terminal=%proc.tty %container.info)"
priority: WARNING
tags: [filesystem, mitre_persistence]
このルールを先ほどと同じように反映し、テスト用のPodにおいて/etc/配下にファイルに対し書き込みを行ってみます。
kubectl exec -it test -- /bin/sh
/ #
/ # echo "test" > /etc/testfile
この書き込みを行ったタイミングでslackを確認すると、以下のようにアラートとログの詳細が出ていることがわかります。
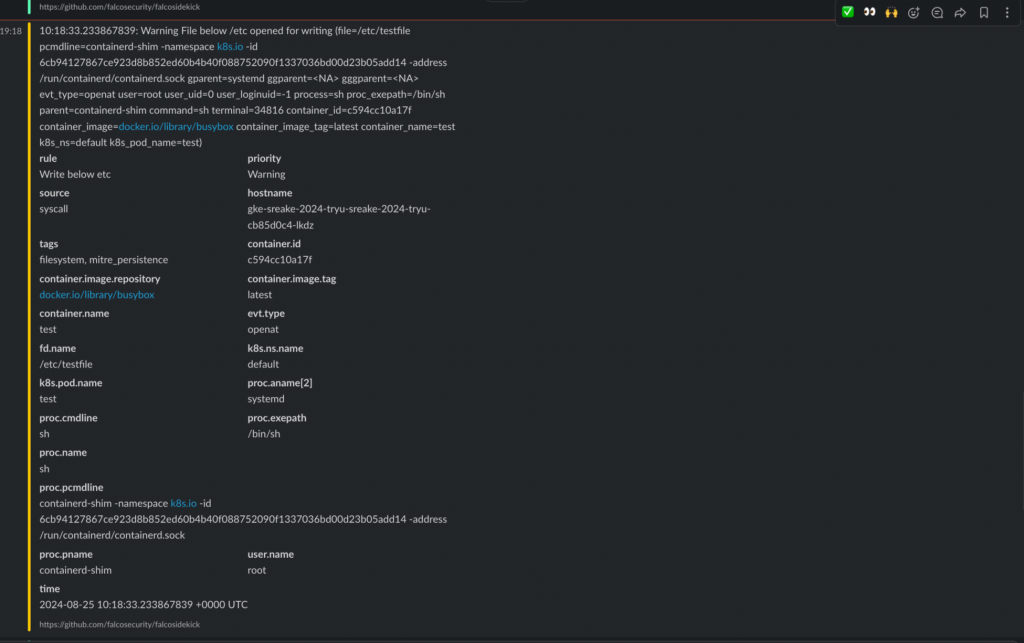
ちなみに、ルールにおいてpriorityをERRORとすると黄色だった線が赤になります。
ここまでで、Falcoを用いたルールの適用と動作確認を行うことができました。
まとめ・実際のユースケースについて
TetragonとFalcoのアーキテクチャを確認し、実際のポリシーの記述および反映、ポリシー外のイベントの検知を行いました。最後に、それぞれのユースケースについて比較を行いたいと思います。
Tetragonはカーネル空間内でイベントの収集と解析を行うことで、システムコールやプロセス、ネットワークなど多岐に渡るイベントを監視・検知することができます。また、検知するだけでなく不審なイベントを遮断する機能も備わっていることを実際に確認しました。
それだけではなく、Tetragonはセキュリティのオブザーバビリティを向上させることができます。
以下の図はcilium enterprise限定になりますが、TetragonとCilium Hubbleを組み合わせることでプロセスとネットワーク接続の情報を結びつけて可視化したものです。
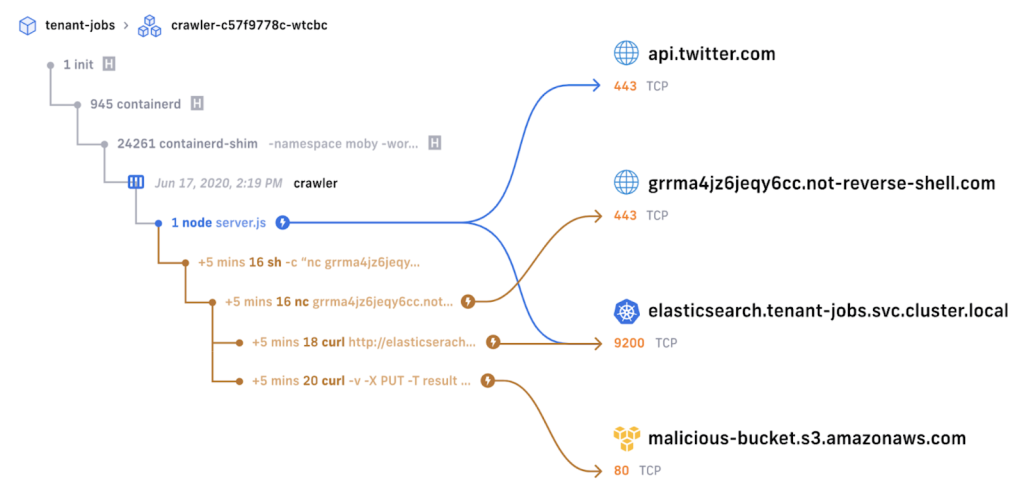
このようにして、Tetragonを用いることでセキュリティのオブザーバビリティを向上させることができます。
一方、Falcoはシステムコールの監視を行うことができ、セキュリティ上の脅威を検知しFalcosideKickによりアラートを様々な外部のアプリケーションと容易に連携し転送することができます。
また、先ほどの動作確認にはカスタムルールを作成しましたが、Falcoには公式が提供しているデフォルトのルールセットが存在します。Helmチャートで、導入したいデフォルトのルールを参照する形で反映することができるため、 自前でポリシーを用意する必要のあるTetragonよりも運用コストが低いと言えます。
簡単にまとめを行うと、セキュリティ上疑わしいイベントを検知しそれをslack等で確認するようなシステムを短時間で作りたい場合、Falcoで十分です。その上で、リアルタイムで疑わしいイベントを遮断したりネットワークとプロセスのイベントを融合し可視化したいといった要望があればTetragonを使うのが良いのかなと思います。ただ、TetragonにはFalcosideKickのような機能はないので、ログを外部のアプリケーションに転送したい場合は、アラートログのエクスポート(loki,fluentd等を用いる)と発報(grafana等)のコンポーネントを別途デプロイする必要があります。
感想と今後の展望
高橋
わたしは、CI / CDに関するセキュリティ技術の調査を行いました。はじめはIAMの設定方法も理解しておらず、とくにBinary Authorizationはさまざまなリソースが必要になるため、準備に時間がかかりました。しかし、長い時間コンソール画面に触れたことで、各種概念に対する理解を深めることができたという側面もあり、結果的には良かったと感じております。
また、実運用に組み込む際に考えなければならないことについては、メンターの方と様々な議論を交わし、内容を深めることができたと感じています。この場をお借りして感謝申し上げます。
今後は、Kubernetesの各種コンポーネントや、クラウドネイティブ領域のセキュリティ技術を実践的に活用することで、今回のインターンで得られた知識をより幅広いものにしていくことを目指します。
竜
今回は、eBPFを用いたコンテナランタイムセキュリティツールであるTetragonとFalcoについて調査を行いました。初めはeBPFもよく知らず、コンテナランタイムセキュリティツールに関する知識は乏しかったですが、公式ドキュメントを読み込み実際に動作確認等を行っていくうちに、それぞれの仕組みを理解していくことができました。また、メンターの方々の丁寧なサポートもあり様々な知見を得ることができました。
この機会をきっかけにして他のセキュリティ技術や、eBPFを用いた技術に興味を持ったので自ら深堀りを行い知見を広げていければと思います。
参考資料
高橋
- (1-1) https://www.linuxfoundation.jp/blog/2024/04/japanese-version-state-of-cicd-2024/
- (1-2) https://owasp.org/www-project-top-10-ci-cd-security-risks/
- (1-3) https://www.digital.go.jp/assets/contents/node/basic_page/field_ref_resources/504c3218-1eb0-4287-ba16-01641fdc038c/d377749c/20240329_policies_development_management_outline_08.pdf
- (1-4) https://circleci.com/ja/blog/what-is-ci-cd/#cicd-とは
- (1-5) https://docs.github.com/ja/actions/about-github-actions/understanding-github-actions
- (1-6) https://cloud.google.com/build/docs/deploying-builds/deploy-gke?hl=ja
- (1-7) https://cloud.google.com/build?hl=ja
- (1-8) https://hub.docker.com/_/python
- (1-9) https://kubernetes.io/ja/docs/concepts/workloads/controllers/deployment/#creating-a-deployment
- (1-10) https://cloud.google.com/kubernetes-engine/docs/how-to/exposing-apps?hl=ja#creating_a_service_of_type_loadbalancer
- (1-11) https://cloud.google.com/build/docs/automating-builds/github/connect-repo-github?hl=ja
- (1-12) https://www.ipa.go.jp/security/vuln/scap/cve.html (1-13) https://trivy.dev/
- (1-14) https://aquasecurity.github.io/trivy/v0.54/docs/coverage/os/#supported-os
- (1-15) https://aquasecurity.github.io/trivy/v0.54/getting-started/installation/#install-from-github-release-official
- (1-16) https://aquasecurity.github.io/trivy/v0.54/docs/scanner/vulnerability/#severity-selection
- (1-17) https://aquasecurity.github.io/trivy/v0.54/docs/configuration/reporting/#file
- (1-18) https://cloud.google.com/build/docs/building/store-artifacts-in-cloud-storage?hl=ja
- (1-19) https://aquasecurity.github.io/trivy/v0.54/docs/configuration/filtering/
- (1-20) https://aquasecurity.github.io/trivy/v0.54/docs/configuration/others/#exit-code
- (1-21) https://aquasecurity.github.io/trivy/v0.54/docs/configuration/filtering/#trivyignore
- (1-22) https://snyk.io/jp/learn/application-security/static-application-security-testing/
- (1-23) https://github.com/PyCQA/bandit
- (1-24) https://bandit.readthedocs.io/en/latest/plugins/index.html#complete-test-plugin-listing
- (1-25) https://bandit.readthedocs.io/en/latest/config.html#suppressing-individual-lines
- (1-26) https://cloud.google.com/binary-authorization?hl=ja
- (1-27) https://cloud.google.com/binary-authorization/docs/key-concepts?hl=ja#attestations
- (1-28) https://cloud.google.com/binary-authorization/docs/cloud-build?hl=ja
- (1-29) https://cloud.google.com/binary-authorization/docs/deploying-containers?hl=ja#before_you_begin
- (1-30) https://cloud.google.com/binary-authorization/docs/viewing-audit-logs?hl=ja#query_for_blocked_deployment_events
竜
- (2-1) https://falco.org/about/
- (2-2) 入門eBPF(オライリー) Liz Rice著 武内 覚、近藤 宇智朗 訳 p1-20
- (2-3) https://tetragon.io/docs/overview/
- (2-4) https://isovalent.com/blog/post/tetragon-release-10/
- (2-5) https://tetragon.io/docs/concepts/enforcement/
- (2-6) https://tetragon.io/docs/concepts/tracing-policy/
- (2-7) https://tetragon.io/docs/concepts/tracing-policy/hooks/
- (2-8) https://tetragon.io/docs/concepts/tracing-policy/example/
- (2-9) https://tetragon.io/docs/getting-started/enforcement/
- (2-10) https://tetragon.io/docs/concepts/tracing-policy/selectors/#override-action
- (2-11) https://www.kernel.org/doc/html/latest/core-api/kernel-api.html
- (2-12) https://falco.org/docs/
- (2-13) https://falco.org/docs/event-sources/kernel/architecture/
- (2-14) https://falco.org/blog/falco-monitoring-new-syscalls/
- (2-15) 入門eBPF(オライリー) Liz Rice著 武内 覚、近藤 宇智朗 訳 p172-173
- (2-16) https://falco.org/blog/extend-falco-outputs-with-falcosidekick/
- (2-17) https://falco.org/docs/reference/rules/supported-events/#syscall-events
- (2-18) https://falco.org/docs/reference/rules/rule-fields/
- (2-19) https://falco.org/docs/reference/rules/default-macros/
- (2-20) https://falco.org/docs/reference/rules/examples/