
はじめに
はじめまして。Sreake事業部インターン生の高島です。2023年10月から長期インターン生としてKubernetes関連技術の習得とSRE技術の調査・検証を行っています。普段は、情報系の大学院生で、数値解析に関する研究をしています。
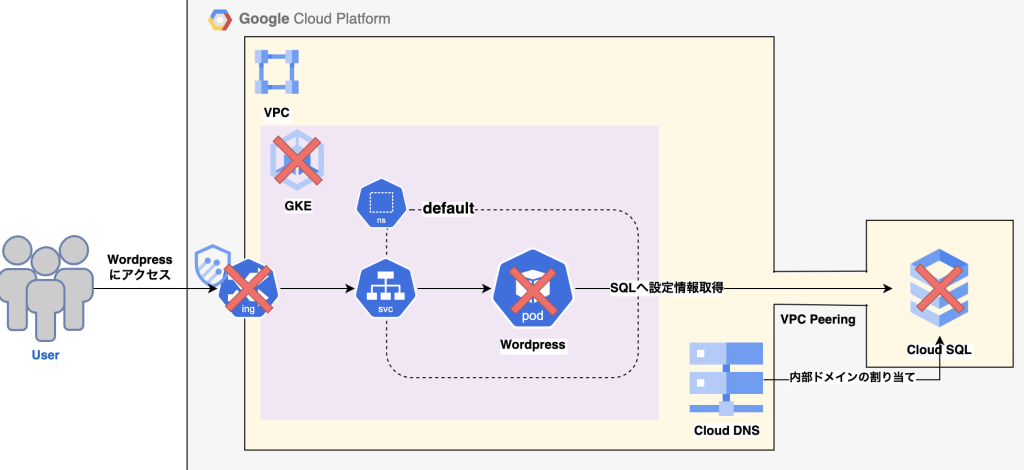
今回も、前記事に引き続き研修内容についてまとめました。本記事では、課題5の「クラスタ内の状況を監視して異常時に通知できるようにする」ということをゴールに記載します。前記事をご覧になってからだとなおわかりやすいと思いますので、そちらも一読いただけると幸いです。課題4については、課題5とはあまり繋がりがないのでそちらとは別で見ることができます。
学習事項
監視とは何かから初め、簡単な設計と導入をしていきます。
- 監視の理解
- GKEへの監視設計および導入
- Cloud MonitoringとCloud Loggingを用いたGoogle Cloudリソースの監視方法
最終的な目標を、「監視に必要なメトリクスおよびログを取得できるようにし、異常時にアラートがでるようにする」として実装を進めていきます。
事前知識と準備
本ブログは以下の内容の理解および準備をしているとスムーズに進行できます。
- 監視に関する基礎知識
- GKE下の監視対象とするアプリケーション
- 前記事で作成したGKE基盤およびWordpressを今回使用します。
- alert通知用の連絡先
- Google Cloud に関する知識
監視と可観測性
監視(Monitoring)とは、システム内のメトリクスやログを観察し、問題が発生したときに対処を促します。基本的に、システム内で完結しており、既知の問題に対して通知や自動修正などの対処を行います。今回実装を行うのはこちらになります。
可観測性(Observability)とは、メトリクスやログに加えて、トレースやイベントといったシステム間の情報も収集し、既知の問題以外の問題にも対処するためのものです。1つのシステム内で完結しないような、近年の複雑化している分散システムにおいては、Observabilityが重要になるため、紹介しておきます。
参考:AWS公式
”オブザーバビリティとモニタリングの違いは何ですか?”
“オブザーバビリティとは? クラウドネイティブなシステムで求められる理由”
監視環境の構築
監視設計
今回、前記事までに作成したGKE下のWordpressの監視を考えていきます。監視は問題を予防し、早期対応するための手段であり、システムの単なる動作確認ではありません。様々なコンポーネントからの情報を組み合わせられるように監視を構築します。また、システム内だけの監視(内部監視)ではなく、ユーザ視点での監視(外形監視)にも心がける必要があります。
考えうるインシデントから、早期に対応できるように監視対象と対象の異常動作へのアラートを設定していくことを考えます。本システムにおいて以下のようなインシデントの発生が考えられます。
- GKEのサーバリソース
問題:CPU過負荷、メモリ不足、ディスク不足
監視対象:CPU使用率、メモリ使用率、スワップ使用率、ディスク使用率 - アプリケーションの動作
問題:httpエラー、レスポンス時間の増加、アプリケーションログに記載されるエラー
監視対象:httpステータスコードの発生頻度 (4xx, 5xx系) - データベース
問題:データベースとの接続エラー、クエリの遅延、データベースの容量不足
監視対象:データベースへの接続失敗回数、クエリの実行時間、スロークエリログ、データベースの使用容量 - セキュリティ
問題:不正ログイン、脆弱性攻撃
監視対象:ログイン失敗回数、特定IPからのログイン試行、セキュリティログ、WebアプリのWAFログ - ネットワーク, ingress
問題:ネットワーク遅延、パケットロス
監視対象:Ping応答時間、帯域幅使用量、パケットロス率
考えうるインシデントを上げていくときりがありませんが、今回はこの中から特にシステム運用における影響の大きい以下について考えていきます。
- GKEリソースのCPUの負荷状況
リソースへのアクセスが集中した場合、CPU使用率が高まり、正常にリクエストに対するレスポンスを返せないことや、他システムへの影響を与える可能性があります。 監視対象:アプリを動作させるPodのCPU使用率 - データベースサーバのリソースの負荷状況
1つ目の項目同様、正常なシステム運用ができているかに大きく関係します。 監視対象:データベースのCPU使用率およびメモリ使用率 - データベースのスロークエリの発生
実行時間が遅いクエリの発生を監視します。スロークエリが多いとシステムのパフォーマンスに影響を与える可能性があるため、対処が必要になります。 監視対象:データベースの各クエリ時間 - Ingressの動作異常
外部からのアクセスを担うIngressの動作状況を監視することで、外形監視を行います。 監視対象:IngressのHealth Checkの状態
必要情報の収集
設計した監視を行うための、メトリクスやログを収集します。今回、Google Cloud下でのシステム構築を行っているため、Cloud MonitoringおよびCloud Loggingを利用してメトリクスとログを取得します。Google Cloudで作成しているリソースは、ほとんどがリソース作成時点で標準またはログ取得を有効化することでメトリクスおよびログを収集することができます。このため、本セクションでの設定は基本的にログ設定の有効化です。
CPUの使用率
GKE下での構築時点でCPUの使用率は既にメトリクスとして取得できるため、後から設定することはありません。
DBサーバのリソース
データベースサーバの構築時点でCPUの使用率は既にメトリクスとして取得できるため、後から設定することはありません。
スロークエリ
Query Insightsを利用することで、各クエリのパフォーマンスを可視化することができます。Database構築する際に利用したTerraformリソースに以下の設定を加えます。
module "sql-db_mysql" {
source = "GoogleCloudPlatform/sql-db/google//modules/mysql"
version = "18.1.0"
...
insights_config = {
query_plans_per_minute = 5
query_string_length = 1024
record_application_tags = true
record_client_address = true
}
...
}また、スロークエリに関するログを残す場合は、以下の設定をさらに加えることでCloud Loggingからスロークエリログを取得できます。
module "sql-db_mysql" {
source = "GoogleCloudPlatform/sql-db/google//modules/mysql"
version = "18.1.0"
...
database_flags = [
{
name = "log_output"
value = "FILE"
},
{
name = "slow_query_log"
value = "on"
},
{
name = "long_query_time"
value = "10"
}
]
...
}上記の設定は、10秒以上かかる処理をスロークエリと見なしてログとして残します。これら以外にもデータベースから様々な情報を取得することができます。
参考:MySQL公式
“Server System Variables”
IngressのHealth Check
IngressのHealth Checkの設定は、KubernetesのBackendConfigのHealth Checkから設定を行うことができます。通常、マニフェストファイルに書き込んで設定をしますが、Health Checkのログの有効化設定がマニフェストから記載できません。コンソールの「Ingress > バックエンドサービス > ヘルスチェック > 編集」からログを有効化します。
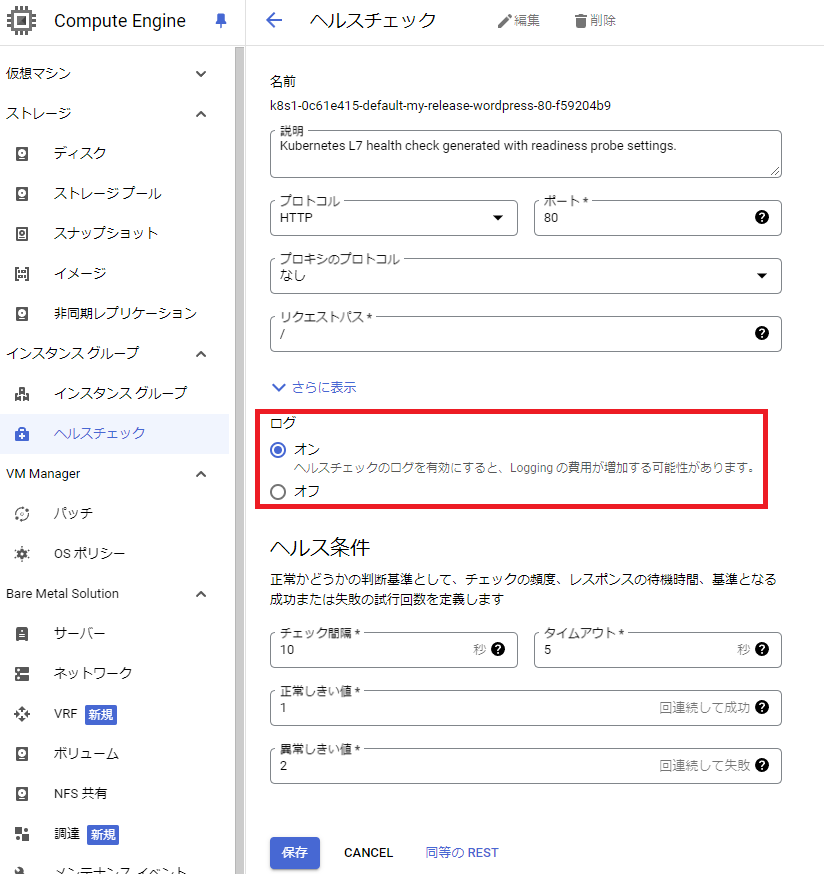
参考:Google公式
Issue Tracker ”Enable health check logs by default”
アラートの設定
収集したメトリクスおよびログを元に問題発生時にアラート通知が来るように設定します。まずは、アラート通知を行う連絡先を設定します。今回は、メール通知を行うようにしています。
resource "google_monitoring_notification_channel" "default_email" {
display_name = "My Email Notification"
type = "email"
labels = {
email_address = "email@test.sample.com"
}
}CPUの使用率
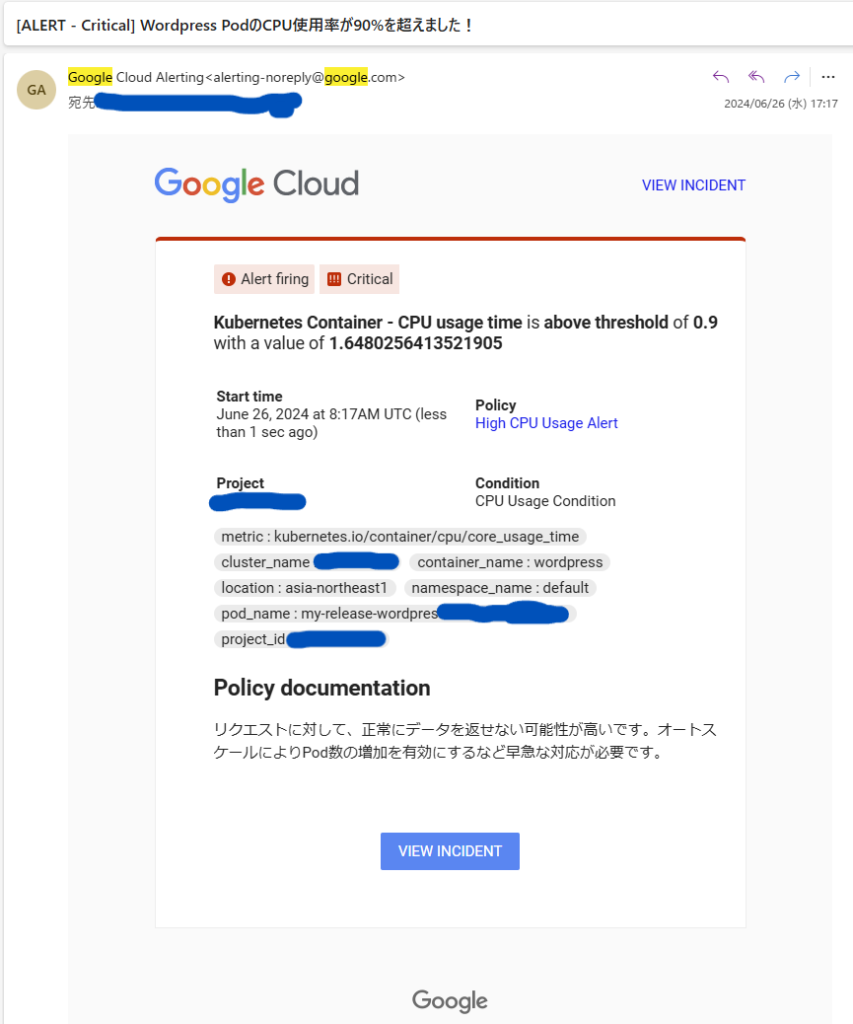
WordPressのPodのCPUの使用率が一定を超えた場合にアラート通知が来るように設定を行います。今回は、70%以上で警告(Warning)、90%以上で致命(Critical)通知が来るように設定します。
# Critical
resource "google_monitoring_alert_policy" "high_cpu_usage" {
display_name = "High CPU Usage Alert"
combiner = "OR"
conditions {
display_name = "CPU Usage Condition"
condition_threshold {
filter = "metric.type=\"kubernetes.io/container/cpu/core_usage_time\" AND resource.type=\"k8s_container\" AND resource.labels.cluster_name=\"my-terraform-cluster\" AND resource.labels.namespace_name=\"default\" AND resource.labels.pod_name=starts_with(\"my-release-wordpress-\")"
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 0.9
aggregations {
alignment_period = "60s"
per_series_aligner = "ALIGN_RATE"
}
}
}
severity = "CRITICAL"
notification_channels = [ google_monitoring_notification_channel.default_email.id ]
documentation {
subject = "Wordpress PodのCPU使用率が90%を超えました!"
content = "リクエストに対して、正常にデータを返せない可能性が高いです。オートスケールによりPod数の増加を有効にするなど早急な対応が必要です。"
}
}
# Warning
resource "google_monitoring_alert_policy" "cpu_usage" {
display_name = "CPU Usage Warning"
combiner = "OR"
conditions {
display_name = "CPU Usage Condition"
condition_threshold {
...
threshold_value = 0.7
...
}
}
severity = "WARNING"
...
}conditions内にアラート通知のトリガ条件を記載します。condition_thresholdとすると監視内容が閾値を超えた場合にアラート通知が来るようになります。notification_channelsに先ほど登録した通知する連絡先を記載します。documentation内にアラート通知の内容を記載します。上記では発生した問題を記載するのみですが、実際は対処方法や参考URLなどを記載し、すぐに問題に対処できるようにします。
DBサーバのリソース
DBサーバのCPU使用率が70%を超過またはメモリの空き容量が30%を下回った場合にアラート通知が来るように設定を行います。
resource "google_monitoring_alert_policy" "db_resource_usage" {
display_name = "SQL Server Resource Alert"
combiner = "OR"
conditions {
display_name = "SQL Server CPU Condition"
condition_threshold {
filter = "metric.type=\"cloudsql.googleapis.com/database/cpu/utilization\" AND resource.type=\"cloudsql_database\" AND resource.labels.database_id=\"project:my-wordpress-db\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 0.7
aggregations {
alignment_period = "60s"
}
}
}
conditions {
display_name = "SQL Server Memory Condition"
condition_threshold {
filter = "metric.type=\"cloudsql.googleapis.com/database/memory/components\" AND metric.labels.component=\"Free\" AND resource.type=\"cloudsql_database\" AND resource.labels.database_id=\"project:my-wordpress-db\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.3
aggregations {
alignment_period = "60s"
}
}
}
...
}複数の条件からアラートをトリガする場合、conditionsを複数記載します。この際、アラートの通知が全条件なのか一条件なのかをcombinerで管理します。今回は、どれか1つの成立でアラートが出るようにしているため、ORを利用します。
スロークエリ
スロークエリの発生ログが検出されたときに、アラート通知が来るように設定します。
resource "google_monitoring_alert_policy" "db_slow_query" {
display_name = "Slow Query"
combiner = "OR"
conditions {
display_name = "Slow Query Condition"
condition_matched_log {
filter = "resource.type=\"cloudsql_database\" AND resource.labels.database_id=\"project:my-wordpress-db\" AND log_name=~\".*slow.log$\""
}
}
alert_strategy {
notification_rate_limit {
period = "300s"
}
}
...
}ログの情報を元にアラート通知を行う場合、conditions内でcondition_matched_logを利用し、alert_strategyという通知の発生タイミングなどの設定を記載する必要があります。
IngressのHealth Check
IngressのHealth CheckがUNHEALTHYになった場合に、アラート通知が来るように設定を行います。
resource "google_monitoring_alert_policy" "ingress_healthcheck" {
display_name = "Ingress HealthCheck"
combiner = "OR"
conditions {
display_name = "Ingress HealthCheck Condition"
condition_matched_log {
filter = "resource.type=\"gce_network_endpoint_group\" AND log_name=~\".*healthchecks$\" AND jsonPayload.healthCheckProbeResult.detailedHealthState=\"UNHEALTHY\""
}
}
alert_strategy {
notification_rate_limit {
period = "300s"
}
}
...
}参考:Terraform公式 “google_monitoring_alert_policy”
各メトリクスおよびログの取得方法
必要なメトリクスおよびログの取得方法についてまとめておきます。特に、前セクションでのアラート設定でのfilterに記載することを前提とします。
メトリクス
以下のPodのCPU使用率のfilter内容を例に説明をします。
filter = "metric.type=\"kubernetes.io/container/cpu/core_usage_time\" AND resource.type=\"k8s_container\" AND resource.labels.cluster_name=\"rt-tf-cluster\" AND resource.labels.namespace_name=\"default\" AND resource.labels.pod_name=starts_with(\"my-release-wordpress-\")"初めに、取得したいメトリクス情報であるmetric.typeとどのリソースの情報が欲しいかというresource.typeを設定します。取得できるメトリクス名およびリソースの対象にできる情報については以下のページからわかります。
参考:Google Cloud公式
“Google Cloud metrics”
“GKE system metrics”
CPU使用率が見たいので、metric.type=\”kubernetes.io/container/cpu/core_usage_time\”となり、上記ページからこのメトリクスはresource.type=\”k8s_container\”ということがわかります。また、上記だけでは取得したい情報がわかりづらい場合は、コンソールのPodの詳細情報で確認できるグラフからメトリクス名を調べることもできます。グラフのメニューの「全画面で表示 > クエリを編集」から、利用しているメトリクスの情報を見ることができます。
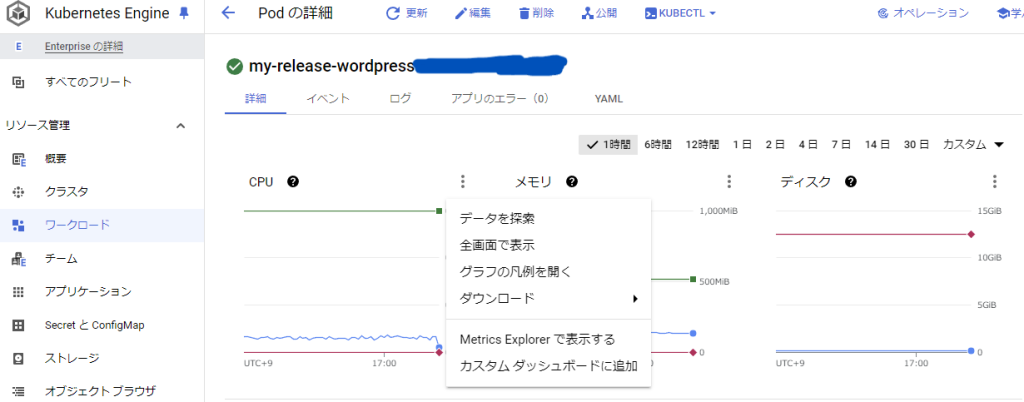
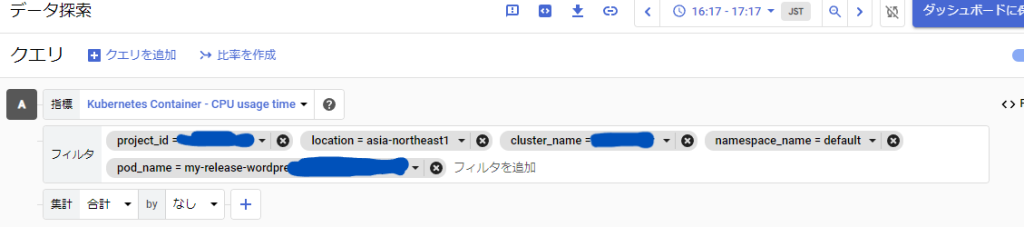
さらに、メトリクスおよびリソースの絞り込みを行うために、metric.labels.~またはresource.labels.~を設定します。metric.labels.~で設定できる内容はさきほどのメトリクス情報が載っているURLから調べることができます。resource.labels.~で設定できる内容は、メトリクスの各項目の設定可能なリソース対象から調べることができます。例として、今回のk8s_containerの場合は以下のページから知ることができます。
参考:Google Cloud公式
“Monitored resource types”
特定のPodに対しての情報が欲しいため、メトリクスに関しては別で指定したいLabelはなく、リソースに関しては、cluster_name、namespace_name、pod_nameを設定しています。また、先ほど同様にコンソールのPodの詳細情報から利用しているLabel名を調べることもできます。上記の画像でも「フィルタ」内でリソースのLabelに設定できる内容が書かれています。
今回、Pod名が”my-release-wordpress-”までは同じですが、その後に固有名を付けるためにランダムな文字列が続きます。この場合、以下のページに記載されている関数を利用することで文字列情報からフィルタリングすることができます。
参考:Google Cloud公式
“指標しきい値のアラートポリシーを作成する”
Pod名が”my-release-wordpress-”から始まる文字列である点は共通しているので、resource.labels.pod_name=starts_with(\"my-release-wordpress-\")と設定しています。
ログ
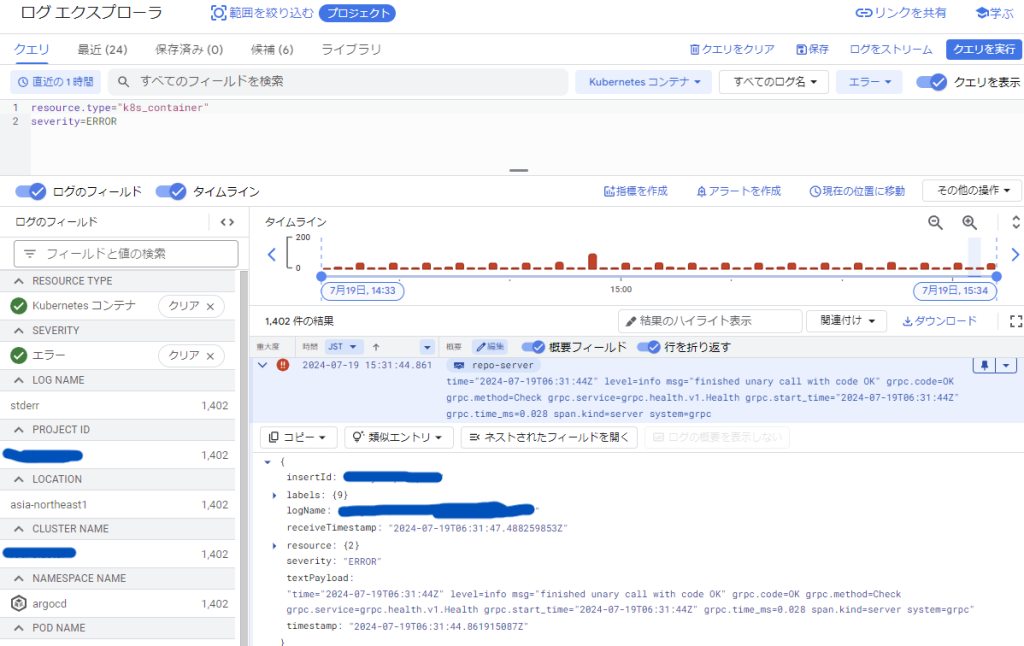
ログはリソースのみの設定になります。ログは基本的に、ログエクスプローラを利用して調べていきます。取得されているログに関しては、「ログのフィールド」から候補を絞っていき、「クエリ」に絞っている途中での設定方法が記載されていくので、メトリクスに比べて調べやすいです。また、上記のようにログはjson形式でデータが入っていますが、これらの各項目の情報から絞ることもできます。
filter = "resource.type=\"cloudsql_database\" AND resource.labels.database_id=\"project:my-wordpress-db\" AND log_name=~\".*slow.log$\""今回スロークエリを検出する際に使用したものを例にすると、このように書くことでログの名前がslow.logで終わるログを検出することができます。=~は正規表現を利用する命令になります。
動作確認
CPUの使用率 & DBサーバのリソース
CPUの使用率およびDBサーバのリソースのアラート通知確認はサーバに負荷を書ければよいので、負荷テストを利用して動作確認します。負荷テストツールとしてk6を利用します。負荷テストに使用するコードは以下のようにシンプルなものです。
注意として、過剰に負荷をかけることで使用料金が上がることや、サービスに影響を与えることがあるので、十分に注意して行ってください。
import http from 'k6/http';
import { sleep } from 'k6';
const host = 'wordpress_host.sample.com'
export const options = {
vus: 100, // 100台からの仮想アクセス
duration: '2m', // 2分間アクセスを続ける
}
export default function () {
http.get('http://' + host);
sleep(1);
}条件の閾値を超えた場合、以下のようにアラート通知のメールが届きます。
スロークエリ
作成してあるCloud SQLのインスタンス内で、スリープ関数を動作させ、スロークエリを実行させることで動作確認します。今回、データベースに対して、内部ドメインからアクセスができるため、以下のようにして接続し、スロークエリを実行します。
$ kubectl run -it --rm --restart=Never sql-test --image=mysql -- bash
$ mysql -h db.internal.cloudsql.org -u wd-user -p
> select sleep(11);正常にスロークエリログを検出できれば、先ほど同様にメールにより通知が来ます。
IngressのHealth Check
一時的にIngressの設定を変更することで動作確認します。今回、Health Check先に指定するrequestPathを存在しないものに変更します。
apiVersion: cloud.google.com/v1
kind: BackendConfig
metadata:
name: backend-config
spec:
securityPolicy:
name: my-sec-policy
healthCheck:
type: HTTP
requestPath: /heeelthIngressのHealth Checkが正常でなくなると、”UNHEALTHY”というログが残り、メールにより通知が来ます。
おわりに
Cloud MonitoringやCloud Loggingを利用して得られた情報を元にアラートを出すシステムの構築方法を説明してきました。今後は、システムのトレースにも着目し、Observabilityについても実装をしてみたいです。これにて一通りのOJTは終了し、SREに関する基礎的な技術力を身に着けることができました。