
前段
Sreake事業部の橋本です。
Generative AIをSRE活動に活用する場合に大きく分けて以下のような2ケースが考えられます。これまで1つめのtoil削減の実装をGenerative AIに含まれる学習データを利用して代替する検証を重視して行ってきました。[^1][^2]
- toil削減実装の代替
自動化できるが実際実装するとなると細かい考慮が必要になりそうなものについてGenerative AIによるコンテンツ生成で実装を代替することで短期間でのtoil削減を実現する。 - ドメイン知識の摂取効率を上げる
Generative AIがサービス独自のドメイン知識を学習することで、自然言語のやり取りでKnowledgeを集めることができる(ex: 障害内容に対する適切な対応手順書の提案等)
今回も引き続きtoil削減をテーマにコストに着目し、コストの増減を常に見張ることなく定期的に監視してくれるコストチェッカーを作成してみます。
また、trustted tester programによって許可いただいたPaLM API for textの多言語対応版を早速利用したいため、Google Cloudのコストを対象に行なっていきます(Googleが作ったモデルなのでGoogle Cloudについての出力が優れていることを期待)。
作るもの
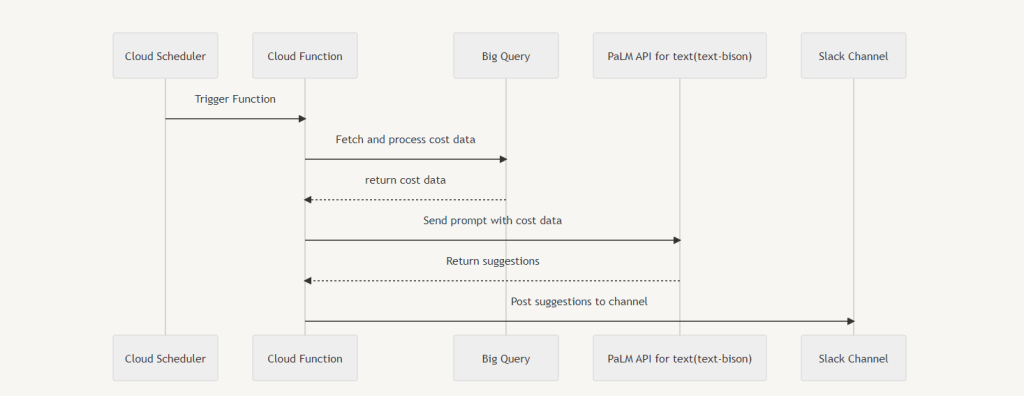
以下のようなシーケンスのシステムを作成します。 CloudSchedulerによって定期的にコストを集計し、区分時間の前後(例えば2週前のコスト合計と1週前のコスト合計)を比較したアドバイスをPaLM API for textにお願いし、その結果をSlackに通知します。
課金データを分析可能な状態にする
Google Cloudの課金データはCloud Billingのコンソール上で閲覧することができます。一方でBilling APIでは詳細な課金データを取得するエンドポイントは用意されておらず、分析を行う(プログラムで取り扱う)ためには、Big Queryへ課金データをエクスポートする必要があります。
どうしても節約したい場合にはコンソール上でcsvをダウンロードできるため、それを自動化する方法もありえなくは無いですが、コストに見合わないためBig Queryへのエクスポートを利用します。
課金データのエクスポートは有効化されたタイミング以降のデータのみであるため、利用予定がない場合でも本番アカウントの課金データなどは作成時点でエクスポートを開始しておくことをおすすめしています。[^3]
エクスポートできるデータは3種類あります。
今回はコスト推移分析のため、どのようなリソース利用が増加しているかを確認したいため使用料金データを利用します。また、token数制限を考えるとあまりに細かい単位での集計は難しい可能性がるため標準的な使用料金データをもとにSKU * Projectの単位でデータを渡すことにしました。
- 標準的な使用料金データ
アカウント ID、請求書の日付、サービス、SKU、プロジェクト、ラベル、ロケーション、費用、使用量、クレジット、調整、通貨など、標準の Cloud 請求先アカウントの使用料金情報が含まれます。 標準的な使用量データのエクスポートを使用して、費用データの幅広い傾向を分析できます。 - 詳細な使用料金データ
Cloud 請求先アカウントの費用の詳細が含まれます。標準的な使用料金データに加えて、リソースレベルの費用データ(サービスの使用状況を生成する仮想マシンや SSD など)も含まれます。 詳細な使用状況データをエクスポートして、リソースレベルでの費用を分析し、コスト増加を引き起こしている可能性のあるリソースを特定します。詳細なエクスポートには、次のプロダクトのリソースレベルの情報が含まれます。
1. Compute Engine
2. Google Kubernetes Engine(GKE)
3. Cloud Functions
4. Cloud Run
GKE に関する情報を表示するには、詳細なエクスポートでコスト割り当てを有効にします。
詳細な推奨事項と制限事項については、詳細な使用料金データのスキーマをご覧ください。 - 料金データ
アカウント ID、サービス、SKU、プロダクト、地理的メタデータ、料金の単位、通貨、集計、階層など、Cloud 請求先アカウントの料金情報が含まれます。
※公式ドキュメントより引用(BigQuery への Cloud Billing データのエクスポートを設定する)
今回は謎リソースがたくさん動いていそうな社内の検証環境の支払いデータをエクスポートしました。
Functionの実装
今回利用したソースコードです。
処理内容としては以下の内容となります。
- 設定項目の取得
- 比較用のデータをbig queryから取得(compare_rangeで日数範囲を指定)
- Generative AIにpromptを送信
- 返答内容をslackに通知
処理変数は環境変数で提供します。 課金データは最大24時間遅延するため、1日前を起点にCOMPARE_RANGEをベースに対象期間を計算します。
| MODEL | palm or openai |
|---|---|
| TABLE | テーブルアドレス(FROM句で利用) [project].[dataset].[table] |
| COMPARE_RANGE | 比較日数 例えば2の場合は1日前を起点に1−2日前と3-4日前のコストを比較 |
| PRICE_DIFFERENCE_THRESHOLD | クエリとして抜き出す課金データのしきい値(before/currentの差額がこの値以上のもののみを利用) |
| SLACK_URL | 通知先のwebhook URL |
| OPENAI_API_KEY | openai利用時のAPIキー |
import datetime
import os
import functions_framework
import openai
from google.cloud import bigquery
from string import Template
import slackweb
from vertexai.language_models import TextGenerationModel
client = bigquery.Client()
openai.api_key = os.getenv('OPENAI_API_KEY', None)
slack_url = os.getenv('SLACK_URL')
compare_range = int(os.getenv('COMPARE_RANGE', 7))
price_difference_threshold = int(os.getenv('PRICE_DIFFERENCE_THRESHOLD', 100))
model = os.getenv('MODEL', 'vertex')
table = os.getenv('TABLE')
query = Template("""
SELECT
sku.description AS sku,
project.name AS project,
ROUND(SUM(CASE WHEN DATE(_PARTITIONTIME) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL ${before_begin} DAY) AND DATE_SUB(CURRENT_DATE(), INTERVAL ${before_end} DAY) THEN cost ELSE 0 END)) AS before_cost,
ROUND(SUM(CASE WHEN DATE(_PARTITIONTIME) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL ${current_begin} DAY) AND DATE_SUB(CURRENT_DATE(), INTERVAL ${current_end} DAY) THEN cost ELSE 0 END)) AS current_cost,
FROM
${table_name}
GROUP BY
project, sku
HAVING
current_cost - before_cost > ${price_difference_threshold}
ORDER BY
project,sku
""")
prompt = Template("""
目的: Google Cloudコストの最適化を行う。
設定: あなたの役割は以下のとおりです。
- あなたはGoogle Cloudのエキスパートエンジニアです。
- ユーザはGoogle Cloudのコストを最適化するために、コストを分析する必要があります。
- これからあなたには"入力:"のあとに過去{date}日感区切りのコストデータが入力されます。形式はproject,sku,before_cost,current_costのcsv形式です。
- 渡されたコストデータを比較し、コスト最適化のアドバイスを出力してください。
ルール: 以下の項目を遵守してください。
- 日本語で回答してください。
- 金額差が大きいものについて、優先してアドバイスしてください。
- 原因となるプロジェクト名、SKU名、金額増減と削減提案を出力してください。
入力:
project,sku,before_cost,current_cost
project-a,E2 Instance Core running in Japan,1000,2000
出力:
## コスト比較結果
- project_aのE2 Instance Core running in Japanは1000円増加しています。新規にインスタンスが作成されたか、既存のインスタンスの稼働時間が増えたことが推測されます。コスト削減のためにはインスタンスサイズの見直しや、未使用時のインスタンス停止を提案します。
入力:
${data}
""")
@functions_framework.http
def cost_check(request):
# 検索日付の計算
before_date_begin = compare_range * 2 + 1
before_date_end = compare_range + 2
current_date_begin = compare_range + 1
current_date_end = 2
# BQからコストデータを抽出
query_job = client.query(
query.substitute(table_name=table,
before_begin=before_date_begin, before_end=before_date_end,
current_begin=current_date_begin, current_end=current_date_end,
price_difference_threshold=price_difference_threshold),
location="asia-northeast1")
data = "project,sku,before_cost,current_cost\\n"
for row in query_job:
data += f"{row.project},{row.sku},{row.before_cost},{row.current_cost} \\n"
today = datetime.date.today()
response = "# Compare Cost[{}~{}] vs [{}~{}]\\n\\n".format(today - datetime.timedelta(days=before_date_begin),
today - datetime.timedelta(days=before_date_end),
today - datetime.timedelta(days=current_date_begin),
today - datetime.timedelta(days=current_date_end))
response += "## Data\\n" + data + "\\n"
# Generative AIによるアドバイス生成
if model == "openai":
advice = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "user",
"content": prompt.substitute(date=compare_range, data=data)},
]
)
response += advice.choices[0].message.content
else:
genai = TextGenerationModel.from_pretrained("text-bison")
advice = genai.predict(prompt.substitute(date=compare_range, data=data),
temperature=1.0,
top_p=1.0,
max_output_tokens=1024)
response += advice.text
# slackチャンネルへの通知
slack_client = slackweb.Slack(url=slack_url)
slack_client.notify(text=response)
return response
PaLM API for textのSDK対応が執筆時点ではPythonのみであったためPythonで記載しています。
OpenAIと比較するとADCを利用できるため、APIキーなどの管理が不要となる点はとても嬉しいですね。
Prompt
OpenAIでの試行錯誤がどの程度通用するのか、両者のprompt設計について記載のあるドキュメントを読み比べました。
PaLM API for text: https://cloud.google.com/vertex-ai/docs/generative-ai/learn/introduction-prompt-design
OpenAI: https://platform.openai.com/docs/guides/gpt-best-practices
概ね同じ考え方でよさそうですのでこれまでと同じ形で試行錯誤を進めていきました。
一点だけ、こちらのドキュメントより情報のprefixを付ける場合はコロン区切りという指定があったため、そのようにしています。
https://cloud.google.com/vertex-ai/docs/generative-ai/text/text-overview
コードに記載のある通り、以下のプロンプトが最終形です。
金額差が大きいものについて、優先してアドバイスしてください。
はじめは上記の記載からうまいこと抽出してくれることを期待していましたが制御がうまく出来なかったため、コード上30行目の通りHAVING句でしきい値金額以上増額したデータのみを抜き出してPaLM APIへ渡すようにしています。
目的: Google Cloudコストの最適化を行う。
設定: あなたの役割は以下のとおりです。
- あなたはGoogle Cloudのエキスパートエンジニアです。
- ユーザはGoogle Cloudのコストを最適化するために、コストを分析する必要があります。
- これからあなたには"入力:"のあとに過去{date}日感区切りのコストデータが入力されます。形式はproject,sku,before_cost,current_costのcsv形式です。
- 渡されたコストデータを比較し、コスト最適化のアドバイスを出力してください。
ルール: 以下の項目を遵守してください。
- 日本語で回答してください。
- 金額差が大きいものについて、優先してアドバイスしてください。
- 原因となるプロジェクト名、SKU名、金額増減と削減提案を出力してください。
入力:
project,sku,before_cost,current_cost
project-a,E2 Instance Core running in Japan,1000,2000
出力:
## コスト比較結果
- project_aのE2 Instance Core running in Japanは1000円増加しています。新規にインスタンスが作成されたか、既存のインスタンスの稼働時間が増えたことが推測されます。コスト削減のためにはインスタンスサイズの見直しや、未使用時のインスタンス停止を提案します。
入力:
${data}
出力:
実装結果
最終的な出力は以下のような形となりました。データとしては1週間分の増加について比較し、100円以上増加のあるものについて抽出しています。 ※プロジェクト名は公開用に手動で変更しています。
# Compare Cost[2023-07-04~2023-07-10] vs [2023-07-11~2023-07-17]
## Data
project,sku,before_cost,current_cost
project-sample-a,E2 Instance Core running in Japan,18.0,185.0
project-sample-a,Network Load Balancing: Forwarding Rule Minimum Service Charge in Japan,0.0,140.0
project-sample-a,Regional Kubernetes Clusters,62.0,400.0
project-sample-b,External IP Charge on a Standard VM,0.0,161.0
project-sample-b,HTTP Load Balancing: Global Forwarding Rule Minimum Service Charge,299.0,605.0
project-sample-c,Network Load Balancing: Forwarding Rule Additional Service Charge in Americas,316.0,484.0
project-sample-d,Monitoring API Requests,425.0,858.0
project-sample-e,Monitoring API Requests,432.0,872.0
## コスト比較結果
- 以下のプロジェクトは費用が大幅に増加しています。
- project-sample-aのE2 Instance Core running in Japanは177円増加しています。新規にインスタンスが作成されたか、既存のインスタンスの稼働時間が増えたことが推測されます。コスト削減のためにはインスタンスサイズの見直しや、未使用時のインスタンス停止を提案します。
- project-sample-aのNetwork Load Balancing: Forwarding Rule Minimum Service Charge in Japanは140円増加しています。新しいルーティングルールが作成されたか、既存のルーティングルールの有効時間が延長されたことが推測されます。コスト削減のためには、必要のないルーティングルールは削除し、必要なルーティングルールについては有効時間の見直しを提案します。
- project-sample-aのRegional Kubernetes Clustersは248円増加しています。新しいクラスターが作成されたか、既存のクラスターのインスタンスサイズが拡大されたことが推測されます。コスト削減のためには、クラスターのインスタンスサイズを最適化し、必要のないクラスターを停止することを検討します。
- project-sample-bのExternal IP Charge on a Standard VMは161円増加しています。新しいIPアドレスが作成されたか、既存のIPアドレスの有効期限が延長されたことが推測されます。コスト削減のためには、不要なIPアドレスは削除し、必要なIPアドレスについては有効期限の見直しを提案します。
- project-sample-bのHTTP Load Balancing: Global Forwarding Rule Minimum Service Chargeは306円増加しています。新しいリスニングポートが作成されたか、既存のリスニングポートの有効時間が延長されたことが推測されます。コスト削減のためには、必要のないリスニングポートは削除し、必要なリスニングポートについては有効期限の見直しを提案します。
- project-sample-cのNetwork Load Balancing: Forwarding Rule Additional Service Charge in Americasは168円増加しています。新しいサブネットが作成されたか、既存のサブネットのルールが追加されたことが推測されます。コスト削減のためには、サブネットに必要なルールのみ追加し、不要なルールは削除することを提案します。
- project-sample-dのMonitoring API Requestsは433円増加しています。新しい監視対象リソースが追加されたか、既存のリソースへの監視設定が変更されたことが推測されます。コスト削減のためには監視対象リソースを最適化し、不要な監視は停止することを提案します。
- project-sample-eのMonitoring API Requestsは440円増加しています。新しい監視対象リソースが追加されたか、既存のリソースへの監視設定が変更されたことが推測されます。コスト削減のためには監視対象リソースを最適化し、不要な監視は停止することを提案します。
project-aでは新規に何かが作成されたであろうことが見て取れます。アドバイス通り未使用な場合は削除ないし停止するように依頼します。
project-bについても同様ですね。
project-d, project-eについてはMonitoring APIの増加ということで確認したところDatadogのIntegrationが入っているプロジェクトでした。月初何日か分はCloud Monitoringの無料枠の範囲で転送ができていたためこのような差分が出ていました。
これを回避するためにはリソースの使用量で確認することも1つの案として考えられます。
https://cloud.google.com/stackdriver/pricing?hl=ja
また、しきい値を高めて500円にすると抽出対象のデータがなくなり、以下のような出力となりました。知りたいしきい値の大きな変動がないときは影響がないことを伝えられそうです。
# Compare Cost[2023-07-04~2023-07-10] vs [2023-07-11~2023-07-17]
## Data
project,sku,before_cost,current_cost
## コスト比較結果
- コストは増減していません。問題ありません。
最後に
今回はPaLM API for textの多言語対応モデルを使ってみたいというモチベーションでGoogle Cloudのコストチェッカーを作成してみました。
作成したものについて
今回はデータの渡し方について悩みました。token制限とあまりにも汎用なデータ(日次のコストデータなど)ですと欲しい情報が得られないケース(1円増などの細かい情報ばかり報告されるなど)が続き、最終的に記事のとおり、指定した日数間隔のコストデータのうちしきい値以上の増加があったもののみ渡すという形に落ち着きました。
最終的な成果物では徐々に利用料金が膨らんでいってしまった場合などについて気づくことができません。また、コスト対策がうまく言っているのかどうかを評価する場合はまた違ったデータの整形が必要になってくると思われます。
PaLM API for textについて
実装の感覚としては、OpenAI(gpt3.5-turbo)と大きな違いはなく、近い感覚での開発が行えるなという感想です。またCloudサービスと密接なことによってADC利用など認証まわりの煩わしさが無い点は魅力に写ります。
出力品質については他のタスク等も実行していきたいと思っていますが、今回のタスクについては計算ミス等は見られるものの概ね期待通りの出力を行ってくれています。一般GAされた場合にはユースケースによってはPaLM API for textを利用することもできそうです。
今後ともSRE/DevOps領域でのGenerative AI活用の模索を続けていきます。 OpenAI APIとPaLM API for textの詳細な比較やLangchainを用いたより高度なGenerative AI活用などを考えています。
脚注
[^1] OpenAI API を利用して Terraform から構成図っぽい Mermaid を出力してくれるコマンドを作った話[^2]OpenAI APIを利用してパブリッククラウドの権限要約をしてくれるCLIコマンドを作成した
[^3] Cloud Billing データを BigQuery にエクスポートする