
1. はじめに
はじめまして、Sreake事業部インターン生の井上です。私はSreake事業部にてSRE技術の調査と研究を行う目的で2023年3月6日から長期インターン生として参加しています。
本記事では、Kubernetesの運用効率化をChatGPTで実現する方法について調査・評価した事をまとめました。
2. ChatGPT-3とは?
概要
- 開発元のOpenAI 公式からの引用
- 会話形式でやり取りする ChatGPT というモデルをトレーニングしました。対話形式により、ChatGPT はフォローアップの質問に答えたり、間違いを認めたり、間違った前提に異議を唱えたり、不適切な要求を拒否したりできます。
- 要約すると、対話形式で会話ができるチャットボット。
- GPTとはGenerative Pre-trained Transformerの略で、Transformerと呼ばれるニューラルネットワークアーキテクチャを使用している。OpenAIのGPT-3ファミリーの言語モデルを基に構築が行われている。
- 特徴
- 対話形式で、タスクを投げる事ができる。
- タスク例
- テキストの生成
- 質問への回答
- テキストの翻訳
- テキストの要約
- 自然な問答を実現する一方で、不正確な回答を出す事がある。
ChatGPTの学習データについて
- 主に、インターネット上のテキスト、書籍、ニュース記事、ウィキペディアの記事、映画の字幕、会話文等が含まれる。
- IT系の技術も、ウェブサイトの記事、技術ブログ、オンラインの学術論文、コンファレンスのプレゼンテーション、またはオンラインの教育プラットフォームから収集されている。
- 上記の学習データについて質問した際に以下のような返答がされた
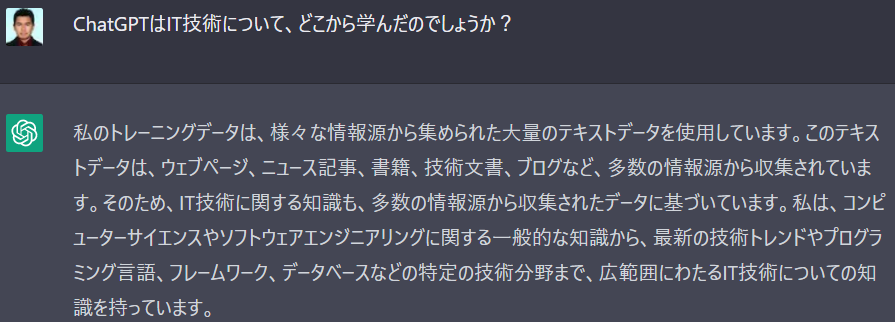

ChatGPTのライセンスや利用規約・利用時の注意事項について(2023年3月13日時点)
公式FAQの引用を翻訳。ChatGPTを利用して作ったアウトプット自体は製作者が権利を持つ。
ChatGPTで出力したものを商用利用することは可能ですか?
コンテンツポリシーと規約に従い、ChatGPTで作成したアウトプットは、無料プラン、有料プランを問わず、転載、販売、商品化する権利を含め、お客様に帰属します。ChatGPT APIについて(2023年3月13日時点)
- ChatGPTではAPIの提供がされていて、無料試用枠がある。また、30日間データが保存されるが、API 経由で送信されたお客様のデータを使用してモデルを改善することはありませんと明記されている。
利用上の注意
- 社外秘なデータ等は、一般的な観点で送信を控えるべきである。
3. Kubernetes × ChatGPT = 運用効率化
調査背景
ChatGPTは、学習データにIT系の技術も多く含む事から、Kubernetesについても対応ができる事が予想される。ChatGPTでKubernetesに関する問題を質問して、運用チームに回答する事で大幅な運用効率化が期待できる。 また、インシデント発生時に、出力されたエラー文や構成情報等を、入力としてChatGPTに与え、影響範囲特定、障害レベル、対応方針を、ChatGPTに回答させる事で、運用チームのtoilを軽減する事が期待できる。
インシデント対応の一般的な処理内容について、PagerDuty株式会社のインシデント処理に関する記事によれば、インシデントの初期対応として以下の二つが掲げられている。
把握する(Size-Up)
何が発生しているか、それがどの程度の影響があるかを判断します。後によい意思決定ができるための、情報収集のステップです。
1. 症状を特定する - 「なにが悪いのか?」を問う
- 症状を特定して、専門家に情報を提供するよう依頼します。
- 可能な限り多くの情報を収集します(この間にもインシデントは継続していることに気をつけてください)。
2. インシデントの範囲を特定する - 「複数サービスに影響があるのか?」を問う
- 問題の規模と、拡大しているか、バタついているか、静的なのかを判断します。
- 事実、起こりうること、それが起こる確率を取得します
本記事では、「Kubernetes × ChatGPT = 運用効率化」を実現する方法として、上記のインシデント処理の初期対応を中心に取り扱う。
本記事で扱う運用ケースの例
本記事では、Kubernetes Eventを使った例について考える。 Kubernetes Eventとは、クラスター内のどこかで発生したイベントレポートで、システム内の何らかの状態変化を示す。Kubernetes Eventを、Slackやwebhookに通知するOSSとして、 KubeCon 2019 San Diegoで発表されたkubernetes-event-exporterがある。これらを利用して、筆者が思いついた簡易的なフローを以下に提示する。
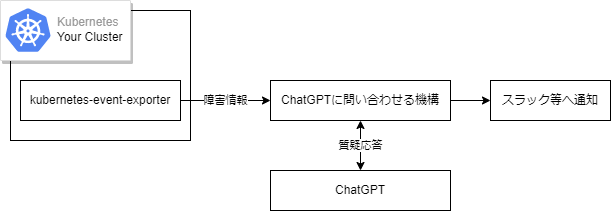
このフローでは、Kubernetes Eventから、得られた障害情報を元にChatGPTが解析し、Slack等に通知する事で初期対応を迅速化できると考えられる。
4. 検証方法
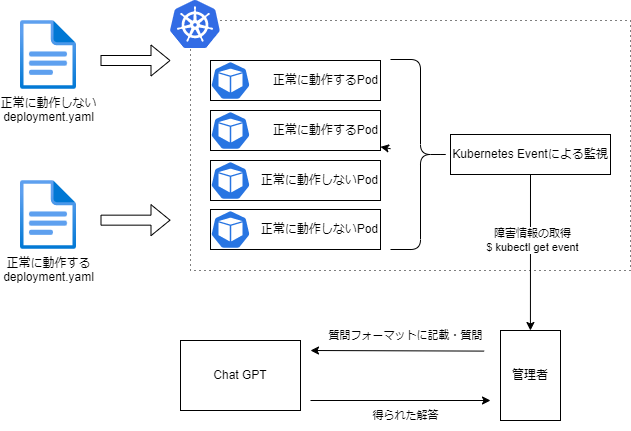
発生した障害について、Kubernetes Eventから得られた情報をChatGPTに質問、分析させ、任意のフォーマットで回答の出力を行わせる。
評価軸
- 解決の糸口
- 質問として、求められている回答が出てくるか?
質問フォーマット
- 以下の質問リストは、インシデントの初期対応に必要な情報を盛り込んだ他、KubernetesのIssue Formのテンプレート情報を盛り込んだ。
# Kubernetesの運用中に以下のエラーが出ました。以下に情報を元に、解決の支援をお願いします。
# Kubernetesの構成に関する情報
- Kubernetes のバージョン
- 1.26.2
- インストール方法又はクラウドプロバイダー
- K0sctl
- OSバージョン
- Linux ubuntu 20.04
- インストール済みのツール
- Helm
- 関連するプラグイン (CNI、CSI など) とバージョン (該当する場合)
- CNI
- Kube-Router v1.5.1
# 解答は以下のフォーマットでお願いします。ChatGPTの回答は<ChatGPT_Answer>に入力して下さい。
1. 障害箇所特定(Kubernetesを構成するコンポーネント、それ以外の場合でも、どこに問題があるか一言で入力して下さい。)
- 障害箇所 : <ChatGPT_Answer>
- 根拠 : <ChatGPT_Answer>
2. 障害内容の説明
- <ChatGPT_Answer>
3. 障害の原因(何が悪いのか?複数個ある場合は箇条書きで入力して下さい。)
- <ChatGPT_Answer>
4. 症状(上記障害で起きる事)
- <ChatGPT_Answer>
5. 障害の解決方針(複数個ある場合は箇条書きで入力して下さい。)
- <ChatGPT_Answer>
# エラー文は以下です。
```
<エラー文を挿入>
```5. 検証環境
オンプレミス環境上にVMを3つ用意して、1つをMasterノード、2つをWorkerノードのクラスタを構築した。
6. 実際に検証してみる
前準備
障害を意図的に引き起こすために、定期的に再起動を繰り返すPodを用意します。以下のdeployment.yamlを検証用のKubernetesクラスタにデプロイする。このdeployment.yamlのコンテナは、実行時の引数にsleep 60を指定しているため、一分毎にPodが終了する。
deployment.yaml
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: dead-deployment
spec:
selector:
matchLabels:
app: ubuntu
replicas: 3
template:
metadata:
labels:
app: ubuntu
spec:
containers:
- name: ubuntu
image: ubuntu:20.04
command: ["bash", "-c" , "sleep 60"]
正常に稼働するdeployment.yamlとして以下を用意して同時にデプロイする。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80情報(Kubernetesのイベントログ)を用意して、先程の質問フォーマットに挿入して、ChatGPTへ与える。
Kubernetesのイベントログ(Podオブジェクトのみ)
$ kubectl get event | grep pod/
37m Normal Scheduled pod/dead-deployment-6f457d7d5b-4gx7j Successfully assigned default/dead-deployment-6f457d7d5b-4gx7j to 3shake-k8s-node-001
37m Normal Pulling pod/dead-deployment-6f457d7d5b-4gx7j Pulling image "ubuntu:20.04"
...
略
...
29m Normal Created pod/nginx-deployment-57c68fcd95-fm72g Created container nginx
29m Normal Started pod/nginx-deployment-57c68fcd95-fm72g Started container nginx
24m Warning BackOff pod/dead-deployment-6f457d7d5b-4gx7j Back-off restarting failed containerChatGPTからの回答を得られた

- ChatGPTへの質問に正常なPodのイベントログも含めたが、滞りなく解答が行われた。
- 障害箇所の特定や、障害内容の説明が適切に行われている。
- 解決の糸口に必要な情報等が記載されているため、初期対応が迅速に行える考えられる。
追加での質問
実際に、障害に対処していく上で、トラブルシューティングが必要な場面がある。 会話形式で、質問して、トラブルシューティングを進める事も可能である。
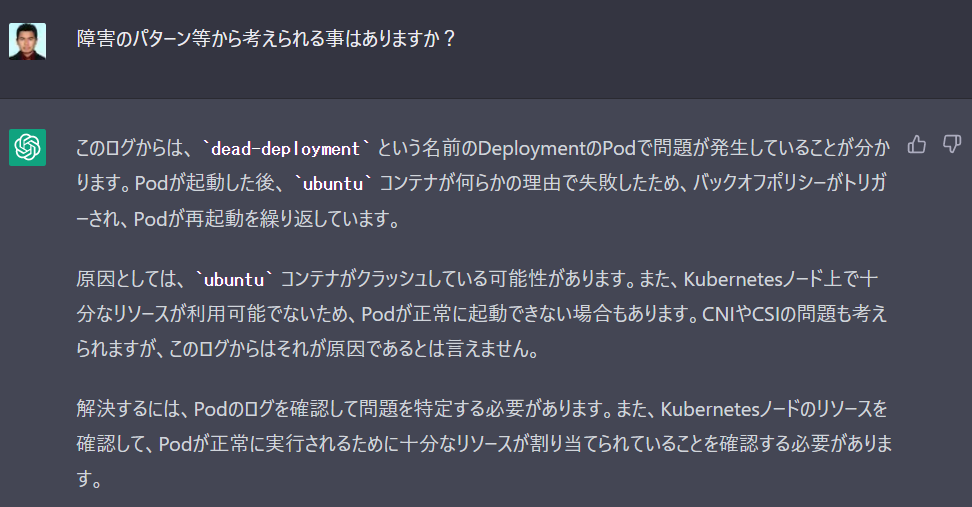
再現性について
同じ入力を与え試行すると、ほとんどのケースでは、文面が同じものの、Podの○○に問題がある、コンテナに問題がある、対応方法としてコンテナの詳細ログを追う等、文の体裁が異なるものの、本質的に同じ解答が得られた。
7. 評価
- 今回の検証では、以下の事が評価できた。
- 正常なPod等もデプロイしたが、滞りなく解答が行われた。
- 障害箇所や障害原因を要約できている。
- コンテナ内のエラーという事を正しく読み取れている。
- 障害の解決方針が、実際に起きた場合の対処法と概ね一致していると考えられる。
- 障害箇所の特定や、障害内容の説明が適切に行われている。
- 解決の糸口に必要な情報等が記載されているため、初期対応やネクストアクションが迅速に行える事が期待できる。
- 以上の障害対応のフローでは、Kubernetes Eventから、得られた障害情報を元にChatGPTが解析し、Slack等に通知する事で初期対応を迅速化が期待できる。また、実際の現場では、システムの中身を知らない人が引き継ぎ、手順書通りに復旧対応を行うシチュエーションがある。この手順書について、ChatGPTを使い、動的に生成する事ができれば、復旧の高速化が期待できる。
- 今後は、Pod のログ / 言語 / パッケージ等の情報もChatGPTに与え、エラー内容要約、解決策の提案等にも挑戦したい。また、実際のシステムやフローへの導入・構築にも挑戦したいと考える。